Cyberling 2009 Workshop: Towards a Cyberinfrastructure for Linguistics Workshop Report Emily M
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

The Violability of Backness in Retroflex Consonants
The violability of backness in retroflex consonants Paul Boersma University of Amsterdam Silke Hamann ZAS Berlin February 11, 2005 Abstract This paper addresses remarks made by Flemming (2003) to the effect that his analysis of the interaction between retroflexion and vowel backness is superior to that of Hamann (2003b). While Hamann maintained that retroflex articulations are always back, Flemming adduces phonological as well as phonetic evidence to prove that retroflex consonants can be non-back and even front (i.e. palatalised). The present paper, however, shows that the phonetic evidence fails under closer scrutiny. A closer consideration of the phonological evidence shows, by making a principled distinction between articulatory and perceptual drives, that a reanalysis of Flemming’s data in terms of unviolated retroflex backness is not only possible but also simpler with respect to the number of language-specific stipulations. 1 Introduction This paper is a reply to Flemming’s article “The relationship between coronal place and vowel backness” in Phonology 20.3 (2003). In a footnote (p. 342), Flemming states that “a key difference from the present proposal is that Hamann (2003b) employs inviolable articulatory constraints, whereas it is a central thesis of this paper that the constraints relating coronal place to tongue-body backness are violable”. The only such constraint that is violable for Flemming but inviolable for Hamann is the constraint that requires retroflex coronals to be articulated with a back tongue body. Flemming expresses this as the violable constraint RETRO!BACK, or RETRO!BACKCLO if it only requires that the closing phase of a retroflex consonant be articulated with a back tongue body. -

Standards for Language Coding: the ISO 639 Family
Standards for language coding: the ISO 639 family Rebecca Guenther Library of Congress Jan. 8, 2010 ISO Standards development !! ISO consists of Technical Committees (TC) with subcommittees (SC) !! ISO language coding standards are maintained by !! TC 37/SC2 (Terminology and other language and content resources ) !! TC 46/SC4 (Information and documentation) LSA Annual Meeting 2 ISO 639 standards !! ISO 639-1: 2-character codes (136 codes) !! ISO 639-2: 3-character codes (450+) !! ISO 639-3: 3-character codes (7700+) !! ISO 639-4: principles !! ISO 639-5: 3-character codes (114) !! ISO 639-6: 4-character codes (??) LSA Annual Meeting 3 ISO 639 Joint Advisory Committee !! Established to advise the RAs for ISO 639-1 and ISO 639-2 !! Rotating chairs: Infoterm (for TC37) and Library of Congress (for TC46) !! Committee consists of 3 members of each TC, representatives of each registration authority and up to 6 observers !! Coordinates development of different parts of ISO 639 LSA Annual Meeting 4 ISO 639 language coding principles !! Language codes are not changed for stability of standard !! If a language code is retired it is not reassigned to something else !! Programming languages are not in scope !! Only deals with languages; codes from other ISO standards may be added as needed for more granularity, e.g. country codes, script codes LSA Annual Meeting 5 ISO 639-1 !! First published 1967 !! Covers major languages of the world !! Alpha-2 codes; only 676 possible combinations !! Developed for use in terminology applications !! Consists of -

Vowel Acoustics Reliably Differentiate Three Coronal Stops of Wubuy Across Prosodic Contexts
Vowel acoustics reliably differentiate three coronal stops of Wubuy across prosodic contexts Rikke L. BundgaaRd-nieLsena, BRett J. BakeRb, ChRistian kRoosa, MaRk haRveyc and CatheRine t. Besta,d aMARCS Auditory Laboratories, University of Western Sydney bSchool of Languages and Linguistics, University of Melbourne cSchool of Humanities and Social Science, University of Newcastle dHaskins Laboratories, New Haven Abstract The present study investigates the acoustic differentiation of three coronal stops in the indigenous Australian language Wubuy. We test independent claims that only VC (vowel-into-consonant) transitions provide robust acoustic cues for retroflex as compared to alveolar and dental coronal stops, with no differentiating cues among these three coronal stops evident in CV (consonant-into-vowel) transitions. The four-way stop distinction /t, t̪ , ʈ, c/ in Wubuy is contrastive word-initially (Heath 1984) and by implication utterance-initially, i.e., in CV-only contexts, which suggests that acoustic differentiation should be expected to occur in the CV transitions of this language, including in initial positions. Therefore, we examined both VC and CV formant transition information in the three target coronal stops across VCV (word-internal), V#CV (word-initial but utterance-medial) and ##CV (word- and utterance-initial), for /a / vowel contexts, which provide the optimal environment for investigating formant transitions. Results confirm that these coro- nal contrasts are maintained in the CVs in this vowel context, and in all three posi- tions. The patterns of acoustic differences across the three syllable contexts also provide some support for a systematic role of prosodic boundaries in influencing the degree of coronal stop differentiation evident in the vowel formant transitions. -

