System Desiderata for XML Databases
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Describing Media Content of Binary Data in XML W3C Working Group Note 2 May 2005
Table of Contents Describing Media Content of Binary Data in XML W3C Working Group Note 2 May 2005 This version: http://www.w3.org/TR/2005/NOTE-xml-media-types-20050502 Latest version: http://www.w3.org/TR/xml-media-types Previous version: http://www.w3.org/TR/2004/WD-xml-media-types-20041102 Editors: Anish Karmarkar, Oracle Ümit Yalçınalp, SAP (formerly of Oracle) Copyright © 2005 W3C ® (MIT, ERCIM, Keio), All Rights Reserved. W3C liability, trademark and document use rules apply. > >Abstract This document addresses the need to indicate the content-type associated with binary element content in an XML document and the need to specify, in XML Schema, the expected content-type(s) associated with binary element content. It is expected that the additional information about the content-type will be used for optimizing the handling of binary data that is part of a Web services message. Status of this Document This section describes the status of this document at the time of its publication. Other documents may supersede this document. A list of current W3C publications and the latest revision of this technical report can be found in the W3C technical reports index at http://www.w3.org/TR/. This document is a W3C Working Group Note. This document includes the resolution of the comments received on the Last Call Working Draft previously published. The comments on this document and their resolution can be found in the Web Services Description Working Group’s issues list and in the section C Change Log [p.11] . A diff-marked version against the previous version of this document is available. -
XML Specifications Growth of the Web
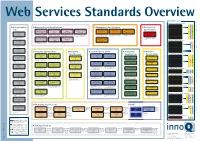
Web Services Standards Overview Dependencies Messaging Specifications SOAP 1.1 SOAP 1.2 Interoperability Business Process Specifications Management Specifications Presentation SOAP Message Transmission Optimization Mechanism WS-Notification the trademarks of their respective owners. of their respective the trademarks Management Using Web Management Of WS-BaseNotification Issues Business Process Execution WS-Choreography Model Web Service Choreography Web Service Choreography WS-Management Specifications Services (WSDM-MUWS) Web Services (WSDM-MOWS) Language for Web Services 1.1 Overview Interface Description Language AMD, Dell, Intel, Microsoft and Sun WS-Topics (BPEL4WS) · 1.1 · BEA Systems, IBM, (WSCI) · 1.0 · W3C 1.0 1.0 1.0 · W3C (CDL4WS) · 1.0 · W3C Microsystems Microsoft, SAP, Sun Microsystems, SAP, BEA Systems WS-BrokeredNotification Working Draft Candidate Recommendation OASIS OASIS Published Specification Web Services for Remote Security Resource Basic Profile Siebel Systems · OASIS-Standard and Intalio · Note OASIS-Standard OASIS-Standard Metadata Portlets (WSRP) WS-Addressing – Core 1.1 ̆ ̆ ̆ ̆ ̆ ̆ ̆ 2.0 WS-I Business Process Execution Language for Web Services WS-Choreography Model Overview defines the format Web Service Choreography Interface (WSCI) describes Web Service Choreography Description Language Web Service Distributed Management: Management Using Web Service Distributed Management: Management Of WS-Management describes a general SOAP-based WS-Addressing – WSDL Binding 1.1(BPEL4WS) provides a language for the formal -

What Is XML Schema?
72076_FM 3/22/02 10:39 AM Page i XML Schema Essentials R. Allen Wyke Andrew Watt Wiley Computer Publishing John Wiley & Sons, Inc. 72076_AppB 3/22/02 10:47 AM Page 378 72076_FM 3/22/02 10:39 AM Page i XML Schema Essentials R. Allen Wyke Andrew Watt Wiley Computer Publishing John Wiley & Sons, Inc. 72076_FM 3/22/02 10:39 AM Page ii Publisher: Robert Ipsen Editor: Cary Sullivan Developmental Editor: Scott Amerman Associate Managing Editor: Penny Linskey Associate New Media Editor: Brian Snapp Text Design & Composition: D&G Limited, LLC Designations used by companies to distinguish their products are often claimed as trademarks. In all instances where John Wiley & Sons, Inc., is aware of a claim, the product names appear in initial capital or ALL CAPITAL LETTERS. Readers, however, should contact the appropriate companies for more complete information regarding trademarks and registration. This book is printed on acid-free paper. Copyright © 2002 by R. Allen Wyke and Andrew Watt. All rights reserved. Published by John Wiley & Sons, Inc. Published simultaneously in Canada. No part of this publication may be reproduced, stored in a retrieval system or transmitted in any form or by any means, electronic, mechanical, photocopying, recording, scanning or otherwise, except as permitted under Sections 107 or 108 of the 1976 United States Copy- right Act, without either the prior written permission of the Publisher, or authorization through payment of the appropriate per-copy fee to the Copyright Clearance Center, 222 Rosewood Drive, Danvers, MA 01923, (978) 750-8400, fax (978) 750-4744. Requests to the Publisher for permission should be addressed to the Permissions Department, John Wiley & Sons, Inc., 605 Third Avenue, New York, NY 10158-0012, (212) 850-6011, fax (212) 850- 6008, E-Mail: PERMREQ @ WILEY.COM. -

