N3883 Revised Proposal to Encode the Khojki Script in ISO/IEC 10646
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

DSU Music Newsletter
Delaware State University Music Department Spring 2018 Music Department Schedule Tues., Mar. 20, 11am: Music Performance Seminar (Theater) Volume 2: Issue 1 Fall 2018 Tues., Mar. 27, 11am: Music Performance Seminar (Theater) Concert choir to perform with Philadelphia orchestra Friday, April 6, 7:00 PM: Junior Recital; Devin Davis, Tenor, Anyre’ Frazier, Alto, On March 28, 29, and 30 of 2019, Tommia Proctor, Soprano (Dover Presbyterian Church) the Delaware State University Concert Choir under the direction of Saturday, April 7, 5:00 PM: Senior Capstone Recital; William Wicks, Tenor (Dover Presbyterian Church) Dr. Lloyd Mallory, Jr. will once again be joining the Philadelphia Sunday, April 8, 4:00 PM: Orchestra. The choir will be Senior Capstone Recital; Michele Justice, Soprano (Dover Presbyterian Church) performing the world premiere of Healing Tones, by the Orchestra’s Tuesday, April 10, 11:00 AM: Percussion Studio Performance Seminar (EH Theater) composer-in-residence Hannibal Lokumbe. In November of 2015 the Sunday, April 15, 4:00 PM: Delaware State University Choir Senior Capstone Recital; Marquita Richardson, Soprano (Dover Presbyterian Church) joined the Philadelphia Orchestra to Tuesday, April 17, 11:00 AM: DSU – A place where dreams begin perform the world premiere of Guest Speaker, Dr. Adrian Barnes, Rowan University (Music Hannibal’s One Land, One River, One Education/Bands) (EH 138) People. About the performance, the Friday, April 20, 12:30 PM: Philadelphia Inquirer said “The massed voices of the Delaware State University Choir, the Lincoln Honors Day, Honors Recital (EH Theater) University Concert Choir, and Morgan State University Choir sang with spirit, accuracy and, near- Friday, April 20, 7:00 PM: More inside! Pg. -

The Origins, Evolution and Decline of the Khojki Script
The origins, evolution and decline of the Khojki script Juan Bruce The origins, evolution and decline of the Khojki script Juan Bruce Dissertation submitted in partial fulfilment of the requirements for the Master of Arts in Typeface Design, University of Reading, 2015. 5 Abstract The Khojki script is an Indian script whose origins are in Sindh (now southern Pakistan), a region that has witnessed the conflict between Islam and Hinduism for more than 1,200 years. After the gradual occupation of the region by Muslims from the 8th century onwards, the region underwent significant cultural changes. This dissertation reviews the history of the script and the different uses that it took on among the Khoja people since Muslim missionaries began their activities in Sindh communities in the 14th century. It questions the origins of the Khojas and exposes the impact that their transition from a Hindu merchant caste to a broader Muslim community had on the development of the script. During this process of transformation, a rich and complex creed, known as Satpanth, resulted from the blend of these cultures. The study also considers the roots of the Khojki writing system, especially the modernization that the script went through in order to suit more sophisticated means of expression. As a result, through recording the religious Satpanth literature, Khojki evolved and left behind its mercantile features, insufficient for this purpose. Through comparative analysis of printed Khojki texts, this dissertation examines the use of the script in Bombay at the beginning of the 20th century in the shape of Khoja Ismaili literature. -

