Building the Semantic Web on XML
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Describing Media Content of Binary Data in XML W3C Working Group Note 2 May 2005
Table of Contents Describing Media Content of Binary Data in XML W3C Working Group Note 2 May 2005 This version: http://www.w3.org/TR/2005/NOTE-xml-media-types-20050502 Latest version: http://www.w3.org/TR/xml-media-types Previous version: http://www.w3.org/TR/2004/WD-xml-media-types-20041102 Editors: Anish Karmarkar, Oracle Ümit Yalçınalp, SAP (formerly of Oracle) Copyright © 2005 W3C ® (MIT, ERCIM, Keio), All Rights Reserved. W3C liability, trademark and document use rules apply. > >Abstract This document addresses the need to indicate the content-type associated with binary element content in an XML document and the need to specify, in XML Schema, the expected content-type(s) associated with binary element content. It is expected that the additional information about the content-type will be used for optimizing the handling of binary data that is part of a Web services message. Status of this Document This section describes the status of this document at the time of its publication. Other documents may supersede this document. A list of current W3C publications and the latest revision of this technical report can be found in the W3C technical reports index at http://www.w3.org/TR/. This document is a W3C Working Group Note. This document includes the resolution of the comments received on the Last Call Working Draft previously published. The comments on this document and their resolution can be found in the Web Services Description Working Group’s issues list and in the section C Change Log [p.11] . A diff-marked version against the previous version of this document is available. -
XML Specifications Growth of the Web
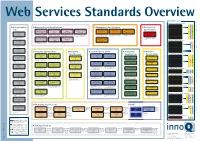
Web Services Standards Overview Dependencies Messaging Specifications SOAP 1.1 SOAP 1.2 Interoperability Business Process Specifications Management Specifications Presentation SOAP Message Transmission Optimization Mechanism WS-Notification the trademarks of their respective owners. of their respective the trademarks Management Using Web Management Of WS-BaseNotification Issues Business Process Execution WS-Choreography Model Web Service Choreography Web Service Choreography WS-Management Specifications Services (WSDM-MUWS) Web Services (WSDM-MOWS) Language for Web Services 1.1 Overview Interface Description Language AMD, Dell, Intel, Microsoft and Sun WS-Topics (BPEL4WS) · 1.1 · BEA Systems, IBM, (WSCI) · 1.0 · W3C 1.0 1.0 1.0 · W3C (CDL4WS) · 1.0 · W3C Microsystems Microsoft, SAP, Sun Microsystems, SAP, BEA Systems WS-BrokeredNotification Working Draft Candidate Recommendation OASIS OASIS Published Specification Web Services for Remote Security Resource Basic Profile Siebel Systems · OASIS-Standard and Intalio · Note OASIS-Standard OASIS-Standard Metadata Portlets (WSRP) WS-Addressing – Core 1.1 ̆ ̆ ̆ ̆ ̆ ̆ ̆ 2.0 WS-I Business Process Execution Language for Web Services WS-Choreography Model Overview defines the format Web Service Choreography Interface (WSCI) describes Web Service Choreography Description Language Web Service Distributed Management: Management Using Web Service Distributed Management: Management Of WS-Management describes a general SOAP-based WS-Addressing – WSDL Binding 1.1(BPEL4WS) provides a language for the formal -

