Bailiwicked Domain Attack
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Browser Security
Transcript of Episode #38 Browser Security Description: Steve and Leo discuss the broad topic of web browser security. They examine the implications of running "client-side" code in the form of interpreted scripting languages such as Java, JavaScript, and VBScript, and also the native object code contained within browser "plug- ins" including Microsoft’s ActiveX. Steve outlines the "zone-based" security model used by IE and explains how he surfs with high security under IE, only "lowering his shields" to a website after he’s had the chance to look around and decide that the site is trustworthy. High quality (64 kbps) mp3 audio file URL: http://media.GRC.com/sn/SN-038.mp3 Quarter size (16 kbps) mp3 audio file URL: http://media.GRC.com/sn/sn-038-lq.mp3 Leo Laporte: Bandwidth for Security Now! is provided by AOL Radio at AOL.com/podcasting. This is Security Now! with Steve Gibson, Episode 38 for May 4, 2006: Browser Security. Security Now! is brought to you by Astaro, makers of the Astaro Security Gateway, on the web at www.astaro.com. So finally the sun is shining in beautiful California. We have summer, or at least spring finally arrived. And, look, Steve Gibson’s wearing a tank top and shorts. No, he’s not. Steve Gibson: Well, it’s dry in Toronto, Leo. You were all chapped; I was all, like, chapped just after one day. Leo: I am. And, you know, they complain in Toronto that it’s too humid because they have the lake effect. But I guess it gets humid some other time because I – chapped is the word, exactly. -

D-Link Announce Alliance to Offer Expanded Entertainment Options for the Digital Home
PRESS RELEASE AMERICA ONLINE AND D-LINK ANNOUNCE ALLIANCE TO OFFER EXPANDED ENTERTAINMENT OPTIONS FOR THE DIGITAL HOME Taipei, January 8, 2004 D-Link, the global leader in the design and development of connectivity and communications technologies for the digital home and the small to medium business markets, and America Online, Inc., the world's leading interactive services company, today announced a new alliance to jointly offer expanded entertainment options for the Digital Home. The companies are collaborating to develop and deliver products and services that will allow broadband consumers to access secure, high-quality video, music and photo content, on-demand, from virtually any room in the home. In the first step of this new relationship, D-Link and AOL are extending access to the #1 Internet broadcasting service, Radio@AOL, beyond the computer and into any room with a TV or stereo. A new line of D-Link Wireless Media Players, including the Wireless Network Player with DVD and the D-Link Wireless Network Player with 5-in-1 Flash Card Reader stream multimedia content such as audio, photos and video across a home network to a home entertainment center for an unparalleled entertainment experience. The D-Link Wireless Media Players will immediately enhance and extend an AOL for Broadband member's experience by allowing them to listen to over 175 CD-quality Radio@AOL stations on any TV or stereo in the home. D-Link and AOL are also working together to extend AOL's popular You've Got Pictures in the same way, allowing AOL for Broadband members to view their personal photos and slideshows, and exclusive photos from AOL's various photo galleries by using the AOL You've Got Pictures service on any TV in the home. -

Finding a Partner Model with Broadcasters at Tunein.Com.” Stanford Casepublisher 204-2011-1
S TANFORD U NIVERSITY 2 0 1 1 - 2 0 4 - 1 S CHOOL OF E NGINEERING C ASEP UBLISHER DRAFT Rev. May 17, 2011 DRAFT COPY DO NOT CITE: R. Chen et al. “Finding a Partner Model with Broadcasters at Tunein.com.” Stanford CasePublisher 204-2011-1. 17 May 2010. DRAFT COPY DO NOT CITE FINDING A PARTNER MODEL WITH BROADCASTERS AT TUNEIN.COM T ABLE OF C ONTENTS Introduction 1. Overview of Online Broadcast Industry 1.1. Industry Trends 1.2. Industry Participants 2. TuneIn Background 2.1. RadioTime 2.2. Tunein Radio 3. Business Model 3.1. Metrics 3.2. Market Reaction 4. Conclusions 5. Discussion 6. Questions 7. Exhibits 8. References 9. Authors Professors Micah Siegel (Stanford University) and Fred Gibbons (Stanford University) guided the de- velopment of this case using the CasePublisher service as the basis for class discussion rather than to il- lustrate either effective or ineffective handling of a business situation. S TANFORD 204-2011-01 Finding a Partner Model at TuneIn.com Introduction !Founded in 2002, TuneIn delivers free Internet radio from all over the world. The application streams radio stations from 50,000 local, international, and Internet stations spanning 140 countries and 55 di"erent languages in over 150 products.1) It provides users with access to live radio content through a variety of media including websites, smart- phones, home entertainment devices, and auto in-dash receivers. 2) The application also al- lows users to pause, rewind, and record live radio programs. Although there are numerous online applications that o"er music streaming, TuneIn di"erentiates itself by focusing on radio programming. -

