Chemical Proteomics: Mass Spectrometry-Based Label-Free Quantitative Approach in Cell Systems
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Histone Isoform H2A1H Promotes Attainment of Distinct Physiological
Bhattacharya et al. Epigenetics & Chromatin (2017) 10:48 DOI 10.1186/s13072-017-0155-z Epigenetics & Chromatin RESEARCH Open Access Histone isoform H2A1H promotes attainment of distinct physiological states by altering chromatin dynamics Saikat Bhattacharya1,4,6, Divya Reddy1,4, Vinod Jani5†, Nikhil Gadewal3†, Sanket Shah1,4, Raja Reddy2,4, Kakoli Bose2,4, Uddhavesh Sonavane5, Rajendra Joshi5 and Sanjay Gupta1,4* Abstract Background: The distinct functional efects of the replication-dependent histone H2A isoforms have been dem- onstrated; however, the mechanistic basis of the non-redundancy remains unclear. Here, we have investigated the specifc functional contribution of the histone H2A isoform H2A1H, which difers from another isoform H2A2A3 in the identity of only three amino acids. Results: H2A1H exhibits varied expression levels in diferent normal tissues and human cancer cell lines (H2A1C in humans). It also promotes cell proliferation in a context-dependent manner when exogenously overexpressed. To uncover the molecular basis of the non-redundancy, equilibrium unfolding of recombinant H2A1H-H2B dimer was performed. We found that the M51L alteration at the H2A–H2B dimer interface decreases the temperature of melting of H2A1H-H2B by ~ 3 °C as compared to the H2A2A3-H2B dimer. This diference in the dimer stability is also refected in the chromatin dynamics as H2A1H-containing nucleosomes are more stable owing to M51L and K99R substitu- tions. Molecular dynamic simulations suggest that these substitutions increase the number of hydrogen bonds and hydrophobic interactions of H2A1H, enabling it to form more stable nucleosomes. Conclusion: We show that the M51L and K99R substitutions, besides altering the stability of histone–histone and histone–DNA complexes, have the most prominent efect on cell proliferation, suggesting that the nucleosome sta- bility is intimately linked with the physiological efects observed. -

Analysis of Trans Esnps Infers Regulatory Network Architecture
Analysis of trans eSNPs infers regulatory network architecture Anat Kreimer Submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in the Graduate School of Arts and Sciences COLUMBIA UNIVERSITY 2014 © 2014 Anat Kreimer All rights reserved ABSTRACT Analysis of trans eSNPs infers regulatory network architecture Anat Kreimer eSNPs are genetic variants associated with transcript expression levels. The characteristics of such variants highlight their importance and present a unique opportunity for studying gene regulation. eSNPs affect most genes and their cell type specificity can shed light on different processes that are activated in each cell. They can identify functional variants by connecting SNPs that are implicated in disease to a molecular mechanism. Examining eSNPs that are associated with distal genes can provide insights regarding the inference of regulatory networks but also presents challenges due to the high statistical burden of multiple testing. Such association studies allow: simultaneous investigation of many gene expression phenotypes without assuming any prior knowledge and identification of unknown regulators of gene expression while uncovering directionality. This thesis will focus on such distal eSNPs to map regulatory interactions between different loci and expose the architecture of the regulatory network defined by such interactions. We develop novel computational approaches and apply them to genetics-genomics data in human. We go beyond pairwise interactions to define network motifs, including regulatory modules and bi-fan structures, showing them to be prevalent in real data and exposing distinct attributes of such arrangements. We project eSNP associations onto a protein-protein interaction network to expose topological properties of eSNPs and their targets and highlight different modes of distal regulation. -
