Mapreduce Service
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Combined Documents V2
Outline: Combining Brainstorming Deliverables Table of Contents 1. Introduction and Definition 2. Reference Architecture and Taxonomy 3. Requirements, Gap Analysis, and Suggested Best Practices 4. Future Directions and Roadmap 5. Security and Privacy - 10 Top Challenges 6. Conclusions and General Advice Appendix A. Terminology Glossary Appendix B. Solutions Glossary Appendix C. Use Case Examples Appendix D. Actors and Roles 1. Introduction and Definition The purpose of this outline is to illustrate how some initial brainstorming documents might be pulled together into an integrated deliverable. The outline will follow the diagram below. Section 1 introduces a definition of Big Data. An extended terminology Glossary is found in Appendix A. In section 2, a Reference Architecture diagram is presented followed by a taxonomy describing and extending the elements of the Reference Architecture. Section 3 maps requirements from use case building blocks to the Reference Architecture. A description of the requirement, a gap analysis, and suggested best practice is included with each mapping. In Section 4 future improvements in Big Data technology are mapped to the Reference Architecture. An initial Technology Roadmap is created on the requirements and gap analysis in Section 3 and the expected future improvements from Section 4. Section 5 is a placeholder for an extended discussion of Security and Privacy. Section 6 gives an example of some general advice. The Appendices provide Big Data terminology and solutions glossaries, Use Case Examples, and some possible Actors and Roles. Big Data Definition - “Big Data refers to the new technologies and applications introduced to handle increasing Volumes of data while enhancing data utilization capabilities such as Variety, Velocity, Variability, Veracity, and Value.” The key attribute is the large Volume of data available that forces horizontal scalability of storage and processing and has implications for all the other V-attributes. -

Apache Sentry
Apache Sentry Prasad Mujumdar [email protected] [email protected] Agenda ● Various aspects of data security ● Apache Sentry for authorization ● Key concepts of Apache Sentry ● Sentry features ● Sentry architecture ● Integration with Hadoop ecosystem ● Sentry administration ● Future plans ● Demo ● Questions Who am I • Software engineer at Cloudera • Committer and PPMC member of Apache Sentry • also for Apache Hive and Apache Flume • Part of the the original team that started Sentry work Aspects of security Perimeter Access Visibility Data Authentication Authorization Audit, Lineage Encryption, what user can do data origin, usage Kerberos, LDAP/AD Masking with data Data access Access ● Provide user access to data Authorization ● Manage access policies what user can do ● Provide role based access with data Agenda ● Various aspects of data security ● Apache Sentry for authorization ● Key concepts of Apache Sentry ● Sentry features ● Sentry architecture ● Integration with Hadoop ecosystem ● Sentry administration ● Future plans ● Demo ● Questions Apache Sentry (Incubating) Unified Authorization module for Hadoop Unlocks Key RBAC Requirements Secure, fine-grained, role-based authorization Multi-tenant administration Enforce a common set of policies across multiple data access path in Hadoop. Key Capabilities of Sentry Fine-Grained Authorization Permissions on object hierarchie. Eg, Database, Table, Columns Role-Based Authorization Support for role templetes to manage authorization for a large set of users and data objects Multi Tanent Administration -

Talend Open Studio for Big Data Release Notes
Talend Open Studio for Big Data Release Notes 6.0.0 Talend Open Studio for Big Data Adapted for v6.0.0. Supersedes previous releases. Publication date July 2, 2015 Copyleft This documentation is provided under the terms of the Creative Commons Public License (CCPL). For more information about what you can and cannot do with this documentation in accordance with the CCPL, please read: http://creativecommons.org/licenses/by-nc-sa/2.0/ Notices Talend is a trademark of Talend, Inc. All brands, product names, company names, trademarks and service marks are the properties of their respective owners. License Agreement The software described in this documentation is licensed under the Apache License, Version 2.0 (the "License"); you may not use this software except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0.html. Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. This product includes software developed at AOP Alliance (Java/J2EE AOP standards), ASM, Amazon, AntlR, Apache ActiveMQ, Apache Ant, Apache Avro, Apache Axiom, Apache Axis, Apache Axis 2, Apache Batik, Apache CXF, Apache Cassandra, Apache Chemistry, Apache Common Http Client, Apache Common Http Core, Apache Commons, Apache Commons Bcel, Apache Commons JxPath, Apache -