Command Injection in XML Signatures and Encryption Bradley W
Command Injection in XML Signatures and Encryption Bradley W. Hill Information Security Partners, July 12, 2007 [email protected] Abstract. The XML Digital Signature1 (XMLDSIG) and XML Encryption2 (XMLENC) standards are complex protocols for securing XML and other content. Among its complexities, the XMLDSIG standard specifies various “Transform” algorithms to identify, manipulate and canonicalize signed content and key material. Unfortunately, the defined transforms have not been rigorously constrained to prevent their use as attack vectors, and denial of service or even arbitrary code execution are probable in implementations that have not specifically guarded against such risks. Attacks against the processing application can be embedded in the KeyInfo portion of a signature, making them inherently unauthenticated, or in the SignedInfo block. Although tampering with the SignedInfo should be detectable, a defective implied order of operations in the specification may still allow unauthenticated attacks here. The ability to execute arbitrary code and perform file system operations with a malicious, invalid signature has been confirmed by the researcher in at least two independent XMLDSIG implementations, and other implementations may be similarly vulnerable. This paper describes the vulnerabilities in detail and offers advice for remediation. The most damaging attack is also likely to apply in other contexts where XSLT is accepted as input, and should be considered by all implementers of complex XML processing systems. Categories and Subject Descriptors Primary Classification: K.6.5 Security and Protection Subject: Invasive software Unauthorized access Authentication Additional Classification: D.2.3 Coding Tools and Techniques (REVISED) Subject: Standards D.2.1 Requirements/Specifications (D.3.1) Subject: Languages Tools General Terms: Security, Reliability, Verification, and Design. -

Describing Media Content of Binary Data in XML W3C Working Group Note 4 May 2005
Table of Contents Describing Media Content of Binary Data in XML W3C Working Group Note 4 May 2005 This version: http://www.w3.org/TR/2005/NOTE-xml-media-types-20050504 Latest version: http://www.w3.org/TR/xml-media-types Previous version: http://www.w3.org/TR/2005/NOTE-xml-media-types-20050502 Editors: Anish Karmarkar, Oracle Ümit Yalçınalp, SAP Copyright © 2005 W3C ® (MIT, ERCIM, Keio), All Rights Reserved. W3C liability, trademark and document use rules apply. > >Abstract This document addresses the need to indicate the content-type associated with binary element content in an XML document and the need to specify, in XML Schema, the expected content-type(s) associated with binary element content. It is expected that the additional information about the content-type will be used for optimizing the handling of binary data that is part of a Web services message. Status of this Document This section describes the status of this document at the time of its publication. Other documents may supersede this document. A list of current W3C publications and the latest revision of this technical report can be found in the W3C technical reports index at http://www.w3.org/TR/. This document is a W3C Working Group Note. This document includes the resolution of the comments received on the Last Call Working Draft previously published. The comments on this document and their resolution can be found in the Web Services Description Working Group’s issues list. There is no technical difference between this document and the 2 May 2005 version; the acknowledgement section has been updated to thank external contributors. -

