Pan-Cancer Molecular Subtypes Revealed by Mass-Spectrometry
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Supplementary Methods
SUPPLEMENTARY METHODS Epilepsy cohorts Epilepsy cohorts contributing to the meta-analysis are detailed below. EPIGEN (Reported by – Chantal Depondt, Sanjay Sisodiya, Norman Delanty, Gianpiero Cavalleri, Erin Heinzen and David Goldstein) The EPIGEN study consisted of epilepsy cohorts from Beaumont Hospital Dublin (Ireland), Université Libre de Bruxelles (ULB, Belgium), Duke University Medical Centre (North Carolina, USA) and University College Hospital London (UK). Inclusion Criteria: Except for Duke, only adult (>16 years) patients with epilepsy were recruited. Exclusion Criteria: No specific exclusion criteria. Quality assurance: At all sites, subjects were recruited and phenotyped by experienced epilepsy specialists. At Duke, all cases underwent independent case-record review by an epilepsy nurse specialist, and ambiguous diagnoses were re-evaluated by a second epileptologist. If the diagnosis remained unclear, then the patient was excluded from the study. For London, all cases underwent review by independent epileptologists. For Brussels, study PI (Chantal Depondt) reviewed the classification of all cases by case-note review. For Dublin, no systematic quality assurance was undertaken. Site-specific details for each EPIGEN cohort as organized for the analysis are as follows: – EPIGEN-Dublin Patients were recruited from a specialized epilepsy clinic at Beaumont Hospital, Dublin, Ireland. Patients were mostly of Irish ethnicity. Patients were genotyped on the Illumina platform using a combination of chips (610-Quad+550+300v1/Omni1-Quad). – EPIGEN-Brussels Patients were recruited from epilepsy clinics at UZ Gasthuisberg, Katholieke Universiteit Leuven, and Hôpital Erasme, Université Libre de Bruxelles. Patients were largely of Belgian ethnicity. Patients were genotyped on the Illumina platform using a combination of chips (610-Quad/300 V1 & V2). -

Analysis of Gene Expression Data for Gene Ontology
ANALYSIS OF GENE EXPRESSION DATA FOR GENE ONTOLOGY BASED PROTEIN FUNCTION PREDICTION A Thesis Presented to The Graduate Faculty of The University of Akron In Partial Fulfillment of the Requirements for the Degree Master of Science Robert Daniel Macholan May 2011 ANALYSIS OF GENE EXPRESSION DATA FOR GENE ONTOLOGY BASED PROTEIN FUNCTION PREDICTION Robert Daniel Macholan Thesis Approved: Accepted: _______________________________ _______________________________ Advisor Department Chair Dr. Zhong-Hui Duan Dr. Chien-Chung Chan _______________________________ _______________________________ Committee Member Dean of the College Dr. Chien-Chung Chan Dr. Chand K. Midha _______________________________ _______________________________ Committee Member Dean of the Graduate School Dr. Yingcai Xiao Dr. George R. Newkome _______________________________ Date ii ABSTRACT A tremendous increase in genomic data has encouraged biologists to turn to bioinformatics in order to assist in its interpretation and processing. One of the present challenges that need to be overcome in order to understand this data more completely is the development of a reliable method to accurately predict the function of a protein from its genomic information. This study focuses on developing an effective algorithm for protein function prediction. The algorithm is based on proteins that have similar expression patterns. The similarity of the expression data is determined using a novel measure, the slope matrix. The slope matrix introduces a normalized method for the comparison of expression levels throughout a proteome. The algorithm is tested using real microarray gene expression data. Their functions are characterized using gene ontology annotations. The results of the case study indicate the protein function prediction algorithm developed is comparable to the prediction algorithms that are based on the annotations of homologous proteins. -