Tags for Identifying Languages File:///C:/W3/International/Draft-Langtags/Draft-Phillips-Lan
Tags for Identifying Languages file:///C:/w3/International/draft-langtags/draft-phillips-lan... Network Working Group A. Phillips, Ed. TOC Internet-Draft webMethods, Inc. Expires: October 7, 2004 M. Davis IBM April 8, 2004 Tags for Identifying Languages draft-phillips-langtags-02 Status of this Memo This document is an Internet-Draft and is in full conformance with all provisions of Section 10 of RFC2026. Internet-Drafts are working documents of the Internet Engineering Task Force (IETF), its areas, and its working groups. Note that other groups may also distribute working documents as Internet-Drafts. Internet-Drafts are draft documents valid for a maximum of six months and may be updated, replaced, or obsoleted by other documents at any time. It is inappropriate to use Internet-Drafts as reference material or to cite them other than as "work in progress." The list of current Internet-Drafts can be accessed at http://www.ietf.org/ietf/1id-abstracts.txt. The list of Internet-Draft Shadow Directories can be accessed at http://www.ietf.org/shadow.html. This Internet-Draft will expire on October 7, 2004. Copyright Notice Copyright (C) The Internet Society (2004). All Rights Reserved. Abstract This document describes a language tag for use in cases where it is desired to indicate the language used in an information object, how to register values for use in this language tag, and a construct for matching such language tags, including user defined extensions for private interchange. Table of Contents 1. Introduction 2. The Language Tag 2.1 Syntax 2.2 Language Tag Sources 2.2.1 Pre-Existing RFC3066 Registrations 1 of 20 08/04/2004 11:03 Tags for Identifying Languages file:///C:/w3/International/draft-langtags/draft-phillips-lan.. -
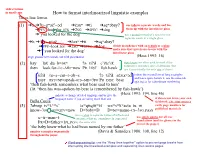
How to Format Interlinearized Linguistic Examples Three-Line Format
abbreviations in small caps How to format interlinearized linguistic examples Three-line format (1) ➜a.➜ʔu–gʷəč’–əd ➜čəxʷ ➜ti ➜sqʷəbayʔ use tabs to separate words and line them up with the interlinear gloss ➜PFV–look.for–ICS ➜2SG ➜SPEC ➜dog ➜‘you looked for the dog’ use a period instead of a space to join separate words in a single gloss ➜b.➜ *ʔu–gʷəč ➜čəxʷ ➜ti ➜sqʷəbayʔ ➜PFV–look.for ➜2SG ➜SPEC ➜dog divide morphemes with an n-dash or a plus; make sure they match one-to-one with the ➜*‘you looked for the dog’ interlinear gloss align glosses with words, not with punctuation (Hess 1993: 16) equal signs are often used to mark clitic- (2) hay la%–du–b=#x" !# ti!i& c’i%c’i% boundaries and other special divisions (but then look.for–LC–MD=now PR DIST fish.hawk use it consistently for only one of these) indent the second line of long examples ti!i& tu=s=cut–t–#b=s !# ti!i& s$#tx"#d and leave space before it; use the same tab DIST PST=NP=speak–ICS–MD=3PO PR DIST bear spacing as for subordinate numbering ‘then fish-hawk remembers what bear said to him’ (lit. ‘then his was-spoken-by-bear is remembered by fish-hawk’) indicate a change of cited language and/or give the (Hess 1993: 194, line 46) language name if you are using more than one if data is not from your own Bella Coola fieldwork, cite your sources (with page numbers for (3) !a&nap–is=k"=c’ ta=qiiqtii=t% wa=s=k"acta–tu–m published material) know–3SG:3SG=QTV=now D=baby=D D=NP=name–CS–3SG.PASS use a colon to separate values of inflectional use single quotes for all free categories that are cumulatively expressed x=ti=man=& translations (and for glosses in the by the same affix PR=D=father=1PL.PO text of the paper) ‘the baby knew what he had been named by our father’ number examples sequentially (Davis & Saunders 1980: 108, line 12) throughout the paper Word-processing tip: use the “Keep lines together” option to prevent page breaks from interrupting interlinearized examples and separating lines across pages. -

