Supplementary Table 2: Genes Only Influenced by Insulin
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
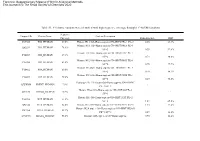
Table S1. 49 Histone Variants Were Identified with High Sequence Coverage Through LC-MS/MS Analysis Electronic Supplementary
Electronic Supplementary Material (ESI) for Analytical Methods. This journal is © The Royal Society of Chemistry 2020 Table S1. 49 histone variants were identified with high sequence coverage through LC-MS/MS analysis Sequence Uniprot IDs Protein Name Protein Description Coverage Ratio E2+/E2- RSD P07305 H10_HUMAN 67.5% Histone H1.0 OS=Homo sapiens GN=H1F0 PE=1 SV=3 4.85 23.3% Histone H1.1 OS=Homo sapiens GN=HIST1H1A PE=1 Q02539 H11_HUMAN 74.4% SV=3 0.35 92.6% Histone H1.2 OS=Homo sapiens GN=HIST1H1C PE=1 P16403 H12_HUMAN 67.1% SV=2 0.73 80.6% Histone H1.3 OS=Homo sapiens GN=HIST1H1D PE=1 P16402 H13_HUMAN 63.8% SV=2 0.75 77.7% Histone H1.4 OS=Homo sapiens GN=HIST1H1E PE=1 P10412 H14_HUMAN 69.0% SV=2 0.70 80.3% Histone H1.5 OS=Homo sapiens GN=HIST1H1B PE=1 P16401 H15_HUMAN 79.6% SV=3 0.29 98.3% Testis-specific H1 histone OS=Homo sapiens GN=H1FNT Q75WM6 H1FNT_HUMAN 7.8% \ \ PE=2 SV=3 Histone H1oo OS=Homo sapiens GN=H1FOO PE=2 Q8IZA3 H1FOO_HUMAN 5.2% \ \ SV=1 Histone H1t OS=Homo sapiens GN=HIST1H1T PE=2 P22492 H1T_HUMAN 31.4% SV=4 1.42 65.0% Q92522 H1X_HUMAN 82.6% Histone H1x OS=Homo sapiens GN=H1FX PE=1 SV=1 1.15 33.2% Histone H2A type 1 OS=Homo sapiens GN=HIST1H2AG P0C0S8 H2A1_HUMAN 99.2% PE=1 SV=2 0.57 26.8% Q96QV6 H2A1A_HUMAN 58.0% Histone H2A type 1-A OS=Homo sapiens 0.90 11.2% GN=HIST1H2AA PE=1 SV=3 Histone H2A type 1-B/E OS=Homo sapiens P04908 H2A1B_HUMAN 99.2% GN=HIST1H2AB PE=1 SV=2 0.92 30.2% Histone H2A type 1-C OS=Homo sapiens Q93077 H2A1C_HUMAN 100.0% GN=HIST1H2AC PE=1 SV=3 0.76 27.6% Histone H2A type 1-D OS=Homo sapiens P20671 -

UNIVERSITY of CALIFORNIA, SAN DIEGO Functional Analysis of Sall4
UNIVERSITY OF CALIFORNIA, SAN DIEGO Functional analysis of Sall4 in modulating embryonic stem cell fate A dissertation submitted in partial satisfaction of the requirements for the degree Doctor of Philosophy in Molecular Pathology by Pei Jen A. Lee Committee in charge: Professor Steven Briggs, Chair Professor Geoff Rosenfeld, Co-Chair Professor Alexander Hoffmann Professor Randall Johnson Professor Mark Mercola 2009 Copyright Pei Jen A. Lee, 2009 All rights reserved. The dissertation of Pei Jen A. Lee is approved, and it is acceptable in quality and form for publication on microfilm and electronically: ______________________________________________________________ ______________________________________________________________ ______________________________________________________________ ______________________________________________________________ Co-Chair ______________________________________________________________ Chair University of California, San Diego 2009 iii Dedicated to my parents, my brother ,and my husband for their love and support iv Table of Contents Signature Page……………………………………………………………………….…iii Dedication…...…………………………………………………………………………..iv Table of Contents……………………………………………………………………….v List of Figures…………………………………………………………………………...vi List of Tables………………………………………………….………………………...ix Curriculum vitae…………………………………………………………………………x Acknowledgement………………………………………………….……….……..…...xi Abstract………………………………………………………………..…………….....xiii Chapter 1 Introduction ..…………………………………………………………………………….1 Chapter 2 Materials and Methods……………………………………………………………..…12 -

