Department of Hindi
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
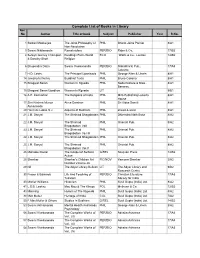
Complete List of Books in Library Acc No Author Title of Book Subject Publisher Year R.No
Complete List of Books in Library Acc No Author Title of book Subject Publisher Year R.No. 1 Satkari Mookerjee The Jaina Philosophy of PHIL Bharat Jaina Parisat 8/A1 Non-Absolutism 3 Swami Nikilananda Ramakrishna PER/BIO Rider & Co. 17/B2 4 Selwyn Gurney Champion Readings From World ECO `Watts & Co., London 14/B2 & Dorothy Short Religion 6 Bhupendra Datta Swami Vivekananda PER/BIO Nababharat Pub., 17/A3 Calcutta 7 H.D. Lewis The Principal Upanisads PHIL George Allen & Unwin 8/A1 14 Jawaherlal Nehru Buddhist Texts PHIL Bruno Cassirer 8/A1 15 Bhagwat Saran Women In Rgveda PHIL Nada Kishore & Bros., 8/A1 Benares. 15 Bhagwat Saran Upadhya Women in Rgveda LIT 9/B1 16 A.P. Karmarkar The Religions of India PHIL Mira Publishing Lonavla 8/A1 House 17 Shri Krishna Menon Atma-Darshan PHIL Sri Vidya Samiti 8/A1 Atmananda 20 Henri de Lubac S.J. Aspects of Budhism PHIL sheed & ward 8/A1 21 J.M. Sanyal The Shrimad Bhagabatam PHIL Dhirendra Nath Bose 8/A2 22 J.M. Sanyal The Shrimad PHIL Oriental Pub. 8/A2 Bhagabatam VolI 23 J.M. Sanyal The Shrimad PHIL Oriental Pub. 8/A2 Bhagabatam Vo.l III 24 J.M. Sanyal The Shrimad Bhagabatam PHIL Oriental Pub. 8/A2 25 J.M. Sanyal The Shrimad PHIL Oriental Pub. 8/A2 Bhagabatam Vol.V 26 Mahadev Desai The Gospel of Selfless G/REL Navijvan Press 14/B2 Action 28 Shankar Shankar's Children Art FIC/NOV Yamuna Shankar 2/A2 Number Volume 28 29 Nil The Adyar Library Bulletin LIT The Adyar Library and 9/B2 Research Centre 30 Fraser & Edwards Life And Teaching of PER/BIO Christian Literature 17/A3 Tukaram Society for India 40 Monier Williams Hinduism PHIL Susil Gupta (India) Ltd. -

Changing Ideas of Freedom in the Indian Postcolonial Context
IDEALISM, ENCHANTMENT AND DISENCHANTMENT: CHANGING IDEAS OF FREEDOM IN THE INDIAN POSTCOLONIAL CONTEXT Yamini Worldwide, Colonial and Postcolonial Literature has represented processes of nation-formation and concepts of nationalism through experiments with forms of representation. Such experiments were quite predominant in the novel form, with its ability to incorporate vast spatial and temporal realities. Homi Bhabha’s Nation and Narration (2008) is a seminal volume discussing the innovations in the Twentieth Century Novel through a Postcolonial perspective and understanding these changes through the idea of National Literatures. The Cambridge Companion to Postcolonial Literary Studies (Neil Lazarus) and The Post-Colonial Studies Reader (Bill Ashcroft et al) present extensive discussions on the relationship between the politics of nation-formation and forms of fiction. In this article I offer a brief introduction to the evolution of the Hindi novel (1940s-1980s) with reference to the freedom movement and nationalist struggle in India. Benedict Anderson’s formulation regarding the significance of the genre of the novel in the process of nation-formation and Timothy Brennan’s concept of ‘The National Longing for Form’ published in Nation and Narration also establishes the novel as a genre representing, as well as creating, the Nation. Brennan writes It was the novel that historically accompanied the rise of the nations by objectifying the ‘one, yet many’ of the national life, and by mimicking the structure of the nation, a clearly bordered jumble of languages and styles… Its manner of presentation allowed people to imagine the special community that was the nation (Brennan, 2008: 49). Postcolonial theories have focussed on the relationship between realism and nationalism within the genre of the novel. -

