Nutritional Systems Biology
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Supplemental Information to Mammadova-Bach Et Al., “Laminin Α1 Orchestrates VEGFA Functions in the Ecosystem of Colorectal Carcinogenesis”
Supplemental information to Mammadova-Bach et al., “Laminin α1 orchestrates VEGFA functions in the ecosystem of colorectal carcinogenesis” Supplemental material and methods Cloning of the villin-LMα1 vector The plasmid pBS-villin-promoter containing the 3.5 Kb of the murine villin promoter, the first non coding exon, 5.5 kb of the first intron and 15 nucleotides of the second villin exon, was generated by S. Robine (Institut Curie, Paris, France). The EcoRI site in the multi cloning site was destroyed by fill in ligation with T4 polymerase according to the manufacturer`s instructions (New England Biolabs, Ozyme, Saint Quentin en Yvelines, France). Site directed mutagenesis (GeneEditor in vitro Site-Directed Mutagenesis system, Promega, Charbonnières-les-Bains, France) was then used to introduce a BsiWI site before the start codon of the villin coding sequence using the 5’ phosphorylated primer: 5’CCTTCTCCTCTAGGCTCGCGTACGATGACGTCGGACTTGCGG3’. A double strand annealed oligonucleotide, 5’GGCCGGACGCGTGAATTCGTCGACGC3’ and 5’GGCCGCGTCGACGAATTCACGC GTCC3’ containing restriction site for MluI, EcoRI and SalI were inserted in the NotI site (present in the multi cloning site), generating the plasmid pBS-villin-promoter-MES. The SV40 polyA region of the pEGFP plasmid (Clontech, Ozyme, Saint Quentin Yvelines, France) was amplified by PCR using primers 5’GGCGCCTCTAGATCATAATCAGCCATA3’ and 5’GGCGCCCTTAAGATACATTGATGAGTT3’ before subcloning into the pGEMTeasy vector (Promega, Charbonnières-les-Bains, France). After EcoRI digestion, the SV40 polyA fragment was purified with the NucleoSpin Extract II kit (Machery-Nagel, Hoerdt, France) and then subcloned into the EcoRI site of the plasmid pBS-villin-promoter-MES. Site directed mutagenesis was used to introduce a BsiWI site (5’ phosphorylated AGCGCAGGGAGCGGCGGCCGTACGATGCGCGGCAGCGGCACG3’) before the initiation codon and a MluI site (5’ phosphorylated 1 CCCGGGCCTGAGCCCTAAACGCGTGCCAGCCTCTGCCCTTGG3’) after the stop codon in the full length cDNA coding for the mouse LMα1 in the pCIS vector (kindly provided by P. -

Association Analyses of Known Genetic Variants with Gene
ASSOCIATION ANALYSES OF KNOWN GENETIC VARIANTS WITH GENE EXPRESSION IN BRAIN by Viktoriya Strumba A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy (Bioinformatics) in The University of Michigan 2009 Doctoral Committee: Professor Margit Burmeister, Chair Professor Huda Akil Professor Brian D. Athey Assistant Professor Zhaohui S. Qin Research Statistician Thomas Blackwell To Sam and Valentina Dmitriy and Elizabeth ii ACKNOWLEDGEMENTS I would like to thank my advisor Professor Margit Burmeister, who tirelessly guided me though seemingly impassable corridors of graduate work. Throughout my thesis writing period she provided sound advice, encouragement and inspiration. Leading by example, her enthusiasm and dedication have been instrumental in my path to becoming a better scientist. I also would like to thank my co-advisor Tom Blackwell. His careful prodding always kept me on my toes and looking for answers, which taught me the depth of careful statistical analysis. His diligence and dedication have been irreplaceable in most difficult of projects. I also would like to thank my other committee members: Huda Akil, Brian Athey and Steve Qin as well as David States. You did not make it easy for me, but I thank you for believing and not giving up. Huda’s eloquence in every subject matter she explained have been particularly inspiring, while both Huda’s and Brian’s valuable advice made the completion of this dissertation possible. I would also like to thank all the members of the Burmeister lab, both past and present: Sandra Villafuerte, Kristine Ito, Cindy Schoen, Karen Majczenko, Ellen Schmidt, Randi Burns, Gang Su, Nan Xiang and Ana Progovac. -

