Complementing GIS with Cluster Analysis in Assessing Property Crime in Katsina State, Nigeria
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
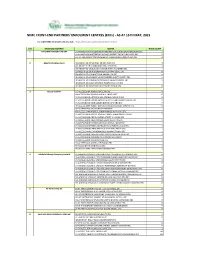
NIMC FRONT-END PARTNERS' ENROLMENT CENTRES (Ercs) - AS at 15TH MAY, 2021
NIMC FRONT-END PARTNERS' ENROLMENT CENTRES (ERCs) - AS AT 15TH MAY, 2021 For other NIMC enrolment centres, visit: https://nimc.gov.ng/nimc-enrolment-centres/ S/N FRONTEND PARTNER CENTER NODE COUNT 1 AA & MM MASTER FLAG ENT LA-AA AND MM MATSERFLAG AGBABIAKA STR ILOGBO EREMI BADAGRY ERC 1 LA-AA AND MM MATSERFLAG AGUMO MARKET OKOAFO BADAGRY ERC 0 OG-AA AND MM MATSERFLAG BAALE COMPOUND KOFEDOTI LGA ERC 0 2 Abuchi Ed.Ogbuju & Co AB-ABUCHI-ED ST MICHAEL RD ABA ABIA ERC 2 AN-ABUCHI-ED BUILDING MATERIAL OGIDI ERC 2 AN-ABUCHI-ED OGBUJU ZIK AVENUE AWKA ANAMBRA ERC 1 EB-ABUCHI-ED ENUGU BABAKALIKI EXP WAY ISIEKE ERC 0 EN-ABUCHI-ED UDUMA TOWN ANINRI LGA ERC 0 IM-ABUCHI-ED MBAKWE SQUARE ISIOKPO IDEATO NORTH ERC 1 IM-ABUCHI-ED UGBA AFOR OBOHIA RD AHIAZU MBAISE ERC 1 IM-ABUCHI-ED UGBA AMAIFEKE TOWN ORLU LGA ERC 1 IM-ABUCHI-ED UMUNEKE NGOR NGOR OKPALA ERC 0 3 Access Bank Plc DT-ACCESS BANK WARRI SAPELE RD ERC 0 EN-ACCESS BANK GARDEN AVENUE ENUGU ERC 0 FC-ACCESS BANK ADETOKUNBO ADEMOLA WUSE II ERC 0 FC-ACCESS BANK LADOKE AKINTOLA BOULEVARD GARKI II ABUJA ERC 1 FC-ACCESS BANK MOHAMMED BUHARI WAY CBD ERC 0 IM-ACCESS BANK WAAST AVENUE IKENEGBU LAYOUT OWERRI ERC 0 KD-ACCESS BANK KACHIA RD KADUNA ERC 1 KN-ACCESS BANK MURTALA MOHAMMED WAY KANO ERC 1 LA-ACCESS BANK ACCESS TOWERS PRINCE ALABA ONIRU STR ERC 1 LA-ACCESS BANK ADEOLA ODEKU STREET VI LAGOS ERC 1 LA-ACCESS BANK ADETOKUNBO ADEMOLA STR VI ERC 1 LA-ACCESS BANK IKOTUN JUNCTION IKOTUN LAGOS ERC 1 LA-ACCESS BANK ITIRE LAWANSON RD SURULERE LAGOS ERC 1 LA-ACCESS BANK LAGOS ABEOKUTA EXP WAY AGEGE ERC 1 LA-ACCESS -

