Recognising Cursive Arabic Text Using a Speech Recognition System M S Khorsheed
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Cloud Fonts in Microsoft Office
APRIL 2019 Guide to Cloud Fonts in Microsoft® Office 365® Cloud fonts are available to Office 365 subscribers on all platforms and devices. Documents that use cloud fonts will render correctly in Office 2019. Embed cloud fonts for use with older versions of Office. Reference article from Microsoft: Cloud fonts in Office DESIGN TO PRESENT Terberg Design, LLC Index MICROSOFT OFFICE CLOUD FONTS A B C D E Legend: Good choice for theme body fonts F G H I J Okay choice for theme body fonts Includes serif typefaces, K L M N O non-lining figures, and those missing italic and/or bold styles P R S T U Present with most older versions of Office, embedding not required V W Symbol fonts Language-specific fonts MICROSOFT OFFICE CLOUD FONTS Abadi NEW ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz 01234567890 Abadi Extra Light ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz 01234567890 Note: No italic or bold styles provided. Agency FB MICROSOFT OFFICE CLOUD FONTS ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz 01234567890 Agency FB Bold ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz 01234567890 Note: No italic style provided Algerian MICROSOFT OFFICE CLOUD FONTS ABCDEFGHIJKLMNOPQRSTUVWXYZ 01234567890 Note: Uppercase only. No other styles provided. Arial MICROSOFT OFFICE CLOUD FONTS ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz 01234567890 Arial Italic ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz 01234567890 Arial Bold ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz 01234567890 Arial Bold Italic ABCDEFGHIJKLMNOPQRSTUVWXYZ -

Basic Sans Serif 7 Font Family Free Download Basic Sans Serif 7 Font
basic sans serif 7 font family free download Basic Sans Serif 7 Font. Use the text generator tool below to preview Basic Sans Serif 7 font, and create appealing text graphics with different colors and hundreds of text effects. Font Tags. Search. :: You Might Like. About. Font Meme is a fonts & typography resource. The "Fonts in Use" section features posts about fonts used in logos, films, TV shows, video games, books and more; The "Text Generator" section features simple tools that let you create graphics with fonts of different styles as well as various text effects; The "Font Collection" section is the place where you can browse, filter, custom preview and download free fonts. Microsoft Sans Serif font family. Microsoft Sans Serif font is a very legible User Interface (UI) font. It was designed to be metrically compatible with the MS Sans bitmap font that shipped in early versions of Microsoft Windows. File name Micross.ttf Styles & Weights Microsoft Sans Serif Designers N/A Copyright © 2012 Microsoft Corporation. All Rights Reserved. Font vendor Microsoft Corp. Script Tags dlng:'Armn', 'Cyrl', 'Geor', 'Grek', 'Latn' slng:'Arab', 'Armn', 'Cyrl', 'Geor', 'Grek', 'Hebr', 'Latn', 'Thai' Code pages 1252 Latin 1 1250 Latin 2: Eastern Europe 1251 Cyrillic 1253 Greek 1254 Turkish 1255 Hebrew 1256 Arabic 1257 Windows Baltic 1258 Vietnamese 874 Thai Mac Roman Macintosh Character Set (US Roman) 862 Hebrew 860 MS-DOS Portuguese 437 US Fixed pitch False. Licensing and redistribution info. Font redistribution FAQ for Windows License Microsoft fonts for enterprises, web developers, for hardware & software redistribution or server installations. -

Tutorial: Changing Languages (Localization)
L O Tutorial C A L I Z A T Changing Languages I O N (Localization) in the TNT Products Changing Languages (Localization) Before Getting Started This booklet surveys the steps necessary to localize the TNT products. Micro- Images has worked hard to internationalize the TNT products so that they may be localized for any country, culture, and language. MicroImages does not cre- ate translated versions of the TNT products, but it does supply the means so that those who have enrolled as Official Translators can create a localization. A local- ization can use any font, so that none of the original English words or Latin characters remain. Alternatively, an Official Translator may choose a less ambi- tious level of localization and translate only selected interface elements, leaving the rest in English. As an Official Translator, your localization efforts can put you into a unique leadership position in your country. Contact MicroImages for de- tails of the Official Translator agreement. Prerequisites To implement a TNT Products localization, you must • enroll with MicroImages, Inc. as the Official Translator for your language, • be a skilled computer user who is comfortable with both the English version of TNT and the target language for your locale, and • be familiar with the TNT processes, since your localization task includes finding linguistic and conceptual equivalents for all interface text, messages, and documentation. MicroImages encourages you in your localization efforts. Already the growing list of completed localized versions has made the TNT products ever more widely accepted around the world. The Locale A Locale is defined by the textres file that contains all the informa- tion needed for a specific translation so that all the text in the TNT interface appears in another language. -

