Cesana D. Et Al., Supplemental Figure 1
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Old Data and Friends Improve with Age: Advancements with the Updated Tools of Genenetwork
bioRxiv preprint doi: https://doi.org/10.1101/2021.05.24.445383; this version posted May 25, 2021. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY 4.0 International license. Old data and friends improve with age: Advancements with the updated tools of GeneNetwork Alisha Chunduri1, David G. Ashbrook2 1Department of Biotechnology, Chaitanya Bharathi Institute of Technology, Hyderabad 500075, India 2Department of Genetics, Genomics and Informatics, University of Tennessee Health Science Center, Memphis, TN 38163, USA Abstract Understanding gene-by-environment interactions is important across biology, particularly behaviour. Families of isogenic strains are excellently placed, as the same genome can be tested in multiple environments. The BXD’s recent expansion to 140 strains makes them the largest family of murine isogenic genomes, and therefore give great power to detect QTL. Indefinite reproducible genometypes can be leveraged; old data can be reanalysed with emerging tools to produce novel biological insights. To highlight the importance of reanalyses, we obtained drug- and behavioural-phenotypes from Philip et al. 2010, and reanalysed their data with new genotypes from sequencing, and new models (GEMMA and R/qtl2). We discover QTL on chromosomes 3, 5, 9, 11, and 14, not found in the original study. We narrowed down the candidate genes based on their ability to alter gene expression and/or protein function, using cis-eQTL analysis, and variants predicted to be deleterious. Co-expression analysis (‘gene friends’) and human PheWAS were used to further narrow candidates. -

Apc11 (ANAPC11) (NM 001002245) Human Tagged ORF Clone Product Data
OriGene Technologies, Inc. 9620 Medical Center Drive, Ste 200 Rockville, MD 20850, US Phone: +1-888-267-4436 [email protected] EU: [email protected] CN: [email protected] Product datasheet for RC223841L4 Apc11 (ANAPC11) (NM_001002245) Human Tagged ORF Clone Product data: Product Type: Expression Plasmids Product Name: Apc11 (ANAPC11) (NM_001002245) Human Tagged ORF Clone Tag: mGFP Symbol: ANAPC11 Synonyms: APC11; Apc11p; HSPC214 Vector: pLenti-C-mGFP-P2A-Puro (PS100093) E. coli Selection: Chloramphenicol (34 ug/mL) Cell Selection: Puromycin ORF Nucleotide The ORF insert of this clone is exactly the same as(RC223841). Sequence: Restriction Sites: SgfI-MluI Cloning Scheme: ACCN: NM_001002245 ORF Size: 252 bp This product is to be used for laboratory only. Not for diagnostic or therapeutic use. View online » ©2021 OriGene Technologies, Inc., 9620 Medical Center Drive, Ste 200, Rockville, MD 20850, US 1 / 2 Apc11 (ANAPC11) (NM_001002245) Human Tagged ORF Clone – RC223841L4 OTI Disclaimer: Due to the inherent nature of this plasmid, standard methods to replicate additional amounts of DNA in E. coli are highly likely to result in mutations and/or rearrangements. Therefore, OriGene does not guarantee the capability to replicate this plasmid DNA. Additional amounts of DNA can be purchased from OriGene with batch-specific, full-sequence verification at a reduced cost. Please contact our customer care team at [email protected] or by calling 301.340.3188 option 3 for pricing and delivery. The molecular sequence of this clone aligns with the gene accession number as a point of reference only. However, individual transcript sequences of the same gene can differ through naturally occurring variations (e.g. -

