Improvement of Svea Coal Mine Availability Using Reliability Analysis
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Petroleum, Coal and Research Drilling Onshore Svalbard: a Historical Perspective
NORWEGIAN JOURNAL OF GEOLOGY Vol 99 Nr. 3 https://dx.doi.org/10.17850/njg99-3-1 Petroleum, coal and research drilling onshore Svalbard: a historical perspective Kim Senger1,2, Peter Brugmans3, Sten-Andreas Grundvåg2,4, Malte Jochmann1,5, Arvid Nøttvedt6, Snorre Olaussen1, Asbjørn Skotte7 & Aleksandra Smyrak-Sikora1,8 1Department of Arctic Geology, University Centre in Svalbard, P.O. Box 156, 9171 Longyearbyen, Norway. 2Research Centre for Arctic Petroleum Exploration (ARCEx), University of Tromsø – the Arctic University of Norway, P.O. Box 6050 Langnes, 9037 Tromsø, Norway. 3The Norwegian Directorate of Mining with the Commissioner of Mines at Svalbard, P.O. Box 520, 9171 Longyearbyen, Norway. 4Department of Geosciences, University of Tromsø – the Arctic University of Norway, P.O. Box 6050 Langnes, 9037 Tromsø, Norway. 5Store Norske Spitsbergen Kulkompani AS, P.O. Box 613, 9171 Longyearbyen, Norway. 6NORCE Norwegian Research Centre AS, Fantoftvegen 38, 5072 Bergen, Norway. 7Skotte & Co. AS, Hatlevegen 1, 6240 Ørskog, Norway. 8Department of Earth Science, University of Bergen, P.O. Box 7803, 5020 Bergen, Norway. E-mail corresponding author (Kim Senger): [email protected] The beginning of the Norwegian oil industry is often attributed to the first exploration drilling in the North Sea in 1966, the first discovery in 1967 and the discovery of the supergiant Ekofisk field in 1969. However, petroleum exploration already started onshore Svalbard in 1960 with three mapping groups from Caltex and exploration efforts by the Dutch company Bataaffse (Shell) and the Norwegian private company Norsk Polar Navigasjon AS (NPN). NPN was the first company to spud a well at Kvadehuken near Ny-Ålesund in 1961. -

Variability of Fast-Ice Thickness in Spitsbergen Fjords
Annals of Glaciology 44 2006 231 Variability of fast-ice thickness in Spitsbergen fjords Sebastian GERLAND, Richard HALL* Norwegian Polar Institute, Polar Environmental Centre, NO-9296 Tromsø, Norway E-mail: [email protected] ABSTRACT. Detailed measurements of sea-ice thickness and snow on sea ice were recorded at different locations in fjords along the western coast of Spitsbergen, the largest island in the Svalbard archipelago, in 2004. Data corresponding to the ice situation before and after melt onset were collected for Kongsfjorden and Van Mijenfjorden, while Hornsund was investigated once during early spring. Profiles of total thickness (snow plus ice thickness) were measured, together with some snow-thickness measure- ments. Total thicknesses were measured with a portable electromagnetic instrument and at selected sites by drilling. The three fjords show some differences in measured thicknesses, connected to individual conditions. However, total thickness does not differ substantially between the three fjords before melt onset. The modal total thickness for all three fjords before melt onset was 1.075 m, and the corresponding modal snow thickness was 0.225 m (bin width 0.05 m). Long-term Kongsfjorden ice-thickness data since 1997 show that the maximum ice thickness varies significantly interannually, as observed at other Arctic sites. The average maximum ice thickness for Kongsfjorden was 0.71 m (years 1997–98, 2000 and 2002–05), and the respective average maximum snow thickness was 0.22 m. In Kongsfjorden, 2004 was the year with highest maximum total thickness and snow thickness relative to the other years. INTRODUCTION Characteristics of fast-ice formation and evolution in The variability, distribution and trends of sea-ice thickness Kongsfjorden differ from those in most other high-Arctic are central issues in current polar climate research (e.g. -

