Banking at the Crossroads Essays on Machine Learning / Applied Data Analytics, Asset Encumbrance / Bail-In, Sustainability and Resource Availability
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Elliott Wave Principle
THE BASICS OF THE ELLIOTT WAVE PRINCIPLE by Robert R. Prechter, Jr. Published by NEW CLASSICS LIBRARY a division of Post Office Box 1618, Gainesville, GA 30503 USA 800-336-1618 or 770-536-0309 or fax 770-536-2514 THE BASICS OF THE ELLIOTT WAVE PRINCIPLE Copyright © 1995-2004 by Robert R. Prechter, Jr. Printed in the United States of America First Edition: August 1995 Second Edition: February 1996 Third Edition: April 2000 Fourth Edition: June 2004 August 2007 For information, address the publishers: New Classics Library a division of Elliott Wave International Post Office Box 1618 Gainesville, Georgia 30503 USA All rights reserved. The material in this volume may not be reprinted or reproduced in any manner whatsoever. Violators will be prosecuted to the fullest extent of the law. Cover design: Marc Benejan Production: Pamela Greenwood ISBN: 0-932750-63-X CONTENTS 7 The Basics 7 The Five Wave Pattern 8 Wave Mode 10 The Essential Design 11 Variations on the Basic Theme 12 Wave Degree 14 Motive Waves 14 Impulse 16 Extension 17 Truncation 18 Diagonal Triangles (Wedges) 19 Corrective Waves 19 Zigzags (5-3-5) 21 Flats (3-3-5) 22 Horizontal Triangles (Triangles) 24 Combinations (Double and Triple Threes) 26 Guidelines of Wave Formation 26 Alternation 26 Depth of Corrective Waves 27 Channeling Technique 28 Volume 29 Learning the Basics 32 The Fibonacci Sequence and its Application 35 Ratio Analysis 35 Retracements 36 Motive Wave Multiples 37 Corrective Wave Multiples 40 Perspective 41 Glossary FOREWORD By understanding the Wave Principle, you can antici- pate large and small shifts in the psychology driving any investment market and help yourself minimize the emo- tions that drive your own investment decisions. -

New Elliott Wave Principle
History The Elliott Wave Theory is named after Ralph Nelson Elliott. In the 1930s, Ralph Nelson Elliott found that the markets exhibited certain repeated patterns. His primary research was with stock market data for the Dow Jones Industrial Average. This research identified patterns or waves that recur in the markets. Very simply, in the direction of the trend, expect five waves. Any corrections against the trend are in three waves. Three wave corrections are lettered as "a, b, c." These patterns can be seen in long-term as well as in short-term charts. In Elliott's model, market prices alternate between an impulsive, or motive phase, and a corrective phase on all time scales of trend, as the illustration shows. Impulses are always subdivided into a set of 5 lower-degree waves, alternating again between motive and corrective character, so that waves 1, 3, and 5 are impulses, and waves 2 and 4 are smaller retraces of waves 1 and 3. Corrective waves subdivide into 3 smaller-degree waves. In a bear market the dominant trend is downward, so the pattern is reversed—five waves down and three up. Motive waves always move with the trend, while corrective waves move against it and hence called corrective waves. Ideally, smaller patterns can be identified within bigger patterns. In this sense, Elliott Waves are like a piece of broccoli, where the smaller piece, if broken off from the bigger piece, does, in fact, look like the big piece. This information (about smaller patterns fitting into bigger patterns), coupled with the Fibonacci relationships between the waves, offers the trader a level of anticipation and/or prediction when searching for and identifying trading opportunities with solid reward/risk ratios. -