General Knowledge ABBREVIATIONS a A.A.F
General Knowledge ABBREVIATIONS A A.A.F. Auxiliary Air Force A.A.S.U. All Asom Students Union A.C.D. Asian Co-operation Dialogue A.D.B. Asian Development Bank A.E.C. Atomic Energy Commission A.F.P.R.O. Action for Food Production A.I.C.C. All India Congress Committee A.I.D.W.A. All India Democratic Women’s Association A.I.D.S. Acquired Immune Deficiency Syndrome A.I.H.B. All India Handicrafts Board A.I.R. Annual Information Report A.J.T. Advanced Jet Trainer A.P.E.C. Asia-Pacific Economic Cooperation A.R.F. ASEAN Regional Forum A.S.E.A.N. Association of South-East Asian Nations A.S.L.V. Augmented Satellite Launch Vehicle A.U. African Union A.V.E.S. Acute Viral Encephalitic Syndrome A.W.A.N. Army Wide Area Network A.Y.U.S.H. Ayurveda, Yoga, Unani, Siddha and Homeopathy B B.A.R.C. Bhabha Atomic Research Centre B.C.C.I. Board of Control of Cricket in India/Bank of Credit and Commerce International B.C.G. Bacillus Calmette Guerin (Anti-T.B. vaccine) B.C.T.T. Bank Cash Transaction Tax B.O.A.C. British Overseas Airways Corporation B.P.O. Business Process Outsourcing BREAD Basic Research Education And Development (SOCIENTY) B.S.N.L. Bharat Sanchar Nigam Ltd. B.V.R.A.A.M. Beyond Visual Range Air-to-Air Missile C C.A. Chartered Accountant C.A.C. Capital Account Convertibility 4 | G.K. C.A.C.C.I. -

Sahitya Akademi Translation Prize 2013
DELHI SAHITYA AKADEMI TRANSLATION PRIZE 2013 August 22, 2014, Guwahati Translation is one area that has been by and large neglected hitherto by the literary community world over and it is time others too emulate the work of the Akademi in this regard and promote translations. For, translations in addition to their role of carrying creative literature beyond known boundaries also act as rebirth of the original creative writings. Also translation, especially of ahitya Akademi’s Translation Prizes for 2013 were poems, supply to other literary traditions crafts, tools presented at a grand ceremony held at Pragyajyoti and rhythms hitherto unknown to them. He cited several SAuditorium, ITA Centre for Performing Arts, examples from Hindi poetry and their transportation Guwahati on August 22, 2014. Sahitya Akademi and into English. Jnanpith Award winner Dr Kedarnath Singh graced the occasion as a Chief Guest and Dr Vishwanath Prasad Sahitya Akademi and Jnanpith Award winner, Dr Tiwari, President, Sahitya Akademi presided over and Kedarnath Singh, in his address, spoke at length about distributed the prizes and cheques to the award winning the role and place of translations in any given literature. translators. He was very happy that the Akademi is recognizing Dr K. Sreenivasarao welcomed the Chief Guest, and celebrating the translators and translations and participants, award winning translators and other also financial incentives are available now a days to the literary connoisseurs who attended the ceremony. He translators. He also enumerated how the translations spoke at length about various efforts and programmes widened the horizons his own life and enriched his of the Akademi to promote literature through India and literary career. -

Of Contemporary India
OF CONTEMPORARY INDIA Catalogue Of The Papers of Prabhakar Machwe Plot # 2, Rajiv Gandhi Education City, P.O. Rai, Sonepat – 131029, Haryana (India) Dr. Prabhakar Machwe (1917-1991) Prolific writer, linguist and an authority on Indian literature, Dr. Prabhakar Machwe was born on 26 December 1917 at Gwalior, Madhya Pradesh, India. He graduated from Vikram University, Ujjain and obtained Masters in Philosophy, 1937, and English Literature, 1945, Agra University; Sahitya Ratna and Ph.D, Agra University, 1957. Dr. Machwe started his career as a lecturer in Madhav College, Ujjain, 1938-48. He worked as Literary Producer, All India Radio, Nagpur, Allahabad and New Delhi, 1948-54. He was closely associated with Sahitya Akademi from its inception in 1954 and served as Assistant Secretary, 1954-70, and Secretary, 1970-75. Dr. Machwe was Visiting Professor in Indian Studies Departments at the University of Wisconsin and the University of California on a Fulbright and Rockefeller grant (1959-1961); and later Officer on Special Duty (Language) in Union Public Service Commission, 1964-66. After retiring from Sahitya Akademi in 1975, Dr. Machwe was a visiting fellow at the Institute of Advanced Studies, Simla, 1976-77, and Director of Bharatiya Bhasha Parishad, Calcutta, 1979-85. He spent the last years of his life in Indore as Chief Editor of a Hindi daily, Choutha Sansar, 1988-91. Dr. Prabhakar Machwe travelled widely for lecture tours to Germany, Russia, Sri Lanka, Mauritius, Japan and Thailand. He organised national and international seminars on the occasion of the birth centenaries of Mahatma Gandhi, Rabindranath Tagore, and Sri Aurobindo between 1961 and 1972. -

