Wikipedia Subcorpora Tool (Wist) a Tool for Creating Customized Document Collections for Training Unsupervised Models of Lexical Semantics
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Military Law Review, Volume 227, Issue 3, 2019
Volume 227 Issue 3 2019 ACADEMIC JOURNAL 27-100-227-3 Mංඅංඍൺඋඒ Lൺඐ Rൾඏංൾඐ Aඋඍංർඅൾඌ Fൾൾඅංඇ Sඈ Fඅඒ Lංൾ ൺ C12 (ඈඋ Mൺඒൻൾ ൺ UC35, Dൾඉൾඇൽංඇ ඈඇ Aඏൺංඅൺൻංඅංඍඒ): A Pඋංආൾඋ MILITARY LAW REVIEW LAW MILITARY ඈඇ Uඍංඅංඓංඇ MILAIR ൿඈඋ Oൿൿංർංൺඅ Tඋൺඏൾඅ Major Joshua J. Tooman Kൾൾඉංඇ Cඈආආංඍආൾඇඍඌ: A Bൺඅൺඇർൾൽ Aඉඉඋඈൺർඁ ඍඈ Tൾඋආංඇൺඍංඈඇ ൿඈඋ Cඈඇඏൾඇංൾඇർൾ Major Justin Hess Sඎൻඌඍൺඇඍංඏൾ Tൾർඁඇංർൺඅංඍංൾඌ: Uඇൽൾඋඌඍൺඇൽංඇ ඍඁൾ Lൾൺඅ Fඋൺආൾඐඈඋ ඈൿ Hඎආൺඇංඍൺඋංൺඇ Aඌඌංඌඍൺඇർൾ ංඇ Aඋආൾൽ Cඈඇൿඅංർඍඌ Tඁඋඈඎඁ ඍඁൾ Pඋൾඌർඋංඉඍංඈඇ ඈൿ Tൾർඁඇංർൺඅ Aඋඋൺඇൾආൾඇඍඌ Major Tzvi Mintz Aඎඌඍඋൺඅංൺ’ඌ Wൺඋ Cඋංආൾ Tඋංൺඅඌ 1945-51 VOLUME 227 • 2019 Reviewed by Fred L. Borch III Academic Journal 27-100-227-3 Military Law Review Volume 227 Issue 3 2019 CONTENTS Articles Feeling So Fly Like a C12 (or Maybe a UC35, Depending on Availability): A Primer on Utilizing MILAIR for Official Travel Major Joshua J. Tooman 219 Keeping Commitments: A Balanced Approach to Termination for Convenience Major Justin Hess 252 Substantive Technicalities: Understanding the Legal Framework of Humanitarian Assistance in Armed Conflicts Through the Prescription of Technical Arrangements Major Tzvi Mintz 275 Australia’s War Crimes Trials 1945-51 Reviewed by Fred L. Borch III 320 i Headquarters, Department of the Army, Washington, D.C. Academic Journal No. 27-100-227-3, 2019 Military Law Review Volume 227 Issue 3 Board of Editors Colonel Randolph Swansiger Dean, The Judge Advocate General’s School Lieutenant Colonel Edward C. -

Guantanamo Bay and the Conflict of Ethical Lawyering
Volume 117 Issue 2 Dickinson Law Review - Volume 117, 2012-2013 10-1-2012 Guantanamo Bay and the Conflict of Ethical Lawyering Dana Carver Boehm Follow this and additional works at: https://ideas.dickinsonlaw.psu.edu/dlra Recommended Citation Dana C. Boehm, Guantanamo Bay and the Conflict of Ethical Lawyering, 117 DICK. L. REV. 283 (2012). Available at: https://ideas.dickinsonlaw.psu.edu/dlra/vol117/iss2/2 This Article is brought to you for free and open access by the Law Reviews at Dickinson Law IDEAS. It has been accepted for inclusion in Dickinson Law Review by an authorized editor of Dickinson Law IDEAS. For more information, please contact [email protected]. I Articles I Guantanamo Bay and the Conflict of Ethical Lawyering Dana Carver Boehm* ABSTRACT The Guantanamo Bay military commissions have been the subject of intense national and international debate since they were announced months after the September 1 lth attacks. This important debate largely has focused on the perennial tension between liberty and security on the one hand and the somewhat technical legal questions regarding the constitutionality of prescribed procedures on the other. As significant as these issues are, the discussion generally has ignored an element of the military commissions that profoundly shapes how national security, civil liberties, and the experience of criminal justice actually occurs: the way that lawyers charged with prosecuting and defending these cases pursue their professional duties as lawyers. This Article considers the unique institutional identities, organizational context, ethical obligations, and professional incentives of * Dean's Scholar and Visiting Researcher, Center on National Security and the Law, Georgetown University Law Center. -