Ontologies and Semantic Web for the Internet of Things - a Survey
See discussions, stats, and author profiles for this publication at: https://www.researchgate.net/publication/312113565 Ontologies and Semantic Web for the Internet of Things - a survey Conference Paper · October 2016 DOI: 10.1109/IECON.2016.7793744 CITATIONS READS 5 256 2 authors: Ioan Szilagyi Patrice Wira Université de Haute-Alsace Université de Haute-Alsace 10 PUBLICATIONS 17 CITATIONS 122 PUBLICATIONS 679 CITATIONS SEE PROFILE SEE PROFILE Some of the authors of this publication are also working on these related projects: Physics of Solar Cells and Systems View project Artificial intelligence for renewable power generation and management: Application to wind and photovoltaic systems View project All content following this page was uploaded by Patrice Wira on 08 January 2018. The user has requested enhancement of the downloaded file. Ontologies and Semantic Web for the Internet of Things – A Survey Ioan Szilagyi, Patrice Wira MIPS Laboratory, University of Haute-Alsace, Mulhouse, France {ioan.szilagyi; patrice.wira}@uha.fr Abstract—The reality of Internet of Things (IoT), with its one of the most important task in an IoT system [6]. Providing growing number of devices and their diversity is challenging interoperability among the things is “one of the most current approaches and technologies for a smarter integration of fundamental requirements to support object addressing, their data, applications and services. While the Web is seen as a tracking and discovery as well as information representation, convenient platform for integrating things, the Semantic Web can storage, and exchange” [4]. further improve its capacity to understand things’ data and facilitate their interoperability. In this paper we present an There is consensus that Semantic Technologies is the overview of some of the Semantic Web technologies used in IoT appropriate tool to address the diversity of Things [4], [7]–[9]. -

What Is XML Schema?
72076_FM 3/22/02 10:39 AM Page i XML Schema Essentials R. Allen Wyke Andrew Watt Wiley Computer Publishing John Wiley & Sons, Inc. 72076_AppB 3/22/02 10:47 AM Page 378 72076_FM 3/22/02 10:39 AM Page i XML Schema Essentials R. Allen Wyke Andrew Watt Wiley Computer Publishing John Wiley & Sons, Inc. 72076_FM 3/22/02 10:39 AM Page ii Publisher: Robert Ipsen Editor: Cary Sullivan Developmental Editor: Scott Amerman Associate Managing Editor: Penny Linskey Associate New Media Editor: Brian Snapp Text Design & Composition: D&G Limited, LLC Designations used by companies to distinguish their products are often claimed as trademarks. In all instances where John Wiley & Sons, Inc., is aware of a claim, the product names appear in initial capital or ALL CAPITAL LETTERS. Readers, however, should contact the appropriate companies for more complete information regarding trademarks and registration. This book is printed on acid-free paper. Copyright © 2002 by R. Allen Wyke and Andrew Watt. All rights reserved. Published by John Wiley & Sons, Inc. Published simultaneously in Canada. No part of this publication may be reproduced, stored in a retrieval system or transmitted in any form or by any means, electronic, mechanical, photocopying, recording, scanning or otherwise, except as permitted under Sections 107 or 108 of the 1976 United States Copy- right Act, without either the prior written permission of the Publisher, or authorization through payment of the appropriate per-copy fee to the Copyright Clearance Center, 222 Rosewood Drive, Danvers, MA 01923, (978) 750-8400, fax (978) 750-4744. Requests to the Publisher for permission should be addressed to the Permissions Department, John Wiley & Sons, Inc., 605 Third Avenue, New York, NY 10158-0012, (212) 850-6011, fax (212) 850- 6008, E-Mail: PERMREQ @ WILEY.COM. -

Command Injection in XML Signatures and Encryption Bradley W
Command Injection in XML Signatures and Encryption Bradley W. Hill Information Security Partners, July 12, 2007 [email protected] Abstract. The XML Digital Signature1 (XMLDSIG) and XML Encryption2 (XMLENC) standards are complex protocols for securing XML and other content. Among its complexities, the XMLDSIG standard specifies various “Transform” algorithms to identify, manipulate and canonicalize signed content and key material. Unfortunately, the defined transforms have not been rigorously constrained to prevent their use as attack vectors, and denial of service or even arbitrary code execution are probable in implementations that have not specifically guarded against such risks. Attacks against the processing application can be embedded in the KeyInfo portion of a signature, making them inherently unauthenticated, or in the SignedInfo block. Although tampering with the SignedInfo should be detectable, a defective implied order of operations in the specification may still allow unauthenticated attacks here. The ability to execute arbitrary code and perform file system operations with a malicious, invalid signature has been confirmed by the researcher in at least two independent XMLDSIG implementations, and other implementations may be similarly vulnerable. This paper describes the vulnerabilities in detail and offers advice for remediation. The most damaging attack is also likely to apply in other contexts where XSLT is accepted as input, and should be considered by all implementers of complex XML processing systems. Categories and Subject Descriptors Primary Classification: K.6.5 Security and Protection Subject: Invasive software Unauthorized access Authentication Additional Classification: D.2.3 Coding Tools and Techniques (REVISED) Subject: Standards D.2.1 Requirements/Specifications (D.3.1) Subject: Languages Tools General Terms: Security, Reliability, Verification, and Design. -