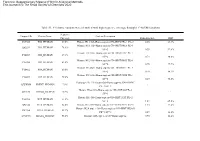
Table S1. 49 Histone Variants Were Identified with High Sequence Coverage Through LC-MS/MS Analysis Electronic Supplementary
Electronic Supplementary Material (ESI) for Analytical Methods. This journal is © The Royal Society of Chemistry 2020 Table S1. 49 histone variants were identified with high sequence coverage through LC-MS/MS analysis Sequence Uniprot IDs Protein Name Protein Description Coverage Ratio E2+/E2- RSD P07305 H10_HUMAN 67.5% Histone H1.0 OS=Homo sapiens GN=H1F0 PE=1 SV=3 4.85 23.3% Histone H1.1 OS=Homo sapiens GN=HIST1H1A PE=1 Q02539 H11_HUMAN 74.4% SV=3 0.35 92.6% Histone H1.2 OS=Homo sapiens GN=HIST1H1C PE=1 P16403 H12_HUMAN 67.1% SV=2 0.73 80.6% Histone H1.3 OS=Homo sapiens GN=HIST1H1D PE=1 P16402 H13_HUMAN 63.8% SV=2 0.75 77.7% Histone H1.4 OS=Homo sapiens GN=HIST1H1E PE=1 P10412 H14_HUMAN 69.0% SV=2 0.70 80.3% Histone H1.5 OS=Homo sapiens GN=HIST1H1B PE=1 P16401 H15_HUMAN 79.6% SV=3 0.29 98.3% Testis-specific H1 histone OS=Homo sapiens GN=H1FNT Q75WM6 H1FNT_HUMAN 7.8% \ \ PE=2 SV=3 Histone H1oo OS=Homo sapiens GN=H1FOO PE=2 Q8IZA3 H1FOO_HUMAN 5.2% \ \ SV=1 Histone H1t OS=Homo sapiens GN=HIST1H1T PE=2 P22492 H1T_HUMAN 31.4% SV=4 1.42 65.0% Q92522 H1X_HUMAN 82.6% Histone H1x OS=Homo sapiens GN=H1FX PE=1 SV=1 1.15 33.2% Histone H2A type 1 OS=Homo sapiens GN=HIST1H2AG P0C0S8 H2A1_HUMAN 99.2% PE=1 SV=2 0.57 26.8% Q96QV6 H2A1A_HUMAN 58.0% Histone H2A type 1-A OS=Homo sapiens 0.90 11.2% GN=HIST1H2AA PE=1 SV=3 Histone H2A type 1-B/E OS=Homo sapiens P04908 H2A1B_HUMAN 99.2% GN=HIST1H2AB PE=1 SV=2 0.92 30.2% Histone H2A type 1-C OS=Homo sapiens Q93077 H2A1C_HUMAN 100.0% GN=HIST1H2AC PE=1 SV=3 0.76 27.6% Histone H2A type 1-D OS=Homo sapiens P20671 -

Environmental Influences on Endothelial Gene Expression
ENDOTHELIAL CELL GENE EXPRESSION John Matthew Jeff Herbert Supervisors: Prof. Roy Bicknell and Dr. Victoria Heath PhD thesis University of Birmingham August 2012 University of Birmingham Research Archive e-theses repository This unpublished thesis/dissertation is copyright of the author and/or third parties. The intellectual property rights of the author or third parties in respect of this work are as defined by The Copyright Designs and Patents Act 1988 or as modified by any successor legislation. Any use made of information contained in this thesis/dissertation must be in accordance with that legislation and must be properly acknowledged. Further distribution or reproduction in any format is prohibited without the permission of the copyright holder. ABSTRACT Tumour angiogenesis is a vital process in the pathology of tumour development and metastasis. Targeting markers of tumour endothelium provide a means of targeted destruction of a tumours oxygen and nutrient supply via destruction of tumour vasculature, which in turn ultimately leads to beneficial consequences to patients. Although current anti -angiogenic and vascular targeting strategies help patients, more potently in combination with chemo therapy, there is still a need for more tumour endothelial marker discoveries as current treatments have cardiovascular and other side effects. For the first time, the analyses of in-vivo biotinylation of an embryonic system is performed to obtain putative vascular targets. Also for the first time, deep sequencing is applied to freshly isolated tumour and normal endothelial cells from lung, colon and bladder tissues for the identification of pan-vascular-targets. Integration of the proteomic, deep sequencing, public cDNA libraries and microarrays, delivers 5,892 putative vascular targets to the science community. -

