Mining Refactorings from Version Histories: Studies, Tools, and Applications/ Danilo Ferreira E Silva — Belo Horizonte, 2020
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Comodo System Cleaner Version 3.0
Comodo System Cleaner Version 3.0 User Guide Version 3.0.122010 Versi Comodo Security Solutions 525 Washington Blvd. Jersey City, NJ 07310 Comodo System Cleaner - User Guide Table of Contents 1.Comodo System-Cleaner - Introduction ............................................................................................................ 3 1.1.System Requirements...........................................................................................................................................5 1.2.Installing Comodo System-Cleaner........................................................................................................................5 1.3.Starting Comodo System-Cleaner..........................................................................................................................9 1.4.The Main Interface...............................................................................................................................................9 1.5.The Summary Area.............................................................................................................................................11 1.6.Understanding Profiles.......................................................................................................................................12 2.Registry Cleaner............................................................................................................................................. 15 2.1.Clean.................................................................................................................................................................16 -

The Top 10 Open Source Music Players Scores of Music Players Are Available in the Open Source World, and Each One Has Something That Is Unique
For U & Me Overview The Top 10 Open Source Music Players Scores of music players are available in the open source world, and each one has something that is unique. Here are the top 10 music players for you to check out. verybody likes to use a music player that is hassle- Amarok free and easy to operate, besides having plenty of Amarok is a part of the KDE project and is the default music Efeatures to enhance the music experience. The open player in Kubuntu. Mark Kretschmann started this project. source community has developed many music players. This The Amarok experience can be enhanced with custom scripts article lists the features of the ten best open source music or by using scripts contributed by other developers. players, which will help you to select the player most Its first release was on June 23, 2003. Amarok has been suited to your musical tastes. The article also helps those developed in C++ using Qt (the toolkit for cross-platform who wish to explore the features and capabilities of open application development). Its tagline, ‘Rediscover your source music players. Music’, is indeed true, considering its long list of features. 98 | FEBRUARY 2014 | OPEN SOURCE FOR YoU | www.LinuxForU.com Overview For U & Me Table 1: Features at a glance iPod sync Track info Smart/ Name/ Fade/ gapless and USB Radio and Remotely Last.fm Playback and lyrics dynamic Feature playback device podcasts controlled integration resume lookup playlist support Amarok Crossfade Both Yes Both Yes Both Yes Yes (Xine), Gapless (Gstreamer) aTunes Fade only -

Introducción a Linux Equivalencias Windows En Linux Ivalencias
No has iniciado sesión Discusión Contribuciones Crear una cuenta Acceder Página discusión Leer Editar Ver historial Buscar Introducción a Linux Equivalencias Windows en Linux Portada < Introducción a Linux Categorías de libros Equivalencias Windows en GNU/Linux es una lista de equivalencias, reemplazos y software Cam bios recientes Libro aleatorio análogo a Windows en GNU/Linux y viceversa. Ayuda Contenido [ocultar] Donaciones 1 Algunas diferencias entre los programas para Windows y GNU/Linux Comunidad 2 Redes y Conectividad Café 3 Trabajando con archivos Portal de la comunidad 4 Software de escritorio Subproyectos 5 Multimedia Recetario 5.1 Audio y reproductores de CD Wikichicos 5.2 Gráficos 5.3 Video y otros Imprimir/exportar 6 Ofimática/negocios Crear un libro 7 Juegos Descargar como PDF Versión para im primir 8 Programación y Desarrollo 9 Software para Servidores Herramientas 10 Científicos y Prog s Especiales 11 Otros Cambios relacionados 12 Enlaces externos Subir archivo 12.1 Notas Páginas especiales Enlace permanente Información de la Algunas diferencias entre los programas para Windows y y página Enlace corto GNU/Linux [ editar ] Citar esta página La mayoría de los programas de Windows son hechos con el principio de "Todo en uno" (cada Idiomas desarrollador agrega todo a su producto). De la misma forma, a este principio le llaman el Añadir enlaces "Estilo-Windows". Redes y Conectividad [ editar ] Descripción del programa, Windows GNU/Linux tareas ejecutadas Firefox (Iceweasel) Opera [NL] Internet Explorer Konqueror Netscape / -