Table 2. Significant
Table 2. Significant (Q < 0.05 and |d | > 0.5) transcripts from the meta-analysis Gene Chr Mb Gene Name Affy ProbeSet cDNA_IDs d HAP/LAP d HAP/LAP d d IS Average d Ztest P values Q-value Symbol ID (study #5) 1 2 STS B2m 2 122 beta-2 microglobulin 1452428_a_at AI848245 1.75334941 4 3.2 4 3.2316485 1.07398E-09 5.69E-08 Man2b1 8 84.4 mannosidase 2, alpha B1 1416340_a_at H4049B01 3.75722111 3.87309653 2.1 1.6 2.84852656 5.32443E-07 1.58E-05 1110032A03Rik 9 50.9 RIKEN cDNA 1110032A03 gene 1417211_a_at H4035E05 4 1.66015788 4 1.7 2.82772795 2.94266E-05 0.000527 NA 9 48.5 --- 1456111_at 3.43701477 1.85785922 4 2 2.8237185 9.97969E-08 3.48E-06 Scn4b 9 45.3 Sodium channel, type IV, beta 1434008_at AI844796 3.79536664 1.63774235 3.3 2.3 2.75319499 1.48057E-08 6.21E-07 polypeptide Gadd45gip1 8 84.1 RIKEN cDNA 2310040G17 gene 1417619_at 4 3.38875643 1.4 2 2.69163229 8.84279E-06 0.0001904 BC056474 15 12.1 Mus musculus cDNA clone 1424117_at H3030A06 3.95752801 2.42838452 1.9 2.2 2.62132809 1.3344E-08 5.66E-07 MGC:67360 IMAGE:6823629, complete cds NA 4 153 guanine nucleotide binding protein, 1454696_at -3.46081884 -4 -1.3 -1.6 -2.6026947 8.58458E-05 0.0012617 beta 1 Gnb1 4 153 guanine nucleotide binding protein, 1417432_a_at H3094D02 -3.13334396 -4 -1.6 -1.7 -2.5946297 1.04542E-05 0.0002202 beta 1 Gadd45gip1 8 84.1 RAD23a homolog (S. -

P-Glycoprotein-Mediated Chemoresistance Is Reversed by Carbonic Anhydrase XII Inhibitors
www.impactjournals.com/oncotarget/ Oncotarget, Advance Publications 2016 P-glycoprotein-mediated chemoresistance is reversed by carbonic anhydrase XII inhibitors Joanna Kopecka1, Gregory M. Rankin2, Iris C. Salaroglio1, Sally-Ann Poulsen2,*, Chiara Riganti1,* 1Department of Oncology, University of Torino, 10126 Torino, Italy 2Eskitis Institute for Drug Discovery, Griffith University, Brisbane, Nathan, Queensland, 4111, Australia *These authors contributed equally to this work Correspondence to: Sally-Ann Poulsen, email: [email protected] Chiara Riganti, email: [email protected] Keywords: carbonic anhydrase XII, P-glycoprotein, doxorubicin, chemoresistance, intracellular pH Received: August 26, 2016 Accepted: October 28, 2016 Published: November 03, 2016 ABSTRACT Carbonic anhydrase XII (CAXII) is a membrane enzyme that maintains pH homeostasis and sustains optimum P-glycoprotein (Pgp) efflux activity in cancer cells. Here, we investigated a panel of eight CAXII inhibitors (compounds 1–8), for their potential to reverse Pgp mediated tumor cell chemoresistance. Inhibitors (5 nM) were screened in human and murine cancer cells (colon, lung, breast, bone) with different expression levels of CAXII and Pgp. We identified three CAXII inhibitors (compounds 1, 2 and 4) that significantly (≥ 2 fold) increased the intracellular retention of the Pgp-substrate and chemotherapeutic doxorubicin, and restored its cytotoxic activity. The inhibitors lowered intracellular pH to indirectly impair Pgp activity. Ca12-knockout assays confirmed that the chemosensitizing property of the compounds was dependent on active CAXII. Furthermore, in a preclinical model of drug-resistant breast tumors compound 1 (1900 ng/kg) restored the efficacy of doxorubicin to the same extent as the direct Pgp inhibitor tariquidar. The expression of carbonic anhydrase IX had no effect on the intracellular doxorubicin accumulation. -