Appendix: Economic Geology: Exploration for Coal, Oil and Minerals
Downloaded from http://mem.lyellcollection.org/ by guest on October 1, 2021 PART 4 Appendix: Economic geology: exploration for coal, oil and Glossary of stratigraphic names, 463 minerals, 449 References, 477 Index of place names, 455 General Index, 515 Alkahornet, a distinctive landmark on the northwest, entrance to Isfjorden, is formed of early Varanger carbonates. The view is from Trygghamna ('Safe Harbour') with CSE motorboats Salterella and Collenia by the shore, with good anchorage and easy access inland. Photo M. J. Hambrey, CSE (SP. 1561). Routine journeys to the fjords of north Spitsbergen and Nordaustlandet pass by the rocky coastline of northwest Spitsbergen. Here is a view of Smeerenburgbreen from Smeerenburgfjordenwhich affords some shelter being protected by outer islands. On one of these was Smeerenburg, the principal base for early whaling, hence the Dutch name for 'blubber town'. Photo N. I. Cox, CSE 1989. Downloaded from http://mem.lyellcollection.org/ by guest on October 1, 2021 The CSE motorboat Salterella in Liefdefjorden looking north towards Erikbreen with largely Devonian rocks in the background unconformably on metamorphic Proterozoic to the left. Photo P. W. Web, CSE 1989. Access to cliffs and a glacier route (up Hannabreen) often necessitates crossing blocky talus (here Devonian in foreground) and then possibly a pleasanter route up the moraine on to hard glacier ice. Moraine generally affords a useful introduction to the rocks to be traversed along the glacial margin. The dots in the sky are geese training their young to fly in V formation for their migration back to the UK at the end of the summer. -

Palaeogene Deposits and the Platform Structure of Svalbard
NORSK POLARINSTITUTT SKRIFTER NR. 159 v JU. JA. LIVSIC Palaeogene deposits and the platform structure of Svalbard NORSK POLARINSTITUTT OSLO 1974 DET KONGEUGE DEPARTEMENT FOR INDUSTRI OG IlANDVERK NORSK POLARINSTITUTT Rolfstangveien 12, Snareya, 1330 Oslo Lufthavn, Norway SALG AV B0KER SALE OF BOOKS Bekene selges gjennom bokhandlere, eller The books are sold through bookshops, or bestilles direkte fra : may be ordered directly from: UNlVERSITETSFORLAGET Postboks 307 16 Pall Mall P.O.Box 142 Blindem, Oslo 3 London SW 1 Boston, Mass. 02113 Norway England USA Publikasjonsliste, som ogsa omfatter land List of publications, including maps and og sjekart, kan sendes pa anmodning. charts, wiZ be sent on request. NORSK POLARINSTITUTT SKRIFTER NR.159 JU. JA. LIVSIC Palaeogene deposits and the platform structure of Svalbard NORSK POLARINSTITUTT OSLO 1974 Manuscript received March 1971 Published April 1974 Contents Abstract ........................ 5 The eastern marginal fault zone 25 The Sassendalen monocline ...... 25 AHHOTaU;HH (Russian abstract) 5 The east Svalbard horst-like uplift 25 The Olgastretet trough .. .. .. .. 26 Introduction 7 The Kong Karls Land uplift .... 26 Stratigraphy ..................... 10 The main stages of formation of the A. Interpretation of sections ac- platform structure of the archipelago 26 cording to areas ............ 11 The Central Basin ........... 11 The Forlandsundet area ..... 13 The importance of Palaeogene depo- The Kongsfjorden area ....... 14 sits for oil and gas prospecting in The Renardodden area ...... 14 Svalbard .. .. .. .. .. .. .. 30 B. Correlation of sections ....... 15 Bituminosity and reservoir rock C. Svalbard Palaeogene deposits properties in Palaeogene deposits 30 as part of the Palaeogene depo- Hydrogeological criteria testifying sits of the Polar Basin ...... 15 to gas and oil content of the rocks 34 Tectonic criteria of oil and gas con- Mineral composition and conditions of tent . -