The Ubiquitination Enzymes of Leishmania Mexicana
The ubiquitination enzymes of Leishmania mexicana Rebecca Jayne Burge Doctor of Philosophy University of York Biology October 2020 Abstract Post-translational modifications such as ubiquitination are important for orchestrating the cellular transformations that occur as the Leishmania parasite differentiates between its main morphological forms, the promastigote and amastigote. Although 20 deubiquitinating enzymes (DUBs) have been partially characterised in Leishmania mexicana, little is known about the role of E1 ubiquitin-activating (E1), E2 ubiquitin- conjugating (E2) and E3 ubiquitin ligase (E3) enzymes in this parasite. Using bioinformatic methods, 2 E1, 13 E2 and 79 E3 genes were identified in the L. mexicana genome. Subsequently, bar-seq analysis of 23 E1, E2 and HECT/RBR E3 null mutants generated in promastigotes using CRISPR-Cas9 revealed that the E2s UBC1/CDC34, UBC2 and UEV1 and the HECT E3 ligase HECT2 are required for successful promastigote to amastigote differentiation and UBA1b, UBC9, UBC14, HECT7 and HECT11 are required for normal proliferation during mouse infection. Null mutants could not be generated for the E1 UBA1a or the E2s UBC3, UBC7, UBC12 and UBC13, suggesting these genes are essential in promastigotes. X-ray crystal structure analysis of UBC2 and UEV1, orthologues of human UBE2N and UBE2V1/UBE2V2 respectively, revealed a heterodimer with a highly conserved structure and interface. Furthermore, recombinant L. mexicana UBA1a was found to load ubiquitin onto UBC2, allowing UBC2- UEV1 to form K63-linked di-ubiquitin chains in vitro. UBC2 was also shown to cooperate with human E3s RNF8 and BIRC2 in vitro to form non-K63-linked polyubiquitin chains, but association of UBC2 with UEV1 inhibits this ability. -

Anti- Histone-H3 Antibody
anti- Histone-H3 antibody Product Information Catalog No.: FNab03890 Size: 100μg Form: liquid Purification: Immunogen affinity purified Purity: ≥95% as determined by SDS-PAGE Host: Rabbit Clonality: polyclonal Clone ID: None IsoType: IgG Storage: PBS with 0.02% sodium azide and 50% glycerol pH 7.3, -20℃ for 12 months (Avoid repeated freeze / thaw cycles.) Background HIST2H3A,histone cluster 2, H3a.It is the core component of nucleosome. Nucleosomes wrap and compact DNA into chromatin, limiting DNA accessibility to the cellular machineries which require DNA as a template. Histones thereby play a central role in transcription regulation, DNA repair, DNA replication and chromosomal stability. DNA accessibility is regulated via a complex set of post-translational modifications of histones, also called histone code, and nucleosome remodeling. HIST2H3A is Expressed during S phase, then expression strongly decreases as cell division slows down during the process of differentiation. Immunogen information Immunogen: histone cluster 2, H3a Synonyms: H3/n, H3/o, H3F2, H3FM, HIST2H3A, HIST2H3C, HIST2H3D, histone cluster 2, H3a, Histone H3, Histone H3.2, Histone H3/m, Histone H3/o Observed MW: 15-17 kDa Uniprot ID : Q71DI3 Application 1 Wuhan Fine Biotech Co., Ltd. B9 Bld, High-Tech Medical Devices Park, No. 818 Gaoxin Ave.East Lake High-Tech Development Zone.Wuhan, Hubei, China(430206) Tel :( 0086)027-87384275 Fax: (0086)027-87800889 www.fn-test.com Reactivity: Human, Mouse, Rat Tested Application: ELISA, WB, IHC, IF Recommended dilution: WB: 1:500-1:5000; IHC: 1:50-1:200; IF: 1:20-1:200 Image: Immunohistochemistry of paraffin-embedded human breast cancer tissue slide using FNab03890(Histone-H3 Antibody) at dilution of 1:50 Immunofluorescent analysis of HEK-293 cells using FNab03890 (Histone-H3 Antibody) at dilution of 1:50 and Rhodamine-Goat anti-Rabbit IgG 2 Wuhan Fine Biotech Co., Ltd. -

