AIDA Hearing on AI and Competitiveness of 23 March 2021
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Wise Leadership & AI 3
Wise Leadership and AI Leadership Chapter 3 | Behind the Scenes of the Machines What’s Ahead For Artificial General Intelligence? By Dr. Peter VERHEZEN With the AMROP EDITORIAL BOARD Putting the G in AI | 8 points True, generalized intelligence will be achieved when computers can do or learn anything that a human can. At the highest level, this will mean that computers aren’t just able to process the ‘what,’ but understand the ‘why’ behind data — context, and cause and effect relationships. Even someday chieving consciousness. All of this will demand ethical and emotional intelligence. 1 We underestimate ourselves The human brain is amazingly general compared to any digital device yet developed. It processes bottom-up and top-down information, whereas AI (still) only works bottom-up, based on what it ‘sees’, working on specific, narrowly defined tasks. So, unlike humans, AI is not yet situationally aware, nuanced, or multi-dimensional. 2 When can we expect AGI? Great minds do not think alike Some eminent thinkers (and tech entrepreneurs) see true AGI as only a decade or two away. Others see it as science fiction — AI will more likely serve to amplify human intelligence, just as mechanical machines have amplified physical strength. 3 AGI means moving from homo sapiens to homo deus Reaching AGI has been described by the futurist Ray Kurzweil as ‘singularity’. At this point, humans should progress to the ‘trans-human’ stage: cyber-humans (electronically enhanced) or neuro-augmented (bio-genetically enhanced). 4 The real risk with AGI is not malice, but unguided brilliance A super-intelligent machine will be fantastically good at meeting its goals. -

Letters to the Editor
Articles Letters to the Editor Research Priorities for is a product of human intelligence; we puter scientists, innovators, entrepre - cannot predict what we might achieve neurs, statisti cians, journalists, engi - Robust and Beneficial when this intelligence is magnified by neers, authors, professors, teachers, stu - Artificial Intelligence: the tools AI may provide, but the eradi - dents, CEOs, economists, developers, An Open Letter cation of disease and poverty are not philosophers, artists, futurists, physi - unfathomable. Because of the great cists, filmmakers, health-care profes - rtificial intelligence (AI) research potential of AI, it is important to sionals, research analysts, and members Ahas explored a variety of problems research how to reap its benefits while of many other fields. The earliest signa - and approaches since its inception, but avoiding potential pitfalls. tories follow, reproduced in order and as for the last 20 years or so has been The progress in AI research makes it they signed. For the complete list, see focused on the problems surrounding timely to focus research not only on tinyurl.com/ailetter. - ed. the construction of intelligent agents making AI more capable, but also on Stuart Russell, Berkeley, Professor of Com - — systems that perceive and act in maximizing the societal benefit of AI. puter Science, director of the Center for some environment. In this context, Such considerations motivated the “intelligence” is related to statistical Intelligent Systems, and coauthor of the AAAI 2008–09 Presidential Panel on standard textbook Artificial Intelligence: a and economic notions of rationality — Long-Term AI Futures and other proj - Modern Approach colloquially, the ability to make good ects on AI impacts, and constitute a sig - Tom Dietterich, Oregon State, President of decisions, plans, or inferences. -

