SWAD-Europe Deliverable 5.1: Schema Technology Survey
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Describing Media Content of Binary Data in XML W3C Working Group Note 2 May 2005
Table of Contents Describing Media Content of Binary Data in XML W3C Working Group Note 2 May 2005 This version: http://www.w3.org/TR/2005/NOTE-xml-media-types-20050502 Latest version: http://www.w3.org/TR/xml-media-types Previous version: http://www.w3.org/TR/2004/WD-xml-media-types-20041102 Editors: Anish Karmarkar, Oracle Ümit Yalçınalp, SAP (formerly of Oracle) Copyright © 2005 W3C ® (MIT, ERCIM, Keio), All Rights Reserved. W3C liability, trademark and document use rules apply. > >Abstract This document addresses the need to indicate the content-type associated with binary element content in an XML document and the need to specify, in XML Schema, the expected content-type(s) associated with binary element content. It is expected that the additional information about the content-type will be used for optimizing the handling of binary data that is part of a Web services message. Status of this Document This section describes the status of this document at the time of its publication. Other documents may supersede this document. A list of current W3C publications and the latest revision of this technical report can be found in the W3C technical reports index at http://www.w3.org/TR/. This document is a W3C Working Group Note. This document includes the resolution of the comments received on the Last Call Working Draft previously published. The comments on this document and their resolution can be found in the Web Services Description Working Group’s issues list and in the section C Change Log [p.11] . A diff-marked version against the previous version of this document is available. -
XML Specifications Growth of the Web
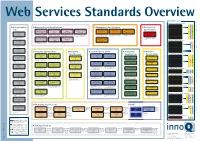
Web Services Standards Overview Dependencies Messaging Specifications SOAP 1.1 SOAP 1.2 Interoperability Business Process Specifications Management Specifications Presentation SOAP Message Transmission Optimization Mechanism WS-Notification the trademarks of their respective owners. of their respective the trademarks Management Using Web Management Of WS-BaseNotification Issues Business Process Execution WS-Choreography Model Web Service Choreography Web Service Choreography WS-Management Specifications Services (WSDM-MUWS) Web Services (WSDM-MOWS) Language for Web Services 1.1 Overview Interface Description Language AMD, Dell, Intel, Microsoft and Sun WS-Topics (BPEL4WS) · 1.1 · BEA Systems, IBM, (WSCI) · 1.0 · W3C 1.0 1.0 1.0 · W3C (CDL4WS) · 1.0 · W3C Microsystems Microsoft, SAP, Sun Microsystems, SAP, BEA Systems WS-BrokeredNotification Working Draft Candidate Recommendation OASIS OASIS Published Specification Web Services for Remote Security Resource Basic Profile Siebel Systems · OASIS-Standard and Intalio · Note OASIS-Standard OASIS-Standard Metadata Portlets (WSRP) WS-Addressing – Core 1.1 ̆ ̆ ̆ ̆ ̆ ̆ ̆ 2.0 WS-I Business Process Execution Language for Web Services WS-Choreography Model Overview defines the format Web Service Choreography Interface (WSCI) describes Web Service Choreography Description Language Web Service Distributed Management: Management Using Web Service Distributed Management: Management Of WS-Management describes a general SOAP-based WS-Addressing – WSDL Binding 1.1(BPEL4WS) provides a language for the formal -

