Flexdnn: Input-Adaptive On-Device Deep Learning for Efficient Mobile
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Mobiledeeppill: a Small-Footprint Mobile Deep Learning System for Recognizing Unconstrained Pill Images
MobileDeepPill: A Small-Footprint Mobile Deep Learning System for Recognizing Unconstrained Pill Images Xiao Zeng, Kai Cao, Mi Zhang Michigan State University ABSTRACT Correct identification of prescription pills based on their visual ap- pearance is a key step required to assure patient safety and facil- itate more effective patient care. With the availability of high- quality cameras and computational power on smartphones, it is possible and helpful to identify unknown prescription pills using smartphones. Towards this goal, in 2016, the U.S. National Li- brary of Medicine (NLM) of the National Institutes of Health (NIH) announced a nationwide competition, calling for the creation of a mobile vision system that can recognize pills automatically from a mobile phone picture under unconstrained real-world settings. In this paper, we present the design and evaluation of such mo- bile pill image recognition system called MobileDeepPill. The de- velopment of MobileDeepPill involves three key innovations: a triplet loss function which attains invariances to real-world nois- iness that deteriorates the quality of pill images taken by mobile phones; a multi-CNNs model that collectively captures the shape, Figure 1: Illustration of the unconstrained pill image recognition problem. color and imprints characteristics of the pills; and a Knowledge Distillation-based deep model compression framework that signif- icantly reduces the size of the multi-CNNs model without deteri- 1. INTRODUCTION orating its recognition performance. Our deep learning-based pill Smartphones with built-in high-quality cameras are ubiquitous image recognition algorithm wins the First Prize (champion) of the today. These cameras coupled with advanced computer vision al- NIH NLM Pill Image Recognition Challenge. -

Corporate Bond Market Dysfunction During COVID-19 and Lessons
Hutchins Center Working Paper # 69 O c t o b e r 2 0 2 0 Corporate Bond Market Dysfunction During COVID-19 and Lessons from the Fed’s Response J. Nellie Liang* October 1, 2020 Abstract: Changes in the financial sector since the global financial crisis appear to have increased dramatically the demand for liquidity by holders of corporate bonds beyond the ability of the markets to provide it in stress events. The March market turmoil revealed the costs of liquidity mismatch in open-end bond mutual funds. The surprisingly large redemptions of investment-grade corporate bond funds added to stresses in both the corporate bond and Treasury markets. These conditions led to unprecedented Fed interventions, which significantly reduced risk spreads and improved market functioning, with much of the improvements occurring right after the initial announcement. The improved conditions allowed companies to issue bonds, which helped them to maintain employees and investment spending. The episode suggests several areas for further study and possible reforms. * J. Nellie Liang, Hutchins Center on Fiscal and Monetary Policy, Brookings Institution ([email protected]). I would like to thank Darrell Duffie, Bill English, Anil Kashyap, Donald Kohn, Patrick Parkinson, Jeremy Stein, Adi Sunderam, David Wessel, and Alex Zhou for helpful comments and insights, and Manuel Alcalá Kovalski for excellent research assistance. THIS PAPER IS ONLINE AT https://www.brookings.edu/research/corporate- bond-market-dysfunction-during-covid-19-and- lessons-from-the-feds-response/ 1. Introduction As concerns about the pandemic’s effect on economic activity in early March escalated, asset prices began to move in unusual ways—including the prices of investment-grade corporate bonds. -