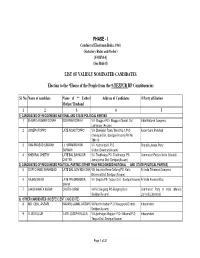
List of Validly Nominated Candidate Phase
PHASE - I Conduct of Electiomn Rules, 1961 (Statutory Rules and Order) [FORM 4] (See Rule 8) LIST OF VALIDLY NOMINATED CANDIDATES Election to the *House of the People from the 9-TEZPUR HP Constituencies Sl. No. Name of candidate Name of ** Father/ Address of Candidates @Party affiliation Mother/ Husband 1 2 3 4 5 1) CANDIDATES OF RECOGNISED NATIONAL AND STATE POLITICAL PARTIES 1 BHUPEN KUMAR BORAH BOGIRAM BORAH Vill- Bhogpur PO:- Bhogpur Chariali Dist. India National Congress Lakhimpur (Assam) 2 JOSEPH TOPPO LATE NOAS TOPPO Vill- Dhekiajuli Town, Ward No.1, P.O- Asom Gana Parishad Dhekiajuli Dist.-Sonitpur(Assam) Pin No. 784110 3 RAM PRASAD SARMAH Lt. HARINARAYAN Vill- Kacharibasti, P.O - Bharatia Janata Party SARMAH Ulubari,Guwahati(Assam) 4 KHEMRAJ CHETRY LATE BAL BAHADUR Vill- Toubhanga PO- Toubhanga PS- Communist Party of India (Marxist) CHETRY Jamugurihat Dist: Sonitpur(Assam) 2) CANDIDATES OF RECOGNISED POLITICAL PARTIES (OTHER THAN RECOGNISED NATIONAL AND STATE POLITICAL PARTIES) 5 GOPI CHAND SHAHABADI LATE BAL GOVINDA SHA Vill- Industrial Area Gotlong PO- Kalia All India Trinamool Congress Bhomora Dist. Sonitpur (Assam) 6 RAJEN SAIKIA LATE PREMANANDA Vill- Depota PS- Tezpur Dist.- Sonitpur(Assam) All India Forward Bloc SAIKIA 7 LAKSHIKANTA KURMI CHUTU KURMI Vill-NC Bargang PO-Bargang Dist.- Communist Party of India (Marxist- Sonitpur(Assam) Laninst)(Liberation) 3) OTHER CANDIDATES (INDEPENDENT CANDIDATE) 8 MD. IQBAL ANSARI KAMARU JAMAL ANSARI Vill-Medhi chuburi P.O-Rangapara District- Independent Sonitpur(Assam) 9 ELIAS KUJUR LATE JOSEPH KUJUR Vill-Jyotinagar Majgaon P.O- Nilkamal P.S- Independent Tezpur Dist. Sonitpur(Assam) Page 1 of 21 Sl. -

Vernon A. Walters: Pathfinder of the Intelligence Profession
Joint Military Intelligence College April 1998 VERNON A. WALTERS: PATHFINDER OF THE INTELLIGENCE PROFESSION Conference Proceedings 3 June 2004 TEL IN LIG Y E R N A C T E I L C I O M L L T E N G I E O J 1962 PCN 54821 Remarks by employees of the Department of Defense have been approved for public release by the Office of Freedom of Information and Security Review, Washington Headquarters Services. The editor wishes to thank Christopher Roberts, Intelligence Community Scholar at the Joint Military Intelligence College, for his proficient work in preliminary editing of these proceedings. [email protected], Editor and Director, Center for Strategic Intelligence Research 54821pref.fm5 Page i Tuesday, December 28, 2004 3:33 PM Conference Proceedings 3 June 2004 VERNON A. WALTERS: PATHFINDER OF THE INTELLIGENCE PROFESSION The views expressed in these remarks are those of the authors and do not reflect the official policy or position of the Department of Defense or the U.S. Government 54821pref.fm5 Page ii Tuesday, December 28, 2004 3:33 PM LTG Vernon A. Walters, U.S. Army 54821pref.fm5 Page iii Tuesday, December 28, 2004 3:33 PM CONTENTS Key Life Events and Professional Assignments. iv Conference Program . v Welcoming Remarks, A. Denis Clift, President, JMIC . 1 Opening Address, Vice Admiral Lowell E. Jacoby, Director, DIA . 5 Keynote Address, Ambassador Hugh Montgomery. 8 Panel on The Military Intelligence Years Colonel John F. Prout, USA (Ret.), JMIC Faculty, Moderator. 14 Luncheon Address, General Alexander M. Haig, Jr., USA (Ret.), Former Secretary of State and colleague of General Walters. -

Military Law Review