Protein Interactions in the Cancer Proteome† Cite This: Mol
Molecular BioSystems View Article Online PAPER View Journal | View Issue Small-molecule binding sites to explore protein– protein interactions in the cancer proteome† Cite this: Mol. BioSyst., 2016, 12,3067 David Xu,ab Shadia I. Jalal,c George W. Sledge Jr.d and Samy O. Meroueh*aef The Cancer Genome Atlas (TCGA) offers an unprecedented opportunity to identify small-molecule binding sites on proteins with overexpressed mRNA levels that correlate with poor survival. Here, we analyze RNA-seq and clinical data for 10 tumor types to identify genes that are both overexpressed and correlate with patient survival. Protein products of these genes were scanned for binding sites that possess shape and physicochemical properties that can accommodate small-molecule probes or therapeutic agents (druggable). These binding sites were classified as enzyme active sites (ENZ), protein–protein interaction sites (PPI), or other sites whose function is unknown (OTH). Interestingly, the overwhelming majority of binding sites were classified as OTH. We find that ENZ, PPI, and OTH binding sites often occurred on the same structure suggesting that many of these OTH cavities can be used for allosteric modulation of Creative Commons Attribution 3.0 Unported Licence. enzyme activity or protein–protein interactions with small molecules. We discovered several ENZ (PYCR1, QPRT,andHSPA6)andPPI(CASC5, ZBTB32,andCSAD) binding sites on proteins that have been seldom explored in cancer. We also found proteins that have been extensively studied in cancer that have not been previously explored with small molecules that harbor ENZ (PKMYT1, STEAP3,andNNMT) and PPI (HNF4A, MEF2B,andCBX2) binding sites. All binding sites were classified by the signaling pathways to Received 29th March 2016, which the protein that harbors them belongs using KEGG. -

The UBE2L3 Ubiquitin Conjugating Enzyme: Interplay with Inflammasome Signalling and Bacterial Ubiquitin Ligases
The UBE2L3 ubiquitin conjugating enzyme: interplay with inflammasome signalling and bacterial ubiquitin ligases Matthew James George Eldridge 2018 Imperial College London Department of Medicine Submitted to Imperial College London for the degree of Doctor of Philosophy 1 Abstract Inflammasome-controlled immune responses such as IL-1β release and pyroptosis play key roles in antimicrobial immunity and are heavily implicated in multiple hereditary autoimmune diseases. Despite extensive knowledge of the mechanisms regulating inflammasome activation, many downstream responses remain poorly understood or uncharacterised. The cysteine protease caspase-1 is the executor of inflammasome responses, therefore identifying and characterising its substrates is vital for better understanding of inflammasome-mediated effector mechanisms. Using unbiased proteomics, the Shenoy grouped identified the ubiquitin conjugating enzyme UBE2L3 as a target of caspase-1. In this work, I have confirmed UBE2L3 as an indirect target of caspase-1 and characterised its role in inflammasomes-mediated immune responses. I show that UBE2L3 functions in the negative regulation of cellular pro-IL-1 via the ubiquitin- proteasome system. Following inflammatory stimuli, UBE2L3 assists in the ubiquitylation and degradation of newly