Identification of the Binding Partners for Hspb2 and Cryab Reveals
Brigham Young University BYU ScholarsArchive Theses and Dissertations 2013-12-12 Identification of the Binding arP tners for HspB2 and CryAB Reveals Myofibril and Mitochondrial Protein Interactions and Non- Redundant Roles for Small Heat Shock Proteins Kelsey Murphey Langston Brigham Young University - Provo Follow this and additional works at: https://scholarsarchive.byu.edu/etd Part of the Microbiology Commons BYU ScholarsArchive Citation Langston, Kelsey Murphey, "Identification of the Binding Partners for HspB2 and CryAB Reveals Myofibril and Mitochondrial Protein Interactions and Non-Redundant Roles for Small Heat Shock Proteins" (2013). Theses and Dissertations. 3822. https://scholarsarchive.byu.edu/etd/3822 This Thesis is brought to you for free and open access by BYU ScholarsArchive. It has been accepted for inclusion in Theses and Dissertations by an authorized administrator of BYU ScholarsArchive. For more information, please contact [email protected], [email protected]. Identification of the Binding Partners for HspB2 and CryAB Reveals Myofibril and Mitochondrial Protein Interactions and Non-Redundant Roles for Small Heat Shock Proteins Kelsey Langston A thesis submitted to the faculty of Brigham Young University in partial fulfillment of the requirements for the degree of Master of Science Julianne H. Grose, Chair William R. McCleary Brian Poole Department of Microbiology and Molecular Biology Brigham Young University December 2013 Copyright © 2013 Kelsey Langston All Rights Reserved ABSTRACT Identification of the Binding Partners for HspB2 and CryAB Reveals Myofibril and Mitochondrial Protein Interactors and Non-Redundant Roles for Small Heat Shock Proteins Kelsey Langston Department of Microbiology and Molecular Biology, BYU Master of Science Small Heat Shock Proteins (sHSP) are molecular chaperones that play protective roles in cell survival and have been shown to possess chaperone activity. -

Transcriptional Regulation of RKIP in Prostate Cancer Progression
Health Science Campus FINAL APPROVAL OF DISSERTATION Doctor of Philosophy in Biomedical Sciences Transcriptional Regulation of RKIP in Prostate Cancer Progression Submitted by: Sandra Marie Beach In partial fulfillment of the requirements for the degree of Doctor of Philosophy in Biomedical Sciences Examination Committee Major Advisor: Kam Yeung, Ph.D. Academic William Maltese, Ph.D. Advisory Committee: Sonia Najjar, Ph.D. Han-Fei Ding, M.D., Ph.D. Manohar Ratnam, Ph.D. Senior Associate Dean College of Graduate Studies Michael S. Bisesi, Ph.D. Date of Defense: May 16, 2007 Transcriptional Regulation of RKIP in Prostate Cancer Progression Sandra Beach University of Toledo ACKNOWLDEGMENTS I thank my major advisor, Dr. Kam Yeung, for the opportunity to pursue my degree in his laboratory. I am also indebted to my advisory committee members past and present, Drs. Sonia Najjar, Han-Fei Ding, Manohar Ratnam, James Trempe, and Douglas Pittman for generously and judiciously guiding my studies and sharing reagents and equipment. I owe extended thanks to Dr. William Maltese as a committee member and chairman of my department for supporting my degree progress. The entire Department of Biochemistry and Cancer Biology has been most kind and helpful to me. Drs. Roy Collaco and Hong-Juan Cui have shared their excellent technical and practical advice with me throughout my studies. I thank members of the Yeung laboratory, Dr. Sungdae Park, Hui Hui Tang, Miranda Yeung for their support and collegiality. The data mining studies herein would not have been possible without the helpful advice of Dr. Robert Trumbly. I am also grateful for the exceptional assistance and shared microarray data of Dr. -

Seq2pathway Vignette
seq2pathway Vignette Bin Wang, Xinan Holly Yang, Arjun Kinstlick May 19, 2021 Contents 1 Abstract 1 2 Package Installation 2 3 runseq2pathway 2 4 Two main functions 3 4.1 seq2gene . .3 4.1.1 seq2gene flowchart . .3 4.1.2 runseq2gene inputs/parameters . .5 4.1.3 runseq2gene outputs . .8 4.2 gene2pathway . 10 4.2.1 gene2pathway flowchart . 11 4.2.2 gene2pathway test inputs/parameters . 11 4.2.3 gene2pathway test outputs . 12 5 Examples 13 5.1 ChIP-seq data analysis . 13 5.1.1 Map ChIP-seq enriched peaks to genes using runseq2gene .................... 13 5.1.2 Discover enriched GO terms using gene2pathway_test with gene scores . 15 5.1.3 Discover enriched GO terms using Fisher's Exact test without gene scores . 17 5.1.4 Add description for genes . 20 5.2 RNA-seq data analysis . 20 6 R environment session 23 1 Abstract Seq2pathway is a novel computational tool to analyze functional gene-sets (including signaling pathways) using variable next-generation sequencing data[1]. Integral to this tool are the \seq2gene" and \gene2pathway" components in series that infer a quantitative pathway-level profile for each sample. The seq2gene function assigns phenotype-associated significance of genomic regions to gene-level scores, where the significance could be p-values of SNPs or point mutations, protein-binding affinity, or transcriptional expression level. The seq2gene function has the feasibility to assign non-exon regions to a range of neighboring genes besides the nearest one, thus facilitating the study of functional non-coding elements[2]. Then the gene2pathway summarizes gene-level measurements to pathway-level scores, comparing the quantity of significance for gene members within a pathway with those outside a pathway. -