An Introduction to Internet Radio
NB: This version was updated with new Internet Radio products on 26 October 2005 (see page 8). INTERNET RADIO AnInternet introduction to Radio Franc Kozamernik and Michael Mullane EBU This article – based on an EBU contribution to the WBU-TC Digital Radio Systems Handbook – introduces the concept of Internet Radio (IR) and provides some technical background. It gives examples of IR services now available in different countries and provides some guidance for traditional radio broadcasters on how to adapt to the rapidly changing multimedia environment. Traditionally, audio programmes have been available via dedicated terrestrial networks broad- casting to radio receivers. Typically, they have operated on AM and FM terrestrial platforms but, with the move to digital broadcasting, audio programmes are also available today via DAB, DRM and IBOC (e.g. HD Radio in the USA). However, this paradigm is about to change. Radio programmes are increasingly available not only from terrestrial networks but also from a large variety of satellite, cable and, indeed, telecommunications networks (e.g. fixed telephone lines, wire- less broadband connections and mobile phones). Very often, radio is added to digital television plat- forms (e.g. DVB-S and DVB-T). Radio receivers are no longer only dedicated hi-fi tuners or portable radios with whip aerials, but are now assuming the shape of various multimedia-enabled computer devices (e.g. desktops, notebooks, PDAs, “Internet” radios, etc.). These sea changes in radio technologies impact dramatically on the radio medium itself – the way it is produced, delivered, consumed and paid-for. Radio has become more than just audio – it can now contain associated metadata, synchronized slideshows and even short video clips. -
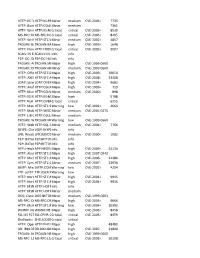
HTTP: IIS "Propfind" Rem HTTP:IIS:PROPFIND Minor Medium
HTTP: IIS "propfind"HTTP:IIS:PROPFIND RemoteMinor DoS medium CVE-2003-0226 7735 HTTP: IkonboardHTTP:CGI:IKONBOARD-BADCOOKIE IllegalMinor Cookie Languagemedium 7361 HTTP: WindowsHTTP:IIS:NSIISLOG-OF Media CriticalServices NSIISlog.DLLcritical BufferCVE-2003-0349 Overflow 8035 MS-RPC: DCOMMS-RPC:DCOM:EXPLOIT ExploitCritical critical CVE-2003-0352 8205 HTTP: WinHelp32.exeHTTP:STC:WINHELP32-OF2 RemoteMinor Buffermedium Overrun CVE-2002-0823(2) 4857 TROJAN: BackTROJAN:BACKORIFICE:BO2K-CONNECT Orifice 2000Major Client Connectionhigh CVE-1999-0660 1648 HTTP: FrontpageHTTP:FRONTPAGE:FP30REG.DLL-OF fp30reg.dllCritical Overflowcritical CVE-2003-0822 9007 SCAN: IIS EnumerationSCAN:II:IIS-ISAPI-ENUMInfo info P2P: DC: DirectP2P:DC:HUB-LOGIN ConnectInfo Plus Plus Clientinfo Hub Login TROJAN: AOLTROJAN:MISC:AOLADMIN-SRV-RESP Admin ServerMajor Responsehigh CVE-1999-0660 TROJAN: DigitalTROJAN:MISC:ROOTBEER-CLIENT RootbeerMinor Client Connectmedium CVE-1999-0660 HTTP: OfficeHTTP:STC:DL:OFFICEART-PROP Art PropertyMajor Table Bufferhigh OverflowCVE-2009-2528 36650 HTTP: AXIS CommunicationsHTTP:STC:ACTIVEX:AXIS-CAMERAMajor Camerahigh Control (AxisCamControl.ocx)CVE-2008-5260 33408 Unsafe ActiveX Control LDAP: IpswitchLDAP:OVERFLOW:IMAIL-ASN1 IMail LDAPMajor Daemonhigh Remote BufferCVE-2004-0297 Overflow 9682 HTTP: AnyformHTTP:CGI:ANYFORM-SEMICOLON SemicolonMajor high CVE-1999-0066 719 HTTP: Mini HTTP:CGI:W3-MSQL-FILE-DISCLSRSQL w3-msqlMinor File View mediumDisclosure CVE-2000-0012 898 HTTP: IIS MFCHTTP:IIS:MFC-EXT-OF ISAPI FrameworkMajor Overflowhigh (via -