produced pro-IL-1. However, in response to caspase-1 activation, UBE2L3 is itself targeted for degradation by the proteasome in a caspase-1-dependent manner, thereby liberating an additional pool of IL-1 which may be processed and released. UBE2L3 therefore acts a molecular rheostat, conferring caspase-1 an additional level of control over this potent cytokine, ensuring that it is efficiently secreted only in appropriate circumstances. These findings on UBE2L3 have implications for IL-1- driven pathology in hereditary fever syndromes, and autoinflammatory conditions associated with UBE2L3 polymorphisms. -

Characterization of the Cellular Network of Ubiquitin Conjugating and Ligating Enzymes Ewa Katarzyna Blaszczak
Characterization of the cellular network of ubiquitin conjugating and ligating enzymes Ewa Katarzyna Blaszczak To cite this version: Ewa Katarzyna Blaszczak. Characterization of the cellular network of ubiquitin conjugating and ligating enzymes. Cellular Biology. Université Rennes 1, 2015. English. NNT : 2015REN1S116. tel-01547616 HAL Id: tel-01547616 https://tel.archives-ouvertes.fr/tel-01547616 Submitted on 27 Jun 2017 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. ANNÉE 2015 THÈSE / UNIVERSITÉ DE RENNES 1 sous le sceau de l’Université Européenne de Bretagne pour le grade de DOCTEUR DE L’UNIVERSITÉ DE RENNES 1 Mention : BIOLOGIE École doctorale Vie-Agro-Santé présentée par Ewa Katarzyna Blaszczak Préparée à l’unité de recherche UMR 6290, IGDR Institut de Génétique et Développement de Rennes Université Rennes 1 Thèse soutenue à Rennes le 26.06.2015 Characterization of devant le jury composé de : Aude ECHALIER-GLAZER the cellular network Maître de conférence University of Leicester / rapporteur of ubiquitin Lionel PINTARD Directeur de recherche -

Pentosan Polysulfate Binds to STRO
Wu et al. Stem Cell Research & Therapy (2017) 8:278 DOI 10.1186/s13287-017-0723-y RESEARCH Open Access Pentosan polysulfate binds to STRO-1+ mesenchymal progenitor cells, is internalized, and modifies gene expression: a novel approach of pre-programing stem cells for therapeutic application requiring their chondrogenesis Jiehua Wu1,7, Susan Shimmon1,8, Sharon Paton2, Christopher Daly3,4,5, Tony Goldschlager3,4,5, Stan Gronthos6, Andrew C. W. Zannettino2 and Peter Ghosh1,5* Abstract Background: The pharmaceutical agent pentosan polysulfate (PPS) is known to induce proliferation and chondrogenesis of mesenchymal progenitor cells (MPCs) in vitro and in vivo. However, the mechanism(s) of action of PPS in mediating these effects remains unresolved. In the present report we address this issue by investigating the binding and uptake of PPS by MPCs and monitoring gene expression and proteoglycan biosynthesis before and after the cells had been exposed to limited concentrations of PPS and then re-established in culture in the absence of the drug (MPC priming). Methods: Immuno-selected STRO-1+ mesenchymal progenitor stem cells (MPCs) were prepared from human bone marrow aspirates and established in culture. The kinetics of uptake, shedding, and internalization of PPS by MPCs was determined by monitoring the concentration-dependent loss of PPS media concentrations using an enzyme-linked immunosorbent assay (ELISA) and the uptake of fluorescein isothiocyanate (FITC)-labelled PPS by MPCs. The proliferation of MPCs, following pre-incubation and removal of PPS (priming), was assessed using the Wst-8 assay 35 method, and proteoglycan synthesis was determined by the incorporation of SO4 into their sulphated glycosaminoglycans. -

PANTHER Tutorial 2011.Pptx