I Want to Be More Hong Kong Than a Hongkonger”: Language Ideologies and the Portrayal of Mainland Chinese in Hong Kong Film During the Transition
Volume 6 Issue 1 2020 “I Want to be More Hong Kong Than a Hongkonger”: Language Ideologies and the Portrayal of Mainland Chinese in Hong Kong Film During the Transition Charlene Peishan Chan [email protected] ISSN: 2057-1720 doi: 10.2218/ls.v6i1.2020.4398 This paper is available at: http://journals.ed.ac.uk/lifespansstyles Hosted by The University of Edinburgh Journal Hosting Service: http://journals.ed.ac.uk/ “I Want to be More Hong Kong Than a Hongkonger”: Language Ideologies and the Portrayal of Mainland Chinese in Hong Kong Film During the Transition Charlene Peishan Chan The years leading up to the political handover of Hong Kong to Mainland China surfaced issues regarding national identification and intergroup relations. These issues manifested in Hong Kong films of the time in the form of film characters’ language ideologies. An analysis of six films reveals three themes: (1) the assumption of mutual intelligibility between Cantonese and Putonghua, (2) the importance of English towards one’s Hong Kong identity, and (3) the expectation that Mainland immigrants use Cantonese as their primary language of communication in Hong Kong. The recurrence of these findings indicates their prevalence amongst native Hongkongers, even in a post-handover context. 1 Introduction The handover of Hong Kong to the People’s Republic of China (PRC) in 1997 marked the end of 155 years of British colonial rule. Within this socio-political landscape came questions of identification and intergroup relations, both amongst native Hongkongers and Mainland Chinese (Tong et al. 1999, Brewer 1999). These manifest in the attitudes and ideologies that native Hongkongers have towards the three most widely used languages in Hong Kong: Cantonese, English, and Putonghua (a standard variety of Mandarin promoted in Mainland China by the Government). -

Study on Fluorescence Spectra of Thiamine and Riboflavin YANG
3rd International Conference on Material, Mechanical and Manufacturing Engineering (IC3ME 2015) Study on Fluorescence Spectra of Thiamine and Riboflavin YANG Hui1, a*, XIAO Xue2, b, ZHAO Xuesong2, c, HU Lan1, d, ZONG Junjun1, e, and XUE Xiangfeng1,f 1New Star Application Technology Institute, Hefei, Anhui 230031, China 2Key Lab. of Environmental Optics & Technology, AIOFM, CAS, Hefei, Anhui 230031, China [email protected], [email protected], [email protected], [email protected], [email protected], [email protected] Key words: Thiamine/Vitamin B1, Riboflavin/Vitamin B2, Fluorescence Spectra, PARAFAC Abstract: This paper presents the intrinsic fluorescence characteristics of vitamin B1 and vitamin B2 with 3D fluorescence Spectrophotometer. Three strong fluorescence areas of vitamin B2 locate at λex/λem=270/525nm, 370/525nm and 450/525nm and one fluorescence areas of vitamin B1 locates at λex/λem=370/460nm were found. The influence of pH of solution are also discussed, and with the PARAFAC algorithm, 9 vitamin B2 and vitamin B1 mixed solutions are successfully decomposed, and the emission profiles, excitation profiles, central wavelengths and the concentration of the two components were retrieved precisely through about 10 iteration times. Introduction The fluorescence of a folded protein or bio-aerosol is a mixture of the fluorescence from individual aromatic component and coenzyme. Riboflavin, known as vitamin B2, is an easily absorbed micronutrient with a key role in maintaining health in humans and animals. As such, vitamin B2 is required for a wide variety of cellular processes. Vitamin B2 plays a key role in energy metabolism, and is required for the metabolism of fats, ketone bodies, carbohydrates, and proteins [1]. -

