Study Designs in Biomedical Research
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
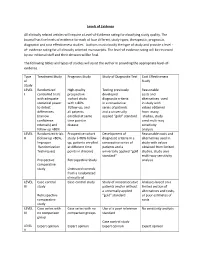
Levels of Evidence Table
Levels of Evidence All clinically related articles will require a Level-of-Evidence rating for classifying study quality. The Journal has five levels of evidence for each of four different study types; therapeutic, prognostic, diagnostic and cost effectiveness studies. Authors must classify the type of study and provide a level - of- evidence rating for all clinically oriented manuscripts. The level-of evidence rating will be reviewed by our editorial staff and their decision will be final. The following tables and types of studies will assist the author in providing the appropriate level-of- evidence. Type Treatment Study Prognosis Study Study of Diagnostic Test Cost Effectiveness of Study Study LEVEL Randomized High-quality Testing previously Reasonable I controlled trials prospective developed costs and with adequate cohort study diagnostic criteria alternatives used statistical power with > 80% in a consecutive in study with to detect follow-up, and series of patients values obtained differences all patients and a universally from many (narrow enrolled at same applied “gold” standard studies, study confidence time point in used multi-way intervals) and disease sensitivity follow up >80% analysis LEVEL Randomized trials Prospective cohort Development of Reasonable costs and II (follow up <80%, study (<80% follow- diagnostic criteria in a alternatives used in Improper up, patients enrolled consecutive series of study with values Randomization at different time patients and a obtained from limited Techniques) points in disease) universally -

The Very Process of Taking a Pill May Create Expectations in a Patient Which May Affect Reactions to the Pill
Ch 1 Pause for Thought Questions p. 36 1- Why is it important to use placebos and a double-blind approach in some studies? The very process of taking a pill may create expectations in a patient which may affect reactions to the pill. To help eliminate the role of patient expectation during testing, a placebo (or fake medicine) is used on subjects in a control group. A researcher’s expectations may also affect results. Therefore, double-blind studies are often used. In such studies, neither the researcher nor the participants know which group is which. 2- Assume that researchers find that people’s memories are sharpest right after they’ve eaten lunch. What hidden variables may have affected these results? Other variables that may play a role (hidden variables): Time of Day Type of food eaten Meaning of “lunch” - May mean “time away from work” - Subjective State of feeling free (not food) helps memory. Socializing at lunch may make a person more alert and then able to take-in more info and retain it longer. 3- How might you use the scientific method to study factors that affect obedience? Devise a simple study, and identify the following: hypothesis, subjects, independent variable, dependent variable, experimental group, and control group. Hypothesis: If employee fears/believes they will be punished if they don’t follow directives, then they will be obedient to directives of bosses/people in “higher” positions than themselves in the workplace. Subjects: Employees Independent Variable: Directive given with harsh consequences for not following through. Dependent Variable: Obedience (Level of) Experimental Group: Group with “harsh” bosses (very by the book; give extreme consequences) present during their work day. -