PANTHER Classificaon System version 7 Huaiyu Mi Department of Preven3ve Medicine Keck School of Medicine University of Southern California USA August 27, 2011, ICSB Tutorial, Heidelberg, Germany 0 Outline • PANTHER Background – How PANTHER is built? • PANTHER Website at a Glance – Brief overview of all PANTHER pages • PANTHER Basic Func3onali3es • PANTHER Tools – Tutorial on tool usage 1 PANTHER BACKGROUND 2 PANTHER Database 3 4 What’s new in PANTHER 7.0? • Whole genome sequence coverage from 48 organisms. • New tree building algorithm (GIGA) for improved phylogene3c relaonships of genes and families. • Improved Hidden-Markov Models • Improved ortholog iden3ficaon. • Implement GO slim and PANTHER protein class for classifying genes and families. • Expanded sets of genomes and sequence iden3fier for PANTHER tools. • PANTHER Pathway diagram in SBGN. 5 PANTHER PROTEIN LIBRARY 6 What is PANTHER? PANTHER library (PANTHER/LIB) • a family tree Sequences • a mul3ple sequence alignment • an HMM PANTHER subfamily HMM models PANTHER GO slim and Protein Class Stas3c models Phylogene3c trees Mul3sequence (HMM) alignments • Molecular func3on • Biological process • Cellular component • Protein class 7 Building PANTHER Protein Family Library Select sequences Build clusters Curaon PANTHER Build MSA Protein Libray Build trees PANTHER GO slim Build and Protein Class HMMs ontology 8 Complete Gene Sets • 12 GO Reference Genomes • 36 other genomes to help reconstruct evolu3onary history – 14 bacterial genomes – 2 archaeal genomes – 2 fungal genomes – 2 plant genomes – 1 amoebozoan genome – 3 prost genomes – 2 protostome genomes – 10 deuterostome genomes 9 “Standard” set of protein coding genes and corresponding protein sequences Get list of genes in each genome • 48 genomes • Sources of genes – MOD Get list of all protein products – ENSEMBL from given source – NCBI (Entrez) • Sources of protein sequences Get mapping of – UniProt each protein – product to UniProt NCBI (Refseq) – ENSEMBL • One protein is selected for Select one each gene. -

Ube1a Suppresses Herpes Simplex Virus-1 Replication
viruses Article UBE1a Suppresses Herpes Simplex Virus-1 Replication Marina Ikeda 1 , Akihiro Ito 2, Yuichi Sekine 1 and Masahiro Fujimuro 1,* 1 Department of Cell Biology, Kyoto Pharmaceutical University, Kyoto 607-8412, Japan; [email protected] (M.I.); [email protected] (Y.S.) 2 Laboratory of Cell Signaling, School of Life Sciences, Tokyo University of Pharmacy and Life Sciences, Tokyo 192-0392, Japan; [email protected] * Correspondence: [email protected]; Tel.: +81-75-595-4717 Academic Editors: Magdalena Weidner-Glunde and Andrea Lipi´nska Received: 7 November 2020; Accepted: 1 December 2020; Published: 4 December 2020 Abstract: Herpes simplex virus-1 (HSV-1) is the causative agent of cold sores, keratitis, meningitis, and encephalitis. HSV-1-encoded ICP5, the major capsid protein, is essential for capsid assembly during viral replication. Ubiquitination is a post-translational modification that plays a critical role in the regulation of cellular events such as proteasomal degradation, protein trafficking, and the antiviral response and viral events such as the establishment of infection and viral replication. Ub-activating enzyme (E1, also named UBE1) is involved in the first step in the ubiquitination. However, it is still unknown whether UBE1 contributes to viral infection or the cellular antiviral response. Here, we found that UBE1a suppressed HSV-1 replication and contributed to the antiviral response. The UBE1a inhibitor PYR-41 increased HSV-1 production. Immunofluorescence analysis revealed that UBE1a highly expressing cells presented low ICP5 expression, and vice versa. UBE1a inhibition by PYR-41 and shRNA increased ICP5 expression in HSV-1-infected cells.