Rule Mining on Microrna Expression Profiles For
Faculty of Engineering and Information Technology University of Technology, Sydney Rule Mining on MicroRNA Expression Profiles for Human Disease Understanding A thesis submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy by Renhua Song July 2016 CERTIFICATE OF AUTHORSHIP/ORIGINALITY I certify that the work in this thesis has not previously been submitted for a degree nor has it been submitted as part of requirements for a degree except as fully acknowledged within the text. I also certify that the thesis has been written by me. Any help that I have received in my research work and the preparation of the thesis itself has been acknowledged. In addition, I certify that all information sources and literature used are indicated in the thesis. Signature of Candidate i Acknowledgments First, and foremost, I would like to express my gratitude to my chief supervisor, Assoc. Prof. Jinyan Li, and to my co-supervisors Assoc. Prof. Paul Kennedy and Assoc. Prof. Daniel Catchpoole. I am extremely grateful for all the advice and guidance so unselfishly given to me over the last three and half years by these three distinguished academics. This research would not have been possible without their high order supervision, support, assistance and leadership. The wonderful support and assistance provided by many people during this research is very much appreciated by me and my family. I am very grateful for the help that I received from all of these people but there are some special individuals that I must thank by name. A very sincere thank you is definitely owed to my loving husband Jing Liu, not only for his tremendous support during the last three and half years, but also his unfailing and often sorely tested patience. -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -

1) (As of December 2018) and the Latest GWAS of AD (2
SUPPLEMENTARY FIGURES downstream intergenic ncRNA_exonic upstream ●936 ●918 group downstream intergenic ncRNA_exonic upstream group exonic exonicintronicintronic ncRNA_intronic ncRNA_intronicUTR3 UTR3 3.8% 1.2%1.5%1.9% 3.8% 5.4%5.4% 750 0.3% 3.8%1.2%1.5%1.9% ●700 5.4% ●670 0.3% 500 45.8% 40.240.2% % 45.8% ●329 ●274 250 ●223 Number (GWAS SNPs/studies) Number (GWAS ●128 ●105 45.8% ●54 ●57 ●58 ●48 ●42 ●46 ●50 ●30 ●3740.2% ● ●17 ●25 ●4 ●6 ●12 0 ● 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 2017 2018 2019 Year Supplementary Figure S1. GWAS of AD since 2007. The figure is based on data from the GWAS Catalog (1) (as of December 2018) and the latest GWAS of AD (2). The green area shows the total number of AD-associated SNPs, and the purple area shows the total number of GWAS of AD. The insert chart shows the proportions of different types of all 936 AD-associated SNPs. 1 100 200 RPS27A TGFB2 BIN1 C4BPB MSH2 PROC UGT1A1 RAB1A TTN DISC1 50 PDCL3 COL4A3 CD55 ERCC3 100 USP21 C4BPA ITSN2 PTPRF MPZ FMN2 INPP5D CEP85 FNBP1L CSF1 CD46 ADAMTS4 PRKRA SPRED2 0 CTNNA2 DGKD ADCY10 ZAP70 LIMS2 PDE1A PROX1 0 CHRNB2 CR1 HSPG2 SH3BGRL3 DAB1 CTBS FCER1G MAP3K2 AD risk score or log10(P value) IL6R CDC73 CD34 AD risk score or log10(P value) −50 B4GALT3 IL19 0 50 100 150 200 250 0 50 100 150 200 Chromosome 1 (Mb) Chromosome 2 (Mb) ATP2B2 LTF ARF4 MECOM PAK2 EPHB1 40 VHL PRSS42 ARL6IP5 150 COL25A1 TDGF1 RPSA CCR2 CCR1 IL1RAP IRAK2 20 PTPRG 100 FLNB TF CX3CR1 IL17RD SH3RF1 FGG FANCD2 LIMD1 CCR5 50 0 WDR1 PDGFRA EIF4E FGB AD risk score or log10(P value) AD risk -