Quasi-Experimental Studies in the Fields of Infection Control and Antibiotic Resistance, Ten Years Later: a Systematic Review
HHS Public Access Author manuscript Author ManuscriptAuthor Manuscript Author Infect Control Manuscript Author Hosp Epidemiol Manuscript Author . Author manuscript; available in PMC 2019 November 12. Published in final edited form as: Infect Control Hosp Epidemiol. 2018 February ; 39(2): 170–176. doi:10.1017/ice.2017.296. Quasi-experimental Studies in the Fields of Infection Control and Antibiotic Resistance, Ten Years Later: A Systematic Review Rotana Alsaggaf, MS, Lyndsay M. O’Hara, PhD, MPH, Kristen A. Stafford, PhD, MPH, Surbhi Leekha, MBBS, MPH, Anthony D. Harris, MD, MPH, CDC Prevention Epicenters Program Department of Epidemiology and Public Health, University of Maryland School of Medicine, Baltimore, Maryland. Abstract OBJECTIVE.—A systematic review of quasi-experimental studies in the field of infectious diseases was published in 2005. The aim of this study was to assess improvements in the design and reporting of quasi-experiments 10 years after the initial review. We also aimed to report the statistical methods used to analyze quasi-experimental data. DESIGN.—Systematic review of articles published from January 1, 2013, to December 31, 2014, in 4 major infectious disease journals. METHODS.—Quasi-experimental studies focused on infection control and antibiotic resistance were identified and classified based on 4 criteria: (1) type of quasi-experimental design used, (2) justification of the use of the design, (3) use of correct nomenclature to describe the design, and (4) statistical methods used. RESULTS.—Of 2,600 articles, 173 (7%) featured a quasi-experimental design, compared to 73 of 2,320 articles (3%) in the previous review (P<.01). Moreover, 21 articles (12%) utilized a study design with a control group; 6 (3.5%) justified the use of a quasi-experimental design; and 68 (39%) identified their design using the correct nomenclature. -

Title: a TRANSMISSION-VIRULENCE EVOLUTIONARY TRADE-OFF
1 Title: A TRANSMISSION-VIRULENCE EVOLUTIONARY TRADE-OFF EXPLAINS 2 ATTENUATION OF HIV-1 IN UGANDA 3 Short title: EVOLUTION OF VIRULENCE IN HIV 4 François Blanquart1, Mary Kate Grabowski2, Joshua Herbeck3, Fred Nalugoda4, David 5 Serwadda4,5, Michael A. Eller6, 7, Merlin L. Robb6,7, Ronald Gray2,4, Godfrey Kigozi4, Oliver 6 Laeyendecker8, Katrina A. Lythgoe1,9, Gertrude Nakigozi4, Thomas C. Quinn8, Steven J. 7 Reynolds8, Maria J. Wawer2, Christophe Fraser1 8 1. MRC Centre for Outbreak Analysis and Modelling, Department of Infectious Disease 9 Epidemiology, School of Public Health, Imperial College London, United Kingdom 10 2. Department of Epidemiology, Bloomberg School of Public Health, Johns Hopkins University, 11 Baltimore, MD, USA 12 3. International Clinical Research Center, Department of Global Health, University of 13 Washington, Seattle, WA, USA 14 4. Rakai Health Sciences Program, Entebbe, Uganda 15 5. School of Public Health, Makerere University, Kampala, Uganda 16 6. U.S. Military HIV Research Program, Walter Reed Army Institute of Research, Silver Spring, 17 MD, USA 18 7. Henry M. Jackson Foundation for the Advancement of Military Medicine, Bethesda, MD, USA 19 8. Laboratory of Immunoregulation, Division of Intramural Research, National Institute of 20 Allergy and Infectious Diseases, National Institutes of Health, Bethesda, MD, USA 21 9. Department of Zoology, University of Oxford, United Kingdom 22 23 Abstract 24 Evolutionary theory hypothesizes that intermediate virulence maximizes pathogen fitness as 25 a result of a trade-off between virulence and transmission, but empirical evidence remains scarce. 26 We bridge this gap using data from a large and long-standing HIV-1 prospective cohort, in 27 Uganda. -

Catalogue of Clinical Trials and Cohort Studies to Identify Biological
Catalogue of clinical trials and cohort studies to identify biological specimens of relevance to the development of assays for acute and early HIV infection: Final Report Catalogue of clinical trials and cohort studies to identify biological specimens of relevance to the development of assays for recent HIV infection Final Report February 2010 This final report was prepared by Dr Joanne Micallef and Professor John Kaldor, The University of New South Wales, under subcontract with Family Health International, funded by the Bill and Melinda Gates Foundation under the grant titled “Development of Assays for Acute HIV Infection and Estimation and HIV Incidence in Population”. 1 Catalogue of clinical trials and cohort studies to identify biological specimens of relevance to the development of assays for acute and early HIV infection: Final Report Table of Contents Table of Contents .................................................................................................................................................................... 2 List of acronyms ...................................................................................................................................................................... 4 1 Introduction ..................................................................................................................................................................... 6 2 Methods ............................................................................................................................................................................ -