WG2 M52 Minutes
ISO.IEC JTC 1/SC 2 N____ ISO/IEC JTC 1/SC 2/WG 2 N3603 2009-07-08 ISO/IEC JTC 1/SC 2/WG 2 Universal Multiple-Octet Coded Character Set (UCS) - ISO/IEC 10646 Secretariat: ANSI DOC TYPE: Meeting Minutes TITLE: Unconfirmed minutes of WG 2 meeting 54 Room S206/S209, Dublin Centre University, Dublin, Ireland 2009-04-20/24 SOURCE: V.S. Umamaheswaran, Recording Secretary, and Mike Ksar, Convener PROJECT: JTC 1.02.18 – ISO/IEC 10646 STATUS: SC 2/WG 2 participants are requested to review the attached unconfirmed minutes, act on appropriate noted action items, and to send any comments or corrections to the convener as soon as possible but no later than the Due Date below. ACTION ID: ACT DUE DATE: 2009-10-12 DISTRIBUTION: SC 2/WG 2 members and Liaison organizations MEDIUM: Acrobat PDF file NO. OF PAGES: 60 (including cover sheet) Michael Y. Ksar Convener – ISO/IEC/JTC 1/SC 2/WG 2 22680 Alcalde Rd Phone: +1 408 255-1217 Cupertino, CA 95014 Email: [email protected] U.S.A. ISO International Organization for Standardization Organisation Internationale de Normalisation ISO/IEC JTC 1/SC 2/WG 2 Universal Multiple-Octet Coded Character Set (UCS) ISO/IEC JTC 1/SC 2 N____ ISO/IEC JTC 1/SC 2/WG 2 N3603 2009-07-08 Title: Unconfirmed minutes of WG 2 meeting 54 Room S206/S209, Dublin Centre University, Dublin, Ireland; 2009-04-20/24 Source: V.S. Umamaheswaran ([email protected]), Recording Secretary Mike Ksar ([email protected]), Convener Action: WG 2 members and Liaison organizations Distribution: ISO/IEC JTC 1/SC 2/WG 2 members and liaison organizations 1 Opening Input document: 3573 2nd Call Meeting # 54 in Dublin; Mike Ksar; 2009-02-16 Mr. -

N3596 Proposal to Encode the Khojki Script in ISO/IEC 10646
ISO/IEC JTC1/SC2/WG2 N3596 L2/09-101 2009-03-25 Proposal to Encode the Khojki Script in ISO/IEC 10646 Anshuman Pandey University of Michigan Ann Arbor, Michigan, U.S.A. [email protected] March 25, 2009 Contents Proposal Summary Form i 1 Introduction 1 2 Background 1 3 Characters Proposed 5 3.1 Character Set . 5 3.2 Basis for Character Set and Glyph Shapes . 6 3.3 Characters Not Proposed . 8 4 The Writing System 10 4.1 General Features . 10 4.2 Inadequacies of the Script . 10 4.3 Supression of Inherent Vowel . 11 4.4 Consonant-Vowel Ligatures . 11 4.5 Consonant Conjuncts . 12 4.6 Nasalization . 13 4.7 Consonant Gemination . 13 4.8 Creation of New Characters . 13 4.9 Punctuation . 14 4.10 Abbreviations . 15 4.11 Number Forms and Unit Marks . 16 4.12 Variant Forms of Characters . 16 5 Implementation 16 5.1 Encoding Model . 16 5.2 Collation . 16 5.3 Character Properties . 17 5.4 Outstanding Issues . 18 6 References 19 List of Tables 1 Glyph chart for Khojki . 2 2 Names list for Khojki . 3 3 Transliteration of Khojki characters and Sindhi-Arabic analogues . 4 List of Figures 1 Inventory of Khojki vowel letters from Grierson (1905) . 20 2 Inventory of Khojki consonant letters from Grierson (1905) . 21 3 Inventory of Khojki consonant letters from Grierson (1905) . 22 4 Inventory of Khojki independent vowel letters from Asani (1992) . 23 5 Inventory of Khojki dependent vowel signs from Asani (1992) . 24 6 Inventory of Khojki consonants (b to dy) from Asani (1992) . -