Mechanism of Completion of Peptidyltransferase Centre
RESEARCH ARTICLE Mechanism of completion of peptidyltransferase centre assembly in eukaryotes Vasileios Kargas1,2,3†, Pablo Castro-Hartmann1,2,3†, Norberto Escudero-Urquijo1,2,3, Kyle Dent1,2,3, Christine Hilcenko1,2,3, Carolin Sailer4, Gertrude Zisser5, Maria J Marques-Carvalho1,2,3, Simone Pellegrino1,2,3, Leszek Wawio´ rka1,2,3,6, Stefan MV Freund7, Jane L Wagstaff7, Antonina Andreeva7, Alexandre Faille1,2,3, Edwin Chen8, Florian Stengel4, Helmut Bergler5, Alan John Warren1,2,3* 1Cambridge Institute for Medical Research, Cambridge, United Kingdom; 2Department of Haematology, University of Cambridge, Cambridge, United Kingdom; 3Wellcome Trust–Medical Research Council Stem Cell Institute, University of Cambridge, Cambridge, United Kingdom; 4Department of Biology, University of Konstanz, Konstanz, Germany; 5Institute of Molecular Biosciences, University of Graz, Graz, Austria; 6Department of Molecular Biology, Maria Curie-Skłodowska University, Lublin, Poland; 7MRC Laboratory of Molecular Biology, Cambridge, United Kingdom; 8Faculty of Biological Sciences, University of Leeds, Leeds, United Kingdom Abstract During their final maturation in the cytoplasm, pre-60S ribosomal particles are converted to translation-competent large ribosomal subunits. Here, we present the mechanism of peptidyltransferase centre (PTC) completion that explains how integration of the last ribosomal *For correspondence: [email protected] proteins is coupled to release of the nuclear export adaptor Nmd3. Single-particle cryo-EM reveals that eL40 recruitment stabilises helix 89 to form the uL16 binding site. The loading of uL16 unhooks † These authors contributed helix 38 from Nmd3 to adopt its mature conformation. In turn, partial retraction of the L1 stalk is equally to this work coupled to a conformational switch in Nmd3 that allows the uL16 P-site loop to fully accommodate Competing interests: The into the PTC where it competes with Nmd3 for an overlapping binding site (base A2971). -

Aneuploidy: Using Genetic Instability to Preserve a Haploid Genome?
Health Science Campus FINAL APPROVAL OF DISSERTATION Doctor of Philosophy in Biomedical Science (Cancer Biology) Aneuploidy: Using genetic instability to preserve a haploid genome? Submitted by: Ramona Ramdath In partial fulfillment of the requirements for the degree of Doctor of Philosophy in Biomedical Science Examination Committee Signature/Date Major Advisor: David Allison, M.D., Ph.D. Academic James Trempe, Ph.D. Advisory Committee: David Giovanucci, Ph.D. Randall Ruch, Ph.D. Ronald Mellgren, Ph.D. Senior Associate Dean College of Graduate Studies Michael S. Bisesi, Ph.D. Date of Defense: April 10, 2009 Aneuploidy: Using genetic instability to preserve a haploid genome? Ramona Ramdath University of Toledo, Health Science Campus 2009 Dedication I dedicate this dissertation to my grandfather who died of lung cancer two years ago, but who always instilled in us the value and importance of education. And to my mom and sister, both of whom have been pillars of support and stimulating conversations. To my sister, Rehanna, especially- I hope this inspires you to achieve all that you want to in life, academically and otherwise. ii Acknowledgements As we go through these academic journeys, there are so many along the way that make an impact not only on our work, but on our lives as well, and I would like to say a heartfelt thank you to all of those people: My Committee members- Dr. James Trempe, Dr. David Giovanucchi, Dr. Ronald Mellgren and Dr. Randall Ruch for their guidance, suggestions, support and confidence in me. My major advisor- Dr. David Allison, for his constructive criticism and positive reinforcement. -