Realization of Big Data Ana- Lytics Tool for Optimization Processes Within the Finnish Engineering Company
OPINNÄYTETYÖ - AMMATTIKORKEAKOULUTUTKINTO TEKNIIKAN JA LIIKENTEEN ALA REALIZATION OF BIG DATA ANA- LYTICS TOOL FOR OPTIMIZATION PROCESSES WITHIN THE FINNISH ENGINEERING COMPANY A u t h o r / s : Karapetyan Karina SAVONIA UNIVERSITY OF APPLIED SCIENCES THESIS Abstract Field of Study Technology, Communication and Transport Degree Programme Degree Programme in Information Technology Author(s) Karapetyan Karina Title of Thesis Realization of Big Data Analytics Tool for optimization processes within the Finnish engineering company Date 23.05.2016 Pages/Appendices 54 Supervisor(s) Mr. Arto Toppinen, Principal Lecturer at Savonia University of Applied Sciences, Mr. Anssi Suhonen, Lecturer at Savonia University of Applied Sciences Client Organisation /Partners Hydroline Oy Abstract Big Data Analytics Tool offers an entire business picture for making both operational and strategic deci- sions from selecting the product price to establishing the priorities for the further vendor’s enhancement. The purpose of the thesis was to explore the industrial system of Hydroline Oy and provide a software solution for the elaboration of the manufacture, due to the internal analyzing within the company. For the development of Big Data Analytics Tool, several software programs and tools were employed. Java-written server controls all components in the project and visualizes the processed data via a user- friendly client web application. The SQL Server maintains data, observed from the ERP system. Moreo- ver, it is responsible for the login and registration procedure to enforce the information security. In the Hadoop environment, two research methods were implemented. The Overall Equipment Effectiveness model investigated the production data to obtain daily, monthly and annual efficiency indices of equip- ment utilization, employees’ workload, resource management, quality degree, among others. -

HDP 3.1.4 Release Notes Date of Publish: 2019-08-26
Release Notes 3 HDP 3.1.4 Release Notes Date of Publish: 2019-08-26 https://docs.hortonworks.com Release Notes | Contents | ii Contents HDP 3.1.4 Release Notes..........................................................................................4 Component Versions.................................................................................................4 Descriptions of New Features..................................................................................5 Deprecation Notices.................................................................................................. 6 Terminology.......................................................................................................................................................... 6 Removed Components and Product Capabilities.................................................................................................6 Testing Unsupported Features................................................................................ 6 Descriptions of the Latest Technical Preview Features.......................................................................................7 Upgrading to HDP 3.1.4...........................................................................................7 Behavioral Changes.................................................................................................. 7 Apache Patch Information.....................................................................................11 Accumulo........................................................................................................................................................... -