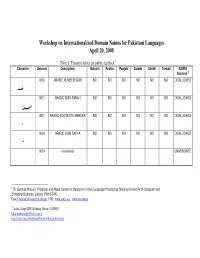
Workshop on Internationalized Domain Names for Pakistani Languages April 20, 2008
Workshop on Internationalized Domain Names for Pakistani Languages April 20, 2008 Table 1: Tentative tables for public feedback 1 Character Unicode Description Balochi Pashto Punjabi Saraiki Sindhi Torwali ASIWG Decision 2 0600 ARABIC NUMBER SIGN NO NO NO NO NO NO DISALLOWED 0601 ARABIC SIGN SANAH NO NO NO NO NO NO DISALLOWED 0601 ARABIC FOOTNOTE MARKER NO NO NO NO NO NO DISALLOWED 0603 ARABIC SIGN SAFHA NO NO NO NO NO NO DISALLOWED 0604 <reserved> UNASSIGNED 1 Dr. Sarmad Hussain, Professor and Head, Center for Research in Urdu Language Processing, National University of Computer and Emerging Sciences, Lahore, PAKISTAN. Email: [email protected] , URL: www.crulp.org , www.nu.edu.pk 2 Arabic Script IDN Working Group (ASIWG) [email protected] http://lists.irnic.ir/mailman/listinfo/idna-arabicscript 0605 <reserved> UNASSIGNED 0606 ARABIC-INDIC CUBE ROOT NO NO NO NO NO NO DISALLOWED 0607 ARABIC-INDIC FOURTH NO NO NO NO NO NO DISALLOWED ROOT 0608 ARABIC RAY NO NO NO NO NO NO DISALLOWED 0609 ARABIC-INDIC PER MILLE NO NO NO NO NO NO DISALLOWED SIGN 060A ARABIC-INDIC PER TEN NO NO NO NO NO NO DISALLOWED THOUSAND SIGN 060B AFGHANI SIGN NO NO NO NO NO NO DISALLOWED 060C ARABIC COMMA NO NO NO NO NO NO DISALLOWED 060D ARABIC DATE SEPARATOR NO NO NO NO NO NO DISALLOWED ؍ 060E ARABIC POETIC VERSE SIGN NO NO NO NO NO NO DISALLOWED ؎ 060F ARABIC SIGN MISRA NO NO NO NO NO NO DISALLOWED ؏ 0610 ARABIC SIGN SALLALLAHOU PENDING PENDING PENDING PENDING PENDING PENDING PVALID ALAYHE WASSALLAM 0611 ARABIC SIGN ALAYHE PENDING PENDING -

Unicode Alphabets for L ATEX
Unicode Alphabets for LATEX Specimen Mikkel Eide Eriksen March 11, 2020 2 Contents MUFI 5 SIL 21 TITUS 29 UNZ 117 3 4 CONTENTS MUFI Using the font PalemonasMUFI(0) from http://mufi.info/. Code MUFI Point Glyph Entity Name Unicode Name E262 � OEligogon LATIN CAPITAL LIGATURE OE WITH OGONEK E268 � Pdblac LATIN CAPITAL LETTER P WITH DOUBLE ACUTE E34E � Vvertline LATIN CAPITAL LETTER V WITH VERTICAL LINE ABOVE E662 � oeligogon LATIN SMALL LIGATURE OE WITH OGONEK E668 � pdblac LATIN SMALL LETTER P WITH DOUBLE ACUTE E74F � vvertline LATIN SMALL LETTER V WITH VERTICAL LINE ABOVE E8A1 � idblstrok LATIN SMALL LETTER I WITH TWO STROKES E8A2 � jdblstrok LATIN SMALL LETTER J WITH TWO STROKES E8A3 � autem LATIN ABBREVIATION SIGN AUTEM E8BB � vslashura LATIN SMALL LETTER V WITH SHORT SLASH ABOVE RIGHT E8BC � vslashuradbl LATIN SMALL LETTER V WITH TWO SHORT SLASHES ABOVE RIGHT E8C1 � thornrarmlig LATIN SMALL LETTER THORN LIGATED WITH ARM OF LATIN SMALL LETTER R E8C2 � Hrarmlig LATIN CAPITAL LETTER H LIGATED WITH ARM OF LATIN SMALL LETTER R E8C3 � hrarmlig LATIN SMALL LETTER H LIGATED WITH ARM OF LATIN SMALL LETTER R E8C5 � krarmlig LATIN SMALL LETTER K LIGATED WITH ARM OF LATIN SMALL LETTER R E8C6 UU UUlig LATIN CAPITAL LIGATURE UU E8C7 uu uulig LATIN SMALL LIGATURE UU E8C8 UE UElig LATIN CAPITAL LIGATURE UE E8C9 ue uelig LATIN SMALL LIGATURE UE E8CE � xslashlradbl LATIN SMALL LETTER X WITH TWO SHORT SLASHES BELOW RIGHT E8D1 æ̊ aeligring LATIN SMALL LETTER AE WITH RING ABOVE E8D3 ǽ̨ aeligogonacute LATIN SMALL LETTER AE WITH OGONEK AND ACUTE 5 6 CONTENTS -

