No Slide Title
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Chapter 1: Computer Abstractions and Technology 1.6 – 1.7: Performance and Power
Chapter 1: Computer Abstractions and Technology 1.6 – 1.7: Performance and power ITSC 3181 Introduction to Computer Architecture https://passlaB.githuB.io/ITSC3181/ Department of Computer Science Yonghong Yan [email protected] https://passlab.github.io/yanyh/ Lectures for Chapter 1 and C Basics Computer Abstractions and Technology • Lecture 01: Chapter 1 – 1.1 – 1.4: Introduction, great ideas, Moore’s law, aBstraction, computer components, and program execution • Lecture 02: C Basics; Memory and Binary Systems • Lecture 03: Number System, Compilation, Assembly, Linking and Program Execution ☛• Lecture 04: Chapter 1 – 1.6 – 1.7: Performance, power and technology trends • Lecture 05: – 1.8 - 1.9: Multiprocessing and Benchmarking 2 § 1.6 Performance 1.6 Defining Performance • Which airplane has the best performance? Boeing 777 Boeing 777 Boeing 747 Boeing 747 BAC/Sud BAC/Sud Concorde Concorde Douglas Douglas DC- DC-8-50 8-50 0 100 200 300 400 500 0 2000 4000 6000 8000 10000 Passenger Capacity Cruising Range (miles) Boeing 777 Boeing 777 Boeing 747 Boeing 747 BAC/Sud BAC/Sud Concorde Concorde Douglas Douglas DC- DC-8-50 8-50 0 500 1000 1500 0 100000 200000 300000 400000 Cruising Speed (mph) Passengers x mph 3 Response Time and Throughput • Response time çè Latency – How long it takes to do a task • Throughput çè Bandwidth – Total work done per unit time • e.g., tasks/transactions/… per hour • How are response time and throughput affected by – Replacing the processor with a faster version? – Adding more processors? • We’ll focus on response time for now… 4 Relative Performance • Define Performance = 1/Execution Time • “X is n time faster than Y”, i.e. -