Svalbard 2015–2016 Meld
Norwegian Ministry of Justice and Public Security Published by: Norwegian Ministry of Justice and Public Security Public institutions may order additional copies from: Norwegian Government Security and Service Organisation E-mail: [email protected] Internet: www.publikasjoner.dep.no KET T Meld. St. 32 (2015–2016) Report to the Storting (white paper) Telephone: + 47 222 40 000 ER RY M K Ø K J E L R I I Photo: Longyearbyen, Tommy Dahl Markussen M 0 Print: 07 PrintMedia AS 7 9 7 P 3 R 0 I 1 08/2017 – Impression 1000 N 4 TM 0 EDIA – 2 Svalbard 2015–2016 Meld. St. 32 (2015–2016) Report to the Storting (white paper) 1 Svalbard Meld. St. 32 (2015–2016) Report to the Storting (white paper) Svalbard Translation from Norwegian. For information only. Table of Contents 1 Summary ........................................ 5 6Longyearbyen .............................. 39 1.1 A predictable Svalbard policy ........ 5 6.1 Introduction .................................... 39 1.2 Contents of each chapter ............... 6 6.2 Areas for further development ..... 40 1.3 Full overview of measures ............. 8 6.2.1 Tourism: Longyearbyen and surrounding areas .......................... 41 2Background .................................. 11 6.2.2 Relocation of public-sector jobs .... 43 2.1 Introduction .................................... 11 6.2.3 Port development ........................... 44 2.2 Main policy objectives for Svalbard 11 6.2.4 Svalbard Science Centre ............... 45 2.3 Svalbard in general ........................ 12 6.2.5 Land development in Longyearbyen ................................ 46 3 Framework under international 6.2.6 Energy supply ................................ 46 law .................................................... 17 6.2.7 Water supply .................................. 47 3.1 Norwegian sovereignty .................. 17 6.3 Provision of services ..................... -

Prioriterte Kulturminner Og Kulturmiljøer Pa Svalbard
KATALOG PRIORITERTE KULTURMINNER OG KULTURMILJØER PA SVALBARD Versjon 1.1 (2013) Irene Skauen Sandodden Sysselmannen på Svalbard Katalog prioriterte kulturminner og kulturmiljøer på Svalbard, versjon 1.1 Side 1 Telefon 79 02 43 00 Internett Adresse Telefaks 79 02 11 66 www.sysselmannen.no Sysselmannen på Svalbard, E-post [email protected] Pb. 633, 9171 Longyearbyen ISBN: Tilgjengelighet Internett: www.sysselmannen.no Opplag: Trykkes ikke, kun digitalt Utgiver Årstall: 2013 Sysselmannen på Svalbard, miljøvernavdelingen Sider: 220 Forfattere Irene Skauen Sandodden. Tekt er hentet fra ulike kilder. Per Kyrre Reymert, Tora Hultgreen, Marit Anne Hauan og Thor Bjørn Arlov har skrevet artikler om de ulike fasene i Svalbard historie (kapittel 2). Deltakende institusjoner Sysselmannen på Svalbard Tittel Title Katalog prioriterte kulturminner og kulturmiljøer på Svalbard. Versjon Catalogue of the cultural heritage sites with high priority in Svalbard. 1.1 (2013). Version 1.1 (2013). Referanse Katalog prioriterte kulturminner og kulturmiljøer på Svalbard. Versjon 1.1 (2013). Tilgjengelig på Internett: www.sysselmannen.no. Sammendrag Katalogen gir et kort innblikk i historien til Svalbard og representative kulturminner. Videre beskrives de om lag 100 prioriterte kulturminnene og kulturmiljøene som er valgt ut i Kulturminneplan for Svalbard 2013 – 2023. Katalogen er utarbeidet som et vedlegg til kulturminneplanen, men kan revideres ved behov. Emneord norsk Keywords English - Kulturminner og kulturmiljø - Cultural heritage (monuments and cultural -
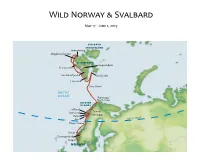
2019 Wild Norway & Svalbard Field Report