Makeyourfont-Abdulkerim.Pdf
اﺻﻨ َﻊ َﺧ ﱠﻄ ﻚ ﺑﻨ َ ْﻔ ﺴ ِﻚ ﺗﺄﻟﻴﻒ ُﻣ َـﺤ ﱠﻤـﺪ َﳛ َﻴﻰ َﻋ ْﺒﺪ َاﻟﻜ ِﺮ ْﻳﻢ أﺧﺼﺎﺋﻲ ﺑﺮاﻣﺞ آﻟﻴﺔ وﺣﺎﺳﺒﺎت ﺑﴩﻛﺔ اﻟﺼﻔﻮة ﻟﻠﱪﳎﻴﺎت − اﻟﻘﺎﻫﺮة − ﻣﴫ ﻣﺮاﺟﻌﺔ وﺗﺪﻗﻴﻖ وﺗﺮﺗﻴﺐ َﻳ َﻌﲆ َﻗ َﺤﻄﺎن ﱡاﻟﺪ ْو ِر ّي – – ﻛﻠﻴﺔ اﻟﺪراﺳﺎت اﻟﻔﻘﻬﻴﺔ واﻟﻘﺎﻧﻮﻧﻴﺔ ﺟﺎﻣﻌﺔ آل اﻟﺒﻴﺖ اﻷُردن א اﺳﻢ اﻟﻜﺘﺎب: اﺻﻨﻊ ﺧﻄﻚ ﺑﻨﻔﺴﻚ. اﳌﺆﻟﻒ: ُﻣ َـﺤ ﱠﻤـﺪ َﳛ َﻴﻰ َﻋ ْﺒﺪ َاﻟﻜ ِﺮ ْﻳﻢ. ﻣﺮاﺟﻌﺔ وﺗﺪﻗﻴﻖ وﺗﺮﺗﻴﺐ: َﻳ َﻌﲆ َﻗ َﺤﻄﺎن ﱡاﻟﺪ ْو ِر ّي . ﺗﺼﻤﻴﻢ اﻟﻐﻼف: َﻋ ْﺒﺪ اﷲ َﻋ ِﺎرف. اﻟﻤﺆﻟﻒ.... DOS C++ C#Visual Basic Visual Basic.net ًوأﺧـــﲑا: ﻟﻼﺳﺘﻔﺴﺎر ﻳﺮﺟﻰ اﻟﺘﻮاﺻﻞ ﻋﲆ: [email protected] +20188913719 ﺷﻜﺮ ﺧﺎص إﱃ اﻷخ اﻟﻜﺮﻳﻢ: َﻳ َﻌﲆ َﻗ َﺤﻄ ﺎن ﱡاﻟﺪ ْو ِر ّي . http://www.graphics4arab.com http://indesignyat.webatu.com http://zakdesign.net http://www.rashedy.com أﻣﺎ ﺑﻌﺪ: اﺻﻨﻊ ﺧﻄﻚ ﺑﻨﻔﺴﻚ واﷲ اﳌﻮﻓﻖ @@@éjn× áíŠØÛa@†jÇ@óî°@†àª اﺻﻨﻊ ﺧﻄﻚ ﺑﻨﻔﺴﻚ ﺗﻌﺮﻳﻒ اﳋﻂ اﳊﺎﺳﻮﰊ [Font File]: E١F Font Font Font File Encoding Character Mapping Traditional Arabic E١F اﺻﻨﻊ ﺧﻄﻚ -

דוקטור לפילוסופיה Doctor of Philosophy
חבור לשם קבלת התואר Thesis for the degree דוקטור לפילוסופיה Doctor of Philosophy מאת By תמיר קליין Tamir Klein אקו - פיזיולוגיה של ניצול מים באורן ירושלים : מרמת העלה ועד רמת היער Eco-physiology of water use in Pinus halepensis : from leaf to forest scale מנחה : פרופ ' דן יקיר Advisor: Prof. Dan Yakir בשיתוף ד"ר שבתאי כהן ( מינהל Co-mentored by Dr. Shabtai המחקר החקלאי מכון וולקני) (Cohen (ARO Volcani תמוז תשע"ב November 2012 מוגש למועצה המדעית של Submitted to the Scientific Council of the מכון ויצמן למדע Weizmann Institute of Science רחובות , ישראל Rehovot, Israel This work has been conducted under the supervision of Prof. Dan Yakir Department of Environmental Sciences and Energy Research Weizmann Institute of Science Rehovot, Israel And Dr. Shabtai Cohen Institute of Soil, Water and Environmental Sciences Volcani Center ARO Beit Dagan, Israel 1 Acknowledgements I was blessed with two exceptional mentors, Prof. Dan Yakir and Dr. Shabtai Cohen, whose positive, passionate approach to scientific research and to any learning in general, has been an inspiration to me. Their enthusiasm about plant eco-physiology together with the highest level of professionalism has made a profound impact on my work. I wish to thank my advisory committee, Profs. Brian Berkowitz and Amram Eshel for their interest in the work and advice for improvements. I have had the privilege of illuminating discussions with Prof. Gabi Schiller, Dr. Jose Gruenzweig, Dr. Gilboa Arye, Dr. Ron Milo, Prof. Harvey Scher, Prof. Yohai Carmel and Dr. Yagil Osem, that broadened my knowledge and understanding. The members of Dan’s group with whom I have worked: Fyodor, David, Uri, Hemu, Naama, Keren, Gil and Amir; have been research collaborators and good friends. -

Psftx-Debian-10.5/Arabic-Fixed16.Psf Linux Console Font Codechart