Comodo System Cleaner Software Version 3.0
Comodo System Cleaner Software Version 3.0 User Guide Guide Version 3.0.011811 Comodo Security Solutions 1255 Broad Street STE 100 Clifton, NJ 07013 Comodo System Cleaner - User Guide Table of Contents 1.Comodo System- Cleaner - Introduction ................................................................................................................................. 3 1.1.System Requirements......................................................................................................................................................... 5 1.2.Installing Comodo System-Cleaner..................................................................................................................................... 5 1.3.Starting Comodo System-Cleaner....................................................................................................................................... 9 1.4.The Main Interface............................................................................................................................................................ 10 1.5.The Summary Area........................................................................................................................................................... 11 1.6.Understanding Profiles...................................................................................................................................................... 12 2.Registry Cleaner...................................................................................................................................................................... -

N – Scheme Directorate of Technical Education
DIPLOMA IN ENGINEERING AND TECHNOLOGY 1053 DEPARTMENT OF COMPUTER NETWORKING ENGINEERING SEMESTER PATTERN N – SCHEME IMPLEMENTED FROM 2020 - 2021 CURRICULUM DEVELOPMENT CENTRE DIRECTORATE OF TECHNICAL EDUCATION CHENNAI-600 025, TAMIL NADU (Blank Page) Curriculum Development Centre, DOTE. ii STATE BOARD OF TECHNICAL EDUCATION & TRAINING, TAMILNADU DIPLOMA IN COMPUTER NETWORKING ENGINEERING SYLLABUS ( II & III YEAR) N Scheme (To be implemented for the students admitted from the year 2020-21 onwards) Chairperson Tmt. G. LAKSHMI PRIYA I.A.S Director, Directorate of Technical Education, Chennai-25 Co-ordinator Tmt.P.Saratha M.E., Principal, Government Polytechnic College, Kirishnagiri-635 001 DIPLOMA IN COMPUTER NETWORKING ENGINEERING (1053) Convener Dr. V.G. Ravindhren M.E., Ph.D., Lecturer(SG)/Computer & Vice-principal, 221, Seshasayee Institute of Technology, Trichy-620 010. Mobile Number: 9443483254. Members Thiru.T. Muthamilselvam. B.E., M.Tech., Tmt. O. Vijaya Venkateswari M.Tech. , Lecturer (SG) / Computer Engg. Lecturer (SG) / Computer Engg., Seshasayee Institute of Technology, Government Polytechnic College, Srirangam, Trichy 620010. Trichy - 620 006. Mobile Number: 9994499781 Mobile Number: 9486067647 Tmt. N. Swarnalatha B.E., Dr. G. Vinodhini M.E., Ph.D., Lecturer (SG) / Computer Engg., Lecturer / Computer Engg. A.D.J. Dharmambal Polytechnic College, Government Polytechnic College, Srirangam, Nagappattinam. Trichy 620 006. Mobile Number: 9442088674 Mobile Number: 9626885482 Thiru. AR.Seetharaman M.E., Dr.S. Chellammal M.Sc., M.Tech., PGDCA, Ph.D., Lecturer/ Computer Engg.. Assistant Professor(Senior), Dept of Computer Government Polytechnic College, Science Bharathidasan University Arts & Thuvakkudi, Trichy 620 022. Science College, Trichy 620 027. Mobile Number: 8489576276. Mobile Number: 9444109147. Thiru.Kabithapriyan Palanivel B.Tech., Tmt. -

Ubuntu:Precise Ubuntu 12.04 LTS (Precise Pangolin)
Ubuntu:Precise - http://ubuntuguide.org/index.php?title=Ubuntu:Precise&prin... Ubuntu:Precise From Ubuntu 12.04 LTS (Precise Pangolin) Introduction On April 26, 2012, Ubuntu (http://www.ubuntu.com/) 12.04 LTS was released. It is codenamed Precise Pangolin and is the successor to Oneiric Ocelot 11.10 (http://ubuntuguide.org/wiki/Ubuntu_Oneiric) (Oneiric+1). Precise Pangolin is an LTS (Long Term Support) release. It will be supported with security updates for both the desktop and server versions until April 2017. Contents 1 Ubuntu 12.04 LTS (Precise Pangolin) 1.1 Introduction 1.2 General Notes 1.2.1 General Notes 1.3 Other versions 1.3.1 How to find out which version of Ubuntu you're using 1.3.2 How to find out which kernel you are using 1.3.3 Newer Versions of Ubuntu 1.3.4 Older Versions of Ubuntu 1.4 Other Resources 1.4.1 Ubuntu Resources 1.4.1.1 Unity Desktop 1.4.1.2 Gnome Project 1.4.1.3 Ubuntu Screenshots and Screencasts 1.4.1.4 New Applications Resources 1.4.2 Other *buntu guides and help manuals 2 Installing Ubuntu 2.1 Hardware requirements 2.2 Fresh Installation 2.3 Install a classic Gnome-appearing User Interface 2.4 Dual-Booting Windows and Ubuntu 1 of 212 05/24/2012 07:12 AM Ubuntu:Precise - http://ubuntuguide.org/index.php?title=Ubuntu:Precise&prin... 2.5 Installing multiple OS on a single computer 2.6 Use Startup Manager to change Grub settings 2.7 Dual-Booting Mac OS X and Ubuntu 2.7.1 Installing Mac OS X after Ubuntu 2.7.2 Installing Ubuntu after Mac OS X 2.7.3 Upgrading from older versions 2.7.4 Reinstalling applications after -