Volume 204 Summer 2010 ARTICLES LEAVE NO SOLDIER BEHIND: ENSURING ACCESS TO HEALTH CARE FOR PTSD-AFFLICTED VETERANS Major Tiffany M. Chapman A “CATCH-22” FOR MENTALLY-ILL MILITARY DEFENDANTS: PLEA-BARGAINING AWAY MENTAL HEALTH BENEFITS Vanessa Baehr-Jones PEACEKEEPING AND COUNTERINSURGENCY: HOW U.S. MILITARY DOCTRINE CAN IMPROVE PEACEKEEPING IN THE DEMOCRATIC REPUBLIC OF THE CONGO Ashley Leonczyk CONSISTENCY AND EQUALITY: A FRAMEWORK FOR ANALYZING THE “COMBAT ACTIVITIES EXCLUSION” OF THE FOREIGN CLAIMS ACT Major Michael D. Jones WHO QUESTIONS THE QUESTIONERS? REFORMING THE VOIR DIRE PROCESS IN COURTS-MARTIAL Major Ann B. Ching CLEARING THE HIGH HURDLE OF JUDICIAL RECUSAL: REFORMING RCM 902A Major Steve D. Berlin READ ANY GOOD (PROFESSIONAL) BOOKS LATELY?: A SUGGESTED PROFESSIONAL READING PROGRAM FOR JUDGE ADVOCATES Lieutenant Colonel Jeff Bovarnick THE FIFTEENTH HUGH J. CLAUSEN LECTURE IN LEADERSHIP: LEADERSHIP IN HIGH PROFILE CASES Professor Thomas W. Taylor BOOK REVIEWS Department of Army Pamphlet 27-100-204 MILITARY LAW REVIEW Volume 204 Summer 2010 CONTENTS ARTICLES Leave No Soldier Behind: Ensuring Access to Health Care for PTSD-Afflicted Veterans Major Tiffany M. Chapman 1 A “Catch-22” for Mentally-Ill Military Defendants: Plea-Bargaining away Mental Health Benefits Vanessa Baehr-Jones 51 Peacekeeping and Counterinsurgency: How U.S. Military Doctrine Can Improve Peacekeeping in the Democratic Republic of the Congo Ashley Leonczyk 66 Consistency and Equality: A Framework for Analyzing the “Combat Activities Exclusion” of the Foreign Claims Act Major Michael D. Jones 144 Who Questions the Questioners? Reforming the Voir Dire Process in Courts-Martial Major Ann B. Ching 182 Clearing the High Hurdle of Judicial Recusal: Reforming RCM 902A Major Steve D. -

JP 2-02 National Intelligence Support to Joint Operations
Joint Pub 2-02 National Intelligence Support to Joint Operations 28 September 1998 PREFACE 1. Scope from organizing the force and executing the mission in a manner the JFC deems most This joint publication describes national appropriate to ensure unity of effort in the intelligence organizations and their support accomplishment of the overall mission. to joint military operations. Also addressed is the special support and augmentation 3. Application available for joint operations by national joint elements such as the Military Intelligence a. Doctrine and guidance established in this Board, the National Military Joint Intelligence publication apply to the commanders and Center, and National Intelligence Support intelligence staff of combatant commands, Teams. This joint publication covers Service subordinate unified commands, joint task forces, intelligence organizations and centers, as combat support agencies, and subordinate well as nonmilitary agencies and components of these commands. These nongovernmental organizations. The principles and guidance also may apply when recommended target audience for this joint significant forces of one Service are attached to publication is commanders and intelligence forces of another Service or when significant staffs of combatant commands, subordinate forces of one Service support forces of another unified commands, joint task forces, combat Service. support agencies, and supporting Service components. b. The guidance in this publication is authoritative; as such, this doctrine (or JTTP) 2. Purpose will be followed except when, in the judgment of the commander, exceptional circumstances This publication has been prepared under dictate otherwise. If conflicts arise between the the direction of the Chairman of the Joint contents of this publication and the contents of Chiefs of Staff. -