Ethnologue: Languages of Honduras Twentieth Edition Data
Ethnologue: Languages of Honduras Twentieth edition data Gary F. Simons and Charles D. Fennig, Editors Based on information from the Ethnologue, 20th edition: Simons, Gary F. and Charles D. Fennig (eds.). 2017. Ethnologue: Languages of the World, Twentieth edition. Dallas, Texas: SIL International. Online: http://www.ethnologue.com. For personal use only Permission to distribute or reuse this work (in whole or in part) may be obtained through the Copyright Clearance Center at http://www.copyright.com. SIL International, 7500 West Camp Wisdom Road, Dallas, Texas 75236-5699 USA Web: www.sil.org, Phone: +1 972 708 7404, Email: [email protected] Ethnologue: Languages of Honduras 2 Contents List of Abbreviations 3 How to Use This Digest 4 Country Overview 6 Language Status Profile 7 Statistical Summaries 8 Alphabetical Listing of Languages 11 Language Map 14 Languages by Population 15 Languages by Status 16 Languages by Department 18 Languages by Family 19 Language Code Index 20 Language Name Index 21 Bibliography 22 Copyright © 2017 by SIL International All rights reserved. No part of this publication may be reproduced, redistributed, or transmitted in any form or by any means—electronic, mechanical, photocopying, recording, or otherwise—without the prior written permission of SIL International, with the exception of brief excerpts in articles or reviews. Ethnologue: Languages of Honduras 3 List of Abbreviations A Agent in constituent word order alt. alternate name for alt. dial. alternate dialect name for C Consonant in canonical syllable patterns CDE Convention against Discrimination in Education (1960) Class Language classification CPPDCE Convention on the Protection and Promotion of the Diversity of Cultural Expressions (2005) CSICH Convention for the Safeguarding of Intangible Cultural Heritage (2003) dial. -

Automatic Interlinear Glossing for Under-Resourced Languages Leveraging Translations
Automatic Interlinear Glossing for Under-Resourced Languages Leveraging Translations Xingyuan Zhaoy, Satoru Ozakiy, Antonios Anastasopoulosz, Graham Neubigy, Lori Leviny yLanguage Technologies Institute, Carnegie Mellon University zDepartment of Computer Science, George Mason University {xingyuanz,sozaki}@andrew.cmu.edu [email protected] {gneubig,lsl}@cs.cmu.edu Abstract Interlinear Glossed Text (IGT) is a widely used format for encoding linguistic information in language documentation projects and scholarly papers. Manual production of IGT takes time and requires linguistic expertise. We attempt to address this issue by creating automatic gloss- ing models, using modern multi-source neural models that additionally leverage easy-to-collect translations. We further explore cross-lingual transfer and a simple output length control mech- anism, further refining our models. Evaluated on three challenging low-resource scenarios, our approach significantly outperforms a recent, state-of-the-art baseline, particularly improving on overall accuracy as well as lemma and tag recall. 1 Introduction The under-documentation of endangered languages is an imminent problem for the linguistic commu- nity. Of the 7,000 languages in the world, an estimated 50% will face extinction in the coming decades, while around 35–42% still remain substantially undocumented (Austin and Sallabank, 2011; Seifart et al., 2018). Perhaps these numbers are no surprise when one acknowledges the difficulty of language documentation – fieldwork demands time, cultural understanding, linguistic expertise, and financial sup- port among a myriad of other factors. Consequently, an important task for the linguistic community is to facilitate the otherwise daunting documentation process as much as possible. Documentation is not a cure-all for language loss, but it is an important part of language preservation; even in an unfortunate worst-case scenario where a language does disappear, a permanent record of the language is saved for posterity, and could hopefully be useful for revitalization purposes. -