Specification for JSON Abstract Data Notation Version
Standards Track Work Product Specification for JSON Abstract Data Notation (JADN) Version 1.0 Committee Specification 01 17 August 2021 This stage: https://docs.oasis-open.org/openc2/jadn/v1.0/cs01/jadn-v1.0-cs01.md (Authoritative) https://docs.oasis-open.org/openc2/jadn/v1.0/cs01/jadn-v1.0-cs01.html https://docs.oasis-open.org/openc2/jadn/v1.0/cs01/jadn-v1.0-cs01.pdf Previous stage: https://docs.oasis-open.org/openc2/jadn/v1.0/csd02/jadn-v1.0-csd02.md (Authoritative) https://docs.oasis-open.org/openc2/jadn/v1.0/csd02/jadn-v1.0-csd02.html https://docs.oasis-open.org/openc2/jadn/v1.0/csd02/jadn-v1.0-csd02.pdf Latest stage: https://docs.oasis-open.org/openc2/jadn/v1.0/jadn-v1.0.md (Authoritative) https://docs.oasis-open.org/openc2/jadn/v1.0/jadn-v1.0.html https://docs.oasis-open.org/openc2/jadn/v1.0/jadn-v1.0.pdf Technical Committee: OASIS Open Command and Control (OpenC2) TC Chair: Duncan Sparrell ([email protected]), sFractal Consulting LLC Editor: David Kemp ([email protected]), National Security Agency Additional artifacts: This prose specification is one component of a Work Product that also includes: JSON schema for JADN documents: https://docs.oasis-open.org/openc2/jadn/v1.0/cs01/schemas/jadn-v1.0.json JADN schema for JADN documents: https://docs.oasis-open.org/openc2/jadn/v1.0/cs01/schemas/jadn-v1.0.jadn Abstract: JSON Abstract Data Notation (JADN) is a UML-based information modeling language that defines data structure independently of data format. -

What Is XML Schema?
72076_FM 3/22/02 10:39 AM Page i XML Schema Essentials R. Allen Wyke Andrew Watt Wiley Computer Publishing John Wiley & Sons, Inc. 72076_AppB 3/22/02 10:47 AM Page 378 72076_FM 3/22/02 10:39 AM Page i XML Schema Essentials R. Allen Wyke Andrew Watt Wiley Computer Publishing John Wiley & Sons, Inc. 72076_FM 3/22/02 10:39 AM Page ii Publisher: Robert Ipsen Editor: Cary Sullivan Developmental Editor: Scott Amerman Associate Managing Editor: Penny Linskey Associate New Media Editor: Brian Snapp Text Design & Composition: D&G Limited, LLC Designations used by companies to distinguish their products are often claimed as trademarks. In all instances where John Wiley & Sons, Inc., is aware of a claim, the product names appear in initial capital or ALL CAPITAL LETTERS. Readers, however, should contact the appropriate companies for more complete information regarding trademarks and registration. This book is printed on acid-free paper. Copyright © 2002 by R. Allen Wyke and Andrew Watt. All rights reserved. Published by John Wiley & Sons, Inc. Published simultaneously in Canada. No part of this publication may be reproduced, stored in a retrieval system or transmitted in any form or by any means, electronic, mechanical, photocopying, recording, scanning or otherwise, except as permitted under Sections 107 or 108 of the 1976 United States Copy- right Act, without either the prior written permission of the Publisher, or authorization through payment of the appropriate per-copy fee to the Copyright Clearance Center, 222 Rosewood Drive, Danvers, MA 01923, (978) 750-8400, fax (978) 750-4744. Requests to the Publisher for permission should be addressed to the Permissions Department, John Wiley & Sons, Inc., 605 Third Avenue, New York, NY 10158-0012, (212) 850-6011, fax (212) 850- 6008, E-Mail: PERMREQ @ WILEY.COM. -

Command Injection in XML Signatures and Encryption Bradley W
Command Injection in XML Signatures and Encryption Bradley W. Hill Information Security Partners, July 12, 2007 [email protected] Abstract. The XML Digital Signature1 (XMLDSIG) and XML Encryption2 (XMLENC) standards are complex protocols for securing XML and other content. Among its complexities, the XMLDSIG standard specifies various “Transform” algorithms to identify, manipulate and canonicalize signed content and key material. Unfortunately, the defined transforms have not been rigorously constrained to prevent their use as attack vectors, and denial of service or even arbitrary code execution are probable in implementations that have not specifically guarded against such risks. Attacks against the processing application can be embedded in the KeyInfo portion of a signature, making them inherently unauthenticated, or in the SignedInfo block. Although tampering with the SignedInfo should be detectable, a defective implied order of operations in the specification may still allow unauthenticated attacks here. The ability to execute arbitrary code and perform file system operations with a malicious, invalid signature has been confirmed by the researcher in at least two independent XMLDSIG implementations, and other implementations may be similarly vulnerable. This paper describes the vulnerabilities in detail and offers advice for remediation. The most damaging attack is also likely to apply in other contexts where XSLT is accepted as input, and should be considered by all implementers of complex XML processing systems. Categories and Subject Descriptors Primary Classification: K.6.5 Security and Protection Subject: Invasive software Unauthorized access Authentication Additional Classification: D.2.3 Coding Tools and Techniques (REVISED) Subject: Standards D.2.1 Requirements/Specifications (D.3.1) Subject: Languages Tools General Terms: Security, Reliability, Verification, and Design. -