ATP 3-90.15. Site Exploitation
ATP 3-90.15 SITE EXPLOITATION July 2015 DISTRIBUTION RESTRICTION. Approved for public release; distribution is unlimited. This publication supersedes ATTP 3-90.15, 8 July 2010. Headquarters, Department of the Army This publication is available at Army Knowledge Online (https://armypubs.us.army.mil/doctrine/index.html). To receive publishing updates, please subscribe at http://www.apd.army.mil/AdminPubs/new_subscribe.asp *ATP 3-90.15 Army Techniques Publication Headquarters No. 3-90.15 Department of the Army Washington, DC, 28 July 2015 Site Exploitation Contents Page PREFACE...............................................................................................................v INTRODUCTION ..................................................................................................vii Chapter 1 SITE EXPLOITATION ........................................................................................ 1-1 Introduction to Site Exploitation .......................................................................... 1-1 Considerations for Effective Site Exploitation..................................................... 1-6 Site Exploitation in the Operational Environment ............................................... 1-7 Chapter 2 SITE EXPLOITATION PLANNING .................................................................... 2-1 Planning Concepts in Site Exploitation ............................................................... 2-1 Information Collection ........................................................................................ -
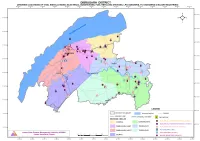
Vital Installations
DISTRICT: DIBRUGARH INFORMATION ON INDUSTRIES/VITAL INSTALLATIONS SL.NO. NAME REVENUE CIRCLE GAON PANCHAYAT VILLAGE NAME APDCL SUB STATIONS 8 FUEL JUNCTION DIBRUGARH EAST DIBRUGARH TOWN WARD 07 SL. NAME OF SUB- VOLTAGE EXISTING TRANSFORMER TOTAL MVA CAP OF NEAREST TOWN 9 MP JALAN DIBRUGARH EAST DIBRUGARH TOWN WARD 07 NO STATION LEVEL CAPACITY (MVA) IN 2008- TRANSFORMER 10 ORIENTAL AUTOMOBILES DIBRUGARH EAST DIBRUGARH TOWN WARD 07 2009 11 R.R. & CO. (MAIN) DIBRUGARH EAST DIBRUGARH TOWN WARD 07 0 RAJGARH 33/11 KV 1X5+1X2.5 7.5 NEAR NAMRUP 12 R.R. & CO. (MGSS) DIBRUGARH EAST DIBRUGARH TOWN WARD 15 1 KHOWANG 33/11 KV 2X3.15 6.3 KHOWANG 13 ASMINA FUELING STATION DIBRUGARH EAST DIBRUGARH TOWN WARD 22 2 DIGBOI 33/11 KV 2X5 10 DIGBOI 14 UDAYRAM RAWATMAL DIBRUGARH EAST PHUKANAR KHAT CHAULKHOWA GRANT GAON 3 MORAN 33/11 KV 2X5 10 MORAN 15 HAYWAY SERVICE STATION DIBRUGARH EAST MOHANBARI MOHANBARI 3/160 4 JOYPUR 33/11 KV 1X3.15 3.15 JOYPUR 16 MEDINI AUTOMOBILES TENGAKHAT TENGAKHAT NIZ-TENGAKHAT 5 NAHARKATIA 33/11 KV 1X5+1X2.5 7.5 NAHARKATIA 17 GIRIJA AUTOMOBILES TENGAKHAT TENGAKHAT NIZ-TENGAKHAT 6 MONABARI 33/11 KV 2X2.5 5 MOHANBARI 18 A.G. FILLING STATION TENGAKHAT DULIAJAN TOWN DULIAJAN TOWN 7 PHOOLBAGAN 33/11 KV 2X5 10 DIBRUGARH 19 BN SING SERVICE STATION TENGAKHAT DULIAJAN TOWN DULIAJAN TOWN 8 BHADOI 33/11 KV 2X5 10 DIBRUGARH PANCHALI 20 JAYANTA DUTTA FILLING TENGAKHAT DULIAJAN TOWN DULIAJAN TOWN SERVICE 9 NADUA 33/11 KV 1X2.5 2.5 DIBRUGARH 21 SANTI AUTO SERVICE TENGAKHAT DULIAJAN TOWN DULIAJAN TOWN 10 DIBRUGARH 33/11 KV 2X10 20 DIBRUGARH 22 BHADOI FUEL CENTRE TENGAKHAT BHADOI NAGAR BHADAI NAGAR 11 MOHANBARI 33/11 KV 1X2.5 2.5 DIBRUGARH 23 SING AUTO AGENCY TENGAKHAT DULIAJAN HOOGRIJAN 12 CHABUA 33/11 KV 2X2.5 5 CHABUA 24 R.R. -