Transcriptomic Analysis of the Aquaporin (AQP) Gene Family
Pancreatology 19 (2019) 436e442 Contents lists available at ScienceDirect Pancreatology journal homepage: www.elsevier.com/locate/pan Transcriptomic analysis of the Aquaporin (AQP) gene family interactome identifies a molecular panel of four prognostic markers in patients with pancreatic ductal adenocarcinoma Dimitrios E. Magouliotis a, b, Vasiliki S. Tasiopoulou c, Konstantinos Dimas d, * Nikos Sakellaridis d, Konstantina A. Svokos e, Alexis A. Svokos f, Dimitris Zacharoulis b, a Division of Surgery and Interventional Science, Faculty of Medical Sciences, UCL, London, UK b Department of Surgery, University of Thessaly, Biopolis, Larissa, Greece c Faculty of Medicine, School of Health Sciences, University of Thessaly, Biopolis, Larissa, Greece d Department of Pharmacology, Faculty of Medicine, School of Health Sciences, University of Thessaly, Biopolis, Larissa, Greece e The Warren Alpert Medical School of Brown University, Providence, RI, USA f Riverside Regional Medical Center, Newport News, VA, USA article info abstract Article history: Background: This study aimed to assess the differential gene expression of aquaporin (AQP) gene family Received 14 October 2018 interactome in pancreatic ductal adenocarcinoma (PDAC) using data mining techniques to identify novel Received in revised form candidate genes intervening in the pathogenicity of PDAC. 29 January 2019 Method: Transcriptome data mining techniques were used in order to construct the interactome of the Accepted 9 February 2019 AQP gene family and to determine which genes members are differentially expressed in PDAC as Available online 11 February 2019 compared to controls. The same techniques were used in order to evaluate the potential prognostic role of the differentially expressed genes. Keywords: PDAC Results: Transcriptome microarray data of four GEO datasets were incorporated, including 142 primary Aquaporin tumor samples and 104 normal pancreatic tissue samples. -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -

Supplementary Materials
1 Supplementary Materials: Supplemental Figure 1. Gene expression profiles of kidneys in the Fcgr2b-/- and Fcgr2b-/-. Stinggt/gt mice. (A) A heat map of microarray data show the genes that significantly changed up to 2 fold compared between Fcgr2b-/- and Fcgr2b-/-. Stinggt/gt mice (N=4 mice per group; p<0.05). Data show in log2 (sample/wild-type). 2 Supplemental Figure 2. Sting signaling is essential for immuno-phenotypes of the Fcgr2b-/-lupus mice. (A-C) Flow cytometry analysis of splenocytes isolated from wild-type, Fcgr2b-/- and Fcgr2b-/-. Stinggt/gt mice at the age of 6-7 months (N= 13-14 per group). Data shown in the percentage of (A) CD4+ ICOS+ cells, (B) B220+ I-Ab+ cells and (C) CD138+ cells. Data show as mean ± SEM (*p < 0.05, **p<0.01 and ***p<0.001). 3 Supplemental Figure 3. Phenotypes of Sting activated dendritic cells. (A) Representative of western blot analysis from immunoprecipitation with Sting of Fcgr2b-/- mice (N= 4). The band was shown in STING protein of activated BMDC with DMXAA at 0, 3 and 6 hr. and phosphorylation of STING at Ser357. (B) Mass spectra of phosphorylation of STING at Ser357 of activated BMDC from Fcgr2b-/- mice after stimulated with DMXAA for 3 hour and followed by immunoprecipitation with STING. (C) Sting-activated BMDC were co-cultured with LYN inhibitor PP2 and analyzed by flow cytometry, which showed the mean fluorescence intensity (MFI) of IAb expressing DC (N = 3 mice per group). 4 Supplemental Table 1. Lists of up and down of regulated proteins Accession No. -