High-Throughput Screening Studies of Inhibition of Human Carbonic Anhydrase II and Bacterial Flagella Antimicrobial Activity
Western Michigan University ScholarWorks at WMU Dissertations Graduate College 5-2010 High-Throughput Screening Studies of Inhibition of Human Carbonic Anhydrase II and Bacterial Flagella Antimicrobial Activity Albert A. Barrese III Western Michigan University Follow this and additional works at: https://scholarworks.wmich.edu/dissertations Part of the Biochemistry, Biophysics, and Structural Biology Commons, and the Biology Commons Recommended Citation Barrese, Albert A. III, "High-Throughput Screening Studies of Inhibition of Human Carbonic Anhydrase II and Bacterial Flagella Antimicrobial Activity" (2010). Dissertations. 500. https://scholarworks.wmich.edu/dissertations/500 This Dissertation-Open Access is brought to you for free and open access by the Graduate College at ScholarWorks at WMU. It has been accepted for inclusion in Dissertations by an authorized administrator of ScholarWorks at WMU. For more information, please contact [email protected]. HIGH-THROUGHPUT SCREENING STUDIES OF INHIBITION OF HUMAN CARBONIC ANHYDRASE II AND BACTERIAL FLAGELLA ANTIMICROBIAL ACTIVITY by Albert A. Barrese III A Dissertation Submitted to the Faculty of The Graduate College in partial fulfillment of the requirements for the Degree of Doctor of Philosophy Department of Biological Sciences Advisor: Brian C. Tripp, Ph.D. Western Michigan University Kalamazoo, Michigan May 2010 UMI Number: 3410393 All rights reserved INFORMATION TO ALL USERS The quality of this reproduction is dependent upon the quality of the copy submitted. In the unlikely event that the author did not send a complete manuscript and there are missing pages, these will be noted. Also, if material had to be removed, a note will indicate the deletion. UMT Dissertation Publishing UMI 3410393 Copyright 2010 by ProQuest LLC. -
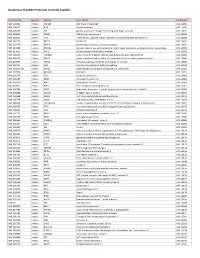
Quantigene Flowrna Probe Sets Currently Available
QuantiGene FlowRNA Probe Sets Currently Available Accession No. Species Symbol Gene Name Catalog No. NM_003452 Human ZNF189 zinc finger protein 189 VA1-10009 NM_000057 Human BLM Bloom syndrome VA1-10010 NM_005269 Human GLI glioma-associated oncogene homolog (zinc finger protein) VA1-10011 NM_002614 Human PDZK1 PDZ domain containing 1 VA1-10015 NM_003225 Human TFF1 Trefoil factor 1 (breast cancer, estrogen-inducible sequence expressed in) VA1-10016 NM_002276 Human KRT19 keratin 19 VA1-10022 NM_002659 Human PLAUR plasminogen activator, urokinase receptor VA1-10025 NM_017669 Human ERCC6L excision repair cross-complementing rodent repair deficiency, complementation group 6-like VA1-10029 NM_017699 Human SIDT1 SID1 transmembrane family, member 1 VA1-10032 NM_000077 Human CDKN2A cyclin-dependent kinase inhibitor 2A (melanoma, p16, inhibits CDK4) VA1-10040 NM_003150 Human STAT3 signal transducer and activator of transcripton 3 (acute-phase response factor) VA1-10046 NM_004707 Human ATG12 ATG12 autophagy related 12 homolog (S. cerevisiae) VA1-10047 NM_000737 Human CGB chorionic gonadotropin, beta polypeptide VA1-10048 NM_001017420 Human ESCO2 establishment of cohesion 1 homolog 2 (S. cerevisiae) VA1-10050 NM_197978 Human HEMGN hemogen VA1-10051 NM_001738 Human CA1 Carbonic anhydrase I VA1-10052 NM_000184 Human HBG2 Hemoglobin, gamma G VA1-10053 NM_005330 Human HBE1 Hemoglobin, epsilon 1 VA1-10054 NR_003367 Human PVT1 Pvt1 oncogene homolog (mouse) VA1-10061 NM_000454 Human SOD1 Superoxide dismutase 1, soluble (amyotrophic lateral sclerosis 1 (adult)) -