The Transition from Primary Colorectal Cancer to Isolated Peritoneal Malignancy
medRxiv preprint doi: https://doi.org/10.1101/2020.02.24.20027318; this version posted February 25, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted medRxiv a license to display the preprint in perpetuity. It is made available under a CC-BY 4.0 International license . The transition from primary colorectal cancer to isolated peritoneal malignancy is associated with a hypermutant, hypermethylated state Sally Hallam1, Joanne Stockton1, Claire Bryer1, Celina Whalley1, Valerie Pestinger1, Haney Youssef1, Andrew D Beggs1 1 = Surgical Research Laboratory, Institute of Cancer & Genomic Science, University of Birmingham, B15 2TT. Correspondence to: Andrew Beggs, [email protected] KEYWORDS: Colorectal cancer, peritoneal metastasis ABBREVIATIONS: Colorectal cancer (CRC), Colorectal peritoneal metastasis (CPM), Cytoreductive surgery and heated intraperitoneal chemotherapy (CRS & HIPEC), Disease free survival (DFS), Differentially methylated regions (DMR), Overall survival (OS), TableFormalin fixed paraffin embedded (FFPE), Hepatocellular carcinoma (HCC) ARTICLE CATEGORY: Research article NOTE: This preprint reports new research that has not been certified by peer review and should not be used to guide clinical practice. 1 medRxiv preprint doi: https://doi.org/10.1101/2020.02.24.20027318; this version posted February 25, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted medRxiv a license to display the preprint in perpetuity. It is made available under a CC-BY 4.0 International license . NOVELTY AND IMPACT: Colorectal peritoneal metastasis (CPM) are associated with limited and variable survival despite patient selection using known prognostic factors and optimal currently available treatments. -

RNA Sequencing of Whole Blood in Discordant Twin and Case-Controlled Cohorts
Biomarker Discovery in Attention Decit Hyperactivity Disorder: RNA sequencing of Whole Blood in Discordant Twin and Case-Controlled Cohorts Timothy A. McCaffrey ( [email protected] ) George Washington University Medical Center https://orcid.org/0000-0002-4648-7833 Georges St. Laurent III The St. Laurent Institute Dmitry Shtokalo Institut sistem informatiki imeni A P Ersova SO RAN Denis Antonets A P Ershov Institute of Informatics Systems SB RAS: Institut sistem informatiki imeni A P Ersova SO RAN Yuri Vyatkin Janssen Research and Development LLC Daniel Jones Amgen Inc Eleanor Battison Oregon Health & Science University - West Campus Joel T. Nigg Oregon Health & Science University Research article Keywords: attention-decit/hyperactivity disorder (ADHD), RNA sequencing, transcriptome, GIT1, galactose, twins Posted Date: October 22nd, 2020 DOI: https://doi.org/10.21203/rs.3.rs-20756/v3 License: This work is licensed under a Creative Commons Attribution 4.0 International License. Read Full License Page 1/34 Version of Record: A version of this preprint was published on October 28th, 2020. See the published version at https://doi.org/10.1186/s12920-020-00808-8. Page 2/34 Abstract Background: A variety of DNA-based methods have been applied to identify genetic markers of attention decit hyperactivity disorder (ADHD), but the connection to RNA-based gene expression has not been fully exploited. Methods: Using well dened cohorts of discordant, monozygotic twins from the Michigan State University Twin Registry, and case-controlled ADHD cases in adolescents, the present studies utilized advanced single molecule RNA sequencing to identify expressed changes in whole blood RNA in ADHD. Multiple analytical strategies were employed to narrow differentially expressed RNA targets to a small set of potential biomarkers of ADHD. -

"The Genecards Suite: from Gene Data Mining to Disease Genome Sequence Analyses". In: Current Protocols in Bioinformat
The GeneCards Suite: From Gene Data UNIT 1.30 Mining to Disease Genome Sequence Analyses Gil Stelzer,1,5 Naomi Rosen,1,5 Inbar Plaschkes,1,2 Shahar Zimmerman,1 Michal Twik,1 Simon Fishilevich,1 Tsippi Iny Stein,1 Ron Nudel,1 Iris Lieder,2 Yaron Mazor,2 Sergey Kaplan,2 Dvir Dahary,2,4 David Warshawsky,3 Yaron Guan-Golan,3 Asher Kohn,3 Noa Rappaport,1 Marilyn Safran,1 and Doron Lancet1,6 1Department of Molecular Genetics, Weizmann Institute of Science, Rehovot, Israel 2LifeMap Sciences Ltd., Tel Aviv, Israel 3LifeMap Sciences Inc., Marshfield, Massachusetts 4Toldot Genetics Ltd., Hod Hasharon, Israel 5These authors contributed equally to the paper 6Corresponding author GeneCards, the human gene compendium, enables researchers to effectively navigate and inter-relate the wide universe of human genes, diseases, variants, proteins, cells, and biological pathways. Our recently launched Version 4 has a revamped infrastructure facilitating faster data updates, better-targeted data queries, and friendlier user experience. It also provides a stronger foundation for the GeneCards suite of companion databases and analysis tools. Improved data unification includes gene-disease links via MalaCards and merged biological pathways via PathCards, as well as drug information and proteome expression. VarElect, another suite member, is a phenotype prioritizer for next-generation sequencing, leveraging the GeneCards and MalaCards knowledgebase. It au- tomatically infers direct and indirect scored associations between hundreds or even thousands of variant-containing genes and disease phenotype terms. Var- Elect’s capabilities, either independently or within TGex, our comprehensive variant analysis pipeline, help prepare for the challenge of clinical projects that involve thousands of exome/genome NGS analyses. -