Using International Characters in Bartender How to Read Data and Print Characters from Almost Every Language and Writing System in the World
Using International Characters in BarTender How to Read Data and Print Characters from Almost Every Language and Writing System in the World Supports the following BarTender software versions: BarTender 2016, BarTender 2019 WHITE PAPER Contents Overview 3 BarTender's Unicode Support 3 Understanding International Character Support 4 Fonts 4 Scripts 4 Asian Characters 5 Writing Systems that Read Right to Left 5 Entering International Text Into Text Objects 7 Using the Insert Symbols or Special Characters Dialog 7 Using the Windows Character Map 7 Using the Keyboard 8 Reading International Characters from a Database 9 Encoding International Characters in Barcodes 10 Using Unicode Data 10 ECI Protocol 11 Formatting According to Locale 12 About Data Types 12 Example 12 Appendix A: Languages, Encodings and Scripts 13 Appendix B: Configuring Windows 14 Installing Windows Input Support for International Languages 14 Windows Support for Additional Display Languages 15 Related Documentation 16 Overview With the built-in international character support that BarTender provides, you can add international characters to your design and encode them into barcodes or RFID tags on your template. When you design items for a single locale, you can configure the format (or appearance) of information that may vary between regions, such as date and time, currency, numbering, and so on. By using BarTender, you can also globalize your design and print international materials by inserting text in multiple languages. For example, the following item illustrates how BarTender can be used with many locales with its built-in Unicode support. BarTender's Unicode Support Unicode is a universal character encoding standard that defines the basis for the processing, storage and interchange of text data in any language. -

Getting Your Project Working
C1061587x.fm Page 197 Friday, November 16, 2001 8:43 AM Part III Getting Your Project Working 10 Ten Common Upgrade Problems 199 11 Resolving Issues with Language 223 12 Resolving Issues with Forms 265 13 Upgrading ActiveX Controls and Components 285 14 Resolving Data Access Issues 305 15 Problems That Require Redesign 323 16 Upgrading COM+ Components 347 17 Upgrading VB Application Wizard Projects 365 C1061587x.fm Page 198 Friday, November 16, 2001 8:43 AM C1061587x.fm Page 199 Friday, November 16, 2001 8:43 AM Ten Common Upgrade Problems Chapter 4 looked at common issues with Microsoft Visual Basic 6 code and dis- cussed how you could resolve them before upgrading. This chapter also focuses on resolving common upgrade issues—but this time we look at the issues found after the wizard has finished upgrading your project. To this end, we describe ten very common upgrade problems and how to fix them. Some of these problems are due to language differences and new control behaviors. Others are related to the different run-time behavior of the .NET Framework. You’ll learn how to avoid these issues in the first place and how to resolve them if you encounter them after you begin upgrading. You’ll also find sample appli- cations on the companion CD that illustrate some of the situations discussed here. Default Properties Default properties are no longer supported in the common language runtime. If the Upgrade Wizard can determine a default property, it will properly modify your code to state the property explicitly in Visual Basic .NET. -

Font Management Basic Terminology ∞ I
CS 175.21 Windsor Green Spring 2010 Font Management Basic Terminology ∞ I. Font Definition∞ A. Strictly speaking the contents of the two cases - upper and lower - in metal type (for one size) B. Nowadays, the word font means all the glyphs (symbols) for a font in all sizes. Examples; Century, Fritz Quadrata, Myriad, , Giddyup, Gill Sans Ultra Bold Bickham Script C. The term typeface is interchangeable with font in today’s modern computer world A. Myriad Italic D. All the variations for a font is called a font family — B. Myria Regular this includes different weights (thicknesses like bold and light) and glyph widths (condensed and extended). C. Myriad Light II. Acquiring Fonts D. Myriad Bold A. Computer fonts: postscript, True type and Open Type E. Myriad SemiboldCondesed B. Font foundries: companies that create fonts F. Myriad Semibold Italic C. Special system fonts: Microsoft has special TT fonts used in the Windows OS Apple has special TT fonts used in their OS and dfonts. D. Application fonts: Microsoft auto installs numerous True type fonts during Office installation Adobe auto installs numerous OpenType fonts during Adobe CS installation E. Purchased fonts 1. Adobe (no longer creates new PostScript fonts but supports them — the focus is now on Open Type fonts) 2. High end fonts for home use and professional printing: OpenType and PostScript 3. Be careful buying fonts! The same typeface is sometimes available from different foundries. 4. Some websites where you can purchase fonts and where foundries are listed. fonts.com myfonts.com philsfonts.com Page 1 5. Some Foundries linotype.com itcfonts.com bertholdtype.com adobe.com/type Licensing agreements for purchased fonts — how can you legally use a font? 6. -