An Update on the Metabolic Roles of Carbonic Anhydrases in the Model Alga Chlamydomonas Reinhardtii
H OH metabolites OH Review An Update on the Metabolic Roles of Carbonic Anhydrases in the Model Alga Chlamydomonas reinhardtii Ashok Aspatwar 1,* ID , Susanna Haapanen 1 and Seppo Parkkila 1,2 1 Faculty of Medicine and Life Sciences, University of Tampere, FI-33014 Tampere, Finland; [email protected].fi (S.H.); [email protected].fi (S.P.) 2 Fimlab, Ltd., and Tampere University Hospital, FI-33520 Tampere, Finland * Correspondence: [email protected].fi; Tel.: +358-46-596-2117 Received: 11 January 2018; Accepted: 10 March 2018; Published: 13 March 2018 Abstract: Carbonic anhydrases (CAs) are metalloenzymes that are omnipresent in nature. − + CAs catalyze the basic reaction of the reversible hydration of CO2 to HCO3 and H in all living organisms. Photosynthetic organisms contain six evolutionarily different classes of CAs, which are namely: α-CAs, β-CAs, γ-CAs, δ-CAs, ζ-CAs, and θ-CAs. Many of the photosynthetic organisms contain multiple isoforms of each CA family. The model alga Chlamydomonas reinhardtii contains 15 CAs belonging to three different CA gene families. Of these 15 CAs, three belong to the α-CA gene family; nine belong to the β-CA gene family; and three belong to the γ-CA gene family. The multiple copies of the CAs in each gene family may be due to gene duplications within the particular CA gene family. The CAs of Chlamydomonas reinhardtii are localized in different subcellular compartments of this unicellular alga. The presence of a large number of CAs and their diverse subcellular localization within a single cell suggests the importance of these enzymes in the metabolic and biochemical roles they perform in this unicellular alga. -

Table S1. Detailed Clinical Features of Individuals with IDDCA and LADCI Syndromes
BMJ Publishing Group Limited (BMJ) disclaims all liability and responsibility arising from any reliance Supplemental material placed on this supplemental material which has been supplied by the author(s) J Med Genet Table S1. Detailed clinical features of individuals with IDDCA and LADCI syndromes Lodder E., De Nittis P., Koopman C. et al., 2016 Family A Family B Family C Family D Family E Family F Individual 1 2 3 4 5 6 7 8 9 Gender, Age (years) F, 22 F, 20 F, 6 F, 11 M, 9 F, 12 F, 13 M, 8 M, 23 c.249G>A,r.249_250 c.249G>A,r.249_250 Nucleotide change c.249+1G>T/ c.249+3G>T/ c.249+3G>T/ c.906C>G/ c.242C>T/ c.242C>T/ c.242C>T/ ins249+1_249+25/ ins249+1_249+25/ (NM_006578.3) c.249+1G>T c.249+3G>T c.249+3G>T c.906C>G c.242C>T c.242C>T c.242C>T c.994C>T c.994C>T Amino acid change p.Asp84Valfs*52/ p.Asp84Valfs*52/ p.Asp84Leufs*31/ p.Asp84Valfs*31/ p.Asp84Valfs*31/ p.Tyr302*/ p.(Ser81Leu)/ p.(Ser81Leu)/ p.(Ser81Leu)/ (NP_006569.1) p.(Arg332*) p.(Arg332*) p.Asp84Leufs*31 p.Asp84Valfs*31 p.Asp84Valfs*31 p.Tyr302* p.(Ser81Leu) p.(Ser81Leu) p.(Ser81Leu) 3580 g (50th 2751 g (15 th Birth weight NA NA NA 2845 g (15th NA NA NA percentile) percentile) percentile) Ethnicity Italy Italy Jordan Puerto Rico Puerto Rico India Morocco Morocco Brazil Consanguinity − − + + + − − − + Altered speech + + NR + + + + + NA development - Verbal NA NA nonverbal unremarkable unremarkable NA NA NA NA understanding - Lexical production NA NA nonverbal delayed delayed nonverbal delayed delayed NA Intellectual + + + + + + mild mild mild disability (ID) Epilepsy + + + - -

Puerto Rico Comprehensive Wildlife Conservation Strategy 2005