Protein Identities in Evs Isolated from U87-MG GBM Cells As Determined by NG LC-MS/MS
Protein identities in EVs isolated from U87-MG GBM cells as determined by NG LC-MS/MS. No. Accession Description Σ Coverage Σ# Proteins Σ# Unique Peptides Σ# Peptides Σ# PSMs # AAs MW [kDa] calc. pI 1 A8MS94 Putative golgin subfamily A member 2-like protein 5 OS=Homo sapiens PE=5 SV=2 - [GG2L5_HUMAN] 100 1 1 7 88 110 12,03704523 5,681152344 2 P60660 Myosin light polypeptide 6 OS=Homo sapiens GN=MYL6 PE=1 SV=2 - [MYL6_HUMAN] 100 3 5 17 173 151 16,91913397 4,652832031 3 Q6ZYL4 General transcription factor IIH subunit 5 OS=Homo sapiens GN=GTF2H5 PE=1 SV=1 - [TF2H5_HUMAN] 98,59 1 1 4 13 71 8,048185945 4,652832031 4 P60709 Actin, cytoplasmic 1 OS=Homo sapiens GN=ACTB PE=1 SV=1 - [ACTB_HUMAN] 97,6 5 5 35 917 375 41,70973209 5,478027344 5 P13489 Ribonuclease inhibitor OS=Homo sapiens GN=RNH1 PE=1 SV=2 - [RINI_HUMAN] 96,75 1 12 37 173 461 49,94108966 4,817871094 6 P09382 Galectin-1 OS=Homo sapiens GN=LGALS1 PE=1 SV=2 - [LEG1_HUMAN] 96,3 1 7 14 283 135 14,70620005 5,503417969 7 P60174 Triosephosphate isomerase OS=Homo sapiens GN=TPI1 PE=1 SV=3 - [TPIS_HUMAN] 95,1 3 16 25 375 286 30,77169764 5,922363281 8 P04406 Glyceraldehyde-3-phosphate dehydrogenase OS=Homo sapiens GN=GAPDH PE=1 SV=3 - [G3P_HUMAN] 94,63 2 13 31 509 335 36,03039959 8,455566406 9 Q15185 Prostaglandin E synthase 3 OS=Homo sapiens GN=PTGES3 PE=1 SV=1 - [TEBP_HUMAN] 93,13 1 5 12 74 160 18,68541938 4,538574219 10 P09417 Dihydropteridine reductase OS=Homo sapiens GN=QDPR PE=1 SV=2 - [DHPR_HUMAN] 93,03 1 1 17 69 244 25,77302971 7,371582031 11 P01911 HLA class II histocompatibility antigen, -
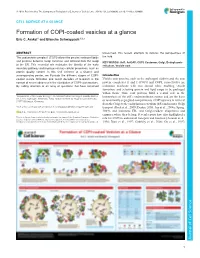
Formation of COPI-Coated Vesicles at a Glance Eric C
© 2018. Published by The Company of Biologists Ltd | Journal of Cell Science (2018) 131, jcs209890. doi:10.1242/jcs.209890 CELL SCIENCE AT A GLANCE Formation of COPI-coated vesicles at a glance Eric C. Arakel1 and Blanche Schwappach1,2,* ABSTRACT unresolved, this review attempts to refocus the perspectives of The coat protein complex I (COPI) allows the precise sorting of lipids the field. and proteins between Golgi cisternae and retrieval from the Golgi KEY WORDS: Arf1, ArfGAP, COPI, Coatomer, Golgi, Endoplasmic to the ER. This essential role maintains the identity of the early reticulum, Vesicle coat secretory pathway and impinges on key cellular processes, such as protein quality control. In this Cell Science at a Glance and accompanying poster, we illustrate the different stages of COPI- Introduction coated vesicle formation and revisit decades of research in the Vesicle coat proteins, such as the archetypal clathrin and the coat context of recent advances in the elucidation of COPI coat structure. protein complexes II and I (COPII and COPI, respectively) are By calling attention to an array of questions that have remained molecular machines with two central roles: enabling vesicle formation, and selecting protein and lipid cargo to be packaged within them. Thus, coat proteins fulfil a central role in the 1Department of Molecular Biology, Universitätsmedizin Göttingen, Humboldtallee homeostasis of the cell’s endomembrane system and are the basis 23, 37073 Göttingen, Germany. 2Max-Planck Institute for Biophysical Chemistry, 37077 Göttingen, Germany. of functionally segregated compartments. COPI operates in retrieval from the Golgi to the endoplasmic reticulum (ER) and in intra-Golgi *Author for correspondence ([email protected]) transport (Beck et al., 2009; Duden, 2003; Lee et al., 2004a; Spang, E.C.A., 0000-0001-7716-7149; B.S., 0000-0003-0225-6432 2009), and maintains ER- and Golgi-resident chaperones and enzymes where they belong. -