H1 Linker Histones Silence Repetitive Elements by Promoting Both Histone H3K9 Methylation and Chromatin Compaction
H1 linker histones silence repetitive elements by promoting both histone H3K9 methylation and chromatin compaction Sean E. Healtona,1,2, Hugo D. Pintoa,1, Laxmi N. Mishraa, Gregory A. Hamiltona,b, Justin C. Wheata, Kalina Swist-Rosowskac, Nicholas Shukeirc, Yali Doud, Ulrich Steidla, Thomas Jenuweinc, Matthew J. Gamblea,b, and Arthur I. Skoultchia,2 aDepartment of Cell Biology, Albert Einstein College of Medicine, Bronx, NY 10461; bDepartment of Molecular Pharmacology, Albert Einstein College of Medicine, Bronx, NY 10461; cMax Planck Institute of Immunobiology and Epigenetics, Stübeweg 51, Freiburg D-79108, Germany; and dDepartment of Pathology, University of Michigan, Ann Arbor, MI 48109 Edited by Robert G. Roeder, Rockefeller University, New York, NY, and approved May 1, 2020 (received for review December 15, 2019) Nearly 50% of mouse and human genomes are composed of repetitive mechanisms of this regulation have not been fully explored. To sequences. Transcription of these sequences is tightly controlled during further investigate the roles of H1 in epigenetic regulation, we have development to prevent genomic instability, inappropriate gene used CRISPR-Cas9–mediated genome editing to inactivate addi- activation and other maladaptive processes. Here, we demonstrate tional H1 genes in the H1 TKO ES cells and thereby deplete the H1 an integral role for H1 linker histones in silencing repetitive elements in content to even lower levels. mouse embryonic stem cells. Strong H1 depletion causes a profound Nearly 50% of the mouse and human genomes consist of re- de-repression of several classes of repetitive sequences, including major petitive sequences, including tandem repeats, such as satellite se- satellite, LINE-1, and ERV. -

NMD3 (NM 015938) Human Recombinant Protein Product Data
OriGene Technologies, Inc. 9620 Medical Center Drive, Ste 200 Rockville, MD 20850, US Phone: +1-888-267-4436 [email protected] EU: [email protected] CN: [email protected] Product datasheet for TP303044 NMD3 (NM_015938) Human Recombinant Protein Product data: Product Type: Recombinant Proteins Description: Recombinant protein of human NMD3 homolog (S. cerevisiae) (NMD3) Species: Human Expression Host: HEK293T Tag: C-Myc/DDK Predicted MW: 57.4 kDa Concentration: >50 ug/mL as determined by microplate BCA method Purity: > 80% as determined by SDS-PAGE and Coomassie blue staining Buffer: 25 mM Tris.HCl, pH 7.3, 100 mM glycine, 10% glycerol Preparation: Recombinant protein was captured through anti-DDK affinity column followed by conventional chromatography steps. Storage: Store at -80°C. Stability: Stable for 12 months from the date of receipt of the product under proper storage and handling conditions. Avoid repeated freeze-thaw cycles. RefSeq: NP_057022 Locus ID: 51068 UniProt ID: Q96D46 RefSeq Size: 2758 Cytogenetics: 3q26.1 RefSeq ORF: 1509 Synonyms: CGI-07 Summary: Ribosomal 40S and 60S subunits associate in the nucleolus and are exported to the cytoplasm. The protein encoded by this gene is involved in the passage of the 60S subunit through the nuclear pore complex and into the cytoplasm. Several transcript variants exist for this gene, but the full-length natures of only two have been described to date. [provided by RefSeq, Feb 2016] This product is to be used for laboratory only. Not for diagnostic or therapeutic use. View online » ©2021 OriGene Technologies, Inc., 9620 Medical Center Drive, Ste 200, Rockville, MD 20850, US 1 / 2 NMD3 (NM_015938) Human Recombinant Protein – TP303044 Product images: Coomassie blue staining of purified NMD3 protein (Cat# TP303044).