NATIONAL AWARDS JNANPITH AWARD Year Name Language
NATIONAL AWARDS JNANPITH AWARD he Jnanpith Award, instituted on May 22, 1961, is given for the best creative literary T writing by any Indian citizen in any of the languages included in the VIII schedule of the Constitution of India. From 1982 the award is being given for overall contribution to literature. The award carries a cash price of Rs 2.5 lakh, a citation and a bronze replica of Vagdevi. The first award was given in 1965 . Year Name Language Name of the Work 1965 Shankara Kurup Malayalam Odakkuzhal 1966 Tara Shankar Bandopadhyaya Bengali Ganadevta 1967 Dr. K.V. Puttappa Kannada Sri Ramayana Darshan 1967 Uma Shankar Joshi Gujarati Nishitha 1968 Sumitra Nandan Pant Hindi Chidambara 1969 Firaq Garakpuri Urdu Gul-e-Naghma 1970 Viswanadha Satyanarayana Telugu Ramayana Kalpavrikshamu 1971 Bishnu Dey Bengali Smriti Satta Bhavishyat 1972 Ramdhari Singh Dinakar Hindi Uravasi 1973 Dattatreya Ramachandran Kannada Nakutanti Bendre 1973 Gopinath Mohanty Oriya Mattimatal 1974 Vishnu Sankaram Khanldekar Marathi Yayati 1975 P.V. Akhilandam Tamil Chittrappavai 1976 Asha Purna Devi Bengali Pratham Pratisruti 1977 Kota Shivarama Karanth Kannada Mukajjiya Kanasugalu 1978 S.H. Ajneya Hindi Kitni Navon mein Kitni Bar 1979 Birendra Kumar Bhattacharya Assamese Mrityunjay 1980 S.K. Pottekkat Malayalam Oru Desattinte Katha 1981 Mrs. Amrita Pritam Punjabi Kagaz te Canvas 1982 Mahadevi Varma Hindi Yama 1983 Masti Venkatesa Iyengar Kannada Chikka Veera Rajendra 1984 Takazhi Siva Shankar Pillai Malayalam 1985 Pannalal Patel Gujarati 1986 Sachidanand Rout Roy Oriya 1987 Vishnu Vaman Shirwadkar Kusumagraj 1988 Dr. C. Narayana Reddy Telugu Vishwambhara 1989 Qurratulain Hyder Urdu 1990 Prof. Vinayak Kishan Gokak Kannada Bharatha Sindhu Rashmi Year Name Language Name of the Work 1991 Subhas Mukhopadhyay Bengali 1992 Naresh Mehta Hindi 1993 Sitakant Mohapatra Oriya 1994 Prof. -

Copy of UNPAID Final WARRANTS 31.10.2016
Statement showing unpaid/unclaimed dividend as on 30.09.2016 for the F.Y. (Final) 2015-16 Sr. No Folio Beneficiary Name Add1 Add2 Add3 Pincode Amount INDERJIT SINGH SETHI ADJOINING HDFC 1 I000326 0045076094010 INDUSIND 87, GLOBE HOUSE BMC CHOWK 90.00 BANK BANK LTD 2 K000382 KALAVATI KAMBAM K CHANDRAKALABATHI H NO 4/146 MUDDANUR 90.00 PATEL PARK NO 2 ROOM NR RANCHODAJI 3 K000778 KIRTIKUMAR KATARIA KATARIA 90.00 NO B 7 TEMPLE WAGODIA 4 N002074 NIMESH KISHORBHAI B G SHAH MEDICAL ST STATION ROAD BODELI 90.00 5P000413 PARAMJIT SINGH D-140 RANJIT AVENUE AMRITSAR PUNJAB 90.00 PRAKASH DNYANOBA 6 P001373 ZYDUS ALTANA PVT LTD PAWANE VILLAGE VASHI 90.00 GAIKWAD 7 S001261 SHYAM BABU GUPTA B.12 INDRLEKHA SOCAIETY SECTR 9.A. VASHI 90.00 8 S001677 SUNITA SHARMA 84 AGRASEN NAGAR AERODROME ROAD INDORE 90.00 C/O PACIFIC PROJECTS SAFEWAY HOUSE D-4 9 S002237 SATISH KUMAR BALYAN PRASHANT VIHAR 110001 90.00 PVT LTD CENTRAL MARKET 10 P000860 PREM SINGH SHARMA 19/988 LODHI COLONY NEW DELHI 110003 90.00 11P001400 PARVEEN KUMAR B 5A GALI NO 4 HIMGIRI ENCLAVE NILOTHI EXTN 110004 90.00 12 G000456 GIRISH MADAN LARSEN ELECTRICALS 1874 BHAGIRATH DELHI 110006 90.00 13 H000538 HEMANT MADAN LARSEN ELECTRICALS 1874 BHAGIRATH DELHI 110006 90.00 JAIN STORE 6033 GALI NAYA BANS KHARI 14 R001030 RATANLAL JAIN DELHI 110006 90.00 ARYA SAMAJ BAOLI 15 V000719 VINOD KHURANA 25/143 SHAKTI NAGAR KLHLURANA MEDICO DELHI 110007 90.00 16 K000781 KISHAN LAL OBEROI U-35 WEST PATEL NAGAR NEW DELHI 110008 90.00 MANISHA SHARMA 12044700 FOURTH LANE 17 392010100004602 AXIS 203 MODEL TOWN 110009 -