Comprehensive Wildlife Conservation Strategy Puerto Rico PUERTO RICO COMPREHENSIVE WILDLIFE CONSERVATION STRATEGY 2005 Miguel A. García José A. Cruz-Burgos Eduardo Ventosa-Febles Ricardo López-Ortiz ii Comprehensive Wildlife Conservation Strategy Puerto Rico ACKNOWLEDGMENTS Financial support for the completion of this initiative was provided to the Puerto Rico Department of Natural and Environmental Resources (DNER) by U.S. Fish and Wildlife Service (USFWS) Federal Assistance Office. Special thanks to Mr. Michael L. Piccirilli, Ms. Nicole Jiménez-Cooper, Ms. Emily Jo Williams, and Ms. Christine Willis from the USFWS, Region 4, for their support through the preparation of this document. Thanks to the colleagues that participated in the Comprehensive Wildlife Conservation Strategy (CWCS) Steering Committee: Mr. Ramón F. Martínez, Mr. José Berríos, Mrs. Aida Rosario, Mr. José Chabert, and Dr. Craig Lilyestrom for their collaboration in different aspects of this strategy. Other colleagues from DNER also contributed significantly to complete this document within the limited time schedule: Ms. María Camacho, Mr. Ramón L. Rivera, Ms. Griselle Rodríguez Ferrer, Mr. Alberto Puente, Mr. José Sustache, Ms. María M. Santiago, Mrs. María de Lourdes Olmeda, Mr. Gustavo Olivieri, Mrs. Vanessa Gautier, Ms. Hana Y. López-Torres, Mrs. Carmen Cardona, and Mr. Iván Llerandi-Román. Also, special thanks to Mr. Juan Luis Martínez from the University of Puerto Rico, for designing the cover of this document. A number of collaborators participated in earlier revisions of this CWCS: Mr. Fernando Nuñez-García, Mr. José Berríos, Dr. Craig Lilyestrom, Mr. Miguel Figuerola and Mr. Leopoldo Miranda. A special recognition goes to the authors and collaborators of the supporting documents, particularly, Regulation No. -

A Molecular Phylogeny of the Solanaceae
TAXON 57 (4) • November 2008: 1159–1181 Olmstead & al. • Molecular phylogeny of Solanaceae MOLECULAR PHYLOGENETICS A molecular phylogeny of the Solanaceae Richard G. Olmstead1*, Lynn Bohs2, Hala Abdel Migid1,3, Eugenio Santiago-Valentin1,4, Vicente F. Garcia1,5 & Sarah M. Collier1,6 1 Department of Biology, University of Washington, Seattle, Washington 98195, U.S.A. *olmstead@ u.washington.edu (author for correspondence) 2 Department of Biology, University of Utah, Salt Lake City, Utah 84112, U.S.A. 3 Present address: Botany Department, Faculty of Science, Mansoura University, Mansoura, Egypt 4 Present address: Jardin Botanico de Puerto Rico, Universidad de Puerto Rico, Apartado Postal 364984, San Juan 00936, Puerto Rico 5 Present address: Department of Integrative Biology, 3060 Valley Life Sciences Building, University of California, Berkeley, California 94720, U.S.A. 6 Present address: Department of Plant Breeding and Genetics, Cornell University, Ithaca, New York 14853, U.S.A. A phylogeny of Solanaceae is presented based on the chloroplast DNA regions ndhF and trnLF. With 89 genera and 190 species included, this represents a nearly comprehensive genus-level sampling and provides a framework phylogeny for the entire family that helps integrate many previously-published phylogenetic studies within So- lanaceae. The four genera comprising the family Goetzeaceae and the monotypic families Duckeodendraceae, Nolanaceae, and Sclerophylaceae, often recognized in traditional classifications, are shown to be included in Solanaceae. The current results corroborate previous studies that identify a monophyletic subfamily Solanoideae and the more inclusive “x = 12” clade, which includes Nicotiana and the Australian tribe Anthocercideae. These results also provide greater resolution among lineages within Solanoideae, confirming Jaltomata as sister to Solanum and identifying a clade comprised primarily of tribes Capsiceae (Capsicum and Lycianthes) and Physaleae. -