DVD-Libre 2015-10 DVD-Libre Libreoffice 5.0.2 - Libreoffice Libreoffice - 5.0.2 Libreoffice Octubre De 2015 De Octubre
(continuación) LenMus 5.3.1 - Liberation Fonts 1.04 - LibreOffice 5.0.2 - LibreOffice 5.0.2 Ayuda en español - Lilypond 2.18.2 - Linphone 3.8.5 - LockNote 1.0.5 - 0 1 Luminance HDR 2.4.0 - MahJongg Solitaire 3D 1.0.1 - MALTED 3.0 2012.10.23 - - Marble 1.09.1 - MD5summer 1.2.0.05 - MediaInfo 0.7.78 - MediaPortal 2.0.0 Update 1 - 5 DVD-Libre 1 Miranda IM 0.10.36 - Miro Video Converter 3.0 - Mixxx 1.11.0 - Mnemosyne 2.3.3 - 0 2 Mozilla Backup 1.5.1 - Mozilla Backup 1.5.1 Españ ol - muCommander 0.9.0 - 2015-10 MuseScore 2.0.2 - MyPaint 1.0.0 - Nightingale 1.12.1 - ODF Add-in para Microsoft e r Office 4.0.5309 - Password Safe 3.36 - PDF Split and Merge 2.2.4 2015.01.13 - b i PdfBooklet 2.3.2 - PDFCreator 2.1.2 - PeaZip 5.7.2 - Peg-E 1.2.1 - PicToBrick 1.0 - L DVD-Libre es una recopilación de programas libres para Windows. - Pidgin 2.10.11 - PNotes.Net 3.1.0.3 - Pooter 5.0 - Portable Puzzle Collection D 2015.09.19 - PosteRazor 1.5.2 - ProjectLibre 1.6.2 - PuTTY 0.65 - PuTTY Tray V En http://www.cdlibre.org puedes conseguir la versión más actual de este 0.65.t026 - Pyromaths 15.02 - PyTraffic 2.5.3 - R 3.2.2 - Remove Empty Directories 2.2 D DVD, así como otros CDs y DVDs recopilatorios de programas y fuentes. -