4-6 Weeks Old Female C57BL/6 Mice Obtained from Jackson Labs Were Used for Cell Isolation
Methods Mice: 4-6 weeks old female C57BL/6 mice obtained from Jackson labs were used for cell isolation. Female Foxp3-IRES-GFP reporter mice (1), backcrossed to B6/C57 background for 10 generations, were used for the isolation of naïve CD4 and naïve CD8 cells for the RNAseq experiments. The mice were housed in pathogen-free animal facility in the La Jolla Institute for Allergy and Immunology and were used according to protocols approved by the Institutional Animal Care and use Committee. Preparation of cells: Subsets of thymocytes were isolated by cell sorting as previously described (2), after cell surface staining using CD4 (GK1.5), CD8 (53-6.7), CD3ε (145- 2C11), CD24 (M1/69) (all from Biolegend). DP cells: CD4+CD8 int/hi; CD4 SP cells: CD4CD3 hi, CD24 int/lo; CD8 SP cells: CD8 int/hi CD4 CD3 hi, CD24 int/lo (Fig S2). Peripheral subsets were isolated after pooling spleen and lymph nodes. T cells were enriched by negative isolation using Dynabeads (Dynabeads untouched mouse T cells, 11413D, Invitrogen). After surface staining for CD4 (GK1.5), CD8 (53-6.7), CD62L (MEL-14), CD25 (PC61) and CD44 (IM7), naïve CD4+CD62L hiCD25-CD44lo and naïve CD8+CD62L hiCD25-CD44lo were obtained by sorting (BD FACS Aria). Additionally, for the RNAseq experiments, CD4 and CD8 naïve cells were isolated by sorting T cells from the Foxp3- IRES-GFP mice: CD4+CD62LhiCD25–CD44lo GFP(FOXP3)– and CD8+CD62LhiCD25– CD44lo GFP(FOXP3)– (antibodies were from Biolegend). In some cases, naïve CD4 cells were cultured in vitro under Th1 or Th2 polarizing conditions (3, 4). -

CRAVAT 4: Cancer-Related Analysis of Variants Toolkit David L
Cancer Focus on Computer Resources Research CRAVAT 4: Cancer-Related Analysis of Variants Toolkit David L. Masica1,2, Christopher Douville1,2, Collin Tokheim1,2, Rohit Bhattacharya2,3, RyangGuk Kim4, Kyle Moad4, Michael C. Ryan4, and Rachel Karchin1,2,5 Abstract Cancer sequencing studies are increasingly comprehensive and level interpretation, including joint prioritization of all nonsilent well powered, returning long lists of somatic mutations that can be mutation consequence types, and structural and mechanistic visu- difficult to sort and interpret. Diligent analysis and quality control alization. Results from CRAVAT submissions are explored in an can require multiple computational tools of distinct utility and interactive, user-friendly web environment with dynamic filtering producing disparate output, creating additional challenges for the and sorting designed to highlight the most informative mutations, investigator. The Cancer-Related Analysis of Variants Toolkit (CRA- even in the context of very large studies. CRAVAT can be run on a VAT) is an evolving suite of informatics tools for mutation inter- public web portal, in the cloud, or downloaded for local use, and is pretation that includes mutation mapping and quality control, easily integrated with other methods for cancer omics analysis. impact prediction and extensive annotation, gene- and mutation- Cancer Res; 77(21); e35–38. Ó2017 AACR. Background quickly returning mutation interpretations in an interactive and user-friendly web environment for sorting, visualizing, and An investigator's work is far from over when results are returned inferring mechanism. CRAVAT (see Supplementary Video) is from the sequencing center. Depending on the service, genetic suitable for large studies (e.g., full-exome and large cohorts) mutation calls can require additional mapping to include all and small studies (e.g., gene panel or single patient), performs relevant RNA transcripts or correct protein sequences. -

Supplemental Information
Supplemental information Dissection of the genomic structure of the miR-183/96/182 gene. Previously, we showed that the miR-183/96/182 cluster is an intergenic miRNA cluster, located in a ~60-kb interval between the genes encoding nuclear respiratory factor-1 (Nrf1) and ubiquitin-conjugating enzyme E2H (Ube2h) on mouse chr6qA3.3 (1). To start to uncover the genomic structure of the miR- 183/96/182 gene, we first studied genomic features around miR-183/96/182 in the UCSC genome browser (http://genome.UCSC.edu/), and identified two CpG islands 3.4-6.5 kb 5’ of pre-miR-183, the most 5’ miRNA of the cluster (Fig. 1A; Fig. S1 and Seq. S1). A cDNA clone, AK044220, located at 3.2-4.6 kb 5’ to pre-miR-183, encompasses the second CpG island (Fig. 1A; Fig. S1). We hypothesized that this cDNA clone was derived from 5’ exon(s) of the primary transcript of the miR-183/96/182 gene, as CpG islands are often associated with promoters (2). Supporting this hypothesis, multiple expressed sequences detected by gene-trap clones, including clone D016D06 (3, 4), were co-localized with the cDNA clone AK044220 (Fig. 1A; Fig. S1). Clone D016D06, deposited by the German GeneTrap Consortium (GGTC) (http://tikus.gsf.de) (3, 4), was derived from insertion of a retroviral construct, rFlpROSAβgeo in 129S2 ES cells (Fig. 1A and C). The rFlpROSAβgeo construct carries a promoterless reporter gene, the β−geo cassette - an in-frame fusion of the β-galactosidase and neomycin resistance (Neor) gene (5), with a splicing acceptor (SA) immediately upstream, and a polyA signal downstream of the β−geo cassette (Fig. -