Matabuey (Goetzea Elegans) 5-Year Review: Summary and Evaluation U.S. Fish and Wildlife Service Southeast Region Caribbean Ecolo
Matabuey (Goetzea elegans) Photo: USFWS 5-Year Review: Summary and Evaluation U.S. Fish and Wildlife Service Southeast Region Caribbean Ecological Services Field Office Boquerón, Puerto Rico 1 5-YEAR REVIEW Matabuey (Goetzea elegans) I. GENERAL INFORMATION A. Methodology used to complete the review: On September 27, 2006, the Service published a notice in the Federal Register (71 FR 56545) announcing the 5-year review of the plant Matabuey (Goetzea elegans) and requesting new information concerning the biology and status of the species. We opened a 60-day public comment period with this notice; however, no information on matabuey was received from the public during the comment period. A Service biologist prepared the 5-year review that summarizes new information that since the species was listed on April 19, 1985 and the recovery plan signed on April 28, 1987. In conducting this 5-year review, we relied on the best available information pertaining to historical and current distribution, life history, habitat, and potential threats of this species. New information consists of publications related to research projects conducted by species experts from 1993 to 2007. This draft 5-year review was shared with several peer reviewers (see Appendix A). Comments received were evaluated and incorporated as appropriate. B. Reviewers Lead Region: Kelly Bibb, Southeast Region, Atlanta, Georgia. (404) 679-7132. Lead Field Office: Jose A. Cruz-Burgos, Caribbean Ecological Services Field Office, Boquerón, Puerto Rico. (787) 851-7297, extension 218. C. Background 1. Federal Register Notice citation announcing initiation of this review: September 27, 2006; 71 FR 56545. 2. Species Status: Increasing. -

Guide to Theecological Systemsof Puerto Rico
United States Department of Agriculture Guide to the Forest Service Ecological Systems International Institute of Tropical Forestry of Puerto Rico General Technical Report IITF-GTR-35 June 2009 Gary L. Miller and Ariel E. Lugo The Forest Service of the U.S. Department of Agriculture is dedicated to the principle of multiple use management of the Nation’s forest resources for sustained yields of wood, water, forage, wildlife, and recreation. Through forestry research, cooperation with the States and private forest owners, and management of the National Forests and national grasslands, it strives—as directed by Congress—to provide increasingly greater service to a growing Nation. The U.S. Department of Agriculture (USDA) prohibits discrimination in all its programs and activities on the basis of race, color, national origin, age, disability, and where applicable sex, marital status, familial status, parental status, religion, sexual orientation genetic information, political beliefs, reprisal, or because all or part of an individual’s income is derived from any public assistance program. (Not all prohibited bases apply to all programs.) Persons with disabilities who require alternative means for communication of program information (Braille, large print, audiotape, etc.) should contact USDA’s TARGET Center at (202) 720-2600 (voice and TDD).To file a complaint of discrimination, write USDA, Director, Office of Civil Rights, 1400 Independence Avenue, S.W. Washington, DC 20250-9410 or call (800) 795-3272 (voice) or (202) 720-6382 (TDD). USDA is an equal opportunity provider and employer. Authors Gary L. Miller is a professor, University of North Carolina, Environmental Studies, One University Heights, Asheville, NC 28804-3299.