Lesson 12 Technical Analysis
Lesson 12 Technical Analysis Instructor: Rick Phillips 702-575-6666 [email protected] Course Description and Learning Objectives Course Description Learn what technical analysis entails and the various ways to analyze the markets using this type of analysis Lessons and Learning Objectives ▪ Define technical analysis ▪ Explore the history of technical analysis ▪ Examine the accuracy of technical analysis ▪ Compare technical analysis to fundamental analysis ▪ Outline different types of technical studies ▪ Study tools and systems which provide technical analysis 2 What is Technical Analysis Short Description: Using the past to predict the future Long Description: A way to analyze securities price patterns, movements, and trends to extrapolate the ranges of potential future prices 3 History of Technical Analysis The principles of technical analysis are derived from hundreds of years of financial market data. Some aspects of technical analysis began to appear in Amsterdam-based merchant Joseph de la Vega's accounts of the Dutch financial markets in the 17th century. In Asia, technical analysis is said to be a method developed by Homma Munehisa during the early 18th century which evolved into the use of candlestick techniques, and is today a technical analysis charting tool. In the 1920s and 1930s, Richard W. Schabacker published several books which continued the work of Charles Dow and William Peter Hamilton in their books Stock Market Theory and Practice and Technical Market Analysis. In 1948, Robert D. Edwards and John Magee published Technical Analysis of Stock Trends which is widely considered to be one of the seminal works of the discipline. It is exclusively concerned with trend analysis and chart patterns and remains in use to the present. -

Harmonic Conditions How to Define Price and Time Cycles
Interview: Tim Hayes – A Class of its Own Your Personal Trading Coach Issue 03, April 2010 | www.traders-mag.com | www.tradersonline-mag.com Harmonic Conditions How to Define Price and Time Cycles Great Profi ts through When to Trade The Right Use of Failed Chart Patterns & When to Fade Cyclical Analysis We Show You How to Recognise Them Gaining an Edge in Forex Trading Timing Is Everything for Lasting Success TRADERS´EDITORIAL Harmonising Price with Time Harmonising price with time is one of the issues serious traders grapple with at one point in their careers. And how could this possibly be otherwise? After all, if you wish to predict the future you have to consider the past. And if you look back on the history of trading, you will automatically end up coming across some of the heroes who have written this history. Jesse Livermore is one of them, so is Ralph Nelson Elliott and, last but not least, William D. Gann. Among all the greats of the trade he certainly stands out as the enigma. Square of Nine, Gann Lines and Gann Angles, the law of vibration of the sphere of activity, i.e. the rate of internal vibration all of which you will come The harmony of price and time results in incredible forecasts across once you begin to study the trading hero. Gann’s forecasts are credited with 90% success rates and his trading results are said to have amounted to 50 million dollars. Considering that he lived from1878 to 1955, it is easy to imagine what an incredible fortune this would be today. -

The Titans of Technical Analysis by David Penn REAL WORLD
Stocks & Commodities V. 20:10 (32-38): The Titans Of Technical Analysis by David Penn REAL WORLD A Celebration Of Technical Analysts From Dow To Zweig The Titans Of Technical Analysis A not-so-random walk through the history of charting the observations, and commentary on the subjects of trading markets. and technical analysis. From our earliest issues featuring reviews titled “An Easy Course In Using The HP-12C And by David Penn Other Financial Calculators” to the present issue, which includes pages of Traders’ Tips in sophisticated computer any years ago, a poet friend who was editing language, no other publication has had its finger on the pulse a collection of contemporary verse noted to of both applied and theoretical technical analysis for as long me that “about half the working poets in as STOCKS & COMMODITIES. And this has been no mere M America are going to be really upset about minding the store. this anthology. Of course, the other half of them are in the S&C publisher Jack Hutson introduced the TRIX, or triple book. …” exponential smoothing oscillator, in 1983. The Richard Such sentiments came to mind when I embarked upon the Wyckoff method was reintroduced to the world via these task of highlighting the few among the many whose contri- pages in 1986. John Bollinger, Jack Schwager, and Vic butions to the field of technical analysis have made them Sperandeo were all among S&C’s interviews in 1993. In the what STOCKS & COMMODITIES has designated the “Titans nine-odd years since then, as a bull market in equities resumed, Of Technical Analysis.” S&C was on hand to provide technical tools for minimizing How subjective is such a list? In some ways, all too risk and maximizing gain — whether through new indicators subjective — particularly with those whose contributions (such as John Ehlers’ MESA adaptive moving averages), new are more recent or are less widely enjoyed. -