Survey of Computer Architecture
Architecture-aware Algorithms and Software for Peta and Exascale Computing Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester 11/17/2010 1 H. Meuer, H. Simon, E. Strohmaier, & JD - Listing of the 500 most powerful Computers in the World - Yardstick: Rmax from LINPACK MPP Ax=b, dense problem TPP performance Rate - Updated twice a year Size SC‘xy in the States in November Meeting in Germany in June - All data available from www.top2 500.org 36rd List: The TOP10 Rmax % of Power Flops/ Rank Site Computer Country Cores [Pflops] Peak [MW] Watt Nat. SuperComputer NUDT YH Cluster, X5670 1 China 186,368 2.57 55 4.04 636 Center in Tianjin 2.93Ghz 6C, NVIDIA GPU DOE / OS Jaguar / Cray 2 USA 224,162 1.76 75 7.0 251 Oak Ridge Nat Lab Cray XT5 sixCore 2.6 GHz Nebulea / Dawning / TC3600 Nat. Supercomputer 3 Blade, Intel X5650, Nvidia China 120,640 1.27 43 2.58 493 Center in Shenzhen C2050 GPU Tusbame 2.0 HP ProLiant GSIC Center, Tokyo 4 SL390s G7 Xeon 6C X5670, Japan 73,278 1.19 52 1.40 850 Institute of Technology Nvidia GPU Hopper, Cray XE6 12-core 5 DOE/SC/LBNL/NERSC USA 153,408 1.054 82 2.91 362 2.1 GHz Commissariat a Tera-100 Bull bullx super- 6 l'Energie Atomique France 138,368 1.050 84 4.59 229 node S6010/S6030 (CEA) DOE / NNSA Roadrunner / IBM 7 USA 122,400 1.04 76 2.35 446 Los Alamos Nat Lab BladeCenter QS22/LS21 NSF / NICS / kyaken/ Cray 8 USA 98,928 .831 81 3.09 269 U of Tennessee Cray XT5 sixCore 2.6 GHz Forschungszentrum Jugene / IBM 9 Germany 294,912 .825 82 2.26 365 Juelich (FZJ) Blue Gene/P Solution DOE/ NNSA / 10 Cray XE6 8-core 2.4 GHz USA 107,152 .817 79 2.95 277 Los Alamos Nat Lab 36rd List: The TOP10 Rmax % of Power Flops/ Rank Site Computer Country Cores [Pflops] Peak [MW] Watt Nat. -
Clock Rate Improves Roughly Proportional to Improvement in L • Number of Transistors Improves Proportional to L2 (Or Faster)
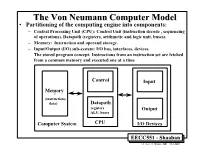
TheThe VonVon NeumannNeumann ComputerComputer ModelModel • Partitioning of the computing engine into components: – Central Processing Unit (CPU): Control Unit (instruction decode , sequencing of operations), Datapath (registers, arithmetic and logic unit, buses). – Memory: Instruction and operand storage. – Input/Output (I/O) sub-system: I/O bus, interfaces, devices. – The stored program concept: Instructions from an instruction set are fetched from a common memory and executed one at a time Control Input Memory - (instructions, data) Datapath registers Output ALU, buses Computer System CPU I/O Devices EECC551 - Shaaban #1 Lec # 1 Winter 2001 12-3-2001 Generic CPU Machine Instruction Execution Steps Instruction Obtain instruction from program storage Fetch Instruction Determine required actions and instruction size Decode Operand Locate and obtain operand data Fetch Execute Compute result value or status Result Deposit results in storage for later use Store Next Determine successor or next instruction Instruction EECC551 - Shaaban #2 Lec # 1 Winter 2001 12-3-2001 HardwareHardware ComponentsComponents ofof AnyAny ComputerComputer Five classic components of all computers: 1. Control Unit; 2. Datapath; 3. Memory; 4. Input; 5. Output } Processor Computer Keyboard, Mouse, etc. Processor Memory Devices (active) (passive) Control Input (where Unit programs, data Disk Datapath live when Output running) Display, Printer, etc. EECC551 - Shaaban #3 Lec # 1 Winter 2001 12-3-2001 CPUCPU OrganizationOrganization • Datapath Design: – Capabilities & performance characteristics of principal Functional Units (FUs): • (e.g., Registers, ALU, Shifters, Logic Units, ...) – Ways in which these components are interconnected (buses connections, multiplexors, etc.). – How information flows between components. • Control Unit Design: – Logic and means by which such information flow is controlled. – Control and coordination of FUs operation to realize the targeted Instruction Set Architecture to be implemented (can either be implemented using a finite state machine or a microprogram). -

Atmega165p Datasheet
Features • High Performance, Low Power Atmel® AVR® 8-Bit Microcontroller • Advanced RISC Architecture – 130 Powerful Instructions – Most Single Clock Cycle Execution – 32 × 8 General Purpose Working Registers – Fully Static Operation – Up to 16 MIPS Throughput at 16 MHz – On-Chip 2-cycle Multiplier • High Endurance Non-volatile Memory segments – 16 Kbytes of In-System Self-programmable Flash program memory – 512 Bytes EEPROM – 1 Kbytes Internal SRAM 8-bit – Write/Erase cyles: 10,000 Flash/100,000 EEPROM(1)(3) – Data retention: 20 years at 85°C/100 years at 25°C(2)(3) Microcontroller – Optional Boot Code Section with Independent Lock Bits In-System Programming by On-chip Boot Program with 16K Bytes True Read-While-Write Operation – Programming Lock for Software Security In-System • JTAG (IEEE std. 1149.1 compliant) Interface – Boundary-scan Capabilities According to the JTAG Standard Programmable – Extensive On-chip Debug Support – Programming of Flash, EEPROM, Fuses, and Lock Bits through the JTAG Interface Flash • Peripheral Features – Two 8-bit Timer/Counters with Separate Prescaler and Compare Mode – One 16-bit Timer/Counter with Separate Prescaler, Compare Mode, and Capture Mode – Real Time Counter with Separate Oscillator –Four PWM Channels ATmega165P – 8-channel, 10-bit ADC – Programmable Serial USART ATmega165PV – Master/Slave SPI Serial Interface – Universal Serial Interface with Start Condition Detector – Programmable Watchdog Timer with Separate On-chip Oscillator – On-chip Analog Comparator Preliminary – Interrupt and Wake-up -