Ssoar-2020-Selle-Der Effektive Altruismus Als Neue.Pdf
www.ssoar.info Der effektive Altruismus als neue Größe auf dem deutschen Spendenmarkt: Analyse von Spendermotivation und Leistungsmerkmalen von Nichtregierungsorganisationen (NRO) auf das Spenderverhalten; eine Handlungsempfehlung für klassische NRO Selle, Julia Veröffentlichungsversion / Published Version Arbeitspapier / working paper Empfohlene Zitierung / Suggested Citation: Selle, J. (2020). Der effektive Altruismus als neue Größe auf dem deutschen Spendenmarkt: Analyse von Spendermotivation und Leistungsmerkmalen von Nichtregierungsorganisationen (NRO) auf das Spenderverhalten; eine Handlungsempfehlung für klassische NRO. (Opuscula, 137). Berlin: Maecenata Institut für Philanthropie und Zivilgesellschaft. https://nbn-resolving.org/urn:nbn:de:0168-ssoar-67950-4 Nutzungsbedingungen: Terms of use: Dieser Text wird unter einer CC BY-NC-ND Lizenz This document is made available under a CC BY-NC-ND Licence (Namensnennung-Nicht-kommerziell-Keine Bearbeitung) zur (Attribution-Non Comercial-NoDerivatives). For more Information Verfügung gestellt. Nähere Auskünfte zu den CC-Lizenzen finden see: Sie hier: https://creativecommons.org/licenses/by-nc-nd/3.0 https://creativecommons.org/licenses/by-nc-nd/3.0/deed.de MAECENATA Julia Selle Der effektive Altruismus als neue Größe auf dem deutschen Spendenmarkt Analyse von Spendermotivation und Leistungsmerkmalen von Nichtregierungsorganisationen (NRO) auf das Spenderverhalten. Eine Handlungsempfehlung für klassische NRO. Opusculum Nr.137 Juni 2020 Die Autorin Julia Selle studierte an den Universität -

Comments to Michael Jackson's Keynote on Determining Energy
Comments to Michael Jackson’s Keynote on Determining Energy Futures using Artificial Intelligence Prof Sirkka Heinonen Finland Futures Research Centre (FFRC) University of Turku ENERGIZING FUTURES 13–14 June 2018 Tampere, Finland AI and Energy • Concrete tools: How Shaping Tomorrow answers the question How can AI help? • Goal of foresight crystal clear: Making better decisions today Huge Challenge – The Challenge The world will need to cut energy-related carbon dioxide emissions by 60 percent by 2050 -even as the population grows by more than two billion people Bold Solution on the Horizon The Renewable Energy Transition Companies as pioneers on energy themes, demand, supply, consumption • Google will reach 100% RE for its global operations this year • GE using AI to boost different forms of energy production and use tech-driven data reports to anticipate performance and maintenance needs around the world BUT …also the role of governments, cities and citizens …NGOs, media… new actors should be emphasised AI + Energy + Peer-to-Peer Society • The transformation of the energy system aligns with the principles of a Peer-to-Peer Society. • Peer-to-peer practices are based on the active participation and self-organisation of citizens. Citizens share knowledge, skills, co-create, and form new peer groups. • Citizens will use their capabilities also to develop energy-related products and services Rethinking Concepts Buildings as Power stations – global (economic) opportunity to construct buildings that generate, store and release solar energy -

2016 Annual Report
Technology is giving life ...or to self-destruct. the potential to flourish Let’s make a difference! like never before... Annual Report Making a Difference 2016 1 2016 By the Numbers Nuclear Participants Conference 200 We launched our nuclear divestment campaign at Speakers MIT’S Nuclear Conference. 18 and panelists Billion dollars committed $1 to nuclear divestment Conferences attended AI Safety 17 by FLI members Events This is an increase of 36 AI safety events from the Invitations to speak at events previous year. 15 Events co-organized to 4 highlight AI safety ubshe, eerreee ers Grant Recipients 43 ur rnt reents re rey hr t or to ee Worshos rntees orne 87 nor rtte n bene. rtes rtten by or bout rntee reserh 16 or mor ubtons 2 2016 By the Numbers, Cont. on eoe the 1 rete eos Website We rehe oer mon on sts eoe onne bout .5 to s estent rs n hoe. on sts to .5 rtes n ebes rtes220 ubshe ntony tht reerene Months of News s mentone n mor nes outets eery month o the yer. nternton100 rtes tht reerene rtes11 rtten or the ste Tot1 number o ontons Donors Wee hee so muh thns to the enerosty o our onors. on$3.3 onte to roets n onors ho e t est8 , 3 Message from the President It’s been a great honor for me to get to work with such a talented and idealistic team at our institute to ensure that tomorrow’s most powerful technologies have a positive impact on humanity. -