1 Worldwide Revenue
digitalposter08_v19_(jg).qxp 3/7/2008 5:24 PM Page 1 ADAGE.COM/DIGITALFAMILYTREES08 GO ONLINE TO EXPLORE AN INTERACTIVE VERSION WITH PROPERTY DESCRIPTIONS DIGITAL FAMILY TREES 2008 AND LINKS Interactive ventures of top media,web portal and agency companies MEDIA COMPANIES PORTALS/SEARCH AGENCY COMPANIES DIGITAL HOLDINGS OF FIVE MAJOR U.S. MEDIA COMPANIES PROPERTIES OF THE BIG THREE WORLDWIDE DIGITAL PROPERTIES OF THE TOP FOUR AGENCY HOLDING COMPANIES Key digital properties and services. See “About the Digital Family Trees” for more information. Key digital properties and services. Key digital services. Go to AdAge.com/digitalfamilytrees08 to see No. 5 Havas and No. 6 Dentsu. TIME WARNER NEWS CORP. GOOGLE OMNICOM GROUP INTERPUBLIC GROUP OF COS. U.S. UNIQUE VISITORS: 123.8 million U.S. UNIQUE VISITORS: 86.6 million U.S. UNIQUE VISITORS: 134.9 million DIGITAL SHARE OF ’07 REVENUE: 13% Ad Age estimate DIGITAL SHARE OF ’07 REVENUE: 10% Ad Age estimate WORLDWIDE REVENUE (’07): $46.5B U.S. MEDIA WORLDWIDE REVENUE (’07): $28.7B U.S. MEDIA WORLDWIDE REVENUE (’07): $16.6B U.S. MEDIA WORLDWIDE REVENUE (’07): $12.7B HOLDING COMPANY WORLDWIDE REVENUE (’07): $6.6B HOLDING COMPANY DIGITAL REVENUE (’07): $655M Ad Age est. U.S. MEDIA REVENUE (’06): $34.0B COMPANY RANK: 1 U.S. MEDIA REVENUE (’06): $15.4B COMPANY RANK: 4 U.S. MEDIA REVENUE (’06): $4.1B COMPANY RANK: 19 DIGITAL REVENUE (’07): $1.6B Ad Age estimate WORLDWIDE REV. RANK: 1 WORLDWIDE REV. RANK: 3 AOL CABLE ADVERTISING SERVICES AGENCIES AGENCIES AD NETWORKS AOL LIVING MAPQUEST BIGTENNETWORK.COM -

Quick Guide to the Web
Quick Guide to the Web For Reference & For Fun Reference General Reference Wiki Reference Academic Encyclopedias Dictionaries More Glossaries by Topic Basic Info Phone & Address Maps & Directions News Weather Health Answers & How-To Basic Sites Internet Basics News News & Politics Newspapers Media Research Entertainment Movies & TV Shows/Movies Online Movies Television Reference Pop Culture Music Online Music Music Sites Reference Games Computer & Console Internet Puzzles & More Media & Fun Online Video Humor/Fun Baseball & Other Sports Government General Depts & Agencies Law Public_Resources Data & Statistics Travel General Flights Driving Automobiles Hotels Studying Academic Study Aids General Reference Data & Statistics Wiki Reference Encyclopedias Dictionaries More Glossaries by Topic Media Online Shows & Movies Music Video Internet Games Books Newspapers Magazines More Local Info Genealogy Finding Basic Information Basic Search & More Google Yahoo Bing MSN ask.com AOL Wikipedia About.com Internet Public Library Freebase Librarian Chick DMOZ Open Directory Executive Library Web Research OEDB LexisNexis Wayback Machine Norton Site-Checker DigitalResearchTools Web Rankings Alexa Web Tools - Librarian Chick Web 2.0 Tools Top Reference & Resources – Internet Quick Links E-map | Indispensable Links | All My Faves | Joongel | Hotsheet | Quick.as Corsinet | Refdesk Tools | CEO Express Internet Resources Wayback Machine | Alexa | Web Rankings | Norton Site-Checker Useful Web Tools DigitalResearchTools | FOSS Wiki | Librarian Chick | Virtual -