Desarrollo De Una Solución Business Intelligence Mediante Un Paradigma De Data Lake
Desarrollo de una solución Business Intelligence mediante un paradigma de Data Lake José María Tagarro Martí Grado de Ingeniería Informática Consultor: Humberto Andrés Sanz Profesor: Atanasi Daradoumis Haralabus 13 de enero de 2019 Esta obra está sujeta a una licencia de Reconocimiento-NoComercial-SinObraDerivada 3.0 España de Creative Commons FICHA DEL TRABAJO FINAL Desarrollo de una solución Business Intelligence mediante un paradigma de Data Título del trabajo: Lake Nombre del autor: José María Tagarro Martí Nombre del consultor: Humberto Andrés Sanz Fecha de entrega (mm/aaaa): 01/2019 Área del Trabajo Final: Business Intelligence Titulación: Grado de Ingeniería Informática Resumen del Trabajo (máximo 250 palabras): Este trabajo implementa una solución de Business Intelligence siguiendo un paradigma de Data Lake sobre la plataforma de Big Data Apache Hadoop con el objetivo de ilustrar sus capacidades tecnológicas para este fin. Los almacenes de datos tradicionales necesitan transformar los datos entrantes antes de ser guardados para que adopten un modelo preestablecido, en un proceso conocido como ETL (Extraer, Transformar, Cargar, por sus siglas en inglés). Sin embargo, el paradigma Data Lake propone el almacenamiento de los datos generados en la organización en su propio formato de origen, de manera que con posterioridad puedan ser transformados y consumidos mediante diferentes tecnologías ad hoc para las distintas necesidades de negocio. Como conclusión, se indican las ventajas e inconvenientes de desplegar una plataforma unificada tanto para análisis Big Data como para las tareas de Business Intelligence, así como la necesidad de emplear soluciones basadas en código y estándares abiertos. Abstract (in English, 250 words or less): This paper implements a Business Intelligence solution following the Data Lake paradigm on Hadoop’s Big Data platform with the aim of showcasing the technology for this purpose. -

SAS 9.4 Hadoop Configuration Guide for Base SAS And
SAS® 9.4 Hadoop Configuration Guide for Base SAS® and SAS/ACCESS® Second Edition SAS® Documentation The correct bibliographic citation for this manual is as follows: SAS Institute Inc. 2015. SAS® 9.4 Hadoop Configuration Guide for Base SAS® and SAS/ACCESS®, Second Edition. Cary, NC: SAS Institute Inc. SAS® 9.4 Hadoop Configuration Guide for Base SAS® and SAS/ACCESS®, Second Edition Copyright © 2015, SAS Institute Inc., Cary, NC, USA All rights reserved. Produced in the United States of America. For a hard-copy book: No part of this publication may be reproduced, stored in a retrieval system, or transmitted, in any form or by any means, electronic, mechanical, photocopying, or otherwise, without the prior written permission of the publisher, SAS Institute Inc. For a web download or e-book: Your use of this publication shall be governed by the terms established by the vendor at the time you acquire this publication. The scanning, uploading, and distribution of this book via the Internet or any other means without the permission of the publisher is illegal and punishable by law. Please purchase only authorized electronic editions and do not participate in or encourage electronic piracy of copyrighted materials. Your support of others' rights is appreciated. U.S. Government License Rights; Restricted Rights: The Software and its documentation is commercial computer software developed at private expense and is provided with RESTRICTED RIGHTS to the United States Government. Use, duplication or disclosure of the Software by the United States Government is subject to the license terms of this Agreement pursuant to, as applicable, FAR 12.212, DFAR 227.7202-1(a), DFAR 227.7202-3(a) and DFAR 227.7202-4 and, to the extent required under U.S. -