Observational Clinical Research
E REVIEW ARTICLE Clinical Research Methodology 2: Observational Clinical Research Daniel I. Sessler, MD, and Peter B. Imrey, PhD * † Case-control and cohort studies are invaluable research tools and provide the strongest fea- sible research designs for addressing some questions. Case-control studies usually involve retrospective data collection. Cohort studies can involve retrospective, ambidirectional, or prospective data collection. Observational studies are subject to errors attributable to selec- tion bias, confounding, measurement bias, and reverse causation—in addition to errors of chance. Confounding can be statistically controlled to the extent that potential factors are known and accurately measured, but, in practice, bias and unknown confounders usually remain additional potential sources of error, often of unknown magnitude and clinical impact. Causality—the most clinically useful relation between exposure and outcome—can rarely be defnitively determined from observational studies because intentional, controlled manipu- lations of exposures are not involved. In this article, we review several types of observa- tional clinical research: case series, comparative case-control and cohort studies, and hybrid designs in which case-control analyses are performed on selected members of cohorts. We also discuss the analytic issues that arise when groups to be compared in an observational study, such as patients receiving different therapies, are not comparable in other respects. (Anesth Analg 2015;121:1043–51) bservational clinical studies are attractive because Group, and the American Society of Anesthesiologists they are relatively inexpensive and, perhaps more Anesthesia Quality Institute. importantly, can be performed quickly if the required Recent retrospective perioperative studies include data O 1,2 data are already available. -

Download and Use
Shenkin et al. BMC Medicine (2019) 17:138 https://doi.org/10.1186/s12916-019-1367-9 RESEARCHARTICLE Open Access Delirium detection in older acute medical inpatients: a multicentre prospective comparative diagnostic test accuracy study of the 4AT and the confusion assessment method Susan D. Shenkin1, Christopher Fox2, Mary Godfrey3, Najma Siddiqi4, Steve Goodacre5, John Young6, Atul Anand7, Alasdair Gray8, Janet Hanley9, Allan MacRaild8, Jill Steven8, Polly L. Black8, Zoë Tieges1, Julia Boyd10, Jacqueline Stephen10, Christopher J. Weir10 and Alasdair M. J. MacLullich1* Abstract Background: Delirium affects > 15% of hospitalised patients but is grossly underdetected, contributing to poor care. The 4 ‘A’s Test (4AT, www.the4AT.com) is a short delirium assessment tool designed for routine use without special training. Theprimaryobjectivewastoassesstheaccuracyofthe4ATfor delirium detection. The secondary objective was to compare the 4AT with another commonly used delirium assessment tool, the Confusion Assessment Method (CAM). Methods: This was a prospective diagnostic test accuracy study set in emergency departments or acute medical wards involving acute medical patients aged ≥ 70. All those without acutely life-threatening illness or coma were eligible. Patients underwent (1) reference standard delirium assessment based on DSM-IV criteria and (2) were randomised to either the index test (4AT, scores 0–12; prespecified score of > 3 considered positive) or the comparator (CAM; scored positive or negative), in a random order, using computer-generated pseudo-random numbers, stratified by study site, with block allocation. Reference standard and 4AT or CAM assessments were performed by pairs of independent raters blinded to the results of the other assessment. Results: Eight hundred forty-three individuals were randomised: 21 withdrew, 3 lost contact, 32 indeterminate diagnosis, 2 missing outcome, and 785 were included in the analysis. -