Towards Lucida Opentype Afm2tfm
TUGboat, Volume 32 (2011), No. 2 169 Another incarnation of Lucida: now be set up for use with TEX using fontinst or Towards Lucida OpenType afm2tfm. This development continued when PDFTEX was Ulrik Vieth and Mojca Miklavec developed and on-screen viewing of PDF files came Abstract into common use in the late 1990s. While the use of METAFONT-generated bitmap TEX has been in existence for more than 30 years. fonts packaged into Type 3 fonts was still acceptable During this time, TEX engines and device drivers for printing, such bitmap fonts turned out to be in- have gone through multiple generations of font tech- adequate for screen rendering in PDF viewers. As a nology: METAFONT, PostScript Type 1, and Open- result, the use of METAFONT fonts became unpop- Type. While choices for text fonts have greatly in- ular, and efforts were undertaken to provide Type 1 creased, there have always been few choices for math replacements for METAFONT fonts. fonts and even fewer for complete font families. In this era, choices of text fonts were increased The Lucida family of typefaces by Bigelow & significantly, but choices of math fonts remained lim- Holmes is a notable exception, as it provides not ited. Besides CM and AMS Euler, converted from only a math font, but also a complete font family, METAFONT, there were only the commercial offer- consisting of a large repertoire of serif, sans-serif, ings of MathTime and Lucida New Math at first. monospace, and fancy variants. Unfortunately, the It was only much later in this era that more current distribution of Lucida fonts dates back to choices of math fonts eventually became available, 1993 and is limited by the use of PostScript Type 1 such as txfonts, pxfonts, mathpazo, fourier, and fonts, which support only 8-bit character sets. -

Sans-Serif Download Free Sans-Serif Download Free
sans-serif download free Sans-serif download free. Completing the CAPTCHA proves you are a human and gives you temporary access to the web property. What can I do to prevent this in the future? If you are on a personal connection, like at home, you can run an anti-virus scan on your device to make sure it is not infected with malware. If you are at an office or shared network, you can ask the network administrator to run a scan across the network looking for misconfigured or infected devices. Another way to prevent getting this page in the future is to use Privacy Pass. You may need to download version 2.0 now from the Chrome Web Store. Cloudflare Ray ID: 66c5fe455a15c433 • Your IP : 188.246.226.140 • Performance & security by Cloudflare. Microsoft Sans Serif font family. Microsoft Sans Serif font is a very legible User Interface (UI) font. It was designed to be metrically compatible with the MS Sans bitmap font that shipped in early versions of Microsoft Windows. File name Micross.ttf Styles & Weights Microsoft Sans Serif Designers N/A Copyright © 2012 Microsoft Corporation. All Rights Reserved. Font vendor Microsoft Corp. Script Tags dlng:'Armn', 'Cyrl', 'Geor', 'Grek', 'Latn' slng:'Arab', 'Armn', 'Cyrl', 'Geor', 'Grek', 'Hebr', 'Latn', 'Thai' Code pages 1252 Latin 1 1250 Latin 2: Eastern Europe 1251 Cyrillic 1253 Greek 1254 Turkish 1255 Hebrew 1256 Arabic 1257 Windows Baltic 1258 Vietnamese 874 Thai Mac Roman Macintosh Character Set (US Roman) 862 Hebrew 860 MS-DOS Portuguese 437 US Fixed pitch False. Licensing and redistribution info. -

Essential NFSS2, Version 2 Default Typeface in a Document Had Three Choices: 1
TUGboat, Volume 14 (1993), No. 2 for use (a greater choice of METAFONT sources, and Tutorials the ubiquitous Postscript fonts), this area has been a bottleneck in the use of I4win general typeset- ting. The user who wanted Times Roman as the Essential NFSS2, version 2 default typeface in a document had three choices: 1. To load many new fonts with the newf ont com- Sebastian Rahtz mand, and use them explicitly; Abstract 2. To heavily edit the file If onts.tex and build a This article offers a user's view of the New Font Se- new version of I4'; or lection Scheme, version 2. It describes the reasons 3. To take large chunks out of 1fonts.tex and for using the NFSS; the differences a user will en- replicate their effect in a style file. counter between NFSS and old IP'; what it will Other style files were written to specifically imple- be like installing and using NFSS2; some special sit- ment features like bold sans-serif; but an altogether uations in mathematics; and an overview of the ad- more general solution was needed, and this was met vanced NFSS2 commands for describing new fonts. in 1989 with the New Font Selection Scheme, which was subsequently also used in AM-IP'. The 1 Introduction NFSS is a complete replacement for If onts . tex; it TEX has a very general model of using different type- contains a generic concept for varying font attributes faces; all it needs is to have a set of metric informa- individually and integrating new font families easily tion for each font, and it leaves the actual setting into I4W. -