NIU-Factbook-2013.Pdf
WLEDGE IS ENL O I N G H K T ENMEN T NATIONALNI INTELLIGENCEU U N I V E R S I T Y FACTBOOK ACADEMIC 2013 YEAR 2014 National Intelligence University FACTBOOK Academic Year 2013–2014 PREPARED BY: Director, Institutional Effectiveness National Intelligence University Joint Base Anacostia-Bolling 200 MacDill Blvd., Washington, DC 20340 1 National Intelligence University FACTBOOK Academic Year 2013–2014 Table of Contents Introduction and History ................................................................................................................... 3 Mission ............................................................................................................................................ 5 Mission Source Document ................................................................................................................. 5 Vision ............................................................................................................................................... 6 Strategic Goals .................................................................................................................................. 6 NIU Organization .............................................................................................................................. 6 NIU Board of Visitors ......................................................................................................................... 6 NIU Leadership ................................................................................................................................ -

The Dilemma of NATO Strategy, 1949-1968 a Dissertation Presented
The Dilemma of NATO Strategy, 1949-1968 A dissertation presented to the faculty of the College of Arts and Sciences of Ohio University In partial fulfillment of the requirements for the degree Doctor of Philosophy Robert Thomas Davis II August 2008 © 2008 Robert Thomas Davis II All Rights Reserved ii This dissertation titled The Dilemma of NATO Strategy, 1949-1968 by ROBERT THOMAS DAVIS II has been approved for the Department of History and the College of Arts and Sciences by ______________________________ Peter John Brobst Associate Professor of History ______________________________ Benjamin M. Ogles Dean, College of Arts and Sciences iii Abstract DAVIS, ROBERT THOMAS II, Ph.D., August 2008, History The Dilemma of NATO Strategy, 1949-1968 (422 pp.) Director of Dissertation: Peter John Brobst This study is a reappraisal of the strategic dilemma of the North Atlantic Treaty Organization in the Cold War. This dilemma revolves around the problem of articulating a strategic concept for a military alliance in the nuclear era. NATO was born of a perceived need to defend Western Europe from a Soviet onslaught. It was an imperative of the early alliance to develop a military strategy and force posture to defend Western Europe should such a war break out. It was not long after the first iteration of strategy took shape than the imperative for a military defense of Europe receded under the looming threat of thermonuclear war. The advent of thermonuclear arsenals in both the United States and Soviet Union brought with it the potential destruction of civilization should war break out. This realization made statesmen on both sides of the Iron Curtain undergo what has been referred to as an ongoing process of nuclear learning. -