Design of Prospective Studies
Design of Prospective Studies Kyoungmi Kim, Ph.D. June 14, 2017 This seminar is jointly supported by the following NIH-funded centers: Seminar Objectives . Discuss about design of prospective longitudinal studies . Understand options for overcoming shortcomings of prospective studies . Learn to determine how many subjects to recruit for a follow-up study What is a prospective study? Study subjects of disease‐free at enrollment are followed for a period of time and periodically checked for progress to see who/when gets the outcome in question ‐thus be able to establish a temporal relationship between exposure & outcome. What is a prospective study? During the follow‐up, data is collected on the factors of interest, including: •When the subject develops the condition •When they drop out of the study or become “lost” •When they exposure status changes •When they die Example: Framingham Study . An original cohort of 5,209 subjects from Framingham, MA between the ages of 30 and 62 years of age was recruited and followed up for 20 years. A number of hypotheses were generated and described by Dawber et al. in 1980 listing various presupposed risk factors such as increasing age, increased weight, tobacco smoking, elevated blood pressure and cholesterol and decreased physical activity. It is largely quoted as a successful longitudinal study owing to the fact that a large proportion of the exposures chosen for analysis were indeed found to correlate closely with the development of cardiovascular disease. Example: Framingham Study . Biases exist: – It was a study carried out in a single population in a single town, brining into question the generalizability and applicability of this data to different groups. -

Top Ten Cool Things About 250B Exam 1
Cohort Studies Madhukar Pai, MD, PhD McGill University Montreal 1 Cohort: origins of the word http://www.caerleon.net/ 2 Introduction • Measurement of the occurrence of events over time is a central goal of epidemiologic research • Regardless of any particular study design or hypothesis, interest is ultimately in the disease or outcome-causing properties of factors that are antecedent to the disease or outcome. • All study designs (including case control and cross- sectional studies) are played out in some populations over time (either well defined cohorts or not) – They differ in how they acknowledge time and how they sample exposed and non-exposed as these groups develop disease over time 3 All the action happens within a “sea of person-time” in which events occur 4 Morgenstern IJE 1980 Cohort studies Intuitive approach to studying disease incidence and risk factors: 1. Start with a population at risk 2. Measure exposures and covariates at baseline 3. Follow-up the cohort over time with a) Surveillance for events or b) re-examination 4. Keep track of attrition, withdrawals, drop-outs and competing risks 5. For covariates that change over time, measure them again during follow up 6. Compare event rates in people with and without exposures of interest - Incidence Density Ratio (IDR) is the most natural and appropriate measure of effect - Adjust for confounders and compute adjusted IDR - Look for effect measure modification, if appropriate 5 Cohort studies • Can be large or small • Can be long or short duration • Can be simple or elaborate • Can look at multiple exposures and multiple outcomes • Can look at changes in exposures over time • For rare outcomes need many people and/or lengthy follow- up • Are usually very expensive because of the numbers and follow-up requirements • But once a cohort is established, can sustain research productivity for a long, long time! 6 Cohort: keeping track of people 7 Szklo & Nieto. -

Study Designs in Biomedical Research
STUDY DESIGNS IN BIOMEDICAL RESEARCH INTRODUCTION TO CLINICAL TRIALS SOME TERMINOLOGIES Research Designs: Methods for data collection Clinical Studies: Class of all scientific approaches to evaluate Disease Prevention, Diagnostics, and Treatments. Clinical Trials: Subset of clinical studies that evaluates Investigational Drugs; they are in prospective/longitudinal form (the basic nature of trials is prospective). TYPICAL CLINICAL TRIAL Study Initiation Study Termination No subjects enrolled after π1 0 π1 π2 Enrollment Period, e.g. Follow-up Period, e.g. three (3) years two (2) years OPERATION: Patients come sequentially; each is enrolled & randomized to receive one of two or several treatments, and followed for varying amount of time- between π1 & π2 In clinical trials, investigators apply an “intervention” and observe the effect on outcomes. The major advantage is the ability to demonstrate causality; in particular: (1) random assigning subjects to intervention helps to reduce or eliminate the influence of confounders, and (2) blinding its administration helps to reduce or eliminate the effect of biases from ascertainment of the outcome. Clinical Trials form a subset of cohort studies but not all cohort studies are clinical trials because not every research question is amenable to the clinical trial design. For example: (1) By ethical reasons, we cannot assign subjects to smoking in a trial in order to learn about its harmful effects, or (2) It is not feasible to study whether drug treatment of high LDL-cholesterol in children will prevent heart attacks many decades later. In addition, clinical trials are generally expensive, time consuming, address narrow clinical questions, and sometimes expose participants to potential harm. -