An Extensive Program of Periodic Alternative Splicing Linked to Cell
RESEARCH ARTICLE An extensive program of periodic alternative splicing linked to cell cycle progression Daniel Dominguez1,2, Yi-Hsuan Tsai1,3, Robert Weatheritt4, Yang Wang1,2, Benjamin J Blencowe4*, Zefeng Wang1,5* 1Department of Pharmacology, University of North Carolina at Chapel Hill, Chapel Hill, United States; 2Lineberger Comprehensive Cancer Center, University of North Carolina at Chapel Hill, Chapel Hill, United States; 3Program in Bioinformatics and Computational Biology, University of North Carolina at Chapel Hill, Chapel Hill, United States; 4Donnelly Centre and Department of Molecular Genetics, University of Toronto, Toronto, Canada; 5Key Lab of Computational Biology, CAS-MPG Partner Institute for Computational Biology, Chinese Academy of Science, Shanghai, China Abstract Progression through the mitotic cell cycle requires periodic regulation of gene function at the levels of transcription, translation, protein-protein interactions, post-translational modification and degradation. However, the role of alternative splicing (AS) in the temporal control of cell cycle is not well understood. By sequencing the human transcriptome through two continuous cell cycles, we identify ~ 1300 genes with cell cycle-dependent AS changes. These genes are significantly enriched in functions linked to cell cycle control, yet they do not significantly overlap genes subject to periodic changes in steady-state transcript levels. Many of the periodically spliced genes are controlled by the SR protein kinase CLK1, whose level undergoes cell cycle- dependent fluctuations via an auto-inhibitory circuit. Disruption of CLK1 causes pleiotropic cell cycle defects and loss of proliferation, whereas CLK1 over-expression is associated with various *For correspondence: cancers. These results thus reveal a large program of CLK1-regulated periodic AS intimately [email protected] (BJB); associated with cell cycle control. -

Molecular Genetics of Microcephaly Primary Hereditary: an Overview
brain sciences Review Molecular Genetics of Microcephaly Primary Hereditary: An Overview Nikistratos Siskos † , Electra Stylianopoulou †, Georgios Skavdis and Maria E. Grigoriou * Department of Molecular Biology & Genetics, Democritus University of Thrace, 68100 Alexandroupolis, Greece; [email protected] (N.S.); [email protected] (E.S.); [email protected] (G.S.) * Correspondence: [email protected] † Equal contribution. Abstract: MicroCephaly Primary Hereditary (MCPH) is a rare congenital neurodevelopmental disorder characterized by a significant reduction of the occipitofrontal head circumference and mild to moderate mental disability. Patients have small brains, though with overall normal architecture; therefore, studying MCPH can reveal not only the pathological mechanisms leading to this condition, but also the mechanisms operating during normal development. MCPH is genetically heterogeneous, with 27 genes listed so far in the Online Mendelian Inheritance in Man (OMIM) database. In this review, we discuss the role of MCPH proteins and delineate the molecular mechanisms and common pathways in which they participate. Keywords: microcephaly; MCPH; MCPH1–MCPH27; molecular genetics; cell cycle 1. Introduction Citation: Siskos, N.; Stylianopoulou, Microcephaly, from the Greek word µικρoκεϕαλi´α (mikrokephalia), meaning small E.; Skavdis, G.; Grigoriou, M.E. head, is a term used to describe a cranium with reduction of the occipitofrontal head circum- Molecular Genetics of Microcephaly ference equal, or more that teo standard deviations -

Viewed Graphically with a Java Graphical User Interface (GUI), Allowing Users to Evaluate Contig Sequence Quality and Predict Snps
BMC Research Notes BioMed Central Short Report Open Access BEAP: The BLAST Extension and Alignment Program- a tool for contig construction and analysis of preliminary genome sequence James E Koltes†, Zhi-Liang Hu†, Eric Fritz and James M Reecy* Address: Department of Animal Science, Iowa State University, Ames, Iowa 50011-3150, USA Email: James E Koltes - [email protected]; Zhi-Liang Hu - [email protected]; Eric Fritz - [email protected]; James M Reecy* - [email protected] * Corresponding author †Equal contributors Published: 22 January 2009 Received: 29 October 2008 Accepted: 22 January 2009 BMC Research Notes 2009, 2:11 doi:10.1186/1756-0500-2-11 This article is available from: http://www.biomedcentral.com/1756-0500/2/11 © 2009 Reecy et al; licensee BioMed Central Ltd. This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. Abstract Background: Fine-mapping projects require a high density of SNP markers and positional candidate gene sequences. In species with incomplete genomic sequence, the DNA sequences needed to generate markers for fine-mapping within a linkage analysis confidence interval may be available but may not have been assembled. To manually piece these sequences together is laborious and costly. Moreover, annotation and assembly of short, incomplete DNA sequences is time consuming and not always straightforward. Findings: We have created a tool called BEAP that combines BLAST and CAP3 to retrieve sequences and construct contigs for localized genomic regions in species with unfinished sequence drafts. -