Wild Norway & Svalbard May 17 - June 2, 2019 SVALBARD ARCHIPELAGO Smeerenburg Magdalenefjorden SPITSBERGEN Longyearbyen Poolepynten Van Mijenfjorden Storfjorden Hornsund Bear Island ARCTIC OCEAN Skarsvaag/ North Cape LOFOTEN ISLANDS Trollfjord Stamsund Tromsø Kjerringøy Reine CLE Røst ARCTIC CIR Husey/Sanna Runde Geirangerfjord Bergen NORWAY Sunday, May 19, 2019 Bergen, Norway / Embark Ocean Adventurer Unusual for Bergen, it was a dry, warm, and sunny weekend when we arrived here to begin our travels in Wild Norway and Svalbard. Bergen experiences only five rain-free days a year, and this exceptional weather was being fully enjoyed by the locals, especially as this was also the Norwegian National Day holiday weekend. We set out on foot early this morning, for a tour of the old wharf-side district of Bryggen with its picturesque and higgledy-piggledy medieval wooden houses, their colorful gables lit up by today’s bright sunshine. Next, we boarded coaches which took us to Troldhaugen, the home of Norwegian composer Edvard Grieg for over 20 years. The hut where he did much of his work still stands on the lakeside at the foot of the garden. We were treated to an excellent piano recital of some of Grieg’s music before we went to lunch. All too soon, it was time to return to Bergen where our home for the next two weeks, the Ocean Adventurer, awaited us. Once settled in our cabins, our Expedition Leader, John Yersin, introduced us to his team of Zodiac drivers and lecturers who would be accompanying us on our journey over the next two weeks. -

Veileder for Bergverksvirksomhet På
'LUHNWRUDWHWIRU PLQHUDOIRUYDOWQLQJ PHG%HUJPHVWHUHQIRU6YDOEDUG BERGVERKSVIRKSOMHETEN PÅ SVALBARD VEILEDER Bergverksvirksomheten på Svalbard, veileder INNHOLD INNLEDNING OG OVERSIKT OVER 3 Undersøkelser/prøvedrift på tertiære 11 ETATER kullforekomster Generelt 3 Forekomster i Kritt 11 Direktoratet for mineralforvaltning med 3 Forekomster i Karbon 11 Bergmesteren for Svalbard Leteboring etter olje på Svalbard 12 Andre aktuelle etater 3 Malmer, mineraler og blokkstein 13 Produkter og tjenester 4 OM BERGVERKSORDNINGEN FOR SVALBARD 15 SVALBARD EN GEOLOGISK 5 Bergverksordningen 15 BILLEDBOK Bergmesteren for Svalbard 16 Generelt 5 Geologisk utforskning av Svalbard 5 BERGVERKSORDNING FOR Noen trekk av Svalbards geologiske historie 5 SVALBARD 18 Tildeling av utmål på olje på Svalbard, 26 geologiske indikasjoner BERGVERKSDRIFT PÅ SVALBARD 9 Tildeling av utmål basert på funnpunkter i 31 Generelt 9 sjøen Kulldriften 10 Søkeseddel 32 Tertiære kull 10 Funnpunktanmeldelse 33 Krittkull 11 Veiledning for utfylling av funnpunktskjema 34 Karbonkull 11 Tidtabell 36 Bergverksvirksomheten på Svalbard, veileder INNLEDNING OG OVERSIKT OVER ETATER Generelt I Svalbardtraktaten av 9.februar 1920 ble det Andre aktuelle etater bestemt at Norge skulle utarbeide en Berg- Sysselmannen er underlagt Justisdepartemen- verksordning for Svalbard. Bergverksordnin- tet og er regjeringens øverste representant på gen for Svalbard ble gitt ved kgl. res av 7. au- øygruppen. Sysselmannen har samme myn- gust 1925 og trådte i kraft ved Norges overtak- dighet som en fylkesmann og er også politi- else av Svalbard 14.august 1925. mester og notarius publicus. Bergmesteren er statens representant når det Den nye ”Svalbardmiljøloven” håndheves av gjelder olje- og bergverksvirksomhet på Sval- Sysselmannen. Loven gir retningslinjer for ak- bard og sorterer administrativt under Nærings- tiviteter som medfører påvirkning av natur- og handelsdepartementet. -

Druga Wojna Światowa Na Svalbardzie
