Introduction to Coding Theory Lecture Notes∗
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Reed-Solomon Codes
Foreword This chapter is based on lecture notes from coding theory courses taught by Venkatesan Gu- ruswami at University at Washington and CMU; by Atri Rudra at University at Buffalo, SUNY and by Madhu Sudan at MIT. This version is dated May 8, 2015. For the latest version, please go to http://www.cse.buffalo.edu/ atri/courses/coding-theory/book/ The material in this chapter is supported in part by the National Science Foundation under CAREER grant CCF-0844796. Any opinions, findings and conclusions or recomendations ex- pressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation (NSF). ©Venkatesan Guruswami, Atri Rudra, Madhu Sudan, 2013. This work is licensed under the Creative Commons Attribution-NonCommercial- NoDerivs 3.0 Unported License. To view a copy of this license, visit http://creativecommons.org/licenses/by-nc-nd/3.0/ or send a letter to Creative Commons, 444 Castro Street, Suite 900, Mountain View, California, 94041, USA. Chapter 5 The Greatest Code of Them All: Reed-Solomon Codes In this chapter, we will study the Reed-Solomon codes. Reed-Solomoncodeshavebeenstudied a lot in coding theory. These codes are optimal in the sense that they meet the Singleton bound (Theorem 4.3.1). We would like to emphasize that these codes meet the Singleton bound not just asymptotically in terms of rate and relative distance but also in terms of the dimension, block length and distance. As if this were not enough, Reed-Solomon codes turn out to be more versatile: they have many applications outside of coding theory. -

Scribe Notes
6.440 Essential Coding Theory Feb 19, 2008 Lecture 4 Lecturer: Madhu Sudan Scribe: Ning Xie Today we are going to discuss limitations of codes. More specifically, we will see rate upper bounds of codes, including Singleton bound, Hamming bound, Plotkin bound, Elias bound and Johnson bound. 1 Review of last lecture n k Let C Σ be an error correcting code. We say C is an (n, k, d)q code if Σ = q, C q and ∆(C) d, ⊆ | | | | ≥ ≥ where ∆(C) denotes the minimum distance of C. We write C as [n, k, d]q code if furthermore the code is a F k linear subspace over q (i.e., C is a linear code). Define the rate of code C as R := n and relative distance d as δ := n . Usually we fix q and study the asymptotic behaviors of R and δ as n . Recall last time we gave an existence result, namely the Gilbert-Varshamov(GV)→ ∞ bound constructed by greedy codes (Varshamov bound corresponds to greedy linear codes). For q = 2, GV bound gives codes with k n log2 Vol(n, d 2). Asymptotically this shows the existence of codes with R 1 H(δ), which is similar≥ to− Shannon’s result.− Today we are going to see some upper bound results, that≥ is,− code beyond certain bounds does not exist. 2 Singleton bound Theorem 1 (Singleton bound) For any code with any alphabet size q, R + δ 1. ≤ Proof Let C Σn be a code with C Σ k. The main idea is to project the code C on to the first k 1 ⊆ | | ≥ | | n k−1 − coordinates. -

An Introduction to Coding Theory
An introduction to coding theory Adrish Banerjee Department of Electrical Engineering Indian Institute of Technology Kanpur Kanpur, Uttar Pradesh India Feb. 6, 2017 Lecture #7A: Bounds on the size of a code Adrish Banerjee Department of Electrical Engineering Indian Institute of Technology Kanpur Kanpur, Uttar Pradesh India An introduction to coding theory Outline of the lecture Hamming bound Adrish Banerjee Department of Electrical Engineering Indian Institute of Technology Kanpur Kanpur, Uttar Pradesh India An introduction to coding theory Outline of the lecture Hamming bound Perfect codes Adrish Banerjee Department of Electrical Engineering Indian Institute of Technology Kanpur Kanpur, Uttar Pradesh India An introduction to coding theory Outline of the lecture Hamming bound Perfect codes Singleton bound Adrish Banerjee Department of Electrical Engineering Indian Institute of Technology Kanpur Kanpur, Uttar Pradesh India An introduction to coding theory Outline of the lecture Hamming bound Perfect codes Singleton bound Maximum distance separable codes Adrish Banerjee Department of Electrical Engineering Indian Institute of Technology Kanpur Kanpur, Uttar Pradesh India An introduction to coding theory Outline of the lecture Hamming bound Perfect codes Singleton bound Maximum distance separable codes Plotkin Bound Adrish Banerjee Department of Electrical Engineering Indian Institute of Technology Kanpur Kanpur, Uttar Pradesh India An introduction to coding theory Outline of the lecture Hamming bound Perfect codes Singleton bound Maximum distance separable codes Plotkin Bound Gilbert-Varshamov bound Adrish Banerjee Department of Electrical Engineering Indian Institute of Technology Kanpur Kanpur, Uttar Pradesh India An introduction to coding theory Bounds on the size of a code The basic problem is to find the largest code of a given length, n and minimum distance, d. -