Technical Analysis
ptg TECHNICAL ANALYSIS ptg Download at www.wowebook.com This page intentionally left blank ptg Download at www.wowebook.com TECHNICAL ANALYSIS THE COMPLETE RESOURCE FOR FINANCIAL MARKET TECHNICIANS SECOND EDITION ptg Charles D. Kirkpatrick II, CMT Julie Dahlquist, Ph.D., CMT Download at www.wowebook.com Vice President, Publisher: Tim Moore Associate Publisher and Director of Marketing: Amy Neidlinger Executive Editor: Jim Boyd Editorial Assistant: Pamela Boland Operations Manager: Gina Kanouse Senior Marketing Manager: Julie Phifer Publicity Manager: Laura Czaja Assistant Marketing Manager: Megan Colvin Cover Designer: Chuti Prasertsith Managing Editor: Kristy Hart Project Editor: Betsy Harris Copy Editor: Karen Annett Proofreader: Kathy Ruiz Indexer: Erika Millen Compositor: Bronkella Publishing Manufacturing Buyer: Dan Uhrig © 2011 by Pearson Education, Inc. Publishing as FT Press Upper Saddle River, New Jersey 07458 FT Press offers excellent discounts on this book when ordered in quantity for bulk purchases or special sales. For more information, please contact U.S. Corporate and Government Sales, 1-800-382-3419, [email protected]. For sales outside the U.S., please contact International Sales at [email protected]. ptg Company and product names mentioned herein are the trademarks or registered trademarks of their respective owners. All rights reserved. No part of this book may be reproduced, in any form or by any means, without permission in writing from the publisher. Printed in the United States of America First Printing November 2010 ISBN-10: 0-13-705944-2 ISBN-13: 978-0-13-705944-7 Pearson Education LTD. Pearson Education Australia PTY, Limited. Pearson Education Singapore, Pte. Ltd. Pearson Education Asia, Ltd. -
Elliott Wave Principle.Pdf.Pdf
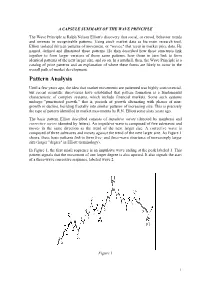
A CAPSULE SUMMARY OF THE WAVE PRINCIPLE The Wave Principle is Ralph Nelson Elliott's discovery that social, or crowd, behavior trends and reverses in recognizable patterns. Using stock market data as his main research tool, Elliott isolated thirteen patterns of movement, or "waves," that recur in market price data. He named, defined and illustrated those patterns. He then described how these structures link together to form larger versions of those same patterns, how those in turn link to form identical patterns of the next larger size, and so on. In a nutshell, then, the Wave Principle is a catalog of price patterns and an explanation of where these forms are likely to occur in the overall path of market development. Pattern Analysis Until a few years ago, the idea that market movements are patterned was highly controversial, but recent scientific discoveries have established that pattern formation is a fundamental characteristic of complex systems, which include financial markets. Some such systems undergo "punctuated growth," that is, periods of growth alternating with phases of non- growth or decline, building fractally into similar patterns of increasing size. This is precisely the type of pattern identified in market movements by R.N. Elliott some sixty years ago. The basic pattern Elliott described consists of impulsive waves (denoted by numbers) and corrective waves (denoted by letters). An impulsive wave is composed of five subwaves and moves in the same direction as the trend of the next larger size. A corrective wave is composed of three subwaves and moves against the trend of the next larger size. -