Rdfa in XHTML: Syntax and Processing Rdfa in XHTML: Syntax and Processing
RDFa in XHTML: Syntax and Processing RDFa in XHTML: Syntax and Processing RDFa in XHTML: Syntax and Processing A collection of attributes and processing rules for extending XHTML to support RDF W3C Recommendation 14 October 2008 This version: http://www.w3.org/TR/2008/REC-rdfa-syntax-20081014 Latest version: http://www.w3.org/TR/rdfa-syntax Previous version: http://www.w3.org/TR/2008/PR-rdfa-syntax-20080904 Diff from previous version: rdfa-syntax-diff.html Editors: Ben Adida, Creative Commons [email protected] Mark Birbeck, webBackplane [email protected] Shane McCarron, Applied Testing and Technology, Inc. [email protected] Steven Pemberton, CWI Please refer to the errata for this document, which may include some normative corrections. This document is also available in these non-normative formats: PostScript version, PDF version, ZIP archive, and Gzip’d TAR archive. The English version of this specification is the only normative version. Non-normative translations may also be available. Copyright © 2007-2008 W3C® (MIT, ERCIM, Keio), All Rights Reserved. W3C liability, trademark and document use rules apply. Abstract The current Web is primarily made up of an enormous number of documents that have been created using HTML. These documents contain significant amounts of structured data, which is largely unavailable to tools and applications. When publishers can express this data more completely, and when tools can read it, a new world of user functionality becomes available, letting users transfer structured data between applications and web sites, and allowing browsing applications to improve the user experience: an event on a web page can be directly imported - 1 - How to Read this Document RDFa in XHTML: Syntax and Processing into a user’s desktop calendar; a license on a document can be detected so that users can be informed of their rights automatically; a photo’s creator, camera setting information, resolution, location and topic can be published as easily as the original photo itself, enabling structured search and sharing. -

Rdfs:Frbr– Towards an Implementation Model for Library Catalogs Using Semantic Web Technology
rdfs:frbr– Towards an Implementation Model for Library Catalogs Using Semantic Web Technology Stefan Gradmann SUMMARY. The paper sets out from a few basic observations (biblio- graphic information is still mostly part of the ‘hidden Web,’ library au- tomation methods still have a low WWW-transparency, and take-up of FRBR has been rather slow) and continues taking a closer look at Se- mantic Web technology components. This results in a proposal for im- plementing FRBR as RDF-Schema and of RDF-based library catalogues built on such an approach. The contribution concludes with a discussion of selected strategic benefits resulting from such an approach. [Article copies available for a fee from The Haworth Document Delivery Service: 1-800-HAWORTH. E-mail address: <[email protected]> Web- site: <http://www.HaworthPress.com> © 2005 by The Haworth Press, Inc. All rights reserved.] Stefan Gradmann, PhD, is Head, Hamburg University “Virtual Campus Library” Unit, which is part of the computing center and has a mission of providing information management services to the university as a whole, including e-publication services and open access to electronic scientific information resources. Address correspondence to: Stefan Gradmann, Virtuelle Campusbibliothek Regionales Rechenzentrum der Universität Hamburg, Schlüterstrasse 70, D-20146 Hamburg, Germany (E-mail: [email protected]). [Haworth co-indexing entry note]: “rdfs:frbr–Towards an Implementation Model for Library Cata- logs Using Semantic Web Technology.” Gradmann, Stefan. Co-published simultaneously in Cataloging & Classification Quarterly (The Haworth Information Press, an imprint of The Haworth Press, Inc.) Vol. 39, No. 3/4, 2005, pp. 63-75; and: Functional Requirements for Bibliographic Records (FRBR): Hype or Cure-All? (ed: Patrick Le Boeuf) The Haworth Information Press, an imprint of The Haworth Press, Inc., 2005, pp. -