Language and Literature
1 Indian Languages and Literature Introduction Thousands of years ago, the people of the Harappan civilisation knew how to write. Unfortunately, their script has not yet been deciphered. Despite this setback, it is safe to state that the literary traditions of India go back to over 3,000 years ago. India is a huge land with a continuous history spanning several millennia. There is a staggering degree of variety and diversity in the languages and dialects spoken by Indians. This diversity is a result of the influx of languages and ideas from all over the continent, mostly through migration from Central, Eastern and Western Asia. There are differences and variations in the languages and dialects as a result of several factors – ethnicity, history, geography and others. There is a broad social integration among all the speakers of a certain language. In the beginning languages and dialects developed in the different regions of the country in relative isolation. In India, languages are often a mark of identity of a person and define regional boundaries. Cultural mixing among various races and communities led to the mixing of languages and dialects to a great extent, although they still maintain regional identity. In free India, the broad geographical distribution pattern of major language groups was used as one of the decisive factors for the formation of states. This gave a new political meaning to the geographical pattern of the linguistic distribution in the country. According to the 1961 census figures, the most comprehensive data on languages collected in India, there were 187 languages spoken by different sections of our society. -

Wandering Writers in the Himalaya: Contesting Narratives and Renunciation in Modern Hindi Literature
Cracow Indological Studies vol. XVII (2015) 10.12797/CIS.17.2015.17.04 Nicola Pozza [email protected] (University of Lausanne, Switzerland) Wandering Writers in the Himalaya: Contesting Narratives and Renunciation in Modern Hindi Literature Summary: The Himalayan setting—especially present-day Himachal Pradesh and Uttarakhand—has fascinated many a writer in India. Journeys, wanderings, and sojourns in the Himalaya by Hindi authors have resulted in many travelogues, as well as in some emblematic short stories of modern Hindi literature. If the environment of the Himalaya and its hill stations has inspired the plot of several fictional writ- ings, the description of the life and traditions of its inhabitants has not been the main focus of these stories. Rather, the Himalayan setting has primarily been used as a nar- rative device to explore and contest the relationship between the mountain world and the intrusive presence of the external world (primarily British colonialism, but also patriarchal Hindu society). Moreover, and despite the anti-conformist approach of the writers selected for this paper (Agyeya, Mohan Rakesh, Nirmal Verma and Krishna Sobti), what mainly emerges from an analysis of their stories is that the Himalayan setting, no matter the way it is described, remains first and foremost a lasting topos for renunciation and liberation. KEYWORDS: Himalaya, Hindi, fiction, wandering, colonialism, modernity, renunci- ation, Agyeya, Nirmal Verma, Mohan Rakesh, Krishna Sobti. Introduction: Himalaya at a glance The Himalaya has been a place of fascination for non-residents since time immemorial and has attracted travellers, monks and pilgrims and itinerant merchants from all over Asia and Europe. -