Linux Essentiel Est Édité Par Les Éditions Diamond B.P
Linux Essentiel est édité par Les Éditions Diamond B.P. 20142 / 67603 Sélestat Cedex Tél. : 03 67 10 00 20 | Fax : 03 67 10 00 21 E-mail : [email protected] ÉDITO [email protected] Service commercial : Linux Essentiel n°29 [email protected] Sites : http://www.linux-essentiel.com http://www.ed-diamond.com Directeur de publication : Arnaud Metzler Chef des rédactions : Denis Bodor Place au Rédactrice en chef : Aline Hof Secrétaire de rédaction : Véronique Sittler changement ! Conception graphique : Kathrin Scali Responsable publicité : Tél. : 03 67 10 00 27 ombreux sont ceux (et j’en fais partie) prêts à parier que l’on retrouvera des Service abonnement : Tél. : 03 67 10 00 20 tablettes sous beaucoup de sapins pour ces fêtes de fin d’année. Il faut dire Photographie et images : www.fotolia.com que les constructeurs ont fait en sorte de tenter un maximum le grand public Impression : VPM Druck Rastatt / Allemagne avec une large variété de modèles et surtout des produits qui deviennent Distribution France : de plus en plus accessibles. Là où il y a quelque temps de cela, il fallait (uniquement pour les dépositaires de presse) compter un budget de plus de 500 euros pour s’offrir ce joujou high-tech, désormais, les offres MLP Réassort : N débutent aux alentours des 200 euros et sont parfois même inférieures à cela. Plate-forme de Saint-Barthélemy-d’Anjou Tél. : 02 41 27 53 12 Avec tout cela, la course à la mobilité est plus que jamais en marche et ce n’est pas Microsoft Plate-forme de Saint-Quentin-Fallavier Tél. -
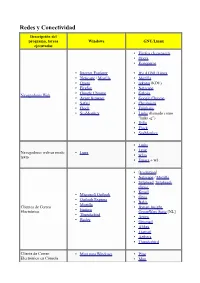
Redes Y Conectividad Descripción Del Programa, Tareas Windows GNU/Linux Ejecutadas • Firefox (Iceweasel) • Opera • Konqueror
Redes y Conectividad Descripción del programa, tareas Windows GNU/Linux ejecutadas • Firefox (Iceweasel) • Opera • Konqueror • Internet Explorer • IEs 4 GNU/Linux • Netscape / Mozilla • Mozilla • Opera • rekonq (KDE) • Firefox • Netscape • Google Chrome • Galeón Navegadores Web • Avant Browser • Google Chrome • Safari • Chromium • Flock • Epiphany • SeaMonkey • Links (llamado como "links -g") • Dillo • Flock • SeaMonkey • Links • • Lynx Navegadores web en modo Lynx • texto w3m • Emacs + w3. • [Evolution] • Netscape / Mozilla • Sylpheed , Sylpheed- claws. • Kmail • Microsoft Outlook • Gnus • Outlook Express • Balsa • Mozilla Clientes de Correo • Bynari Insight • Eudora Electrónico GroupWare Suite [NL] • Thunderbird • Arrow • Becky • Gnumail • Althea • Liamail • Aethera • Thunderbird Cliente de Correo • Mutt para Windows • Pine Electrónico en Cónsola • Mutt • Gnus • de , Pine para Windows • Elm. • Xemacs • Liferea • Knode. • Pan • Xnews , Outlook, • NewsReader Lector de noticias Netscape / Mozilla • Netscape / Mozilla. • Sylpheed / Sylpheed- claws • MultiGet • Orbit Downloader • Downloader para X. • MetaProducts Download • Caitoo (former Kget). Express • Prozilla . • Flashget • wxDownloadFast . • Go!zilla • Kget (KDE). Gestor de Descargas • Reget • Wget (console, standard). • Getright GUI: Kmago, QTget, • Wget para Windows Xget, ... • Download Accelerator Plus • Aria. • Axel. • Httrack. • WWW Offline Explorer. • Wget (consola, estándar). GUI: Kmago, QTget, Extractor de Sitios Web Teleport Pro, Webripper. Xget, ... • Downloader para X. • -
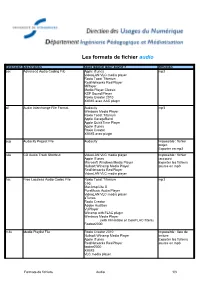
Les Formats De Fichier Audio
Les formats de fichier audio Extension Description Quel logiciel pour ouvrir ? diffusion aac Advanced Audio Coding File Apple iTunes mp3 VideoLAN VLC media player Roxio Toast Titanium RealNetworks RealPlayer MPlayer Media Player Classic KSP Sound Player Roxio Creator 2010 XMMS avec AAC plugin aif Audio Interchange File Format Audacity mp3 Windows Media Player Roxio Toast Titanium Apple GarageBand Apple QuickTime Player Apple iTunes Roxio Creator XMMS avec plugin aup Audacity Project File Audacity Impossible : fichier projet. Exporter en mp3 cda CD Audio Track Shortcut VideoLAN VLC media player Impossible : fichier Apple iTunes raccourci Microsoft Windows Media Player Exporter les fichiers Nullsoft Winamp Media Player source en mp3 RealNetworks RealPlayer VideoLAN VLC media player flac Free Lossless Audio Codec File Roxio Toast Titanium mp3 Cog MacAmp Lite X PureMusic Audio Player VideoLAN VLC media player aTunes Roxio Creator Adobe Audition VUPlayer Winamp with FLAC plugin Windows Media Player (with Illiminable or CoreFLAC filters) Foobar2000 m3u Media Playlist File Roxio Creator 2010 Impossible : liste de Nullsoft Winamp Media Player lecture. Apple iTunes Exporter les fichiers RealNetworks RealPlayer source en mp3 foobar2000 XMMS VLC media player Formats de fichiers Audio 1/3 Les formats de fichier audio Extension Description Quel logiciel pour ouvrir ? diffusion m4a Apple Lossless Audio File Roxio Toast Titanium mp3 Other music player Apple iTunes Apple QuickTime Player KSP Sound Player Microsoft Windows Media Player NCH Swift Sound -