PRZEGLĄD GEOGRAFICZNY 2011, 83, 4, s. 483–506 Druga wojna światowa na Svalbardzie The Second World War on Svalbard JAN SZUPRYCZYŃSKI Instytut Geografii i Przestrzennego Zagospodarowania im. S. Leszczyckiego PAN, 87-100 Toruń, ul. Kopernika 19; [email protected] Zarys treści. W czasie II wojny światowej Spitsbergen był ważnym miejscem strategicznym. Na mocy traktatu podpisanego 9 lutego 1920 r. w Paryżu Spitsbergen został integralną czę- ścią terytorium Norwegii. Traktat ten do 1940 r. podpisało ponad 30 sygnatariuszy, którzy uzy- skiwali prawo prowadzenia badań naukowych i działalności gospodarczej. Traktat zakładał, że Spitsbergen miał pozostać obszarem zdemilitaryzowanym. W czasie II wojny światowej zasada ta została złamana – na Spitsbergenie toczyły się walki pomiędzy aliantami a Niemcami. Słowa kluczowe: Svalbard, Spitsbergen, Nordaustlandet, Isfjorden, Barentsburg, Grumantbyen, Longyearbyen, Sveagruva, Bansö, Haudegen, Knospe, Kreuzritter, Nussbaum. Status Spitsbergenu W dniu 9 lutego 1920 r. w Paryżu został podpisany tzw. traktat spitsbergeń- ski, zwany również traktatem paryskim, kończący ostatecznie dyskusje dotyczą- ce przynależności terytorialnej Spitsbergenu. Traktat zawarty został pomiędzy Danią, Francją, Holandią, Irlandią, Japonią, Stanami Zjednoczonymi, Szwecją, Wielką Brytanią i Włochami. Ponad trzydzieści innych państw, w tym również Polska, podpisało ten dokument w czasie późniejszym. Związek Radziecki (obecnie Federacja Rosyjska) podpisał go w 1924, a Polska w 1931 r. Obecnie państw sygnatariuszy jest 49 (Stange, 2008). W myśl zapisu art. 1. traktatu, wszystkie strony umawiające się „...uznają całkowitą suweren- ność Norwegii nad archipelagiem Spitsbergenu” (Svalbardu), a państwa sygna- tariusze mają prawo do korzystania z zasobów naturalnych archipelagu, prowa- dzenia działalności gospodarczej i badań naukowych. W zakresie działalności gospodarczej prawa przyznane zapisami traktatu wykorzystują jedynie Norwegia i Rosja, które mają na Spitsbergenie kopalnie węgla (Dege, 1964). -

University of Groningen Frozen Assets Kruse, Frigga
University of Groningen Frozen assets Kruse, Frigga IMPORTANT NOTE: You are advised to consult the publisher's version (publisher's PDF) if you wish to cite from it. Please check the document version below. Document Version Publisher's PDF, also known as Version of record Publication date: 2013 Link to publication in University of Groningen/UMCG research database Citation for published version (APA): Kruse, F. (2013). Frozen assets: British mining exploration, and geopolitics on Spitsbergen, 1904-53. [S.n.]. Copyright Other than for strictly personal use, it is not permitted to download or to forward/distribute the text or part of it without the consent of the author(s) and/or copyright holder(s), unless the work is under an open content license (like Creative Commons). The publication may also be distributed here under the terms of Article 25fa of the Dutch Copyright Act, indicated by the “Taverne” license. More information can be found on the University of Groningen website: https://www.rug.nl/library/open-access/self-archiving-pure/taverne- amendment. Take-down policy If you believe that this document breaches copyright please contact us providing details, and we will remove access to the work immediately and investigate your claim. Downloaded from the University of Groningen/UMCG research database (Pure): http://www.rug.nl/research/portal. For technical reasons the number of authors shown on this cover page is limited to 10 maximum. Download date: 06-10-2021 Frozen Assets: British mining, exploration, and geopolitics on Spitsbergen, 1904-53 Circumpolar Studies Volume 9 Circumpolar Studies is a series on Dutch research in the Polar Regions published by the Arctic Centre of the University of Groningen in the Netherlands. -

Twenty of the Most Thermophilous Vascular Plant Species in Svalbard and Their Conservation State