Essential Genes and Their Role in Autism Spectrum Disorder
University of Pennsylvania ScholarlyCommons Publicly Accessible Penn Dissertations 2017 Essential Genes And Their Role In Autism Spectrum Disorder Xiao Ji University of Pennsylvania, [email protected] Follow this and additional works at: https://repository.upenn.edu/edissertations Part of the Bioinformatics Commons, and the Genetics Commons Recommended Citation Ji, Xiao, "Essential Genes And Their Role In Autism Spectrum Disorder" (2017). Publicly Accessible Penn Dissertations. 2369. https://repository.upenn.edu/edissertations/2369 This paper is posted at ScholarlyCommons. https://repository.upenn.edu/edissertations/2369 For more information, please contact [email protected]. Essential Genes And Their Role In Autism Spectrum Disorder Abstract Essential genes (EGs) play central roles in fundamental cellular processes and are required for the survival of an organism. EGs are enriched for human disease genes and are under strong purifying selection. This intolerance to deleterious mutations, commonly observed haploinsufficiency and the importance of EGs in pre- and postnatal development suggests a possible cumulative effect of deleterious variants in EGs on complex neurodevelopmental disorders. Autism spectrum disorder (ASD) is a heterogeneous, highly heritable neurodevelopmental syndrome characterized by impaired social interaction, communication and repetitive behavior. More and more genetic evidence points to a polygenic model of ASD and it is estimated that hundreds of genes contribute to ASD. The central question addressed in this dissertation is whether genes with a strong effect on survival and fitness (i.e. EGs) play a specific oler in ASD risk. I compiled a comprehensive catalog of 3,915 mammalian EGs by combining human orthologs of lethal genes in knockout mice and genes responsible for cell-based essentiality. -

Supplementary Figures 1-14 and Supplementary References
SUPPORTING INFORMATION Spatial Cross-Talk Between Oxidative Stress and DNA Replication in Human Fibroblasts Marko Radulovic,1,2 Noor O Baqader,1 Kai Stoeber,3† and Jasminka Godovac-Zimmermann1* 1Division of Medicine, University College London, Center for Nephrology, Royal Free Campus, Rowland Hill Street, London, NW3 2PF, UK. 2Insitute of Oncology and Radiology, Pasterova 14, 11000 Belgrade, Serbia 3Research Department of Pathology and UCL Cancer Institute, Rockefeller Building, University College London, University Street, London WC1E 6JJ, UK †Present Address: Shionogi Europe, 33 Kingsway, Holborn, London WC2B 6UF, UK TABLE OF CONTENTS 1. Supplementary Figures 1-14 and Supplementary References. Figure S-1. Network and joint spatial razor plot for 18 enzymes of glycolysis and the pentose phosphate shunt. Figure S-2. Correlation of SILAC ratios between OXS and OAC for proteins assigned to the SAME class. Figure S-3. Overlap matrix (r = 1) for groups of CORUM complexes containing 19 proteins of the 49-set. Figure S-4. Joint spatial razor plots for the Nop56p complex and FIB-associated complex involved in ribosome biogenesis. Figure S-5. Analysis of the response of emerin nuclear envelope complexes to OXS and OAC. Figure S-6. Joint spatial razor plots for the CCT protein folding complex, ATP synthase and V-Type ATPase. Figure S-7. Joint spatial razor plots showing changes in subcellular abundance and compartmental distribution for proteins annotated by GO to nucleocytoplasmic transport (GO:0006913). Figure S-8. Joint spatial razor plots showing changes in subcellular abundance and compartmental distribution for proteins annotated to endocytosis (GO:0006897). Figure S-9. Joint spatial razor plots for 401-set proteins annotated by GO to small GTPase mediated signal transduction (GO:0007264) and/or GTPase activity (GO:0003924).