Basics of Elliott Wave Theory –
Basics of Elliott Wave Theory – Learn the Essentials In this article we will first cover the Elliott wave basics and structure. The goal of this article is to help you learn Elliott wave theory and give you the foundation to further explore and test the theory. Next, we will take a look at how to apply the theory to day trading. Elliott wave theory is based on the premise that markets form repetitive patterns or cycles. Ralph Nelson Elliott developed the Elliott wave concept of trading in the late 1920’s. The theory proposed an alternative view to the notion that markets are random. Based on this theory, investors could anticipate and predict potential cycles in the market. The most challenging part of Elliott wave analysis is that it’s highly subjective. Where you may see the next bear market starting, another trader will see a double bottom setting in before a massive wave one. This need to quickly assess the pattern in complex markets is what makes the theory so challenging to master. Dow Theory and Elliott Wave The Elliott wave analysis also draws upon the Dow theory. The Dow theory, postulated by Charles Dow also states price moves in waves. Charles Dow called these waves trends. There is a strong influence of the Dow Theory of trends which in Elliott wave trading terminology are nothing more than various degrees of trends. Elliott wave theory goes into great detail regarding the study of the fractal nature of the markets. Now that we have tackled a brief overview, let’s dig into the principles of the theory and key retracement levels which categorize the waves. -

A Study to Understand Elliott Wave Principle
International Journal of Engineering Research and General Science Volume 4, Issue 4, July-August, 2016 ISSN 2091-2730 A STUDY TO UNDERSTAND ELLIOTT WAVE PRINCIPLE Mr. Suresh A.S1 Assistant Professor, MBA Department, PES Institute of Technology, Bangalore South Campus, 1km Before Electronic city, Hosur Road, Bangalore – 560100 Phone: 96861-95506 Email: [email protected], [email protected] Dr. S Naveen Prasath2 Assistant Professor, MBA Department, PES Institute of Technology, Bangalore South Campus, 1km Before Electronic city, Hosur Road, Bangalore – 560100 Email: [email protected] ABSTRACT- The Elliott Wave Principle states that markets move in natural patterns according to changing investor psychology and price momentum. Specifically, crowd psychology will move from optimism to pessimism, and back up again, making it possible to forecast the progression of certain market trends. "The Wave Principle" is Ralph Nelson Elliott's discovery that social, or crowd, behavior trends and reverses in recognizable patterns. The Wave Principle is not primarily a forecasting tool; it is a detailed description of how markets behave. Many areas of mass human activity follow the Wave Principle, but the stock market is where it is most popularly applied. Indeed, the stock market considered alone is far more important than it seems to casual observers. According to the Elliott Wave theory, market move in the five distinct waves existing on the upside and the three distinct waves existing on the downside. The upwards waves that lie in the bull move are termed as Impulse waves and the other three waves that are against the trend direction are termed as Corrective waves. -

Elliott's Wave Theory in the Field of Econophysics and Its Application to the Psi20 in the Context of Crisis
E STUDIOS DE E C O N O M Í A A PLICADA V OL . 37-2 2019. P ÁGS . 41-53 ELLIOTT'S WAVE THEORY IN THE FIELD OF ECONOPHYSICS AND ITS APPLICATION TO THE PSI20 IN THE CONTEXT OF CRISIS SANDRA CRISTINA ANTUNES RIBEIRO OBSERVARE – Observatório de Relações Exteriores, Universidade Autónoma de Lisboa ISCAL- Instituto Superior de Contabilidade e Administração de Lisboa PORTUGAL E-mail: [email protected] ABSTRACT In the last decades and in the scope of the economic sciences, new interdisciplinary forms have been developed, of which Econophysics stands out. It uses theoretical bases of physics and of statistical physics for the explanation of economic phenomena, particularly financial phenomena. This work shows, through statistical physics, possible forms of chart analysis of a stock exchange index, through the practical application of Elliott’s Wave Theory to the movement of the Portuguese stock index, the PSI20. With the empirical application made to the PSI20, we emphasize the degree of reliability that the Elliott method has demonstrated when applied to large indexes, generating projection scenarios based on patterns of repetitive cyclic behaviour. It is possible, and for several moments, to identify the Elliott wave pattern, namely in the crisis period. Keywords: Econophysical, Technical Analysis, Elliott’s Wave Theory, Portuguese stock market. La teoría de las ondas de Elliott en el campo de la econofísica y su aplicación a la PSI20 en el contexto de la crisis RESUMEN En las últimas décadas y en el ámbito de las ciencias económicas, se han desarrollado nuevas formas interdisciplinares, de las cuales se destaca la Econofísica. -