Talend Open Studio for Big Data Release Notes
Talend Open Studio for Big Data Release Notes 6.5.1 Contents Copyleft.......................................................................................................................3 System requirements...................................................................................................4 Talend Open Studio for Big Data: new features........................................................4 Talend Open Studio for Big Data: bug fixes............................................................. 7 Talend Open Studio for Big Data: deprecated items................................................. 7 Talend Open Studio for Big Data: known issues and limitations...............................7 Talend Open Studio for Big Data: hints and notes.................................................... 8 Documentation............................................................................................................ 9 Reporting defects and issues.................................................................................... 10 Talend Open Studio for Big Data 6.5.1 © Talend 2018 Copyleft Adapted for 6.5.1. Supersedes previous releases. Publication date: January 18, 2018 This documentation is provided under the terms of the Creative Commons Public License (CCPL). For more information about what you can and cannot do with this documentation in accordance with the CCPL, please read: http://creativecommons.org/licenses/by-nc-sa/2.0/. Notices Talend is a trademark of Talend, Inc. All brands, product names, company names, trademarks -
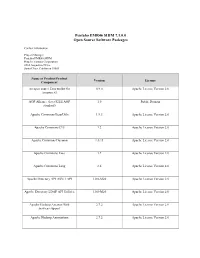
Pentaho EMR46 SHIM 7.1.0.0 Open Source Software Packages
Pentaho EMR46 SHIM 7.1.0.0 Open Source Software Packages Contact Information: Project Manager Pentaho EMR46 SHIM Hitachi Vantara Corporation 2535 Augustine Drive Santa Clara, California 95054 Name of Product/Product Version License Component An open source Java toolkit for 0.9.0 Apache License Version 2.0 Amazon S3 AOP Alliance (Java/J2EE AOP 1.0 Public Domain standard) Apache Commons BeanUtils 1.9.3 Apache License Version 2.0 Apache Commons CLI 1.2 Apache License Version 2.0 Apache Commons Daemon 1.0.13 Apache License Version 2.0 Apache Commons Exec 1.2 Apache License Version 2.0 Apache Commons Lang 2.6 Apache License Version 2.0 Apache Directory API ASN.1 API 1.0.0-M20 Apache License Version 2.0 Apache Directory LDAP API Utilities 1.0.0-M20 Apache License Version 2.0 Apache Hadoop Amazon Web 2.7.2 Apache License Version 2.0 Services support Apache Hadoop Annotations 2.7.2 Apache License Version 2.0 Name of Product/Product Version License Component Apache Hadoop Auth 2.7.2 Apache License Version 2.0 Apache Hadoop Common - 2.7.2 Apache License Version 2.0 org.apache.hadoop:hadoop-common Apache Hadoop HDFS 2.7.2 Apache License Version 2.0 Apache HBase - Client 1.2.0 Apache License Version 2.0 Apache HBase - Common 1.2.0 Apache License Version 2.0 Apache HBase - Hadoop 1.2.0 Apache License Version 2.0 Compatibility Apache HBase - Protocol 1.2.0 Apache License Version 2.0 Apache HBase - Server 1.2.0 Apache License Version 2.0 Apache HBase - Thrift - 1.2.0 Apache License Version 2.0 org.apache.hbase:hbase-thrift Apache HttpComponents Core -

Technology Overview
Big Data Technology Overview Term Description See Also Big Data - the 5 Vs Everyone Must Volume, velocity and variety. And some expand the definition further to include veracity 3 Vs Know and value as well. 5 Vs of Big Data From Wikipedia, “Agile software development is a group of software development methods based on iterative and incremental development, where requirements and solutions evolve through collaboration between self-organizing, cross-functional teams. Agile The Agile Manifesto It promotes adaptive planning, evolutionary development and delivery, a time-boxed iterative approach, and encourages rapid and flexible response to change. It is a conceptual framework that promotes foreseen tight iterations throughout the development cycle.” A data serialization system. From Wikepedia, Avro Apache Avro “It is a remote procedure call and serialization framework developed within Apache's Hadoop project. It uses JSON for defining data types and protocols, and serializes data in a compact binary format.” BigInsights Enterprise Edition provides a spreadsheet-like data analysis tool to help Big Insights IBM Infosphere Biginsights organizations store, manage, and analyze big data. A scalable multi-master database with no single points of failure. Cassandra Apache Cassandra It provides scalability and high availability without compromising performance. Cloudera Inc. is an American-based software company that provides Apache Hadoop- Cloudera Cloudera based software, support and services, and training to business customers. Wikipedia - Data Science Data science The study of the generalizable extraction of knowledge from data IBM - Data Scientist Coursera Big Data Technology Overview Term Description See Also Distributed system developed at Google for interactively querying large datasets. Dremel Dremel It empowers business analysts and makes it easy for business users to access the data Google Research rather than having to rely on data engineers. -