Twenty of the most thermophilous vascular plant species in Svalbard and their conservation state Torstein Engelskjøn, Leidulf Lund & Inger Greve Alsos An aim for conservation in Norway is preserving the Svalbard archi- pelago as one of the least disturbed areas in the Arctic. Information on local distribution, population sizes and ecology is summarized for 20 thermophilous vascular plant species. The need for conservation of north- ern, marginal populations in Svalbard is reviewed, using World Conser- vation Union categories and criteria at a regional scale. Thirteen species reach their northernmost distribution in Svalbard, the remaining seven in the western Arctic. Nine species have 1 - 8 populations in Svalbard and are assigned to Red List categories endangered or critically endangered: Campanula rotundifolia, Euphrasia frigida, Juncus castaneus, Kobresia simpliciuscula, Rubus chamaemorus, Alchemilla glomerulans, Ranuncu- lus wilanderi, Salix lanata and Vaccinium uliginosum, the last four spe- cies needing immediate protective measures. Five species are classifi ed as vulnerable: Betula nana, Carex marina ssp. pseudolagopina, Luzula wahlenbergii, Ranunculus arcticus and Ranunculus pallasii. Six species are considered at lower risk: Calamagrostis stricta, Empetrum nigrum ssp. hermaphroditum, Hippuris vulgaris (only occurring on Bjørnøya), Juncus triglumis, Ranunculus lapponicus and Rhodiola rosea. The warmer Inner Arctic Fjord Zone of Spitsbergen supports most of the 20 target species and is of particular importance for conservation. Endan- gered or vulnerable species were found in a variety of edaphic conditions; thus, several kinds of habitats need protection. T. Engelskjøn, I. G. Alsos, Tromsø Museum, University of Tromsø, NO-9037 Tromsø, Norway, torstein@ tmu.uit.no; L. Lund, Phytotron, University of Tromsø, NO-9037 Tromsø, Norway. -

Variability of Fast-Ice Thickness in Spitsbergen Fjords
Annals of Glaciology 44 2006 231 Variability of fast-ice thickness in Spitsbergen fjords Sebastian GERLAND, Richard HALL* Norwegian Polar Institute, Polar Environmental Centre, NO-9296 Tromsø, Norway E-mail: [email protected] ABSTRACT. Detailed measurements of sea-ice thickness and snow on sea ice were recorded at different locations in fjords along the western coast of Spitsbergen, the largest island in the Svalbard archipelago, in 2004. Data corresponding to the ice situation before and after melt onset were collected for Kongsfjorden and Van Mijenfjorden, while Hornsund was investigated once during early spring. Profiles of total thickness (snow plus ice thickness) were measured, together with some snow-thickness measure- ments. Total thicknesses were measured with a portable electromagnetic instrument and at selected sites by drilling. The three fjords show some differences in measured thicknesses, connected to individual conditions. However, total thickness does not differ substantially between the three fjords before melt onset. The modal total thickness for all three fjords before melt onset was 1.075 m, and the corresponding modal snow thickness was 0.225 m (bin width 0.05 m). Long-term Kongsfjorden ice-thickness data since 1997 show that the maximum ice thickness varies significantly interannually, as observed at other Arctic sites. The average maximum ice thickness for Kongsfjorden was 0.71 m (years 1997–98, 2000 and 2002–05), and the respective average maximum snow thickness was 0.22 m. In Kongsfjorden, 2004 was the year with highest maximum total thickness and snow thickness relative to the other years. INTRODUCTION Characteristics of fast-ice formation and evolution in The variability, distribution and trends of sea-ice thickness Kongsfjorden differ from those in most other high-Arctic are central issues in current polar climate research (e.g.