The Future of AI: Opportunities and Challenges
The Future of AI: Opportunities and Challenges Puerto Rico, January 2-5, 2015 ! Ajay Agrawal is the Peter Munk Professor of Entrepreneurship at the University of Toronto's Rotman School of Management, Research Associate at the National Bureau of Economic Research in Cambridge, MA, Founder of the Creative Destruction Lab, and Co-founder of The Next 36. His research is focused on the economics of science and innovation. He serves on the editorial boards of Management Science, the Journal of Urban Economics, and The Strategic Management Journal. & Anthony Aguirre has worked on a wide variety of topics in theoretical cosmology, ranging from intergalactic dust to galaxy formation to gravity physics to the large-scale structure of inflationary universes and the arrow of time. He also has strong interest in science outreach, and has appeared in numerous science documentaries. He is a co-founder of the Foundational Questions Institute and the Future of Life Institute. & Geoff Anders is the founder of Leverage Research, a research institute that studies psychology, cognitive enhancement, scientific methodology, and the impact of technology on society. He is also a member of the Effective Altruism movement, a movement dedicated to improving the world in the most effective ways. Like many of the members of the Effective Altruism movement, Geoff is deeply interested in the potential impact of new technologies, especially artificial intelligence. & Blaise Agüera y Arcas works on machine learning at Google. Previously a Distinguished Engineer at Microsoft, he has worked on augmented reality, mapping, wearable computing and natural user interfaces. He was the co-creator of Photosynth, software that assembles photos into 3D environments. -

Beneficial AI 2017
Beneficial AI 2017 Participants & Attendees 1 Anthony Aguirre is a Professor of Physics at the University of California, Santa Cruz. He has worked on a wide variety of topics in theoretical cosmology and fundamental physics, including inflation, black holes, quantum theory, and information theory. He also has strong interest in science outreach, and has appeared in numerous science documentaries. He is a co-founder of the Future of Life Institute, the Foundational Questions Institute, and Metaculus (http://www.metaculus.com/). Sam Altman is president of Y Combinator and was the cofounder of Loopt, a location-based social networking app. He also co-founded OpenAI with Elon Musk. Sam has invested in over 1,000 companies. Dario Amodei is the co-author of the recent paper Concrete Problems in AI Safety, which outlines a pragmatic and empirical approach to making AI systems safe. Dario is currently a research scientist at OpenAI, and prior to that worked at Google and Baidu. Dario also helped to lead the project that developed Deep Speech 2, which was named one of 10 “Breakthrough Technologies of 2016” by MIT Technology Review. Dario holds a PhD in physics from Princeton University, where he was awarded the Hertz Foundation doctoral thesis prize. Amara Angelica is Research Director for Ray Kurzweil, responsible for books, charts, and special projects. Amara’s background is in aerospace engineering, in electronic warfare, electronic intelligence, human factors, and computer systems analysis areas. A co-founder and initial Academic Model/Curriculum Lead for Singularity University, she was formerly on the board of directors of the National Space Society, is a member of the Space Development Steering Committee, and is a professional member of the Institute of Electrical and Electronics Engineers (IEEE). -