Report of Investigation on Allegations Related to the Dod's Decision To
INTEGRITY EFFICIENCY ACCOUNTABILITY EXCELLENCE Mission Our mission is to provide independent, relevant, and timely oversight of the Department of Defense that supports the warfighter; promotes accountability, integrity, and efficiency; advises the Secretary of Defense and Congress; and informs the public. Vision Our vision is to be a model oversight organization in the Federal Government by leading change, speaking truth, and promoting excellence—a diverse organization, working together as one professional team, recognized as leaders in our field. Fraud, Waste, & Abuse HOTLINE Department of Defense dodig.mil/hotline|800.424.9098 For more information about whistleblower protection, please see the inside back cover. Table of Contents I. INTRODUCTION ................................................................................................................. 1 II. OVERVIEW OF ALLEGATIONS AND THE DoD OIG INVESTIGATION .................... 4 A. Background and Specific Allegations ............................................................................ 4 B. The DoD OIG Investigation ............................................................................................ 7 III. BACKGROUND ................................................................................................................... 9 A. EUCOM Mission ............................................................................................................ 9 B. AFRICOM Mission ..................................................................................................... -

Psychological Operations Principles and Case Studies
Psychological Operations Principles and Case Studies Editor Frank L. Goldstein, Col, USAF Co-editor Benjamin F. Findley, Jr., Col, USAFR Air University. Press Maxwell Air Force Base, Alabama September 1996 Library of Congress Cataloging-in-Publication Data Psychological operations : principles and case studies j editor, Frank L. Goldstein ; co-editor, Benjamin F. Findley. p. cm. At head of t.p. : AU Shield. "September 1996 ." 1. Psychological warfare-United States . 2. Psychological warfare-Case studies . 1. Goldstein, Frank L., 1945- . 11. Findley, Benjamin F. UB276.P82 1996 355 .3'434-dc20 96-22817 CIP ISBN 1-58566-016-7 Disclaimer This publication was produced in the Department of Defense school environment in the interest of academic freedom and the advancement of national defense-related concepts . The views expressed in this publication are those of the authors and do not reflect the official policy or position of the Department of Defense or the United States government. This publication has been reviewed by security and policy review authorities and is cleared for public release . For Sale by the Superintendent of Documents US Government Printing Office Washington, DC 20402 Contents Essay Page DISCLAIMER -------------------- ii FOREWORD . Lx PREFACE ______________________ xi PART I Nature and Scope of Psychological Operations (PSYOP) Introduction . 3 1 Psychological Operations : An Introduction Col Frank L. Goldstein, USAF Col Daniel W. Jacobowitz, USAF, Retired 2 Strategic Concepts for Military Operations . , 17 Col Fred W. Walker, USAF, Retired 3 No More Tactical Information Detachments: US Military Psychological Operations in Transition . 25 Col Alfred H. Paddock, Jr., USA, Retired 4 Blending Military and Civilian PSYOP Paradigms .