Web Font Combinations Cheat Sheet
BRAND TM BIGSYSTEM Web Font Combinations Cheat Sheet Confused about which typeface families work well together? This cheat sheet provides font combinations three different ways: 1. Web standard fonts that everyone has on their systems* 2. Google Font API, a free service* 3. Typekit, a paid font service by Adobe * Want to check to see how system and Google font combinations look on a web page and see them at different sizes? Try the handy Web Font Combinator tool: http://font-combinator.com/ Web Standard Font Combinations The combinations below can be implemented immediately: they use web standard fonts that are already installed on your computer, and the computer of anyone who visits your site. Arial Black for Headlines Georgia for text. This is sample text so you can see what the font looks like in para- graph form. Is it readable? This is sample text so you can see what the font looks like in paragraph form. Is it readable? This is sample text so you can see what the font looks like in paragraph form. Is it readable? Impact for Headlines Times New Roman for text. This is sample text so you can see what the font looks like in paragraph form. Is it readable? This is sample text so you can see what the font looks like in paragraph form. Is it readable? This is sample text so you can see what the font looks like in paragraph form. Is it readable? ©BigBrandSystem.com 1 BRAND TM BIGSYSTEM Web Standard Font Combinations, continued Trebuchet Bold for Headlines Trebuchet for text. -
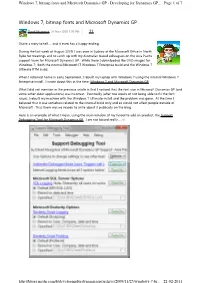
Windows 7, Bitmap Fonts and Microsoft Dynamics GP - Developing for Dynamics GP
Windows 7, bitmap fonts and Microsoft Dynamics GP - Developing for Dynamics GP ... Page 1 of 7 Windows 7, bitmap fonts and Microsoft Dynamics GP David Musgrave 24 Nov 2009 5:00 PM 21 I have a story to tell..... and it even has a happy ending. During the last week of August 2009, I was over in Sydney at the Microsoft Office in North Ryde for meetings and to catch up with my Australian based colleagues on the Asia Pacific support team for Microsoft Dynamics GP. While there I downloaded the DVD images for Windows 7; both the internal Microsoft IT Windows 7 Enterprise build and the Windows 7 Ultimate RTM build. When I returned home in early September, I rebuilt my laptop with Windows 7 using the internal Windows 7 Enterprise install. I wrote about this at the time: Windows 7 and Microsoft Dynamics GP. What I did not mention in the previous article is that I noticed that the font size in Microsoft Dynamics GP (and some other older applications) was incorrect. Eventually (after two weeks of not being able to fix the font issue), I rebuilt my machine with the Windows 7 Ultimate install and the problem was gone. At the time I believed that it was somehow related to the internal build only and so would not affect people outside of Microsoft. Thus there was no reason to write about it publically on the blog. Here is an example of what I mean, using the main window of my favourite add on product, the Support Debugging Tool for Microsoft Dynamics GP. -

Fonts for the Web
Fonts for the Web Until font downloading technology is perfected, Web designers must normally restrict themselves to fonts that are available on most users’ computer systems. So which fonts are installed on everyone’s computers? Your best bets are the ones that come with the Internet Explorer (MSIE) browser and the Windows and Macintosh operating systems. For the last few years, the MSIE fonts have been installed on every new Windows and Macintosh PC, so they are your best “cross-platform” bet. Font Platform CSS info [Bold, Italic] Originally named Monotype.com font-family: "Andale Mono", MSIE "Monotype.com", monospace Also named Zapf Chancery on older Macs (and some Win PCs). font-family: Mac "Apple Chancery", "Zapf Chancery", cursive [Bold, Italic] Very similar to Helvetica. font-family: Arial, Helvetica, MSIE sans-serif Less common than Arial. Do not use it with a bold font-weight; it’s bold enough already! MSIE font-family: "Arial Black", sans-serif Not on pre-1999 Macs font-family: Capitals, serif Mac Mac system font (for menus, dialog boxes, etc.) since 1999. It will be very familiar to Mac users at 12 points, but also works well in headlines (without bold). Mac font- family: Charcoal, Chicago, sans-serif [Italic] Former Mac system font, replaced by Charcoal. Still present on every Mac ever made. Mac font-family: Chicago, Charcoal, sans-serif [Bold, Italic] An informal font designed to be easily legible on screen. Believe it or not, this is the default cursive font for Internet Explorer. MSIE font-family: "Comic Sans MS", cursive [Bold, Italic] Courier is the most common monospace (typewriter-style) font.