AI Research Considerations for Human Existential Safety (ARCHES)
AI Research Considerations for Human Existential Safety (ARCHES) Andrew Critch Center for Human-Compatible AI UC Berkeley David Krueger MILA Université de Montréal June 11, 2020 Abstract Framed in positive terms, this report examines how technical AI research might be steered in a manner that is more attentive to hu- manity’s long-term prospects for survival as a species. In negative terms, we ask what existential risks humanity might face from AI development in the next century, and by what principles contempo- rary technical research might be directed to address those risks. A key property of hypothetical AI technologies is introduced, called prepotence, which is useful for delineating a variety of poten- tial existential risks from artificial intelligence, even as AI paradigms might shift. A set of twenty-nine contemporary research directions are then examined for their potential benefit to existential safety. Each research direction is explained with a scenario-driven motiva- tion, and examples of existing work from which to build. The research directions present their own risks and benefits to society that could occur at various scales of impact, and in particular are not guaran- teed to benefit existential safety if major developments in them are deployed without adequate forethought and oversight. As such, each direction is accompanied by a consideration of potentially negative arXiv:2006.04948v1 [cs.CY] 30 May 2020 side effects. Taken more broadly, the twenty-nine explanations of the research directions also illustrate a highly rudimentary methodology for dis- cussing and assessing potential risks and benefits of research direc- tions, in terms of their impact on global catastrophic risks. -
![F.3. the NEW POLITICS of ARTIFICIAL INTELLIGENCE [Preliminary Notes]](https://docslib.b-cdn.net/cover/6619/f-3-the-new-politics-of-artificial-intelligence-preliminary-notes-1566619.webp)
F.3. the NEW POLITICS of ARTIFICIAL INTELLIGENCE [Preliminary Notes]
F.3. THE NEW POLITICS OF ARTIFICIAL INTELLIGENCE [preliminary notes] MAIN MEMO pp 3-14 I. Introduction II. The Infrastructure: 13 key AI organizations III. Timeline: 2005-present IV. Key Leadership V. Open Letters VI. Media Coverage VII. Interests and Strategies VIII. Books and Other Media IX. Public Opinion X. Funders and Funding of AI Advocacy XI. The AI Advocacy Movement and the Techno-Eugenics Movement XII. The Socio-Cultural-Psychological Dimension XIII. Push-Back on the Feasibility of AI+ Superintelligence XIV. Provisional Concluding Comments ATTACHMENTS pp 15-78 ADDENDA pp 79-85 APPENDICES [not included in this pdf] ENDNOTES pp 86-88 REFERENCES pp 89-92 Richard Hayes July 2018 DRAFT: NOT FOR CIRCULATION OR CITATION F.3-1 ATTACHMENTS A. Definitions, usage, brief history and comments. B. Capsule information on the 13 key AI organizations. C. Concerns raised by key sets of the 13 AI organizations. D. Current development of AI by the mainstream tech industry E. Op-Ed: Transcending Complacency on Superintelligent Machines - 19 Apr 2014. F. Agenda for the invitational “Beneficial AI” conference - San Juan, Puerto Rico, Jan 2-5, 2015. G. An Open Letter on Maximizing the Societal Benefits of AI – 11 Jan 2015. H. Partnership on Artificial Intelligence to Benefit People and Society (PAI) – roster of partners. I. Influential mainstream policy-oriented initiatives on AI: Stanford (2016); White House (2016); AI NOW (2017). J. Agenda for the “Beneficial AI 2017” conference, Asilomar, CA, Jan 2-8, 2017. K. Participants at the 2015 and 2017 AI strategy conferences in Puerto Rico and Asilomar. L. Notes on participants at the Asilomar “Beneficial AI 2017” meeting. -