psftx-debian-10.5/Arabic-Fixed16.psf Linux console font codechart Glyphs 0x000 to 0x0FF 0 1 2 3 4 5 6 7 8 9 A B C D E F 0x00_ 0x01_ 0x02_ 0x03_ 0x04_ 0x05_ 0x06_ 0x07_ 0x08_ 0x09_ 0x0A_ 0x0B_ 0x0C_ 0x0D_ 0x0E_ 0x0F_ Page 1 Glyphs 0x100 to 0x1FF 0 1 2 3 4 5 6 7 8 9 A B C D E F 0x10_ 0x11_ 0x12_ 0x13_ 0x14_ 0x15_ 0x16_ 0x17_ 0x18_ 0x19_ 0x1A_ 0x1B_ 0x1C_ 0x1D_ 0x1E_ 0x1F_ Page 2 Font information 0x016 U+2026 HORIZONTAL ELLIPSIS Filename: psftx-debian-10.5/Arabic-Fixed16.ps 0x017 U+2030 PER MILLE SIGN f PSF version: 1 0x018 U+2191 UPWARDS ARROW, U+25B2 BLACK UP-POINTING Glyph size: 8 × 16 pixels TRIANGLE, Glyph count: 512 U+25B4 BLACK UP-POINTING Unicode font: Yes (mapping table present) SMALL TRIANGLE 0x019 U+2193 DOWNWARDS ARROW, Unicode mappings U+25BC BLACK DOWN-POINTING 0x000 U+00A9 COPYRIGHT SIGN TRIANGLE, U+25BE BLACK DOWN-POINTING 0x001 U+00AE REGISTERED SIGN SMALL TRIANGLE 0x002 U+0152 LATIN CAPITAL LIGATURE 0x01A U+2192 RIGHTWARDS ARROW, OE U+25B6 BLACK RIGHT-POINTING TRIANGLE, 0x003 U+0153 LATIN SMALL LIGATURE OE U+25B8 BLACK RIGHT-POINTING 0x004 U+2666 BLACK DIAMOND SUIT, SMALL TRIANGLE U+25C8 WHITE DIAMOND 0x01B U+2190 LEFTWARDS ARROW, CONTAINING BLACK SMALL U+25C0 BLACK LEFT-POINTING DIAMOND, TRIANGLE, U+FFFD REPLACEMENT U+25C2 BLACK LEFT-POINTING CHARACTER SMALL TRIANGLE 0x005 U+061F ARABIC QUESTION MARK 0x01C U+2122 TRADE MARK SIGN 0x006 U+0622 ARABIC LETTER ALEF WITH 0x01D U+FB53 ARABIC LETTER BEEH MADDA ABOVE FINAL FORM 0x007 U+0633 ARABIC LETTER SEEN 0x01E U+FB55 ARABIC LETTER BEEH MEDIAL FORM 0x008 U+0634 ARABIC LETTER -

KALĀM-E-MAWLĀ (Hindi – Gujarati Sayings of Hazrat Mawlana Ali A.S)
KALĀM-E-MAWLĀ (Hindi – Gujarati sayings of Hazrat Mawlana Ali A.S) With the introduction, annotation, transliteration, translation and approximated Arabic sayings and Quranic verses By Dr. Amin Valliani, ITREB (Pakistan), Karachi. 1 Ever-Blessing Words From the very beginnings of Islam, the search for knowledge has been central to our cultures. I think of the words of Hazrat Ali ibn Abi Talib, the first hereditary Imam of the Shia Muslims, and the last of the four rightly-guided Caliphs after the passing away of the Prophet (may peace be upon Him). In his teachings, Hazrat Ali emphasized that “No honour is like knowledge.” And then he added that “No belief is like modesty and patience, no attainment is like humility, no power is like forbearance, and no support is more reliable than consultation.” Notice that the virtues endorsed by Hazrat Ali are qualities which subordinate the self and emphasize others ---modesty, patience, humility, forbearance and consultation. What he thus is telling us, is that we find knowledge best by admitting first what it is we do not know, and by opening our minds to what others can teach us. Mawlana Hazar Imam, Address at the Commencement Ceremony of the American University in Cairo, dated 15th June, 2006. 2 This book is a humble tribute to my late teacher Itmadi Noor Din H.Bakhsh (d.2000) who inspired me to undertake this research based academic exercise. 3 Acknowledgments Upon completion of this project on Kālām-e-Mawlā, I bow my head and heart to thank the He, who made me able to undertake the academic task. -

Proposal to Encode Productive Arabic-Script Modifier Marks 2