XML Information Set
XML Information Set XML Information Set W3C Recommendation 24 October 2001 This version: http://www.w3.org/TR/2001/REC-xml-infoset-20011024 Latest version: http://www.w3.org/TR/xml-infoset Previous version: http://www.w3.org/TR/2001/PR-xml-infoset-20010810 Editors: John Cowan, [email protected] Richard Tobin, [email protected] Copyright ©1999, 2000, 2001 W3C® (MIT, INRIA, Keio), All Rights Reserved. W3C liability, trademark, document use and software licensing rules apply. Abstract This specification provides a set of definitions for use in other specifications that need to refer to the information in an XML document. Status of this Document This section describes the status of this document at the time of its publication. Other documents may supersede this document. The latest status of this document series is maintained at the W3C. This is the W3C Recommendation of the XML Information Set. This document has been reviewed by W3C Members and other interested parties and has been endorsed by the Director as a W3C Recommendation. It is a stable document and may be used as reference material or cited as a normative reference from another document. W3C's role in making the Recommendation is to draw attention to the specification and to promote its widespread deployment. This enhances the functionality and interoperability of the file:///C|/Documents%20and%20Settings/immdca01/Desktop/xml-infoset.html (1 of 16) [8/12/2002 10:38:58 AM] XML Information Set Web. This document has been produced by the W3C XML Core Working Group as part of the XML Activity in the W3C Architecture Domain. -
5241 Index 0939-0964.Qxd 29/08/02 5.30 Pm Page 941
5241_index_0939-0964.qxd 29/08/02 5.30 pm Page 941 INDEX 941 5241_index_0939-0964.qxd 29/08/02 5.30 pm Page 942 Index 942 Regular A Alternatives, 362 Analysis Patterns: Reusable Expression ABSENT value, 67 Object Models, 521 Symbols abstract attribute, 62, 64–66 ancestor (XPath axis), 54 of complexType element, ancestor-or-self (XPath axis), . escape character, 368, 369 247–248, 512, 719 54 . metacharacter, 361 of element element, 148–149 Annotation, 82 ? metacharacter, 361, 375 mapping to object-oriented defined, 390 ( metacharacter, 361 language, 513–514 mapping to object-oriented ) metacharacter, 361 Abstract language, 521 { metacharacter, 361 attribute type, 934 Microsoft use of term, } metacharacter, 361 defined, 58 821–822 + metacharacter, 361, 375 element type, 16, 17, 18, 934 properties of, 411 * metacharacter, 361, 375 object, corresponding to docu- annotation content option ^ metacharacter, 379 ment, 14 for schema element, 115 \ metacharacter, 361 uses of term, 238, 931–932 annotation element, 82, 83, | metacharacter, 361 Abstract character, 67 254, 260, 722, 859 \. escape character, 366 Abstract document attributes of, 118 \? escape character, 366 document information item content options for, 118–119 \( escape character, 367 view of, 62 example of use of, 117 \) escape character, 367 infoset view of, 62 function of, 116, 124, 128 \{ escape character, 367 makeup of, 59 nested, 83–84 \} escape character, 367 properties of, 66 Anonymous component, 82 \+ escape character, 367 Abstract element, 14–15 any element, 859 \- escape character, -

SWAD-Europe Deliverable 5.1: Schema Technology Survey
Sat Jun 05 2004 23:47:40 Europe/London SWAD-Europe Deliverable 5.1: Schema Technology Survey Project name: Semantic Web Advanced Development for Europe (SWAD-Europe) Project Number: IST-2001-34732 Workpackage name: 5. Integration with XML Technology Workpackage description: ☞http://www.w3.org/2001/sw/Europe/plan/workpackages/live/esw-wp-5.html Deliverable title: SWAD-Europe: Schema Technology Survey URI: ☞http://www.w3.org/2001/sw/Europe/reports/xml_schema_tools_techniques_report Authors: Stephen Buswell, Dan Brickley, Brian Matthews Abstract: This report surveys the state of schema annotation and mapping technology. It takes a practical approach by targeting the work to the needs of developers, providing background to support our attempts to answer frequently asked questions on this subject. The report first reviews previous work on 'bridging languages', giving an overview of the major approaches and uses that to motivate further technical work to progress the state of the art in this area. Status: Snapshot release for discussion and editorial work. Further revisions are planned during WP4. Comments on this document are welcome and should be sent to the ☞[email protected] list. An archive of this list is available at ☞http://lists.w3.org/Archives/Public/public-esw/ This report is part of ☞SWAD-Europe ☞Work package 5: Integration with XML Technology and addresses the topic of Schema annotation, and the relationship(s) between RDF and XML technologies. The variety of so-called 'schema languages' for the Web has caused some confusion. This document attempts to place them in context, and explore the state of the art in tools for mapping data between the different approaches. -

XML Tutorial Description
Introduction to XML Tutorial Description With your HTML knowledge, you have a solid foundation for working with markup languages. However, unlike HTML, XML is more flexible, Bebo White allowing for custom tag creation. This course [email protected] introduces the fundamentals of XML and its related technologies so that you can create your own markup language. InterLab 2006 FermiLab October 2006 Topics* What Is Markup? • XML well-formed documents • Information added to a text to make its structure • Validation concepts comprehensible • DTD syntax and constructs • Pre-computer markup (punctuational and presentational) • W3C Schema syntax and constructs • Word divisions • XSL(T) syntax and processing • Punctuation • XPath addressing language • Copy-editor and typesetters marks • Development and design considerations • Formatting conventions • XML processing model • XML development and processing tools * Tutorial plus references Computer Markup (1/3) Computer Markup (2/3) • Any kind of codes added to a document • Declarative markup (cont) • Typesetting (presentational markup) • Names and structure • Macros embedded in ASCII • Framework for indirection • Commands to define the layout • Finer level of detail (most human-legible signals are • MS Word, TeX, RTF, Scribe, Script, nroff, etc. overloaded) • *Hello* Æ Hello • Independent of presentation (abstract) ••/Hello//Hello/ Æ Hello • Often called “semantic” • Declarative markup • HTML (sometimes) ••XMLXML Computer Markup (3/3) Markup – ISO-Definitions • Semantic Markup • Markup – Text -