Labphon 7: Seventh Conference on Laboratory Phonology
LabPhon 7: Seventh Conference on Laboratory Phonology This is an archive site LabPhon 7 Seventh Conference on Laboratory Phonology Thursday 29 June - Saturday 1 July 2000 Hosted by: University of Nijmegen (KUN) Max Planck Institute for Psycholinguistics (MPI) Location: Collegezalencomplex Mercatorpad 1 University of Nijmegen The Netherlands Themes and speakers: Phonological encoding Willem Levelt, discussant Max Planck Institute for Psycholinguistics Pat Keating, invited speaker University of California, Los Angeles Phonological processing Anne Cutler, discussant Max Planck Institute for Psycholinguistics Janet Pierrehumbert, invited speaker Northwestern University Field work and phonological theory Leo Wetzels, discussant Free University of Amsterdam Didier Demolin, invited speaker Free University of Brussels Speech technology and phonological theory Louis Boves,discussant University of Nijmegen Aditi Lahiri, invited speaker University of Konstanz Phonology-phonetics interface Bruce Hayes, discussant University of California, Los Angeles Nick Clements, invited speaker CNRS, Paris John Ohala, invited speaker University of California, Berkeley Important dates: 14 January 2000 Deadline for receipt of abstracts 1 March 2000 Notification of accceptance file:///C|/Users/warrenpa/OneDrive%20-%20Victoria%20University%20of%20Wellington%20-%20STAFF/labphon7/index.html[14/03/2019 3:58:15 PM] LabPhon 7: Seventh Conference on Laboratory Phonology 28 April 2000 Deadline for receipt of draft papers 1 June 2000 Deadline for excursion sign-up Deadline for receipt of advance registration payment 29 June 2000 Conference begins 1 December 2000 Deadline for receipt of final papers Organizing committee: Carlos Gussenhoven, KUN Toni Rietveld, KUN Natasha Warner, MPI Contact information: Please note: If you have been using the email address [email protected], please do not use it anymore. -

The Diachronic Emergence of Retroflex Segments in Three Languages* 1
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Hochschulschriftenserver - Universität Frankfurt am Main The diachronic emergence of retroflex segments in three languages* Silke Hamann ZAS (Centre for General Linguistics), Berlin [email protected] The present study shows that though retroflex segments can be considered articulatorily marked, there are perceptual reasons why languages introduce this class into their phoneme inventory. This observation is illustrated with the diachronic developments of retroflexes in Norwegian (North- Germanic), Nyawaygi (Australian) and Minto-Nenana (Athapaskan). The developments in these three languages are modelled in a perceptually oriented phonological theory, since traditional articulatorily-based features cannot deal with such processes. 1 Introduction Cross-linguistically, retroflexes occur relatively infrequently. From the 317 languages of the UPSI database (Maddieson 1984, 1986), only 8.5 % have a voiceless retroflex stop [ˇ], 7.3 % a voiced stop [Í], 5.3 % a voiceless retroflex fricative [ß], 0.9 % a voiced fricative [¸], and 5.9 % a retroflex nasal [˜]. Compared to other segmental classes that are considered infrequent, such as a palatal nasal [¯], which occurs in 33.7 % of the UPSID languages, and the uvular stop [q], which occurs in 14.8 % of the languages, the percentages for retroflexes are strikingly low. Furthermore, typically only large segment inventories have a retroflex class, i.e. at least another coronal segment (apical or laminal) is present, as in Sanskrit, Hindi, Norwegian, Swedish, and numerous Australian Aboriginal languages. Maddieson’s (1984) database includes only one exception to this general tendency, namely the Dravidian language Kota, which has a retroflex as its only coronal fricative. -