Bayero University, Kano
BUK UTME Admission List - Uploaded on www.myschoolgist.com.ng BBAYEROAYERO UNIVERSITY, KANO OfficOfficee of The Registrar DIRECTORATE OF EXAMINATIONS, ADMISSIONS & RECORDS 22016/2017016/2017 UTME ADMISSIONS Faculty of Agriculture B. Agriculture -100590B S/N PS/N UTME No. Full Name 1 1 66173020HD MAILAFIYA MOHAMMED 2 2 65301356EC MUHAMMAD MUHAMMAD SANI 3 3 65193024II AHMAD FAIZ KABIR 4 4 66172307HI AHMAD NAFSUZZAKIYA ISAH 5 5 65303336BJ ABDULLAHI FATIMA ALI 6 6 65886647GD DANEIL EMMANUEL SUNDAY 7 7 65550339JA AHMED HAMZA ABUBAKAR 8 8 65875601CH ABBANI ABDULLAHI AMMANI 9 9 66543624HF MUHAMMAD YAHAYA 10 10 65248771HF BELLO ALIYU ALIYU 11 11 65193465CG AMINU AMINU BALA 12 12 66546533HI MUSA AUWAL MIKO 13 13 65193237DB ISHAQ ABDURRAHMAN MANSUR 14 14 65219564AI ASIRU ILIYASU ABDULLAHI 15 15 65881138AD SAGIR SURAJ ISAH 16 16 66547762HH SANI UMMI USMAN 17 17 65235454GC YUSIF USMAN SALISU 18 18 65305219JD YUSUF HUSSAINA TIJJANI 19 19 65528886EB NASIR HASSAN IBRAHIM BUK UTME Admission List - Uploaded on www.myschoolgist.com.ng 20 20 65879081GD MAGASHI ADAMU AMINU 21 21 65885355FJ IDRIS ACHAMAJA JIBRIL 22 22 65898369BB MUHAMMAD BALA SANI 23 23 65295005ID ABDUL ADAMU SABO 24 24 66180675JH UBALE ABDUL GWAMNATI 25 25 65248118JE YAQUB BILYAMINU 26 26 66182381CD HASSAN ABDULRAZAK SALISU 27 27 65882096DJ SHANAWA RUFAI ISAH 28 28 65194550GJ GWADABE USMAN BASHIR 29 29 65196802AG KABIR ABDULMALIK 30 30 66542377DD USMAN ISA 31 31 65879598GE ABDULLAHI ABUBAKAR 32 32 65245787AG MAMUDA SUNUSI 33 33 65887995JD HAFIZ AISHA ABDULYASSAR 34 34 65047384CD NURA ABDULLAHI -

Report of the Technical Committee Om
REPORT OF THE TECHNICAL COMMITTEE ON CONSTITUTIONAL PROVISIONS FOR THE APPLICATION OF SHARIA IN KATSINA STATE January 2000 Contents: Volume I: Main Report Chapter One: Preliminary Matters Preamble Terms of Reference Modus Operandi Chapter Two: Consideration of Various Sections of the Constitution in Relation to Application of Sharia A. Section 4(6) B. Section 5(2) C. Section 6(2) D. Section 10 E. Section 38 F. Section 275(1) G. Section 277 Chapter Three: Observations and Recommendations 1. General Observations 2. Specific Recommendations 3. General Recommendations Conclusion Appendix A: List of all the Groups, Associations, Institutions and Individuals Contacted by the Committee Volume II: Verbatim Proceedings Zone 1: Funtua: Funtua, Bakori, Danja, Faskari, Dandume and Sabuwa Zone 2: Malumfashi: Malumfashi, Kafur, Kankara and Musawa Zone 3: Dutsin-Ma: Dutsin-Ma, Danmusa, Batsari, Kurfi and Safana Zone 4: Kankia: Kankia, Ingawa, Kusada and Matazu Zone 5: Daura: Daura, Baure, Zango, Mai’adua and Sandamu Zone 6: Mani: Mani, Mashi, Dutsi and Bindawa Zone 7: Katsina: Katsina, Kaita, Rimi, Jibia, Charanchi and Batagarawa 1 Ostien: Sharia Implementation in Northern Nigeria 1999-2006: A Sourcebook: Supplement to Chapter 2 REPORT OF THE TECHNICAL COMMITTEE ON APPLICATION OF SHARIA IN KATSINA STATE VOLUME I: MAIN REPORT CHAPTER ONE Preamble The Committee was inaugurated on the 20th October, 1999 by His Excellency, the Governor of Katsina State, Alhaji Umaru Musa Yar’adua, at the Council Chambers, Government House. In his inaugural address, the Governor gave four point terms of reference to the Committee. He urged members of the Committee to work towards realising the objectives for which the Committee was set up. -