Optimisation of Ad-Hoc Analysis of an OLAP Cube Using Sparksql
UPTEC X 17 007 Examensarbete 30 hp September 2017 Optimisation of Ad-hoc analysis of an OLAP cube using SparkSQL Milja Aho Abstract Optimisation of Ad-hoc analysis of an OLAP cube using SparkSQL Milja Aho Teknisk- naturvetenskaplig fakultet UTH-enheten An Online Analytical Processing (OLAP) cube is a way to represent a multidimensional database. The multidimensional database often uses a star Besöksadress: schema and populates it with the data from a relational database. The purpose of Ångströmlaboratoriet Lägerhyddsvägen 1 using an OLAP cube is usually to find valuable insights in the data like trends or Hus 4, Plan 0 unexpected data and is therefore often used within Business intelligence (BI). Mondrian is a tool that handles OLAP cubes that uses the query language Postadress: MultiDimensional eXpressions (MDX) and translates it to SQL queries. Box 536 751 21 Uppsala Apache Kylin is an engine that can be used with Apache Hadoop to create and query OLAP cubes with an SQL interface. This thesis investigates whether the Telefon: engine Apache Spark running on a Hadoop cluster is suitable for analysing OLAP 018 – 471 30 03 cubes and what performance that can be expected. The Star Schema Benchmark Telefax: (SSB) has been used to provide Ad-Hoc queries and to create a large database 018 – 471 30 00 containing over 1.2 billion rows. This database was created in a cluster in the Omicron office consisting of five worker nodes and one master node. Queries were Hemsida: then sent to the database using Mondrian integrated into the BI platform Pentaho. http://www.teknat.uu.se/student Amazon Web Services (AWS) has also been used to create clusters with 3, 6 and 15 slaves to see how the performance scales. -

Code Smell Prediction Employing Machine Learning Meets Emerging Java Language Constructs"
Appendix to the paper "Code smell prediction employing machine learning meets emerging Java language constructs" Hanna Grodzicka, Michał Kawa, Zofia Łakomiak, Arkadiusz Ziobrowski, Lech Madeyski (B) The Appendix includes two tables containing the dataset used in the paper "Code smell prediction employing machine learning meets emerging Java lan- guage constructs". The first table contains information about 792 projects selected for R package reproducer [Madeyski and Kitchenham(2019)]. Projects were the base dataset for cre- ating the dataset used in the study (Table I). The second table contains information about 281 projects filtered by Java version from build tool Maven (Table II) which were directly used in the paper. TABLE I: Base projects used to create the new dataset # Orgasation Project name GitHub link Commit hash Build tool Java version 1 adobe aem-core-wcm- www.github.com/adobe/ 1d1f1d70844c9e07cd694f028e87f85d926aba94 other or lack of unknown components aem-core-wcm-components 2 adobe S3Mock www.github.com/adobe/ 5aa299c2b6d0f0fd00f8d03fda560502270afb82 MAVEN 8 S3Mock 3 alexa alexa-skills- www.github.com/alexa/ bf1e9ccc50d1f3f8408f887f70197ee288fd4bd9 MAVEN 8 kit-sdk-for- alexa-skills-kit-sdk- java for-java 4 alibaba ARouter www.github.com/alibaba/ 93b328569bbdbf75e4aa87f0ecf48c69600591b2 GRADLE unknown ARouter 5 alibaba atlas www.github.com/alibaba/ e8c7b3f1ff14b2a1df64321c6992b796cae7d732 GRADLE unknown atlas 6 alibaba canal www.github.com/alibaba/ 08167c95c767fd3c9879584c0230820a8476a7a7 MAVEN 7 canal 7 alibaba cobar www.github.com/alibaba/