Optimal Codes and Entropy Extractors
Department of Mathematics Ph.D. Programme in Mathematics XXIX cycle Optimal Codes and Entropy Extractors Alessio Meneghetti 2017 University of Trento Ph.D. Programme in Mathematics Doctoral thesis in Mathematics OPTIMAL CODES AND ENTROPY EXTRACTORS Alessio Meneghetti Advisor: Prof. Massimiliano Sala Head of the School: Prof. Valter Moretti Academic years: 2013{2016 XXIX cycle { January 2017 Acknowledgements I thank Dr. Eleonora Guerrini, whose Ph.D. Thesis inspired me and whose help was crucial for my research on Coding Theory. I also thank Dr. Alessandro Tomasi, without whose cooperation this work on Entropy Extraction would not have come in the present form. Finally, I sincerely thank Prof. Massimiliano Sala for his guidance and useful advice over the past few years. This research was funded by the Autonomous Province of Trento, Call \Grandi Progetti 2012", project On silicon quantum optics for quantum computing and secure communications - SiQuro. i Contents List of Figures......................v List of Tables....................... vii Introduction1 I Codes and Random Number Generation7 1 Introduction to Coding Theory9 1.1 Definition of systematic codes.............. 16 1.2 Puncturing, shortening and extending......... 18 2 Bounds on code parameters 27 2.1 Sphere packing bound.................. 29 2.2 Gilbert bound....................... 29 2.3 Varshamov bound.................... 30 2.4 Singleton bound..................... 31 2.5 Griesmer bound...................... 33 2.6 Plotkin bound....................... 34 2.7 Johnson bounds...................... 36 2.8 Elias bound........................ 40 2.9 Zinoviev-Litsyn-Laihonen bound............ 42 2.10 Bellini-Guerrini-Sala bounds............... 43 iii 3 Hadamard Matrices and Codes 49 3.1 Hadamard matrices.................... 50 3.2 Hadamard codes..................... 53 4 Introduction to Random Number Generation 59 4.1 Entropy extractors................... -

Optimal Locally Repairable Codes of Distance 3 and 4 Via Cyclic Codes
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by CWI's Institutional Repository Optimal locally repairable codes of distance 3 and 4 via cyclic codes Yuan Luo,∗ Chaoping Xing and Chen Yuan y Abstract Like classical block codes, a locally repairable code also obeys the Singleton-type bound (we call a locally repairable code optimal if it achieves the Singleton-type bound). In the breakthrough work of [14], several classes of optimal locally repairable codes were constructed via subcodes of Reed-Solomon codes. Thus, the lengths of the codes given in [14] are upper bounded by the code alphabet size q. Recently, it was proved through extension of construction in [14] that length of q-ary optimal locally repairable codes can be q + 1 in [7]. Surprisingly, [2] presented a few examples of q-ary optimal locally repairable codes of small distance and locality with code length achieving roughly q2. Very recently, it was further shown in [8] that there exist q-ary optimal locally repairable codes with length bigger than q + 1 and distance propositional to n. Thus, it becomes an interesting and challenging problem to construct new families of q-ary optimal locally repairable codes of length bigger than q + 1. In this paper, we construct a class of optimal locally repairable codes of distance 3 and 4 with un- bounded length (i.e., length of the codes is independent of the code alphabet size). Our technique is through cyclic codes with particular generator and parity-check polynomials that are carefully chosen. -