Technical Analysis
ptg TECHNICAL ANALYSIS ptg www.rasabourse.com This page intentionally left blank ptg www.rasabourse.com Download at www.wowebook.com TECHNICAL ANALYSIS THE COMPLETE RESOURCE FOR FINANCIAL MARKET TECHNICIANS SECOND EDITION ptg Charles D. Kirkpatrick II, CMT Julie Dahlquist, Ph.D., CMT www.rasabourse.com Download at www.wowebook.com Vice President, Publisher: Tim Moore Associate Publisher and Director of Marketing: Amy Neidlinger Executive Editor: Jim Boyd Editorial Assistant: Pamela Boland Operations Manager: Gina Kanouse Senior Marketing Manager: Julie Phifer Publicity Manager: Laura Czaja Assistant Marketing Manager: Megan Colvin Cover Designer: Chuti Prasertsith Managing Editor: Kristy Hart Project Editor: Betsy Harris Copy Editor: Karen Annett Proofreader: Kathy Ruiz Indexer: Erika Millen Compositor: Bronkella Publishing Manufacturing Buyer: Dan Uhrig © 2011 by Pearson Education, Inc. Publishing as FT Press Upper Saddle River, New Jersey 07458 FT Press offers excellent discounts on this book when ordered in quantity for bulk purchases or special sales. For more information, please contact U.S. Corporate and Government Sales, 1-800-382-3419, [email protected]. For sales outside the U.S., please contact International Sales at [email protected]. ptg Company and product names mentioned herein are the trademarks or registered trademarks of their respective owners. All rights reserved. No part of this book may be reproduced, in any form or by any means, without permission in writing from the publisher. Printed in the United States of America First Printing November 2010 ISBN-10: 0-13-705944-2 ISBN-13: 978-0-13-705944-7 Pearson Education LTD. Pearson Education Australia PTY, Limited. Pearson Education Singapore, Pte. -

President's Report to Colleagues
IFTAUPDATE 2013 Volume 20 Issue 4 page 1 a newsletter for the colleagues of the International Federation of Technical Analysts IFTA UPDATE is a publication of the International 2013 Volume 20 Issue 4 Federation of Technical Analysts, Inc. (www.ifta.org), a not-for-profit professional IN THIS ISSUE organization incorporated in 1986. International Federation of Technical Analysts 1 President’s Report to Colleagues President’s Report to Colleagues 9707 Key West Avenue, Suite 100 Rockville, MD 20850 USA 2 Congratulations New CFTes! Dear IFTA Colleagues, Email: [email protected] • Phone: +1 240-404-6508 3 Save the Dates! 5 Calendar At-A-Glance I am happy to report that the IFTA confer- about nautical miles, tetrahedral latitude, I wish them a very successful three-year 8 The State of Global Technical ence in San Francisco was a success! We and the orbital angle. I also learned a lot term. As well, we bid farewell to Saleh Analysis had more attendees than in past years from Howard Bandy’s presentation about Nasser and David Furcagj, who retired 13 Defining Requirements for an and the presentations were fascinating. system development. And of course, I from the IFTA board. We thank them for Algorithmic Trading System Plus, San Francisco is a lovely place for a will never forget the performance by Ed their commitment in the past years and 16 Arms Candlevolume conference. I want to thank our host, the Seykota, as I have never seen a financial their contributions for the federation. 19 An Unexpected Encounter of the Third Kind… Technical Security Analysts Association of presentation where the speaker sings his We are grateful that both of them will San Francisco (TSAASF), and our former main messages accompanied by his banjo.