Monetering of Infectious Diseases in Katsina and Daura Zones of Katsina State: a Clustering Analysis
Available online at http://www.ajol.info/index.php/njbas/index Nigerian Journal of Basic and Applied Science (2011), 19 (1): 31-42 ISSN 0794-5698 Monetering of Infectious Diseases in Katsina and Daura Zones of Katsina State: A Clustering Analysis 1U. Dauda, 2S.U. Gulumbe, *2M. Yakubu and 1L.K. Ibrahim 1Department of Mathematics and Computer Science, Umaru Musa Yar’aduwa University, Katsina. 2Department of mathematics Usmanu Danfodiyo University, Sokoto Nigeria [*Corresponding Author: [email protected]] ABSTRACT: In this paper, data of infectious diseases were collected from the two senatorial zones of Katsina state, and analyzed using cluster analysis, a multivariate technique. This necessitated a partition of the set of diseases into groups such that the diseases with similar degree of prevalence were identified. The result of the cluster formation shows that Malaria is more prevalent in all of the two zones, followed by Cholera and Typhoid fever using the Single Linkage and Centroid methods. The Complete Linkage and Ward methods showed that Malaria is the most prevalent followed by Typhoid fever and Cholera in Katsina zone, while in Daura zone Typhoid fever is more prevalent followed by Malaria and Cholera. The number of clusters tends to vary from one zone to another. This is achieved by using Chi-square test for independence. The study concludes that the use of clustering methods provides a suitable tool for assessing the level of infections of the disease. Keywords: Cluster analysis, Infectious diseases, Malaria, Cholera and Typhoid INTRODUCTION important is that it is caused by living One of the most challenging tasks to public health microorganisms which can usually be identified, in Nigeria and Africa in general, is the control of thus establishing the aetiology early in the illness. -

IOM Nigeria DTM Flash Report NCNW 37 (31 January 2021)
FLASH REPORT #37: POPULATION DISPLACEMENT DTM North West/North Central Nigeria Nigeria 25 - 31 JANUARY 2021 Casualties: Movement Trigger: 160 Individuals 9 Individuals Armed attacks OVERVIEW The crisis in Nigeria’s North Central and North West zones, which involves long-standing tensions between NIGER REPUBLIC ethnic and religious groups; attacks by criminal Kaita Mashi Mai'adua Jibia groups; and banditry/hirabah (such as kidnapping and Katsina Daura Zango Dutsi Faskari Batagarawa Mani Rimi Safana grand larceny along major highways) led to a fresh Batsari Baure Bindawa wave of population displacement. 134 Kurfi Charanchi Ingawa Sandamu Kusada Dutsin-Ma Kankia Following these events, a rapid assessment was Katsina Matazu conducted by DTM (Displacement Tracking Matrix) Dan Musa Jigawa Musawa field staff between 25 and 31 January 2021, with the Kankara purpose of informing the humanitarian community Malumfashi Katsina Kano Faskari Kafur and government partners in enabling targeted Bakori response. Flash reports utilise direct observation and Funtua Dandume Danja a broad network of key informants to gather represen- Sabuwa tative data and collect information on the number, profile and immediate needs of affected populations. NIGERIA Latest attacks affected 160 individuals, including 14 injuries and 9 fatalities, in Makurdi LGA of Benue State and Faskari LGA of Katsina State. The attacks caused Kaduna people to flee to neighbouring localities. SEX (FIG. 1) Plateau Federal Capital Territory 39% Nasarawa X Affected Population 61% Male Makurdi International border Female 26 State Guma Agatu Benue Makurdi LGA Apa Gwer West Tarka Oturkpo Gwer East Affected LGAs Gboko Ohimini Konshisha Ushongo The map is for illustration purposes only. -