Jews Control U.S.A., Therefore the World – Is That a Good Thing?
Jews Control U.S.A., Therefore the World – Is That a Good Thing? By Chairman of the U.S. based Romanian National Vanguard©2007 www.ronatvan.com You probably don’t believe a world! That’s why we decided to back up with proof & facts all our statements in 15 (as short as possible) Chapters! v. 1.5 1 INDEX 1. Are Jews satanic? 1.1 What The Talmud Rules About Christians 1.2 Foes Destroyed During the Purim Feast 1.3 The Shocking "Kol Nidre" Oath 1.4 The Bar Mitzvah - A Pledge to The Jewish Race 1.5 Jewish Genocide over Armenian People 1.6 The Satanic Bible 1.7 Other Examples 2. Are Jews the “Chosen People” or the real “Israel”? 2.1 Who are the “Chosen People”? 2.2 God & Jesus quotes about race mixing and globalization 3. Are they “eternally persecuted people”? 3.1 Crypto-Judaism 4. Is Judeo-Christianity a healthy “alliance”? 4.1 The “Jesus was a Jew” Hoax 4.2 The "Judeo - Christian" Hoax 4.3 Judaism's Secret Book - The Talmud 5. Are Christian sects Jewish creations? Are they affecting Christianity? 5.1 Biblical Quotes about the sects , the Jews and about the results of them working together. 6. “Anti-Semitism” shield & weapon is making Jews, Gods! 7. Is the “Holocaust” a dirty Jewish LIE? 7.1 The Famous 66 Questions & Answers about the Holocaust 8. Jews control “Anti-Hate”, “Human Rights” & Degraded organizations??? 8.1 Just a small part of the full list: CULTURAL/ETHNIC 8.2 "HATE", GENOCIDE, ETC. -

Hon. Marsha J. Pechman UNITED STATES DISTRICT
Case 2:11-cv-00716-MJP Document 2 Filed 05/03/11 Page 1 of 35 1 Hon. Marsha J. Pechman 2 3 4 5 6 7 8 UNITED STATES DISTRICT COURT WESTERN DISTRICT OF WASHINGTON 9 AT SEATTLE 10 11 INTERVAL LICENSING LLC, Case No. C11-716 MJP 12 Plaintiff, LEAD CASE NO. C10-1385 MJP 13 v. FIRST AMENDED COMPLAINT 14 FOR PATENT INFRINGEMENT YAHOO! INC., 15 JURY DEMAND 16 Defendant. 17 FIRST AMENDED COMPLAINT FOR PATENT INFRINGEMENT 18 19 Plaintiff Interval Licensing LLC, files this first amended complaint for patent 20 infringement against Defendants AOL, Inc., Apple, Inc., eBay, Inc., Facebook, Inc., Google 21 Inc., Netflix, Inc., Office Depot, Inc., OfficeMax Inc., Staples, Inc., Yahoo! Inc., and 22 YouTube, LLC. Plaintiff Interval Licensing LLC alleges: 23 24 25 26 27 28 FIRST AMENDED COMPLAINT FOR PATENT SUSMAN GODFREY L.L.P. INFRINGEMENT 1201 Third Avenue, Suite 3800 Case No. C11-716 MJP Seattle, WA 98101-3000 Page 1 of 35 Tel: (206) 516-3880; Fax: (206) 516-3883 1544610v1/011873 Case 2:11-cv-00716-MJP Document 2 Filed 05/03/11 Page 2 of 35 THE PARTIES 1 2 1. Interval Licensing LLC (“Interval”) is a limited liability company duly 3 organized under the laws of the state of Washington, with its principal place of business at 4 505 Fifth Avenue South, Suite 900, Seattle, WA 98104. 5 2. Interval is informed and believes, and on that basis alleges, that Defendant 6 7 AOL, Inc. (“AOL”) is a corporation duly organized and existing under the laws of the state 8 of Delaware, with its principal place of business at 770 Broadway, New York, NY 10003. -