The Later Han Empire (25-220CE) & Its Northwestern Frontier
University of Pennsylvania ScholarlyCommons Publicly Accessible Penn Dissertations 2012 Dynamics of Disintegration: The Later Han Empire (25-220CE) & Its Northwestern Frontier Wai Kit Wicky Tse University of Pennsylvania, [email protected] Follow this and additional works at: https://repository.upenn.edu/edissertations Part of the Asian History Commons, Asian Studies Commons, and the Military History Commons Recommended Citation Tse, Wai Kit Wicky, "Dynamics of Disintegration: The Later Han Empire (25-220CE) & Its Northwestern Frontier" (2012). Publicly Accessible Penn Dissertations. 589. https://repository.upenn.edu/edissertations/589 This paper is posted at ScholarlyCommons. https://repository.upenn.edu/edissertations/589 For more information, please contact [email protected]. Dynamics of Disintegration: The Later Han Empire (25-220CE) & Its Northwestern Frontier Abstract As a frontier region of the Qin-Han (221BCE-220CE) empire, the northwest was a new territory to the Chinese realm. Until the Later Han (25-220CE) times, some portions of the northwestern region had only been part of imperial soil for one hundred years. Its coalescence into the Chinese empire was a product of long-term expansion and conquest, which arguably defined the egionr 's military nature. Furthermore, in the harsh natural environment of the region, only tough people could survive, and unsurprisingly, the region fostered vigorous warriors. Mixed culture and multi-ethnicity featured prominently in this highly militarized frontier society, which contrasted sharply with the imperial center that promoted unified cultural values and stood in the way of a greater degree of transregional integration. As this project shows, it was the northwesterners who went through a process of political peripheralization during the Later Han times played a harbinger role of the disintegration of the empire and eventually led to the breakdown of the early imperial system in Chinese history. -

The Yu of Yi-Mei and Chang-Wan in Kwangtung,S Xin-Hui Xian
Genealogy and History: The Yu of Yi-mei and Chang-wan in Kwangtung,s Xin-hui xian By L . E ve A r m e n t r o u t M a Chinese / Chinese American History Project, El Cerrito CAt USA A number of reasons have been advanced to explain why formal clan and lineage1 organizations first became widespread in China during the Song dynasty. Among these is the suggestion that the “ new ’, men (many of obscure origins), brought into the bureaucracy by the Song emphasis on the しonfucian examination system, desired to strength en the fabric of society. One means they chose was encouraging the revitalization and extension of clan and lineage organizations. They did tms in order to fill the void created by the decline of the aristocratic (“ great”) families (Twitchett 1959: 100-101). If these assumptions are true, one would expect to find a certain amount of the “ ordinary ” in the genealogies kept by these groups. 1 his was, indeed, often the case. A good example is that of the Yu 余 lineage that I will introduce in this essay. These Yus lived in the villages of Yi-mei 乂美 and Chang-wan 長湾 in Kwangtung’s Xin-hui xian 新会縣. As we shall see, they provide an interesting case study of a lineage that had its brief moment of glory, constructed a genealogy that helped to reflect this moment, and then faded into relative obscurity. In light of what we know about the distribution of wealth and power in the southern Chinese countryside, there must have been thousands of lineages similar to this one. -