Rdfa in XHTML: Syntax and Processing Rdfa in XHTML: Syntax and Processing
RDFa in XHTML: Syntax and Processing RDFa in XHTML: Syntax and Processing RDFa in XHTML: Syntax and Processing A collection of attributes and processing rules for extending XHTML to support RDF W3C Recommendation 14 October 2008 This version: http://www.w3.org/TR/2008/REC-rdfa-syntax-20081014 Latest version: http://www.w3.org/TR/rdfa-syntax Previous version: http://www.w3.org/TR/2008/PR-rdfa-syntax-20080904 Diff from previous version: rdfa-syntax-diff.html Editors: Ben Adida, Creative Commons [email protected] Mark Birbeck, webBackplane [email protected] Shane McCarron, Applied Testing and Technology, Inc. [email protected] Steven Pemberton, CWI Please refer to the errata for this document, which may include some normative corrections. This document is also available in these non-normative formats: PostScript version, PDF version, ZIP archive, and Gzip’d TAR archive. The English version of this specification is the only normative version. Non-normative translations may also be available. Copyright © 2007-2008 W3C® (MIT, ERCIM, Keio), All Rights Reserved. W3C liability, trademark and document use rules apply. Abstract The current Web is primarily made up of an enormous number of documents that have been created using HTML. These documents contain significant amounts of structured data, which is largely unavailable to tools and applications. When publishers can express this data more completely, and when tools can read it, a new world of user functionality becomes available, letting users transfer structured data between applications and web sites, and allowing browsing applications to improve the user experience: an event on a web page can be directly imported - 1 - How to Read this Document RDFa in XHTML: Syntax and Processing into a user’s desktop calendar; a license on a document can be detected so that users can be informed of their rights automatically; a photo’s creator, camera setting information, resolution, location and topic can be published as easily as the original photo itself, enabling structured search and sharing. -

The Application of Semantic Web Technologies to Content Analysis in Sociology
THEAPPLICATIONOFSEMANTICWEBTECHNOLOGIESTO CONTENTANALYSISINSOCIOLOGY MASTER THESIS tabea tietz Matrikelnummer: 749153 Faculty of Economics and Social Science University of Potsdam Erstgutachter: Alexander Knoth, M.A. Zweitgutachter: Prof. Dr. rer. nat. Harald Sack Potsdam, August 2018 Tabea Tietz: The Application of Semantic Web Technologies to Content Analysis in Soci- ology, , © August 2018 ABSTRACT In sociology, texts are understood as social phenomena and provide means to an- alyze social reality. Throughout the years, a broad range of techniques evolved to perform such analysis, qualitative and quantitative approaches as well as com- pletely manual analyses and computer-assisted methods. The development of the World Wide Web and social media as well as technical developments like optical character recognition and automated speech recognition contributed to the enor- mous increase of text available for analysis. This also led sociologists to rely more on computer-assisted approaches for their text analysis and included statistical Natural Language Processing (NLP) techniques. A variety of techniques, tools and use cases developed, which lack an overall uniform way of standardizing these approaches. Furthermore, this problem is coupled with a lack of standards for reporting studies with regards to text analysis in sociology. Semantic Web and Linked Data provide a variety of standards to represent information and knowl- edge. Numerous applications make use of these standards, including possibilities to publish data and to perform Named Entity Linking, a specific branch of NLP. This thesis attempts to discuss the question to which extend the standards and tools provided by the Semantic Web and Linked Data community may support computer-assisted text analysis in sociology. First, these said tools and standards will be briefly introduced and then applied to the use case of constitutional texts of the Netherlands from 1884 to 2016. -