Gene Co-Expression Network Mining Using Graph Sparsification
Gene Co-expression Network Mining Using Graph Sparsification THESIS Presented in Partial Fulfillment of the Requirements for the Degree Master of Science in the Graduate School of The Ohio State University By Jinchao Di Graduate Program in Electrical and Computer Engineering The Ohio State University 2013 Master’s Examination Committee: Dr. Kun Huang, Advisor Dr. Raghu Machiraju Dr. Yuejie Chi ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! Copyright by Jinchao Di 2013 ! ! Abstract Identifying and analyzing gene modules is important since it can help understand gene function globally and reveal the underlying molecular mechanism. In this thesis, we propose a method combining local graph sparsification and a gene similarity measurement method TOM. This method can detect gene modules from a weighted gene co-expression network more e↵ectively since we set a local threshold which can detect clusters with di↵erent densities. In our algorithm, we only retain one edge for each gene, which can generate more balanced gene clusters. To estimate the e↵ectiveness of our algorithm we use DAVID to functionally evaluate the gene list for each module we detect and compare our results with some well known algorithms. The result of our algorithm shows better biological relevance than the compared methods and the number of the meaningful biological clusters is much larger than other methods, implying we discover some previously missed gene clusters. Moreover, we carry out a robustness test by adding Gaussian noise with di↵erent variance to the expression data. We find that our algorithm is robust to noise. We also find that some hub genes considered as important genes could be artifacts. -

A Master Autoantigen-Ome Links Alternative Splicing, Female Predilection, and COVID-19 to Autoimmune Diseases
bioRxiv preprint doi: https://doi.org/10.1101/2021.07.30.454526; this version posted August 4, 2021. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY 4.0 International license. A Master Autoantigen-ome Links Alternative Splicing, Female Predilection, and COVID-19 to Autoimmune Diseases Julia Y. Wang1*, Michael W. Roehrl1, Victor B. Roehrl1, and Michael H. Roehrl2* 1 Curandis, New York, USA 2 Department of Pathology, Memorial Sloan Kettering Cancer Center, New York, USA * Correspondence: [email protected] or [email protected] 1 bioRxiv preprint doi: https://doi.org/10.1101/2021.07.30.454526; this version posted August 4, 2021. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY 4.0 International license. Abstract Chronic and debilitating autoimmune sequelae pose a grave concern for the post-COVID-19 pandemic era. Based on our discovery that the glycosaminoglycan dermatan sulfate (DS) displays peculiar affinity to apoptotic cells and autoantigens (autoAgs) and that DS-autoAg complexes cooperatively stimulate autoreactive B1 cell responses, we compiled a database of 751 candidate autoAgs from six human cell types. At least 657 of these have been found to be affected by SARS-CoV-2 infection based on currently available multi-omic COVID data, and at least 400 are confirmed targets of autoantibodies in a wide array of autoimmune diseases and cancer. -