Describing Media Content of Binary Data in XML W3C Working Group Note 4 May 2005
Table of Contents Describing Media Content of Binary Data in XML W3C Working Group Note 4 May 2005 This version: http://www.w3.org/TR/2005/NOTE-xml-media-types-20050504 Latest version: http://www.w3.org/TR/xml-media-types Previous version: http://www.w3.org/TR/2005/NOTE-xml-media-types-20050502 Editors: Anish Karmarkar, Oracle Ümit Yalçınalp, SAP Copyright © 2005 W3C ® (MIT, ERCIM, Keio), All Rights Reserved. W3C liability, trademark and document use rules apply. > >Abstract This document addresses the need to indicate the content-type associated with binary element content in an XML document and the need to specify, in XML Schema, the expected content-type(s) associated with binary element content. It is expected that the additional information about the content-type will be used for optimizing the handling of binary data that is part of a Web services message. Status of this Document This section describes the status of this document at the time of its publication. Other documents may supersede this document. A list of current W3C publications and the latest revision of this technical report can be found in the W3C technical reports index at http://www.w3.org/TR/. This document is a W3C Working Group Note. This document includes the resolution of the comments received on the Last Call Working Draft previously published. The comments on this document and their resolution can be found in the Web Services Description Working Group’s issues list. There is no technical difference between this document and the 2 May 2005 version; the acknowledgement section has been updated to thank external contributors. -

Darwin Information Typing Architecture (DITA) Version 1.3 Draft 29 May 2015
Darwin Information Typing Architecture (DITA) Version 1.3 Draft 29 May 2015 Specification URIs This version: http://docs.oasis-open.org/dita/dita/v1.3/csd01/dita-v1.3-csd01.html (Authoritative version) http://docs.oasis-open.org/dita/dita/v1.3/csd01/dita-v1.3-csd01.pdf http://docs.oasis-open.org/dita/dita/v1.3/csd01/dita-v1.3-csd01-chm.zip http://docs.oasis-open.org/dita/dita/v1.3/csd01/dita-v1.3-csd01-xhtml.zip Previous version: Not applicable Latest version: http://docs.oasis-open.org/dita/dita/v1.3/dita-v1.3-csd01.html (Authoritative version) http://docs.oasis-open.org/dita/dita/v1.3/dita-v1.3-csd01.pdf http://docs.oasis-open.org/dita/dita/v1.3/dita-v1.3-csd01-chm.zip http://docs.oasis-open.org/dita/dita/v1.3/dita-v1.3-csd01-xhtml.zip Technical committee: OASIS Darwin Information Typing Architecture (DITA) TC Chair: Kristen James Eberlein ([email protected]), Eberlein Consulting LLC Editors: Robert D. Anderson ([email protected]), IBM Kristen James Eberlein ([email protected]), Eberlein Consulting LLC Additional artifacts: This prose specification is one component of a work product that also includes: OASIS DITA Version 1.3 RELAX NG: http://docs.oasis-open.org/dita/dita/v1.3/csd01/schemas/ DITA1.3-rng.zip OASIS DITA Version 1.3 DTDs: http://docs.oasis-open.org/dita/v1.3/os/DITA1.3-dtds.zip OASIS DITA Version 1.3 XML Schemas: http://docs.oasis-open.org/dita/v1.3/os/DITA1.3-xsds.zip DITA source that was used to generate this document: http://docs.oasis-open.org/dita/dita/v1.3/ csd01/source/DITA1.3-source.zip Abstract: The Darwin Information Typing Architecture (DITA) 1.3 specification defines both a) a set of document types for authoring and organizing topic-oriented information; and b) a set of mechanisms for combining, extending, and constraining document types. -