Volume 31 August 2009
W NE Volume 31 August 2009 TTaabbllee ooff CCoonntteennttss WWeellccoommee ffrroomm tthhee CChhiieeff EEddiittoorr elcome to the August 2009 issue of The NEW PCLinuxOS Magazine. This is an W exciting time for PCLinuxOS. Not only do we have the new and revitalized magazine to look forward to every month, but there is a lot of other activity going on. Within the last month, we've seen the release of MiniMe KDE 3 2009.1, ZenMini 2009.1, and the first quarterly update in PCLinuxOS 2009.2. And there's even more just around the corner. The final release of the PCLinuxOS XFCE - Phoenix remaster from Sproggy is looming large on the horizon, complete with the latest XFCE 4.6 desktop. Additionally, Neal is wrapping up work on the LXDE remaster, while maddogf16 is hard at work on the e17 remaster. Updates to programs in the repository, as well as new additions to the repository, are coming out at an amazing rate. One of those new additions to the repository that is just around the corner is KDE 4.3 RC3. Texstar has been working feverishly to put the final touches on it, and many from the community have been assisting by testing the next generation of the KDE desktop. The addition of Pinoc's addlocale program to allow international users to use PCLinuxOS in their native language, has spurred growth in the PCLinuxOS international community, allowing PCLinuxOS to appear in any one of 73 different languages. In this issue of the magazine, we have a wide variety of articles. This month's cover story is from Texstar himself, on how to Master the Remaster. -

Apache-Ivy Wordgrinder Nethogs Qtfm Fcgi Enblend-Enfuse
eric Ted fsvs kegs ht tome wmii ttcp ess stgit nut heyu lshw 0th tiger ecl r+e vcp glfw trf sage p6f aris gq dstat vice glpk kvirc scite lyx yagf cim fdm atop slock fann G8$ fmit tkcvs pev bip vym fbida fyre yate yturl ogre owfs aide sdcv ncdu srm ack .eex ddd exim .wm ibam siege eagle xlt xclip gts .pilot atool xskat faust qucs gcal nrpe gavl tintin ruff wdfs spin wink vde+ ldns xpad qxkb kile ent gocr uae rssh gpac p0v qpdf pudb mew cc e afuse igal+ naim lurc xsel fcgi qtfm sphinx vmpk libsmi aterm lxsplit cgit librcd fuseiso squi gnugo spotify verilog kasumi pattern liboop latrace quassel gaupol firehol hydra emoc fi mo brlcad bashdb nginx d en+ xvnkb snappy gemrb bigloo sqlite+ shorten tcludp stardict rss-glx astyle yespl hatari loopy amrwb wally id3tool 3proxy d.ango cvsps cbmfs ledger beaver bsddb3 pptpd comgt x.obs abook gauche lxinput povray peg-e icecat toilet curtain gtypist hping3 clam wmdl splint fribid rope ssmtp grisbi crystal logpp ggobi ccrypt snes>x snack culmus libtirpc loemu herrie iripdb dosbox 8yro0 unhide tclvfs dtach varnish knock tracker kforth gbdfed tvtime netatop 8y,wt blake+ qmmp cgoban nexui kdesvn xrestop ifstatus xforms gtklife gmrun pwgen httrack prelink trrnt ip qlipper audiere ssdeep biew waon catdoc icecast uif+iso mirage epdfview tools meld subtle parcellite fusesmb gp+fasta alsa-tools pekwm viewnior mailman memuse hylafax= pydblite sloccount cdwrite uemacs hddtemp wxGT) adom .ulius qrencode usbmon openscap irssi!otr rss-guard psftools anacron mongodb nero-aac gem+tg gambas3 rsnapshot file-roller schedtool