S41467-019-10037-Y.Pdf
ARTICLE https://doi.org/10.1038/s41467-019-10037-y OPEN Feedback inhibition of cAMP effector signaling by a chaperone-assisted ubiquitin system Laura Rinaldi1, Rossella Delle Donne1, Bruno Catalanotti 2, Omar Torres-Quesada3, Florian Enzler3, Federica Moraca 4, Robert Nisticò5, Francesco Chiuso1, Sonia Piccinin5, Verena Bachmann3, Herbert H Lindner6, Corrado Garbi1, Antonella Scorziello7, Nicola Antonino Russo8, Matthis Synofzik9, Ulrich Stelzl 10, Lucio Annunziato11, Eduard Stefan 3 & Antonio Feliciello1 1234567890():,; Activation of G-protein coupled receptors elevates cAMP levels promoting dissociation of protein kinase A (PKA) holoenzymes and release of catalytic subunits (PKAc). This results in PKAc-mediated phosphorylation of compartmentalized substrates that control central aspects of cell physiology. The mechanism of PKAc activation and signaling have been largely characterized. However, the modes of PKAc inactivation by regulated proteolysis were unknown. Here, we identify a regulatory mechanism that precisely tunes PKAc stability and downstream signaling. Following agonist stimulation, the recruitment of the chaperone- bound E3 ligase CHIP promotes ubiquitylation and proteolysis of PKAc, thus attenuating cAMP signaling. Genetic inactivation of CHIP or pharmacological inhibition of HSP70 enhances PKAc signaling and sustains hippocampal long-term potentiation. Interestingly, primary fibroblasts from autosomal recessive spinocerebellar ataxia 16 (SCAR16) patients carrying germline inactivating mutations of CHIP show a dramatic dysregulation of PKA signaling. This suggests the existence of a negative feedback mechanism for restricting hormonally controlled PKA activities. 1 Department of Molecular Medicine and Medical Biotechnologies, University Federico II, 80131 Naples, Italy. 2 Department of Pharmacy, University Federico II, 80131 Naples, Italy. 3 Institute of Biochemistry and Center for Molecular Biosciences, University of Innsbruck, A-6020 Innsbruck, Austria. -
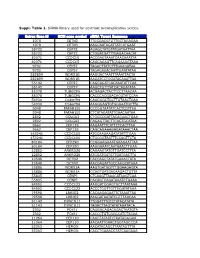
Suppl. Table 1
Suppl. Table 1. SiRNA library used for centriole overduplication screen. Entrez Gene Id NCBI gene symbol siRNA Target Sequence 1070 CETN3 TTGCGACGTGTTGCTAGAGAA 1070 CETN3 AAGCAATAGATTATCATGAAT 55722 CEP72 AGAGCTATGTATGATAATTAA 55722 CEP72 CTGGATGATTTGAGACAACAT 80071 CCDC15 ACCGAGTAAATCAACAAATTA 80071 CCDC15 CAGCAGAGTTCAGAAAGTAAA 9702 CEP57 TAGACTTATCTTTGAAGATAA 9702 CEP57 TAGAGAAACAATTGAATATAA 282809 WDR51B AAGGACTAATTTAAATTACTA 282809 WDR51B AAGATCCTGGATACAAATTAA 55142 CEP27 CAGCAGATCACAAATATTCAA 55142 CEP27 AAGCTGTTTATCACAGATATA 85378 TUBGCP6 ACGAGACTACTTCCTTAACAA 85378 TUBGCP6 CACCCACGGACACGTATCCAA 54930 C14orf94 CAGCGGCTGCTTGTAACTGAA 54930 C14orf94 AAGGGAGTGTGGAAATGCTTA 5048 PAFAH1B1 CCCGGTAATATCACTCGTTAA 5048 PAFAH1B1 CTCATAGATATTGAACAATAA 2802 GOLGA3 CTGGCCGATTACAGAACTGAA 2802 GOLGA3 CAGAGTTACTTCAGTGCATAA 9662 CEP135 AAGAATTTCATTCTCACTTAA 9662 CEP135 CAGCAGAAAGAGATAAACTAA 153241 CCDC100 ATGCAAGAAGATATATTTGAA 153241 CCDC100 CTGCGGTAATTTCCAGTTCTA 80184 CEP290 CCGGAAGAAATGAAGAATTAA 80184 CEP290 AAGGAAATCAATAAACTTGAA 22852 ANKRD26 CAGAAGTATGTTGATCCTTTA 22852 ANKRD26 ATGGATGATGTTGATGACTTA 10540 DCTN2 CACCAGCTATATGAAACTATA 10540 DCTN2 AACGAGATTGCCAAGCATAAA 25886 WDR51A AAGTGATGGTTTGGAAGAGTA 25886 WDR51A CCAGTGATGACAAGACTGTTA 55835 CENPJ CTCAAGTTAAACATAAGTCAA 55835 CENPJ CACAGTCAGATAAATCTGAAA 84902 CCDC123 AAGGATGGAGTGCTTAATAAA 84902 CCDC123 ACCCTGGTTGTTGGATATAAA 79598 LRRIQ2 CACAAGAGAATTCTAAATTAA 79598 LRRIQ2 AAGGATAATATCGTTTAACAA 51143 DYNC1LI1 TTGGATTTGTCTATACATATA 51143 DYNC1LI1 TAGACTTAGTATATAAATACA 2302 FOXJ1 CAGGACAGACAGACTAATGTA