An Automated Approach to Grammar Recovery for a Dialect of the C++ Language
An Automated Approach to Grammar Recovery for a Dialect of the C++ Language Edward B. Duffy and Brian A. Malloy School of Computing Clemson University Clemson, SC 29634, USA feduffy,[email protected] Abstract plications developed in a new or existing language [12, 15]. Frequently, the only representation of a dialect is the gram- In this paper we present the design and implementa- mar contained in the source code of a compiler; however, a tion of a fully automated technique for reverse engineering compiler grammar is difficult to comprehend since parser or recovering a grammar from existing language artifacts. generation algorithms place restrictions on the form of the The technique that we describe uses only test cases and a compiler grammar [16, page 10]. parse tree, and we apply the technique to a dialect of the Another problem with language dialects is that there C++ language. However, given test cases and a parse tree has been little research, to date, addressing the problem for a language or a dialect of a language, our technique of reverse engineering a grammar or language specifica- can be used to recover a grammar for the language, in- tion for a language dialect from existing language arti- cluding languages such as Java, C, Python or Ruby. facts. Lammel¨ and Verhoef have developed a technique that uses a language reference manual and test cases to recover a grammar for a language or dialect [16]. How- 1. Introduction ever, their technique requires user intervention along most of the stages of recovery and some of the recovery process The role of programming languages in software devel- is manual. -

XML Information Set
XML Information Set XML Information Set W3C Recommendation 24 October 2001 This version: http://www.w3.org/TR/2001/REC-xml-infoset-20011024 Latest version: http://www.w3.org/TR/xml-infoset Previous version: http://www.w3.org/TR/2001/PR-xml-infoset-20010810 Editors: John Cowan, [email protected] Richard Tobin, [email protected] Copyright ©1999, 2000, 2001 W3C® (MIT, INRIA, Keio), All Rights Reserved. W3C liability, trademark, document use and software licensing rules apply. Abstract This specification provides a set of definitions for use in other specifications that need to refer to the information in an XML document. Status of this Document This section describes the status of this document at the time of its publication. Other documents may supersede this document. The latest status of this document series is maintained at the W3C. This is the W3C Recommendation of the XML Information Set. This document has been reviewed by W3C Members and other interested parties and has been endorsed by the Director as a W3C Recommendation. It is a stable document and may be used as reference material or cited as a normative reference from another document. W3C's role in making the Recommendation is to draw attention to the specification and to promote its widespread deployment. This enhances the functionality and interoperability of the file:///C|/Documents%20and%20Settings/immdca01/Desktop/xml-infoset.html (1 of 16) [8/12/2002 10:38:58 AM] XML Information Set Web. This document has been produced by the W3C XML Core Working Group as part of the XML Activity in the W3C Architecture Domain. -

XML: Looking at the Forest Instead of the Trees Guy Lapalme Professor Département D©Informatique Et De Recherche Opérationnelle Université De Montréal
XML: Looking at the Forest Instead of the Trees Guy Lapalme Professor Département d©informatique et de recherche opérationnelle Université de Montréal C.P. 6128, Succ. Centre-Ville Montréal, Québec Canada H3C 3J7 [email protected] http://www.iro.umontreal.ca/~lapalme/ForestInsteadOfTheTrees/ Publication date April 14, 2019 XML to PDF by RenderX XEP XSL-FO Formatter, visit us at http://www.renderx.com/ XML: Looking at the Forest Instead of the Trees Guy Lapalme Professor Département d©informatique et de recherche opérationnelle Université de Montréal C.P. 6128, Succ. Centre-Ville Montréal, Québec Canada H3C 3J7 [email protected] http://www.iro.umontreal.ca/~lapalme/ForestInsteadOfTheTrees/ Publication date April 14, 2019 Abstract This tutorial gives a high-level overview of the main principles underlying some XML technologies: DTD, XML Schema, RELAX NG, Schematron, XPath, XSL stylesheets, Formatting Objects, DOM, SAX and StAX models of processing. They are presented from the point of view of the computer scientist, without the hype too often associated with them. We do not give a detailed description but we focus on the relations between the main ideas of XML and other computer language technologies. A single compact pretty-print example is used throughout the text to illustrate the processing of an XML structure with XML technologies or with Java programs. We also show how to create an XML document by programming in Java, in Ruby, in Python, in PHP, in E4X (Ecmascript for XML) and in Swift. The source code of the example XML ®les and the programs are available either at the companion web site of this document or by clicking on the ®le name within brackets at the start of the caption of each example.