Exploring the XML World
Lars Strandén SP Swedish National Testing and Research Institute develops and transfers Exploring the XML World technology for improving competitiveness and quality in industry, and for safety, conservation of resources and good environment in society as a whole. With - A survey for dependable systems Swedens widest and most sophisticated range of equipment and expertise for technical investigation, measurement, testing and certfi cation, we perform research and development in close liaison with universities, institutes of technology and international partners. SP is a EU-notifi ed body and accredited test laboratory. Our headquarters are in Borås, in the west part of Sweden. SP Swedish National Testing and Research Institute SP Swedish National Testing SP Electronics SP REPORT 2004:04 ISBN 91-7848-976-8 ISSN 0284-5172 SP Swedish National Testing and Research Institute Box 857 SE-501 15 BORÅS, SWEDEN Telephone: + 46 33 16 50 00, Telefax: +46 33 13 55 02 SP Electronics E-mail: [email protected], Internet: www.sp.se SP REPORT 2004:04 Lars Strandén Exploring the XML World - A survey for dependable systems 2 Abstract Exploring the XML World - A survey for dependable systems The report gives an overview of and an introduction to the XML world i.e. the definition of XML and how it can be applied. The content shall not be considered a development tutorial since this is better covered by books and information available on the Internet. Instead this report takes a top-down perspective and focuses on the possibilities when using XML e.g. concerning functionality, tools and supporting standards. Getting started with XML is very easy and the threshold is low. -

Chapter 7 XML.Pptx
Prof. Dr.-Ing. Stefan Deßloch AG Heterogene Informationssysteme Geb. 36, Raum 329 Tel. 0631/205 3275 [email protected] Chapter 7 - XML XML Origin and Usages n Defined by the WWW Consortium (W3C) n Originally intended as a document markup language, not a database language n Documents have tags giving extra information about sections of the document n For example: n <title> XML </title> n <slide> XML Origin and Usages </slide> n Meta-language: used to define arbitrary XML languages/vocabularies (e.g. XHTML) n Derived from SGML (Standard Generalized Markup Language) n standard for document description n enables document interchange in publishing, office, engineering, … n main idea: separate form from structure n XML is simpler to use than SGML n roughly 20% complexity achieves 80% functionality © Prof.Dr.-Ing. Stefan Deßloch XML Origin and Usages (cont.) n XML documents are to some extent self-describing n Tags represent metadata n Metadata and data are combined in the same document n semi-structured data modeling n Example <bank> <account> <account-number> A-101 </account-number> <branch-name> Downtown </branch-name> <balance> 500 </balance> </account> <depositor> <account-number> A-101 </account-number> <customer-name> Johnson </customer-name> </depositor> </bank> © Prof.Dr.-Ing. Stefan Deßloch Forces Driving XML n Document Processing n Goal: use document in various, evolving systems n structure – content – layout n grammar: markup vocabulary for mixed content n Data Bases and Data Exchange n Goal: data independence n structured, typed data – schema-driven – integrity constraints n Semi-structured Data and Information Integration n Goal: integrate autonomous data sources n data source schema not known in detail – schemata are dynamic n schema might be revealed through analysis only after data processing © Prof.Dr.-Ing. -

Guidelines for the Use of Extensible Markup Language (XML) Within IETF Protocols
Network Working Group S. Hollenbeck Request for Comments: 3470 VeriSign, Inc. BCP: 70 M. Rose Category: Best Current Practice Dover Beach Consulting, Inc. L. Masinter Adobe Systems Incorporated January 2003 Guidelines for the Use of Extensible Markup Language (XML) within IETF Protocols Status of this Memo This document specifies an Internet Best Current Practices for the Internet Community, and requests discussion and suggestions for improvements. Distribution of this memo is unlimited. Copyright Notice Copyright © The Internet Society (2003). All Rights Reserved. Abstract The Extensible Markup Language (XML) is a framework for structuring data. While it evolved from Standard Generalized Markup Language (SGML) -- a markup language primarily focused on structuring documents -- XML has evolved to be a widely-used mechanism for representing structured data. There are a wide variety of Internet protocols being developed; many have need for a representation for structured data relevant to their application. There has been much interest in the use of XML as a representation method. This document describes basic XML concepts, analyzes various alternatives in the use of XML, and provides guidelines for the use of XML within IETF standards-track protocols. Conventions Used In This Document This document recommends, as policy, what specifications for Internet protocols -- and, in particular, IETF standards track protocol documents -- should include as normative language within them. The capitalized keywords "SHOULD", "MUST", "REQUIRED", etc. are used in the sense of how they would be used within other documents with the meanings as specified in BCP 14, RFC 2119 [1]. RFC 3470 XML Within IETF Protocols January 2003 Table of Contents 1 Introduction and Overview....................................................................................................................................