Performance of a Computer (Chapter 4) Vishwani D
ELEC 5200-001/6200-001 Computer Architecture and Design Fall 2013 Performance of a Computer (Chapter 4) Vishwani D. Agrawal & Victor P. Nelson epartment of Electrical and Computer Engineering Auburn University, Auburn, AL 36849 ELEC 5200-001/6200-001 Performance Fall 2013 . Lecture 1 What is Performance? Response time: the time between the start and completion of a task. Throughput: the total amount of work done in a given time. Some performance measures: MIPS (million instructions per second). MFLOPS (million floating point operations per second), also GFLOPS, TFLOPS (1012), etc. SPEC (System Performance Evaluation Corporation) benchmarks. LINPACK benchmarks, floating point computing, used for supercomputers. Synthetic benchmarks. ELEC 5200-001/6200-001 Performance Fall 2013 . Lecture 2 Small and Large Numbers Small Large 10-3 milli m 103 kilo k 10-6 micro μ 106 mega M 10-9 nano n 109 giga G 10-12 pico p 1012 tera T 10-15 femto f 1015 peta P 10-18 atto 1018 exa 10-21 zepto 1021 zetta 10-24 yocto 1024 yotta ELEC 5200-001/6200-001 Performance Fall 2013 . Lecture 3 Computer Memory Size Number bits bytes 210 1,024 K Kb KB 220 1,048,576 M Mb MB 230 1,073,741,824 G Gb GB 240 1,099,511,627,776 T Tb TB ELEC 5200-001/6200-001 Performance Fall 2013 . Lecture 4 Units for Measuring Performance Time in seconds (s), microseconds (μs), nanoseconds (ns), or picoseconds (ps). Clock cycle Period of the hardware clock Example: one clock cycle means 1 nanosecond for a 1GHz clock frequency (or 1GHz clock rate) CPU time = (CPU clock cycles)/(clock rate) Cycles per instruction (CPI): average number of clock cycles used to execute a computer instruction. -

Chap01: Computer Abstractions and Technology
CHAPTER 1 Computer Abstractions and Technology 1.1 Introduction 3 1.2 Eight Great Ideas in Computer Architecture 11 1.3 Below Your Program 13 1.4 Under the Covers 16 1.5 Technologies for Building Processors and Memory 24 1.6 Performance 28 1.7 The Power Wall 40 1.8 The Sea Change: The Switch from Uniprocessors to Multiprocessors 43 1.9 Real Stuff: Benchmarking the Intel Core i7 46 1.10 Fallacies and Pitfalls 49 1.11 Concluding Remarks 52 1.12 Historical Perspective and Further Reading 54 1.13 Exercises 54 CMPS290 Class Notes (Chap01) Page 1 / 24 by Kuo-pao Yang 1.1 Introduction 3 Modern computer technology requires professionals of every computing specialty to understand both hardware and software. Classes of Computing Applications and Their Characteristics Personal computers o A computer designed for use by an individual, usually incorporating a graphics display, a keyboard, and a mouse. o Personal computers emphasize delivery of good performance to single users at low cost and usually execute third-party software. o This class of computing drove the evolution of many computing technologies, which is only about 35 years old! Server computers o A computer used for running larger programs for multiple users, often simultaneously, and typically accessed only via a network. o Servers are built from the same basic technology as desktop computers, but provide for greater computing, storage, and input/output capacity. Supercomputers o A class of computers with the highest performance and cost o Supercomputers consist of tens of thousands of processors and many terabytes of memory, and cost tens to hundreds of millions of dollars. -