Nigeria's Constitution of 1999
PDF generated: 26 Aug 2021, 16:42 constituteproject.org Nigeria's Constitution of 1999 This complete constitution has been generated from excerpts of texts from the repository of the Comparative Constitutions Project, and distributed on constituteproject.org. constituteproject.org PDF generated: 26 Aug 2021, 16:42 Table of contents Preamble . 5 Chapter I: General Provisions . 5 Part I: Federal Republic of Nigeria . 5 Part II: Powers of the Federal Republic of Nigeria . 6 Chapter II: Fundamental Objectives and Directive Principles of State Policy . 13 Chapter III: Citizenship . 17 Chapter IV: Fundamental Rights . 20 Chapter V: The Legislature . 28 Part I: National Assembly . 28 A. Composition and Staff of National Assembly . 28 B. Procedure for Summoning and Dissolution of National Assembly . 29 C. Qualifications for Membership of National Assembly and Right of Attendance . 32 D. Elections to National Assembly . 35 E. Powers and Control over Public Funds . 36 Part II: House of Assembly of a State . 40 A. Composition and Staff of House of Assembly . 40 B. Procedure for Summoning and Dissolution of House of Assembly . 41 C. Qualification for Membership of House of Assembly and Right of Attendance . 43 D. Elections to a House of Assembly . 45 E. Powers and Control over Public Funds . 47 Chapter VI: The Executive . 50 Part I: Federal Executive . 50 A. The President of the Federation . 50 B. Establishment of Certain Federal Executive Bodies . 58 C. Public Revenue . 61 D. The Public Service of the Federation . 63 Part II: State Executive . 65 A. Governor of a State . 65 B. Establishment of Certain State Executive Bodies . -

Legacies of Colonialism and Islam for Hausa Women: an Historical Analysis, 1804-1960
Legacies of Colonialism and Islam for Hausa Women: An Historical Analysis, 1804-1960 by Kari Bergstrom Michigan State University Winner of the Rita S. Gallin Award for the Best Graduate Student Paper in Women and International Development Working Paper #276 October 2002 Abstract This paper looks at the effects of Islamization and colonialism on women in Hausaland. Beginning with the jihad and subsequent Islamic government of ‘dan Fodio, I examine the changes impacting Hausa women in and outside of the Caliphate he established. Women inside of the Caliphate were increasingly pushed out of public life and relegated to the domestic space. Islamic law was widely established, and large-scale slave production became key to the economy of the Caliphate. In contrast, Hausa women outside of the Caliphate were better able to maintain historical positions of authority in political and religious realms. As the French and British colonized Hausaland, the partition they made corresponded roughly with those Hausas inside and outside of the Caliphate. The British colonized the Caliphate through a system of indirect rule, which reinforced many of the Caliphate’s ways of governance. The British did, however, abolish slavery and impose a new legal system, both of which had significant effects on Hausa women in Nigeria. The French colonized the northern Hausa kingdoms, which had resisted the Caliphate’s rule. Through patriarchal French colonial policies, Hausa women in Niger found they could no longer exercise the political and religious authority that they historically had held. The literature on Hausa women in Niger is considerably less well developed than it is for Hausa women in Nigeria. -

Analysis of Crime in Katsina Metropolitan Area, Katsina State
ANALYSIS OF CRIME IN KATSINA METROPOLITAN AREA, KATSINA STATE, NIGERIA BY Ahmed Barde, ABDULLAHI B.Sc (A.B.U. Zaria) A DISSERTATION SUBMITTED TO THE SCHOOL OF POSTGRADUATE STUDIES, AHMADU BELLO UNIVERSITY, ZARIA, NIGERIA IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE AWARD OF MASTER OF SCIENCE DEGREE IN REMOTE SENSING AND GEOGRAPHICAL INFORMATION SYSTEM DEPARTMENT OF GEOGRAPHY AND ENVIRONMENTAL STUDIES, AHMADU BELLO UNIVERSITY, ZARIA, NIGERIA NOVEMBER, 2018 ANALYSIS OF CRIME IN KATSINA METROPOLITAN AREA, KATSINA STATE, NIGERIA BY Ahmed Barde, ABDULLAHI B.Sc (A.B.U. Zaria) P16PSGS8540 A DISSERTATION SUBMITTED TO THE SCHOOL OF POSTGRADUATE STUDIES, AHMADU BELLO UNIVERSITY, ZARIA, NIGERIA IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE AWARD OF MASTER OF SCIENCE DEGREE IN REMOTE SENSING AND GEOGRAPHICAL INFORMATION SYSTEM DEPARTMENT OF GEOGRAPHY AND ENVIRONMENTAL STUDIES, AHMADU BELLO UNIVERSITY, ZARIA, NIGERIA NOVEMBER, 2018 ii DECLARATION I declare that this project research titled‟ “ANALYSIS OF CRIME IN KATSINA METROPOLITAN AREA, KATSINA STATE NIGERIA” Wasconducted by me under the supervision of DR. A.K Usman and DR.B. AkpuDepartment of Geography and Environmental Management and it is a record of my own work and has not been submitted for the award of Masters Degree, diploma or any other qualification in any other institution. All information and excerpts from the work of any other has been acknowledged by means of references. ABDULLAHI AHMED BARDE ______________________ ___________________ Signature Date iii CERTIFICATION This dissertation entitled “ANALYSIS OF CRIME IN KATSINA METROPOLITAN AREA, KATSINA STATE NIGERIA” meets the regulations governing the award of masters‟ degree of Remote Sensing and GIS of Ahmadu Bello University and approved for its contribution to knowledge and literary presentation. -