Proposal to encode productive Arabic-script modifier marks Date: May 16, 2003 Author: Jonathan Kew, SIL International Kamal Mansour, Agfa Monotype Mark Davis, IBM Address: Horsleys Green Agfa Monotype High Wycombe 425 Sherman Ave Bucks HP14 3XL Palo Alto, CA 94306 England USA Tel: +44 (1494) 682306 +1 (650) 321-4102 Email: [email protected] [email protected] [email protected] A. Administrative 1. Title Proposal to encode productive Arabic-script modifier marks 2. Requester’s name SIL International (contacts: Jonathan Kew, Peter Constable); Agfa Monotype (contact: Kamal Mansour) 3. Requester type Expert contribution 4. Submission date May 16, 2003 5. Requester’s reference 6a. Completion This is a complete proposal. 6b. More information to be provided? Only as required for clarification. B. Technical — General 1a. New script? Name? No 1b. Addition of characters to existing block? Yes — Arabic Name? 2. Number of characters in proposal 23 3. Proposed category A 4. Proposed level of implementation and 2 (includes combining marks) rationale 5a. Character names included in proposal? Yes 5b. Character names in accordance with Yes guidelines? 5c. Character shapes reviewable? Yes 6a. Who will provide computerized font? Jonathan Kew, SIL International 6b. Font currently available? Yes 6c. Font format? TrueType 7a. Are references (to other character sets, See the documents cited under References. dictionaries, descriptive texts, etc.) provided? 7b. Are published examples (such as samples See the documents cited under References. from newspapers, magazines, or other sources) of use of proposed characters attached? 8. Does the proposal address other aspects of Yes, suggested character properties and collation character data processing? weights are included. -
Typographic Development of the Khojki Script and Printing Affairs at the Turn of the 19Th Century in Bombay by Juan Bruce
Typographic development of the Khojki script and printing affairs at the turn of the 19th century in Bombay by Juan Bruce Khōjā Studies Conference, cnrs-ceias, París, December 2016. Paper based on the dissertation The origins, evolution and decline of the Khojki script submitted in September of 2015 by the same author as part of the requirements of the Master of Arts in Typeface Design at the University of Reading, uk. overview The Khojki script is an Indian script whose origins are in Sindh (now south of Pakistan), a region that has witnessed more than 1,200 years of interplay between Islam and Hinduism. After the gradual occupation of the region by Muslims from the 8th century onwards, the script took on different usages among its community, the Khojas. Sindh, Punjab and Gujarat, were the first places that received gradual Muslim religious incursions into Hindu communities, to which language and writing constituted the first barrier for conversion. It is believed that one prominent Muslim pir (Pir Sadruddin) was very much active inside the Hindu Lohana community in the 14th century, a caste of merchants and traders. As a way to approach and transmit the teachings to the people, the pir adopted the Lohānākī script of this community. Later on, the converted came to be known as the Khoja caste. Significantly, a totally different creed, known as Satpanth, grew inside the community after the blend of these cultures. Academic interest has been stimulated by the special nature of the Satpanthi literature and its place in the Indian subcontinent. It has emerged as a fascinating example of an Islamic religious movement expressing itself within a local Indian religious culture.