JSC News No. 166, July 2008
JUMP Succession two more years. This should provide users No. 166 • July 2008 with sufficient available computing power On 1 July 2008, the new IBM Power6 ma- on the general purpose part and time to mi- chine p6 575 – known as JUMP, just like grate their applications to the new cluster. its predecessor – took over the production (Contact: Klaus Wolkersdorfer, ext. 6579) workload from the previous Power4 clus- ter as scheduled. First benchmark tests show that users can expect their applica- Gauss Alliance Founded tions to run about three times faster on the During the ISC 2008, an agreement was new machine. This factor could even be im- signed to found the Gauss Alliance, which proved by making the most out of the follow- will unite supercomputer forces in Ger- ing Power6 features: many. The Gauss Centre for Supercom- • Simultaneous multi-threading (SMT puting (GCS) and eleven regional and topi- mode): 64 threads (instead of 32) can cal high-performance computer centres are be used on one node, where 2 threads participating in the alliance, thus creating a now share one physical processor with computer association that is unique world- its dedicated memory caches and float- wide. The signatories are: Gauss Cen- ing point units. tre for Supercomputing (GCS), Center for • Medium size virtual memory pages Computing and Communication of RWTH (64K): applications can set 64K pages Aachen University, Norddeutscher Ver- as a default during link time and thus bund für Hoch- und Höchstleistungsrech- can benefit from improved hardware ef- nen (HLRN) consisting of Zuse Institute ficiencies by accessing these pages. -

3Dfx Oral History Panel Gordon Campbell, Scott Sellers, Ross Q. Smith, and Gary M. Tarolli
3dfx Oral History Panel Gordon Campbell, Scott Sellers, Ross Q. Smith, and Gary M. Tarolli Interviewed by: Shayne Hodge Recorded: July 29, 2013 Mountain View, California CHM Reference number: X6887.2013 © 2013 Computer History Museum 3dfx Oral History Panel Shayne Hodge: OK. My name is Shayne Hodge. This is July 29, 2013 at the afternoon in the Computer History Museum. We have with us today the founders of 3dfx, a graphics company from the 1990s of considerable influence. From left to right on the camera-- I'll let you guys introduce yourselves. Gary Tarolli: I'm Gary Tarolli. Scott Sellers: I'm Scott Sellers. Ross Smith: Ross Smith. Gordon Campbell: And Gordon Campbell. Hodge: And so why don't each of you take about a minute or two and describe your lives roughly up to the point where you need to say 3dfx to continue describing them. Tarolli: All right. Where do you want us to start? Hodge: Birth. Tarolli: Birth. Oh, born in New York, grew up in rural New York. Had a pretty uneventful childhood, but excelled at math and science. So I went to school for math at RPI [Rensselaer Polytechnic Institute] in Troy, New York. And there is where I met my first computer, a good old IBM mainframe that we were just talking about before [this taping], with punch cards. So I wrote my first computer program there and sort of fell in love with computer. So I became a computer scientist really. So I took all their computer science courses, went on to Caltech for VLSI engineering, which is where I met some people that influenced my career life afterwards. -

PACKET 7 BOOKSTORE 433 Lecture 5 Dr W IBM OVERVIEW
“PROCESSORS” and multi-processors Excerpt from Hennessey Computer Architecture book; edits by JT Wunderlich PhD Plus Dr W’s IBM Research & Development: JT Wunderlich PhD “PROCESSORS” Excerpt from Hennessey Computer Architecture book; edits by JT Wunderlich PhD Historical Perspective and Further 7.14 Reading There is a tremendous amount of history in multiprocessors; in this section we divide our discussion by both time period and architecture. We start with the SIMD SIMD=SinGle approach and the Illiac IV. We then turn to a short discussion of some other early experimental multiprocessors and progress to a discussion of some of the great Instruction, debates in parallel processing. Next we discuss the historical roots of the present multiprocessors and conclude by discussing recent advances. Multiple Data SIMD Computers: Attractive Idea, Many Attempts, No Lasting Successes The cost of a general multiprocessor is, however, very high and further design options were considered which would decrease the cost without seriously degrading the power or efficiency of the system. The options consist of recentralizing one of the three major components. Centralizing the [control unit] gives rise to the basic organization of [an] . array processor such as the Illiac IV. Bouknight, et al.[1972] The SIMD model was one of the earliest models of parallel computing, dating back to the first large-scale multiprocessor, the Illiac IV. The key idea in that multiprocessor, as in more recent SIMD multiprocessors, is to have a single instruc- tion that operates on many data items at once, using many functional units (see Figure 7.14.1). Although successful in pushing several technologies that proved useful in later projects, it failed as a computer. -