Socio-Economic Characteristics Influencing Farm Household Participation in Gandu System in Charanchi Local Government Area of Katsina State, Nigeria
Journal of Agricultural Extension and Rural Development Vol. 3(12), pp. 220-223, November 2011 Available online http:// academicjournals.org/JAERD DOI: 10.5897/JAERD11.053 ISSN- 2141 -2154 ©2011 Academic Journals Full Length Research Paper Socio-economic characteristics influencing farm household participation in gandu system in Charanchi Local Government Area of Katsina State, Nigeria Yusuf, H. A.*, Omokore, D. F. , Akinola, M. O. and Omolehin, R. A. Department of Agricultural Economics and Rural Sociology, P.M.B. 1044, Ahmadu Bello University, Zaria, Kaduna State, Nigeria. Accepted 2 August, 2011 The study aims at determining the socio-economic characteristics influencing farm household participation in gandu system. The data for this study were obtained by the use of structured interview schedule. A total sample size of 140 households was interviewed consisting of 70 gandu and 70 non- gandu participants. Descriptive statistics and logit regression model were used to analyse the data collected. The results of the study indicated that household size (X2) and extension contact (X6) significantly influence participation in gandu system at 1% level of probability while age of household head (X1) significantly influence it at 5% level of probability and migration (X5) was significant at 10% level of probability. Hence, it is recommended that extension contact should be targeted towards the gandu heads who are usually traditionally bound. It is also suggested that, adult literacy classes should be organised for the farmers by the local government so as to improve their literacy level and enable them to understand technical recommendations made by extension agents. In order to discourage migration of youth to urban areas, infrastructural facilities and social amenities such as water, electricity, roads, schools and hospitals should be provided. -

IOM Nigeria DTM Flash Report NCNW 26 June 2020
FLASH REPORT: POPULATION DISPLACEMENT DTM North West/North Central Nigeria. Nigeria 22 - 26 JUNE 2020 Aected Population: Casualties: Movement Trigger: 2,349 Individuals 3 Individuals Armed attacks OVERVIEW Maikwama 219 The crisis in Nigeria’s North Central and North West zones, which involves long-standing Dandume tensions between ethnic and linguis�c groups; a�acks by criminal groups; and banditry/hirabah (such as kidnapping and grand larceny along major highways) led to fresh wave of popula�on displacement. Kaita Mashi Mai'adua Jibia Shinkafi Katsina Daura Zango Dutsi Batagarawa Mani Safana Latest a�acks affected 2,349 individuals, includ- Zurmi Rimi Batsari Baure Maradun Bindawa Kurfi ing 18 injuries and 3 fatali�es, in Dandume LGA Bakura Charanchi Ingawa Jigawa Kaura Namoda Sandamu Katsina Birnin Magaji Kusada Dutsin-Ma Kankia (Katsina) and Bukkuyum LGA (Zamfara) between Talata Mafara Bungudu Matazu Dan Musa 22 - 26 June, 2020. The a�acks caused people to Gusau Zamfara Musawa Gummi Kankara flee to neighboring locali�es. Bukkuyum Anka Tsafe Malumfashi Kano Faskari Kafur Gusau Bakori A rapid assessment was conducted by field staff Maru Funtua Dandume Danja to assess the impact on people and immediate Sabuwa needs. ± GENDER (FIG. 1) Kaduna X Affected PopulationPlateau 42% Kyaram 58% Male State Bukkuyum 2,130 Female Federal Capital Territory LGA Nasarawa Affected LGAs The map is for illustration purposes only. The depiction and use of boundaries, geographic names and related data shown are not warranted to be error free nor do they imply judgment on the legal status of any territory, or any endorsement or accpetance of such boundaries by MOST NEEDED ASSISTANCE (FIG. -