Why Do We Need Longitudinal Survey Data?
HEATHER JOSHI University College London, UK Why do we need longitudinal survey data? Knowing people’s history helps in understanding their present state and where they are heading Keywords: life chances, inequality, mobility, gender, cohort, panel studies ELEVATOR PITCH Work experiences of men and women explain little of the Information from longitudinal surveys transforms gap in their hourly pay in the UK Cohorts snapshots of a given moment into something with a Born 1946 time dimension. It illuminates patterns of events within Age 26 31 an individual’s life and records mobility and immobility 43 Born 1958 between older and younger generations. It can track Age 23 33 the different pathways of men and women and people 42 of diverse socio-economic background through the life Born 1970 Gap explained by differences Age 26 in work experience & education course. It can join up data on aspects of a person’s life, 30 Unexplained gap 34 health, education, family, and employment and show how 0510 15 20 25 30 35 40 45 these domains affect one another. It is ideal for bridging Men’s pay minus women’s pay as % of men’s pay the different silos of policies that affect people’s lives. Source: [1]; Table 7.12. KEY FINDINGS Pros Cons Longitudinal surveys form a record of Longitudinal survey data are expensive to collect continuities and transitions of a life as they and challenging to analyze. happen, information not reliably gained through Data must be collected over a long timeframe to recollection or cross-section surveys. show relevant, long-term results. -

Epidemiologic Study Designs
Epidemiologic Study Designs Jacky M Jennings, PhD, MPH Associate Professor Associate Director, General Pediatrics and Adolescent Medicine Director, Center for Child & Community Health Research (CCHR) Departments of Pediatrics & Epidemiology Johns Hopkins University Learning Objectives • Identify basic epidemiologic study designs and their frequent sequence of study • Recognize the basic components • Understand the advantages and disadvantages • Appropriately select a study design Research Question & Hypotheses Analytic Study Plan Design Basic Study Designs and their Hierarchy Clinical Observation Hypothesis Descriptive Study Case-Control Study Cohort Study Randomized Controlled Trial Systematic Review Causality Adapted from Gordis, 1996 MMWR Study Design in Epidemiology • Depends on: – The research question and hypotheses – Resources and time available for the study – Type of outcome of interest – Type of exposure of interest – Ethics Study Design in Epidemiology • Includes: – The research question and hypotheses – Measures and data quality – Time – Study population • Inclusion/exclusion criteria • Internal/external validity Epidemiologic Study Designs • Descriptive studies – Seeks to measure the frequency of disease and/or collect descriptive data on risk factors • Analytic studies – Tests a causal hypothesis about the etiology of disease • Experimental studies – Compares, for example, treatments EXPOSURE Cross-sectional OUTCOME EXPOSURE OUTCOME Case-Control EXPOSURE OUTCOME Cohort TIME Cross-sectional studies • Measure existing disease and current exposure levels at one point in time • Sample without knowledge of exposure or disease • Ex. Prevalence studies Cross-sectional studies • Advantages – Often early study design in a line of investigation – Good for hypothesis generation – Relatively easy, quick and inexpensive…depends on question – Examine multiple exposures or outcomes – Estimate prevalence of disease and exposures Cross-sectional studies • Disadvantages – Cannot infer causality – Prevalent vs.