Radio Internet
RADIO INTERNET Di era modern ini, seluruh segi kehidupan kita membutuhkan berbagai perangkat untuk kemudahan. Hal ini didukung dengan terus berkembangnya alat-alat tersebut dari waktu ke waktu demi kebutuhan kemudahan kita sendiri. Seluruh alat tadi ada baiknya jika kita sebut dengan ”teknologi”. Sekarang ini banyak teknologi kmunikasi yang bermunculan ditengah masyarakat hal ini terjadi karena kebutuhan masyarakat akan informasi yang terus meningakat sehingga dibutuhkan suatu alat penyampaian pesan atau informasi yang cepat dan tepat. Dalam tulisan ini, penulis ingin mengutarakan beberapa informasi tentang radio internet dengan segala layanan kemudahan dan manfaatnya. Radio internet muncul karena suatu kebutuhan akan informasi dan kemampuan transmisi informasi yang cepat tanpa mengenal batas ruang dan waktu. Hal ini sesuai dengan perkembangan zaman yang menuntut adanya suatu jalur transmisiinformasi yang mudah dan mampu mentransfer sejumlah data (info) dalam tempo yang relatif cepat. Diawali dengan dikembangkannya internet oleh sejumlah penyedia layanan internet, radio internet muncul sebagai efek susulan yang disebabkan oleh perkembangan teknologi seiring dengan prinsip-prinsip yang kita kenal sebagai koevolusi, konvergensi, dan kompleksitasnya. Hal-hal selanjutnya yang lebih lengkap akan penulis paparkan dalam bagian selanjutnya. Mengenal Radio Internet Seiring dengan penetrasi internet di dunia yang mulai mencapai angka 1 miliar pengguna, kebutuhan untuk mendapatkan layanan berbasis Internet juga semakin meningkat. Data menunjukkan [1] bahwa, 80% pengguna Internet mengirimkan email, 60% menggunakan instant messaging (seperti Yahoo atau MSN Messenger) dan 55% mendownload file. Kemudian 22% pengguna Internet juga mulai menikmati video lewat Internet. Setelah ATM diperkuat dengan Internet banking, toko buku diperkuat dengan toko buku online, ternyata Radio dan TV juga mengikuti jejak untuk mencoba versi Internet dengan broadcastingnya. -

Spotify Asks Creative Leaders What Music Inspires Them
Spotify – Growing Competitor in Music Catalog Field, But Not FM Radio Competitor • …the underlying premise of Spotify — that people want access to a giant catalog of music instead of buying it piecemeal through iTunes Source: Jeff John Roberts Mar. 12, 2013 paidContent.org Spotify Asks Creative Leaders What Music Inspires Them Wendy Clark, Bob Greenberg and Maurice Levy Share Their Fave Tunes in Cannes Campaign By: Shareen Pathak Published: June 10, 2013 Spotify is certainly taking this year's Cannes Lions festival seriously. The music streaming service is launching a new campaign to celebrate the 60th anniversary of the Cannes Lions that will pay tribute to people who have helped "shape creativity" by asking them what songs inspire them. Created by Droga5, the campaign, dubbed #60Inspirations, launches Monday and features people like Arianna Huffington, Maurice Levy, Bob Greenberg, John Legend and John Boiler. Wendy Clark, senior VP-integrated marketing at Coca-Cola, is also one of the "titans." The two companies signed a global deal in 2012 to create a seamless, social music sharing experience. Rounding out the list of titans are Shelly Lazarus, Chairman Emeritus, Ogilvy& Mather, Steve Stoute, CEO at Translation, David Droga, founder of Droga5, and David Lubars, chief creative officer at BBDO. The campaign lives online, and will result in a unique Spotify playlist of 60 songs, along with commentary from the titans about why they picked them. It'll also be pushed via out-of-home ads appearing at the airport in Nice. 1 Erin Clift, VP-global marketing and partnerships at Spotify, said that while last year, the company went to Cannes in a very "simplistic" way, they really wanted to make a bigger splash this year. -

Original Aol Download
Original aol download Official Website: ; Company: America Online; Recently added version: America Select Version of America Online to Download for FREE!America Online · America Online · America Online · America Online America Online Screenshots. upload screenshot; upload screenshot; upload screenshot; upload screenshot; upload screenshot; upload screenshot. Learn how to install and uninstall the AOL Desktop Software. Download and install the AOL Desktop Software. To download and install the latest AOL Desktop. Discover AOL products and services that provide convenience, connection, entertainment, protection and more! From AOL Mail to the new Alto App to AIM to. It doesn't matter which AOL Advantage plan or if you are using the free AOL service. Simply download the latest version, sign in with your username and. We recommend that you uninstall the old version of AIM from your computer before downloading the new version using the links above. If you are logging in to. AOL VR lets users on Windows , ME and 98 enjoy their favorite online Note: If you are having trouble downloading AOL VR, please click here. America Online was the first version to include email signatures. a “large” number of people — 50, — downloaded the beta version. Old Version of AOL Instant Messenger. Website. Developer. AOL Inc. Latest Version. AOL Instant Messenger Supported Systems. AOL Explorer is a stand-alone browser featuring tabbed browsing, thumbnail tab popups, and many more special features. AOL Software Deutsch: Die "AOL Software" will das Angebot von AOL in einen bequemen Launcher bringen. AOL Explorer, previously known as AOL Browser, is a discontinued graphical web browser based on the Microsoft Trident layout engine and was released by AOL.