Distance Learning
Computing Service kekekeyyynotesnotesnotes Volume 25 Number 3 January 1999 Distance Learning Also in this Issue: Managed UNIX Workstations MIS News RALPHY 1 kkeeyynotesnotes Volume 25, Number 3 From the Editor Chris Joy explains the procedures by contents which the Computing Service is able to manage UNIX workstations on behalf of users, removing this burden news in brief from them. Turn to page 2 for more Windows 95 Login Problems 1 details. King's Manor Update 1 ❖❖❖ New National Service Computing Resources 1 On page 6, Gareth Johnson writes news about RALPHY, the Library's Managing UNIX Workstations 2 electronic reserve project, which is Distance Learning 3 providing students, on and off campus, with improved access to a mis range of publications. York Skills Management System 4 ❖❖❖ Postgraduate Degree Certificate Production 4 New Tuition Fees: New Software 5 Opposite, John Robinson details the Syllabus Plus 5 national computing services library available to academics within RALPHY 6 higher education. ❖❖❖ Finally, best wishes for the New Year. And keep an eye on the Millennium Countdown... Joanne Casey Information Officer millennium countdown 51 weeks to go! Are you prepared? See http:// www.york.ac.uk/services/cserv/offdocs/ y2k.htm for further information. 2 news brief in Windows 95 Login Problems Andrew Smith Since the start of last term, we have vicinity, could you please report it to (network, filestore, etc), it sometimes had a number of problems with users the Infodesk. It is a simple matter to takes a while to diagnose a fault not being able to login to an office or pick up the phone and leave a message report which may initially point to a classroom Windows 95 PC. -

Online Sec 6.15.Indd
6.155.9 Historical Perspective and Further Reading Th ere is a tremendous amount of history in multiprocessors; in this section we divide our discussion by both time period and architecture. We start with the SIMD approach and the Illiac IV. We then turn to a short discussion of some other early experimental multiprocessors and progress to a discussion of some of the great debates in parallel processing. Next we discuss the historical roots of the present multiprocessors and conclude by discussing recent advances. SIMD Computers: Attractive Idea, Many Attempts, No Lasting Successes Th e cost of a general multiprocessor is, however, very high and further design options were considered which would decrease the cost without seriously degrading the power or effi ciency of the system. Th e options consist of recentralizing one of the three major components. Centralizing the [control unit] gives rise to the basic organization of [an] . array processor such as the Illiac IV. Bouknight et al. [1972] Th e SIMD model was one of the earliest models of parallel computing, dating back to the fi rst large-scale multiprocessor, the Illiac IV. Th e key idea in that multiprocessor, as in more recent SIMD multiprocessors, is to have a single instruction that operates on many data items at once, using many functional units (see Figure 6.15.1). Although successful in pushing several technologies that proved useful in later projects, it failed as a computer. Costs escalated from the $8 million estimate in 1966 to $31 million by 1972, despite construction of only a quarter of the planned multiprocessor. -

Data Warehousing on the Cray CS6400: Oracle's Test-To-Scale Benchmark
Data Warehousing on the Cray CS6400: Oracle's Test-to-Scale Benchmark Brad Carlile, Cray Research, Inc., Business Systems Division 1 INTRODUCTION largest Oracle Database in terms of both data volume and number of rows. Several different queries were run on this data- Consolidating enterprise-wide data located in disparate data- base to demonstrate full table scan and aggregate performance. bases into a data warehouse provides an opportunity for many This was a test to demonstrate the high capacity of the Oracle7 companies to develop a competitive advantage. Data ware- database. A single large table was created to serve as a stress houses are large repositories of corporate data that can often test of the databases internal structures. The database schema require Terabytes of data storage. Decision Support System was based on the Wisconsin benchmark schema. (DSS) is the complete system used to learn more about this data This paper presents Cray's results on the Test-to-Scale within the warehouse and highlight previously un-explored rela- benchmark demonstrating high performance, linear scaleup, tionships in large databases. Finding the important data in a data and excellent scalability on a very large database. The CS6400 warehouse involves the judicious use of detail data, summarized is Cray's SPARC-based SMP System that runs the Solaris 2.4 data, and meta-data (data about the data). Summary data can operating system and is fully SPARC binary compatible. The dramatically speed important basic queries but often this must combination of the CS6400 and the parallel features of Oracle7 be balanced with being able to explore all the detail data without provide scaleable performance for DSS operations on databases losing information due to over-summarization.