Describing Media Content of Binary Data in XML W3C Working Group Note 4 May 2005
Table of Contents Describing Media Content of Binary Data in XML W3C Working Group Note 4 May 2005 This version: http://www.w3.org/TR/2005/NOTE-xml-media-types-20050504 Latest version: http://www.w3.org/TR/xml-media-types Previous version: http://www.w3.org/TR/2005/NOTE-xml-media-types-20050502 Editors: Anish Karmarkar, Oracle Ümit Yalçınalp, SAP Copyright © 2005 W3C ® (MIT, ERCIM, Keio), All Rights Reserved. W3C liability, trademark and document use rules apply. > >Abstract This document addresses the need to indicate the content-type associated with binary element content in an XML document and the need to specify, in XML Schema, the expected content-type(s) associated with binary element content. It is expected that the additional information about the content-type will be used for optimizing the handling of binary data that is part of a Web services message. Status of this Document This section describes the status of this document at the time of its publication. Other documents may supersede this document. A list of current W3C publications and the latest revision of this technical report can be found in the W3C technical reports index at http://www.w3.org/TR/. This document is a W3C Working Group Note. This document includes the resolution of the comments received on the Last Call Working Draft previously published. The comments on this document and their resolution can be found in the Web Services Description Working Group’s issues list. There is no technical difference between this document and the 2 May 2005 version; the acknowledgement section has been updated to thank external contributors. -

The Semantic Web: the Origins of Artificial Intelligence Redux
The Semantic Web: The Origins of Artificial Intelligence Redux Harry Halpin ICCS, School of Informatics University of Edinburgh 2 Buccleuch Place Edinburgh EH8 9LW Scotland UK Fax:+44 (0) 131 650 458 E-mail:[email protected] Corresponding author is Harry Halpin. For further information please contact him. This is the tear-off page. To facilitate blind review. Title:The Semantic Web: The Origins of AI Redux working process managed to both halt the fragmentation of Submission for HPLMC-04 the Web and create accepted Web standards through its con- sensus process and its own research team. The W3C set three long-term goals for itself: universal access, Semantic Web, and a web of trust, and since its creation these three goals 1 Introduction have driven a large portion of development of the Web(W3C, 1999) The World Wide Web is considered by many to be the most significant computational phenomenon yet, although even by One comparable program is the Hilbert Program in mathe- the standards of computer science its development has been matics, which set out to prove all of mathematics follows chaotic. While the promise of artificial intelligence to give us from a finite system of axioms and that such an axiom system machines capable of genuine human-level intelligence seems is consistent(Hilbert, 1922). It was through both force of per- nearly as distant as it was during the heyday of the field, the sonality and merit as a mathematician that Hilbert was able ubiquity of the World Wide Web is unquestionable. If any- to set the research program and his challenge led many of the thing it is the Web, not artificial intelligence as traditionally greatest mathematical minds to work. -