For Linguists User's Guide
ExPex for linguists Example formatting, glosses, and reference (1) a. Maryi ist sicher, [dass es den Hans nicht storen¨ wurde¨ [seiner Freundin Mary is sure that it the-ACC Hans not annoy would his-DAT girlfriend-DAT ihri Herz auszuschutten¨ ]]. her-ACC heart-ACC out to throw ‘Mary is sure that it would not annoy John to reveal her heart to his girlfriend.’ b. Maryi ist sicher, [dass seiner Freunden ihri Herz auszuchutten¨ Mary is sure that his-DAT girlfriend-DAT her-ACC heart-ACC out to throw [dem Hans nicht schaden wurde¨ ]]. the-DAT Hans not damage would ‘Mary is sure that to reveal her heart to his girlfriend would not damage John.’ User’s Guide John Frampton [email protected] January 2014 Version 5.0 Contents 1 Introduction ............................... 1 1.1 Changes ............................. 1 1.2 LaTex/Texcooperation . 2 1.3 Acknowledgements . 3 2 Somepreliminaryexamples . 4 3 XKVparameterization . 8 4 Exampleswithoutparts . 10 4.1 Explicit example numbers; Formatting the example number ..... 13 5 Exampleswithlabeledparts:Basics . 15 5.1 nopreamble ......................... 17 5.2 Stipulatedlabels . 18 6 More on examples, with and without labeled parts . 18 6.1 Anchoring ........................... 18 6.2 Formatting the labels . 19 6.3 Aligning the labels . 21 6.4 Relative versus fixed dimensions . 23 6.5 Userdesignedlabeling . 23 6.6 The parameter sampleexno ................... 25 6.7 IJAL style format of multiline examples . 26 6.8 Footnotes and endnotes . 28 7 Userdefinedstyles ........................... 30 8 Judgmentmarks ............................ 32 9 Glosses ................................ 34 9.1 Parameters .......................... 36 9.2 Exceptional \gla items ..................... 39 10 Nlevel glosses; an alternate coding syntax . -

Using Interlinear Glosses As Pivot in Low-Resource Multilingual Machine Translation
Using Interlinear Glosses as Pivot in Low-Resource Multilingual Machine Translation Zhong Zhou Lori Levin David R. Mortensen Alex Waibel Carnegie Mellon University Carnegie Mellon University Carnegie Mellon University Carnegie Mellon University [email protected] [email protected] [email protected] Karlsruhe Institute of Technology [email protected] Abstract We demonstrate a new approach to Neu- ral Machine Translation (NMT) for low- resource languages using a ubiquitous lin- guistic resource, Interlinear Glossed Text (IGT). IGT represents a non-English sen- Figure 1: Multilingual NMT. tence as a sequence of English lemmas and morpheme labels. As such, it can serve as a pivot or interlingua for NMT. Our contribution is four-fold. Firstly, we pool IGT for 1,497 languages in ODIN (54,545 glosses) and 70,918 glosses in Ara- paho and train a gloss-to-target NMT sys- Figure 2: Using interlinear glosses as pivot to translate in tem from IGT to English, with a BLEU multilingual NMT in Hmong, Chinese, and German. score of 25.94. We introduce a multi- lingual NMT model that tags all glossed resource settings (Firat et al.(2016)Firat, Cho, text with gloss-source language tags and and Bengio; Zoph and Knight(2016); Dong train a universal system with shared atten- et al.(2015)Dong, Wu, He, Yu, and Wang; Gillick tion across 1,497 languages. Secondly, we et al.(2016)Gillick, Brunk, Vinyals, and Subra- use the IGT gloss-to-target translation as manya; Al-Rfou et al.(2013)Al-Rfou, Perozzi, a key step in an English-Turkish MT sys- and Skiena; Zhou et al.(2018)Zhou, Sperber, and tem trained on only 865 lines from ODIN. -

Retroflexion and Retraction Revised∗
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Hochschulschriftenserver - Universität Frankfurt am Main Retroflexion and Retraction Revised∗ Silke Hamann, OTS Utrecht Abstract Arguing against Bhat’s (1974) claim that retroflexion cannot be correlated with retraction, the present article illustrates that retroflexes are always retracted, though retraction is not claimed to be a sufficient criterion for retroflexion. The cooccurrence of retraction with retroflexion is shown to make two further implications; first, that non-velarized retroflexes do not exist, and second, that secondary palatalization of retroflexes is phonetically impossible. The process of palatalization is shown to trigger a change in the primary place of articulation to non-retroflex. Phonologically, retraction has to be represented by the feature specification [+back] for all retroflex segments. 1 Introduction Retroflex consonants are usually described as sounds articulated with a bent-backwards tongue tip and a postalveolar place of articulation, e.g. by Catford (1977: 150) or Trask (1996: 308). As illustrated in Hamann (in prep.), a number of retroflex segments deviate from this definition. The retroflex stops and nasals in Hindi, for example, do not show a bending backwards of the tongue tip but these sounds are still considered to be phonetically and phonologically retroflex. The same holds for the voiced and voiceless postalveolar fricatives in Polish and Russian (ibid.), which are articulated without active involvement of the tongue tip in the constriction (though the tip is raised from its resting position) and with a flat tongue body. The class of retroflexes shows considerable articulatory variation regarding both the articulator (i.e.