中国人的姓名 王海敏 Wang Hai Min
中国人的姓名 王海敏 Wang Hai min last name first name Haimin Wang 王海敏 Chinese People’s Names Two parts Last name First name 姚明 Yao Ming Last First name name Jackie Chan 成龙 cheng long Last First name name Bruce Lee 李小龙 li xiao long Last First name name The surname has roughly several origins as follows: 1. the creatures worshipped in remote antiquity . 龙long, 马ma, 牛niu, 羊yang, 2. ancient states’ names 赵zhao, 宋song, 秦qin, 吴wu, 周zhou 韩han,郑zheng, 陈chen 3. an ancient official titles 司马sima, 司徒situ 4. the profession. 陶tao,钱qian, 张zhang 5. the location and scene in residential places 江jiang,柳 liu 6.the rank or title of nobility 王wang,李li • Most are one-character surnames, but some are compound surname made up of two of more characters. • 3500Chinese surnames • 100 commonly used surnames • The three most common are 张zhang, 王wang and 李li What does my name mean? first name strong beautiful lively courageous pure gentle intelligent 1.A person has an infant name and an official one. 2.In the past,the given names were arranged in the order of the seniority in the family hierarchy. 3.It’s the Chinese people’s wish to give their children a name which sounds good and meaningful. Project:Search on-Line www.Mandarinintools.com/chinesename.html Find Chinese Names for yourself, your brother, sisters, mom and dad, or even your grandparents. Find meanings of these names. ----What is your name? 你叫什么名字? ni jiao shen me ming zi? ------ 我叫王海敏 wo jiao Wang Hai min ------ What is your last name? 你姓什么? ni xing shen me? (你贵姓?)ni gui xing? ------ 我姓 王,王海敏。 wo xing wang, Wang Hai min ----- What is your nationality? 你是哪国人? ni shi na guo ren? ----- I am chinese/American 我是中国人/美国人 Wo shi zhong guo ren/mei guo ren 百家 姓 bai jia xing 赵(zhào) 钱(qián) 孙(sūn) 李(lǐ) 周(zhōu) 吴(wú) 郑(zhèng) 王(wán 冯(féng) 陈(chén) 褚(chǔ) 卫(wèi) 蒋(jiǎng) 沈(shěn) 韩(hán) 杨(yáng) 朱(zhū) 秦(qín) 尤(yóu) 许(xǔ) 何(hé) 吕(lǚ) 施(shī) 张(zhāng). -

Xiao Liu (刘潇) Ph.D
C URRICULUM V ITAE U PDATED: J UNE 2019 Xiao Liu (刘潇) Ph.D. THE PROGRAM IN ATMOSPHERIC AND OCEANIC SCIENCES, PRINCETON UNIVERSITY 201 Forrestal Rd, Rm 301, Princeton, NJ 08540; +1 (609)452-6673 [email protected] | http://scholar.princeton.edu/xiaoliu EDUCATION 2017 Ph.D. Ocean Sciences, University of Southern California. Advisors: Naomi M. Levine (2013-2017), Burt Jones (2011-2012) 2011 M.S. Marine Biology, Virginia Institute of Marine Science, College of William and Mary. Advisor: Walker O. Smith, Jr. 2008 B.S. Biological Sciences w/ marine concentration, Ocean University of China ACADEMIC POSITIONS 2017-now Postdoctoral Research Associate, Program in Atmospheric and Oceanic Sciences, Princeton University; Visiting Scientist, NOAA Geophysical Fluid Dynamics Laboratory 2013,14 Visiting Scholar (summer), King Abdullah University of Science and Technology 2012-14 Teaching Assistant (BISC-120L, 220L), Department of Biological Sciences, University of Southern California 2011, 14-17 Graduate Research Fellow, Department of Earth Sciences, University of Southern California 2008-11 Graduate Research Assistant, Virginia Institute of Marine Science, College of William and Mary HONORS, AWARDS, AND GRANTS 2020-23 (Pending) Simons Postdoctoral Fellowship in Marine Microbial Ecology ($261,000 requested) 2015-17 Graduate School Top-off Fellowship, University of Southern California ($20,000) 2014-17 NASA Earth and Space Sciences Graduate Fellowship (NESSF, $89,400) 2014 IOCCG Sponsored Participant for the Ocean Optics Summer Lecture Series at Villefranche-sur- Mer, France (full travel support) 2013 Award for Outstanding Teaching (Fa. BISC-120L, top 20%), University of Southern California 2013 OCB Sponsored Participant for the Satellite Remote Sensing Training Program at Cornell University (tuition and full travel support) 2013,14 Award for Outstanding Teaching (Sp. -