Secondary Indian Culture and Heritage
Culture: An Introduction MODULE - I Understanding Culture Notes 1 CULTURE: AN INTRODUCTION he English word ‘Culture’ is derived from the Latin term ‘cult or cultus’ meaning tilling, or cultivating or refining and worship. In sum it means cultivating and refining Ta thing to such an extent that its end product evokes our admiration and respect. This is practically the same as ‘Sanskriti’ of the Sanskrit language. The term ‘Sanskriti’ has been derived from the root ‘Kri (to do) of Sanskrit language. Three words came from this root ‘Kri; prakriti’ (basic matter or condition), ‘Sanskriti’ (refined matter or condition) and ‘vikriti’ (modified or decayed matter or condition) when ‘prakriti’ or a raw material is refined it becomes ‘Sanskriti’ and when broken or damaged it becomes ‘vikriti’. OBJECTIVES After studying this lesson you will be able to: understand the concept and meaning of culture; establish the relationship between culture and civilization; Establish the link between culture and heritage; discuss the role and impact of culture in human life. 1.1 CONCEPT OF CULTURE Culture is a way of life. The food you eat, the clothes you wear, the language you speak in and the God you worship all are aspects of culture. In very simple terms, we can say that culture is the embodiment of the way in which we think and do things. It is also the things Indian Culture and Heritage Secondary Course 1 MODULE - I Culture: An Introduction Understanding Culture that we have inherited as members of society. All the achievements of human beings as members of social groups can be called culture. -

Building a Word Segmenter for Sanskrit Overnight
Building a Word Segmenter for Sanskrit Overnight Vikas Reddy*1, Amrith Krishna*2, Vishnu Dutt Sharma3, Prateek Gupta4, Vineeth M R5, Pawan Goyal2 1Dept. of Mining Engineering, 2Dept. of Computer Science and Engineering, 4Dept. of Mathematics, 5Dept. of Electrical Engineering, 1,2,4,5IIT Kharagpur 3American Express India Pvt Ltd fvikas.challaram, [email protected], [email protected] Abstract There is abundance of digitised texts available in Sanskrit. However, the word segmentation task in such texts are challenging due to the issue of Sandhi. In Sandhi, words in a sentence often fuse together to form a single chunk of text, where the word delimiter vanishes and sounds at the word boundaries undergo transformations, which is also reflected in the written text. Here, we propose an approach that uses a deep sequence to sequence (seq2seq) model that takes only the sandhied string as the input and predicts the unsandhied string. The state of the art models are linguistically involved and have external dependencies for the lexical and morphological analysis of the input. Our model can be trained “overnight” and be used for production. In spite of the knowledge lean approach, our system preforms better than the current state of the art by gaining a percentage increase of 16.79 % than the current state of the art. Keywords: Word Segmentation, Sanskrit, Low-Resource Languages, Sequence to sequence, seq2seq, Deep Learning 1. Introduction proximity between two compatible sounds as per any one Sanskrit had profound influence as the knowledge preserv- of the 281 rules is the sole criteria for sandhi. -

India Progressive Writers Association; *7:Arxicm
DOCUMENT RESUME ED 124 936 CS 202 742 ccpp-.1a, CsIrlo. Ed. Marxist Influences and South Asaan li-oerazure.South ;:sia Series OcasioLal raper No. 23,Vol. I. Michijar East Lansing. As:,an Studies Center. PUB rAIE -74 NCIE 414. 7ESF ME-$C.8' HC-$11.37 Pius ?cstage. 22SCrIP:0:", *Asian Stud,es; 3engali; *Conference reports; ,,Fiction; Hindi; *Literary Analysis;Literary Genres; = L_tera-y Tnfluences;*Literature; Poetry; Feal,_sm; *Socialism; Urlu All India Progressive Writers Association; *7:arxicm 'ALZT:AL: Ti.'__ locument prasen-ls papers sealing *viithvarious aspects of !',arxi=it 2--= racyinfluence, and more specifically socialisr al sr, ir inlia, Pakistan, "nd Bangladesh.'Included are articles that deal with _Aich subjects a:.the All-India Progressive Associa-lion, creative writers in Urdu,Bengali poets today Inclian poetry iT and socialist realism, socialist real.Lsm anu the Inlion nov-,-1 in English, the novelistMulk raj Anand, the poet Jhaverchan'l Meyhani, aspects of the socialistrealist verse of Sandaram and mash:: }tar Yoshi, *socialistrealism and Hindi novels, socialist realism i: modern pos=y, Mohan Bakesh andsocialist realism, lashpol from tealist to hcmanisc. (72) y..1,**,,A4-1.--*****=*,,,,k**-.4-**--4.*x..******************.=%.****** acg.u.re:1 by 7..-IC include many informalunpublished :Dt ,Ivillable from othr source r.LrIC make::3-4(.--._y effort 'c obtain 1,( ,t c-;;,y ava:lable.fev,?r-rfeless, items of marginal * are oft =.ncolntered and this affects the quality * * -n- a%I rt-irodu::tior:; i:";IC makes availahl 1: not quali-y o: th< original document.reproductiour, ba, made from the original.