XML Information Set
XML Information Set XML Information Set W3C Recommendation 24 October 2001 This version: http://www.w3.org/TR/2001/REC-xml-infoset-20011024 Latest version: http://www.w3.org/TR/xml-infoset Previous version: http://www.w3.org/TR/2001/PR-xml-infoset-20010810 Editors: John Cowan, [email protected] Richard Tobin, [email protected] Copyright ©1999, 2000, 2001 W3C® (MIT, INRIA, Keio), All Rights Reserved. W3C liability, trademark, document use and software licensing rules apply. Abstract This specification provides a set of definitions for use in other specifications that need to refer to the information in an XML document. Status of this Document This section describes the status of this document at the time of its publication. Other documents may supersede this document. The latest status of this document series is maintained at the W3C. This is the W3C Recommendation of the XML Information Set. This document has been reviewed by W3C Members and other interested parties and has been endorsed by the Director as a W3C Recommendation. It is a stable document and may be used as reference material or cited as a normative reference from another document. W3C's role in making the Recommendation is to draw attention to the specification and to promote its widespread deployment. This enhances the functionality and interoperability of the file:///C|/Documents%20and%20Settings/immdca01/Desktop/xml-infoset.html (1 of 16) [8/12/2002 10:38:58 AM] XML Information Set Web. This document has been produced by the W3C XML Core Working Group as part of the XML Activity in the W3C Architecture Domain. -
5241 Index 0939-0964.Qxd 29/08/02 5.30 Pm Page 941
5241_index_0939-0964.qxd 29/08/02 5.30 pm Page 941 INDEX 941 5241_index_0939-0964.qxd 29/08/02 5.30 pm Page 942 Index 942 Regular A Alternatives, 362 Analysis Patterns: Reusable Expression ABSENT value, 67 Object Models, 521 Symbols abstract attribute, 62, 64–66 ancestor (XPath axis), 54 of complexType element, ancestor-or-self (XPath axis), . escape character, 368, 369 247–248, 512, 719 54 . metacharacter, 361 of element element, 148–149 Annotation, 82 ? metacharacter, 361, 375 mapping to object-oriented defined, 390 ( metacharacter, 361 language, 513–514 mapping to object-oriented ) metacharacter, 361 Abstract language, 521 { metacharacter, 361 attribute type, 934 Microsoft use of term, } metacharacter, 361 defined, 58 821–822 + metacharacter, 361, 375 element type, 16, 17, 18, 934 properties of, 411 * metacharacter, 361, 375 object, corresponding to docu- annotation content option ^ metacharacter, 379 ment, 14 for schema element, 115 \ metacharacter, 361 uses of term, 238, 931–932 annotation element, 82, 83, | metacharacter, 361 Abstract character, 67 254, 260, 722, 859 \. escape character, 366 Abstract document attributes of, 118 \? escape character, 366 document information item content options for, 118–119 \( escape character, 367 view of, 62 example of use of, 117 \) escape character, 367 infoset view of, 62 function of, 116, 124, 128 \{ escape character, 367 makeup of, 59 nested, 83–84 \} escape character, 367 properties of, 66 Anonymous component, 82 \+ escape character, 367 Abstract element, 14–15 any element, 859 \- escape character, -

Exploiting Semantic Web Knowledge Graphs in Data Mining
Exploiting Semantic Web Knowledge Graphs in Data Mining Inauguraldissertation zur Erlangung des akademischen Grades eines Doktors der Naturwissenschaften der Universit¨atMannheim presented by Petar Ristoski Mannheim, 2017 ii Dekan: Dr. Bernd Lübcke, Universität Mannheim Referent: Professor Dr. Heiko Paulheim, Universität Mannheim Korreferent: Professor Dr. Simone Paolo Ponzetto, Universität Mannheim Tag der mündlichen Prüfung: 15 Januar 2018 Abstract Data Mining and Knowledge Discovery in Databases (KDD) is a research field concerned with deriving higher-level insights from data. The tasks performed in that field are knowledge intensive and can often benefit from using additional knowledge from various sources. Therefore, many approaches have been proposed in this area that combine Semantic Web data with the data mining and knowledge discovery process. Semantic Web knowledge graphs are a backbone of many in- formation systems that require access to structured knowledge. Such knowledge graphs contain factual knowledge about real word entities and the relations be- tween them, which can be utilized in various natural language processing, infor- mation retrieval, and any data mining applications. Following the principles of the Semantic Web, Semantic Web knowledge graphs are publicly available as Linked Open Data. Linked Open Data is an open, interlinked collection of datasets in machine-interpretable form, covering most of the real world domains. In this thesis, we investigate the hypothesis if Semantic Web knowledge graphs can be exploited as background knowledge in different steps of the knowledge discovery process, and different data mining tasks. More precisely, we aim to show that Semantic Web knowledge graphs can be utilized for generating valuable data mining features that can be used in various data mining tasks.