English Versions of Chinese Authors' Names in Biomedical Journals
Dialogue English Versions of Chinese Authors’ Names in Biomedical Journals: Observations and Recommendations The English language is widely used inter- In English transliteration, two-syllable Forms of Chinese Authors’ Names nationally for academic purposes. Most of given names sometimes are spelled as two in Biomedical Journals the world’s leading life-science journals are words (Jian Hua), sometimes as one word We recently reviewed forms of Chinese published in English. A growing number (Jianhua), and sometimes hyphenated authors’ names accompanying English- of Chinese biomedical journals publish (Jian-Hua). language articles or abstracts in various abstracts or full papers in this language. Occasionally Chinese surnames are Chinese and Western biomedical journals. We have studied how Chinese authors’ two syllables (for example, Ou-Yang, Mu- We found considerable inconsistency even names are presented in English in bio- Rong, Si-Ma, and Si-Tu). Editors who are within the same journal or issue. The forms medical journals. There is considerable relatively unfamiliar with Chinese names were in the following categories: inconsistency. This inconsistency causes may mistake these compound surnames for • Surname in all capital letters followed by confusion, for example, in distinguishing given names. hyphenated or closed-up given name, for surnames from given names and thus cit- China has 56 ethnic groups. Names example, ing names properly in reference lists. of minority group members can differ KE Zhi-Yong (Chinese Journal of In the current article we begin by pre- considerably from those of Hans, who Contemporary Pediatrics) senting as background some features of constitute most of the Chinese population. GUO Liang-Qian (Chinese Chinese names. -
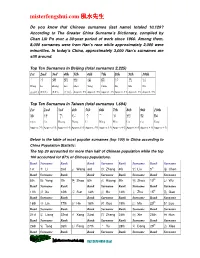
Misterfengshui.Com 風水先生
misterfengshui.com 風水先生 Do you know that Chinese surnames (last name) totaled 10,129? According to The Greater China Surname’s Dictionary, compiled by Chan Lik Pu over a 30-year period of work since 1960. Among them, 8,000 surnames were from Han’s race while approximately 2,000 were minorities. In today’s China, approximately 3,000 Han’s surnames are still around. Top Ten Surnames In Beijing (total surnames 2,225) 1st 2nd 3rd 4th 5th 6th 7th 8th 9th 10th 王 李 張 劉 趙 楊 陳 徐 馬 吳 Wang Li Zhang Liu Zhao Yang Chen Xu Ma Wu (10.6% ) (9.6%) (9.6%) (7.7% ) Approx. 5% Approx. 5% Approx. 4% Approx. 4% Approx. 4% Approx. 3% Top Ten Surnames In Taiwan (total surnames 1,694) 1st 2nd 3rd 4th 5th 6th 7th 8th 9th 10th 陳 林 黃 張 李 王 吳 劉 蔡 楊 Chen Lin Huang Zhang Li Wang Wux. Liu Cai Yang Approx .7% Approx 6 % Approx 6 % Approx 6 % Approx. 5% Approx 5 % Approx 4 % Approx 4 % Approx 4 % Approx 4 % Below is the table of most popular surnames (top 100) in China according to China Population Statistic: The top 20 accounted for more than half of Chinese population while the top 100 accounted for 87% of Chinese populations. Rank Surname Rank Rank Surname Rank Surname Rank Surname 1st 李 Li 2nd 王 Wang 3rd 張 Zhang 4th 劉 Liu 5th 陳 Chen Rank Surname Rank Rank Surname Rank Surname Rank Surname 6th 楊 Yang 7th 趙 Zhao 8th 黃 Huang 9th 周 Zhou 10 th 吳 Wu Rank Surname Rank Rank Surname Rank Surname Rank Surname 11th 徐 Xu 12th 孫 Sun 13th 胡 Hu 14th 朱 Zhu 15 th 高 Gao Rank Surname Rank Rank Surname Rank Surname Rank Surname 16th 林 Lin 17th 何 He 18th 郭 Guo 19th 馬 Ma 20 th 羅 Luo Rank -