Cheerfully Suicidal Ais Who Want Nothing More Than to Die for Our Benefit
FRIDAY OCTOBER 14 Eisner/Lubin Auditorium, 4th Floor, NYU Kimmel Center, 60 Washington Square South Overflow Rooms (with live stream): Kimmel 405/406, Kimmel 905/907 8:30 - 9:40 am: REGISTRATION AND COFFEE 9:40 am: CONFERENCE OPENING: Thomas J. Carew, Dean of Faculty of Arts and Science, NYU 10:00 am - 12:00 noon: ETHICS OF AI: GENERAL ISSUES Chair: David Chalmers Nick Bostrom (Oxford University, Future of Humanity Institute) Cooperation, Legitimacy, and Governance in AI Development Virginia Dignum (Delft University of Technology, Technology, Policy and Management) On Moral Decisions by Autonomous Systems Yann LeCun (NYU, Data Science; Facebook) Should We Fear Future AI Systems? 12:00 - 1:30 pm: LUNCH BREAK 1:30 - 3:30 pm: ETHICS OF SPECIFIC TECHNOLOGIES Chair: Ned Block Peter Asaro (New School, Media Studies) Killer Robots and the Ethics of Autonomous Weapons Kate Devlin (Goldsmiths College, University of London, Computing) The Ethics of Artificial Sexuality Vasant Dhar (NYU, Data Science) Equity, Safety and Privacy in the Autonomous Vehicle Era Adam Kolber (Brooklyn Law School) Code is Not the Law: Blockchain Contracts and Artificial Intelligence 3:30 - 4:00 pm: COFFEE BREAK 4:00 - 6:00 pm: BUILDING MORALITY INTO MACHINES Chair: Matthew Liao Stephen Wolfram (Wolfram Research) How to Tell AIs What to Do (and What to Tell Them) Francesca Rossi (IBM; University of Padova) Ethical Embodied Decision Making Peter Railton (University of Michigan, Philosophy) Machine Morality: Building or Learning? SATURDAY OCTOBER 15 NYU Cantor Film Center -
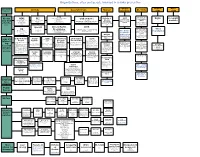
The Map of Organisation and People Involved in X
Organizations, sites and people involved in x-risks prevention Global Impact Nano Size and level of AI risks General x-risks Nuclear Bio-risks influence warming risks risks FHI Future of humanity institute Bulletin of IPCC World Health NASA Foresight Known MIRI FLI Club of Rome Organization link (Former Singularity Future of life institute Oxford, link Still exist! Atomic International (WHO) institute very well institute) Elon Musk Nick Bostrom Were famous in 1970s when they pro- panel of climate and large Scientists change includes a division called the Global link E.Yudkowsky link list of researchers duced “Limits of growth” Link Alert and Response (GAR) which mon- Famous doomsday itors and responds to global epidemic amount of work link crisis. GAR helps member states with clock training and coordination of response to is done epidemics. link link OpenAI Oxford Martin CSER EA B612 Elon Musk Programme Cambridge center of existential risks The United States Effective altruism on the Impacts of Future wiki Martin Rees, link The Forum Agency for Interna- Foundation Open Philanthropy Technology, link for Climate tional Development project (USAID) 80’000 hours Nuclear Engineering has its Emerging Pandemic Threats Program which aims to prevent and threat Initia- Assessment contain naturally generated pandemics Got grant from OFP at their source.[129] Global Priorities X-risks GCRI Foundational Skoll Global CISAC tive link Large and Global catastrophic risks Project institute institute, Research Threats Fund “The Center for Internation- interest- -

Read Volume 73: 19Th April 2015
Read Volume 73: 19th April 2015 Forum for Multidisciplinary Thinking !1 Read Volume 73: 19th April 2015 Content Page3: Existential Risk: A Conversation With Jaan Tallinn Page 13: From “Economic Man” to Behavioral Economics By Justin Fox Page 24: Why C.E.O. Pay Reform Failed By James Surowiecki Page 28: The anatomy of discovery: a case study By David Field Chetan Parikh Prashant Patel Arpit Ranka Compiled & Edited by Prashant Patel “The best thing a human being can do is to help another human being know more.” — Charlie Munger Forum for Multidisciplinary Thinking !2 Read Volume 73: 19th April 2015 Existential Risk: A Conversation With Jaan Tallinn JAAN TALLINN is a co-founder of The Centre for the Study of Existential Risk at University of Cambridge, UK as well as The Future of Life Institute in Cambridge, MA. He is also a founding engineer of Kazaa and Skype. Jaan Tallinn's Edge Bio Page INTRODUCTION by Max Tegmark I find Jaan Tallinn remarkable in more ways than one. His rags-to-riches entrepreneur story is inspiring in its own right, starting behind the Iron Curtain and ending up connecting the world with Skype. How many times have you skyped? How many people do you know who created a new verb? Most successful entrepreneurs I know went on to become serial entrepreneurs. In contrast, Jaan chose a different path: he asked himself how he could leverage his success to do as much good as possible in the world, developed a plan, and dedicated his life to it. His ambition makes even the goals of Skype seem modest: reduce existential risk, i.e., the risk that we humans do something as stupid as go extinct due to poor planning.