Kabiru Abubakar Gulma
24, Block B, 200 Housing Estate (after Kabiru Abubakar Gulma Kebbi Radio), Birnin Kebbi, Nigeria State Logistics Coordinator [email protected] AXIOS Foundation Nigeria (234) 803 9728 505; (234) 7011558801 Skype ID: mcgulma https://ng.linkedin.com/pub/kabiru- abubakar-gulma/b4/70a/77b S k i l l s : Supply chain management; public health logistics [forecasting, quantification, procurement, Logistics Management Information System (LMIS), and monitoring & evaluation]; contract management; health system strengthening; and project m a n a g e m e n t EDUCATION CAREER EXPERIENCE (3) Euclid University, The Gambia October 2016 to present (July 2016 – Date) Organization: Axios Foundation Nigeria Title/Position: State Logistics Coordinator (Katsina) Degree: Doctor of Philosophy Program: Nigerian Maternal, Newborn, and Child Health (Ph.D.) in International Public Programme (MNCH2)- DfID-funded Health Project goals achieved included: (2) Assam Don Bosco University, India (March 2016) 1. Coordinated state-wide review of quantification for 2017 and 2018 commodities Degree: Master of Business and equipment to be supplied to 204 MNCH2- Administration (MBA)- Dual supported health facilities across the 34 Local Degree (Supply Chain and Project Management) Government Areas (LGAs) of Katsina State 2. Supported Katsina State to develop distribution (1) Ahmadu Bello University, Zaria- plans for commodities received in 2015, 2016, Nigeria (August 2010) and 2017 to 16 general hospitals, 29 comprehensive health centers, and 159 Degree: Bachelor of Pharmacy (B. primary health center Pharm) 3. Coordinated the implementation year 3 CERTIFICATE COURSES (1) Johns Hopkins University, MNCH2 renovation of health facilities (14 LGA Baltimore- USA (2017) Medical Stores, 14 LGA Cold Chain Stores, and Course: Statistical Reasoning 9 primary health centers) across Mani, Mashi, for Public Health: Estimation, Daura, Rimi, Bindawa, Zango, Baure, Matazu, Inference, and Interpretation Danmusa, Safana, Kafur, Sabuwa, Kaita, and Danja LGAs. -

2018/2019 Annual School Census Report
Foreword Successful education policies are formed and supported by accurate, timely and reliable data, to improve governance practices, enhance accountability and ultimately improve the teaching and learning process in schools. Considering the importance of robust data collection, the Planning, Research and Statistics (PRS) Department, Katsina State Ministry of Education prepares and publishes the Annual Schools Census Statistical Report of both Public and Private Schools on an annual basis. This is in compliance with the National EMIS Policy and its implementation. The Annual Schools Census Statistical Report of 2018-2019 is the outcome of the exercise conducted between May and June 2019, through a rigorous activities that include training Head Teachers and Teachers on School Records Keeping; how to fill ASC questionnaire using school records; data collection, validation, entry, consistency checks and analysis. This publication is the 13th Annual Schools Census Statistical Report of all Schools in the State. In line with specific objectives of National Education Management Information System (NEMIS), this year’s ASC has obtained comprehensive and reliable data where by all data obtained were from the primary source (the school’s head provide all data required from schools records). Data on Key Performance Indicators (KPIs) of basic education and post basic to track the achievement of the State Education Sector Operational Plan (SESOP) as well as Sustainable Development Goals (SDGs); feed data into the National databank to strengthen NEMIS for national and global reporting. The report comprises of educational data pertaining to all level both public and private schools ranging from pre-primary, primary, junior secondary and senior secondary level.