CJK NACO Searching
1/13/2017 CJK NACO Searching Prepared by Ryan Finnerty and Shi Deng, UC San Diego Library With assistance by Hideyuki Morimoto, Columbia University Libraries Thanks to Erica Chang (Univ. of Hawai’i) and Sarah Byun (LC) for providing Korean examples and search tips. NACO Searching: Purpose & Outlines • Keep the database clean by searching before contributing • Discuss why searching is important with CJK examples • To prevent duplicate NARs • To prevent conflict in authorized access points and variant access points • To gather information from existing bibliographic records • To identify existing records that may need to be evaluated and re‐coded for RDA • To identify bibliographic records that may need BFM • Searching tips in Connexion 2 1 1/13/2017 Why Search? To Prevent Duplicate NARs • Duplicates are normally created by inefficient searching and the 24‐ hour upload gap in the Name authority file. • Before creating a name authority record: 1. Search the OCLC authority file for the authorized access point, including variant forms of the access point. 2. In addition, search WorldCat for bibliographic records that contain the authorized access point or variant forms. • If you put your record in a save file, remember to search again if more than 24 hours have passed. • If you encounter duplicate records in the authority file, be sure to notify your NACO Coordinator so the records can be reported to LC. 3 Duplicate NARs for Personal Names (1) • 24 hours rule: If you put your record in a save file, remember to search again if more than 24 hours have passed. Entered: May 16, 2016 Entered: May 10, 2016 010 no2016066120 010 n 2016025569 046 ǂf 1983 ǂ2 edtf 046 ǂf 1983 ǂ2 edtf 1001 Tanaka, Yūsuke, ǂd 1983‐ 1001 Tanaka, Yūsuke, ǂd 1983‐ 4001 田中祐輔, ǂd 1983‐ 4001 田中祐輔, ǂd 1983‐ 670 Gendai Chūgoku no Nihongo kyōikushi, 2015: 670 Gendai Chūgoku no Nihongo kyōikushi, 2015: ǂbt.p. -

527 Títulos De Livros Antigos De Medicina Chinesa. Lista Organizada Pela People's Medical Publishing House - China
527 Títulos de Livros Antigos de Medicina Chinesa. Lista organizada pela People's Medical Publishing House - China www.medicinaclassicachinesa.org Vários desses livros podem ser encontrados em versão gratuita no site http://www.zysj.com.cn/lilunshuji/5index.html 中文名 作者名(字号) 出书年代 Titulo em 拼音 英文名 Nome Real ou Literário Data em que escrito Chinês Pin Yin Titulo em Inglês do Autor ou publicado. Zhang Zhong‐hua 张仲 华 (Style 号 Zhang Ai‐lu 1. 爱庐医案 Ài Lú Yī Àn [Zhang] Ai‐lu’s Case Records 张爱庐) 2. 敖氏伤寒金镜 Ao’s Golden Mirror Records for Cold 录 Áo Shì Shāng Hán Jīn Jìng Lù Damage Du Qing‐bi 杜清碧 1341 3. 百草镜 Băi Căo Jìng Mirror of the Hundred Herbs Zhao Xue‐kai 赵学楷 Qing 4. 白喉条辨 Bái Hóu Tiáo Biàn Systematic Analysis of Diphtheria Chen Bao‐shan 陈宝善 1887 5. 百一选方 Băi Yī Xuăn Fāng Selected Formulas Wang Qiu 王璆 1196 Wan Quan 万全 (Style: 6. 保命歌诀 Băo Mìng Gē Jué Verses for Survival Wan Mi 万密) 7. 保婴撮要 Băo Yīng Cuō Yào Essentials of Infant Care Xue Kai 薛凯 1555 Ge Hong 葛洪 (Styles: Ge Zhi‐chuan 葛稚川, 8. 抱朴子内外篇 Bào Pŭ Zĭ Nèi Wài Piān The Inner and Outer Chapters of Bao Pu‐zi Bao Pu‐zi 抱朴子) Wen Ren Qi Nian 闻人耆 9. 备急灸法 Bèi Jí Jiŭ Fă Moxibustion Techniques for Emergency 年 1226 Important Formulas Worth a Thousand 7th century; 652 10. 备急千金要方 Bèi Jí Qiān Jīn Yào Fāng Gold Pieces for Emergency Sun Si‐miao 孙思邈 (Tang) Wang Ang 汪昂 (Style: 11. 本草备要 Bĕn Căo Bèi Yào Essentials of Materia Medica Wang Ren‐an) 1664 (Qing) Zhang Bing‐cheng 张秉 12.