MAS309 Coding Theory
MAS309 Coding theory Matthew Fayers January–March 2008 This is a set of notes which is supposed to augment your own notes for the Coding Theory course. They were written by Matthew Fayers, and very lightly edited my me, Mark Jerrum, for 2008. I am very grateful to Matthew Fayers for permission to use this excellent material. If you find any mistakes, please e-mail me: [email protected]. Thanks to the following people who have already sent corrections: Nilmini Herath, Julian Wiseman, Dilara Azizova. Contents 1 Introduction and definitions 2 1.1 Alphabets and codes . 2 1.2 Error detection and correction . 2 1.3 Equivalent codes . 4 2 Good codes 6 2.1 The main coding theory problem . 6 2.2 Spheres and the Hamming bound . 8 2.3 The Singleton bound . 9 2.4 Another bound . 10 2.5 The Plotkin bound . 11 3 Error probabilities and nearest-neighbour decoding 13 3.1 Noisy channels and decoding processes . 13 3.2 Rates of transmission and Shannon’s Theorem . 15 4 Linear codes 15 4.1 Revision of linear algebra . 16 4.2 Finite fields and linear codes . 18 4.3 The minimum distance of a linear code . 19 4.4 Bases and generator matrices . 20 4.5 Equivalence of linear codes . 21 4.6 Decoding with a linear code . 27 5 Dual codes and parity-check matrices 30 5.1 The dual code . 30 5.2 Syndrome decoding . 34 1 2 Coding Theory 6 Some examples of linear codes 36 6.1 Hamming codes . 37 6.2 Existence of codes and linear independence . -

Optimal Linear and Cyclic Locally Repairable Codes Over Small Fields
Optimal Linear and Cyclic Locally Repairable Codes over Small Fields Alexander Zeh and Eitan Yaakobi Computer Science Department Technion—Israel Institute of Technology [email protected], [email protected] Abstract—We consider locally repairable codes over small This paper is structured as follows. Section II gives fields and propose constructions of optimal cyclic and linear codes necessary preliminaries on linear and cyclic codes, defines in terms of the dimension for a given distance and length. LRCs, recalls the generalized Singleton bound, the Cadambe– Four new constructions of optimal linear codes over small fields with locality properties are developed. The first two Mazumdar bound [8] as well as the definition of availability approaches give binary cyclic codes with locality two. While the for LRCs. The concept of a locality code and the projection first construction has availability one, the second binary code is to an additive code are discussed in Section III based on the characterized by multiple available repair sets based on a binary work of Goparaju and Calderbank [9]. Two new constructions Simplex code. of optimal binary codes are given in Section IV and a con- The third approach extends the first one to q-ary cyclic codes including (binary) extension fields, where the locality property struction based on a q-ary shortened cyclic first-order Reed– is determined by the properties of a shortened first-order Reed– Muller code is given in Section V. The fourth construction Muller code. Non-cyclic optimal binary linear codes with locality in Section VI uses code concatenation and provides optimal greater than two are obtained by the fourth construction. -

Constructions of MDS-Convolutional Codes Ring H, with RNk Q@Haak
IEEE TRANSACTIONS ON INFORMATION THEORY, VOL. 47, NO. 5, JULY 2001 2045 Constructions of MDS-Convolutional Codes ring h, with rnk q@hAak. For the purpose of this correspon- dence, we define the rate kan convolutional code generated by q@hA Roxana Smarandache, Student Member, IEEE, as the set Heide Gluesing-Luerssen, and n k Joachim Rosenthal, Senior Member, IEEE g a fu@hAq@hA P @hAju@hA P @hAg and say that q@hA is a generator matrix for the convolutional code g q@hA qH@hA Abstract—Maximum-distance separable (MDS) convolutional codes are . If the generator matrices and both generate the same characterized through the property that the free distance attains the gener- convolutional code g then there exists a k k invertible matrix @hA alized Singleton bound. The existence of MDS convolutional codes was es- with qH@hAa @hAq@hA and we say q@hA and qH@hA are equiva- tablished by two of the authors by using methods from algebraic geometry. lent encoders. This correspondence provides an elementary construction of MDS convo- lutional codes for each rate and each degree . The construction is Because of this, we can assume without loss of generality that the based on a well-known connection between quasi-cyclic codes and convo- code g is presented by a minimal basic encoder q@hA. For this, let lutional codes. #i be the ith-row degree of q@hA, i.e., #i amxj deg gij @hA. In the # Index Terms—Convolutional codes, generalized Singleton bound, max- literature [7], the indexes i are also called the constraint length for the imum-distance separable (MDS) convolutional codes. -
Bounds on Error-Correction Coding Performance
Chapter 1 Bounds on Error-Correction Coding Performance 1.1 Gallager’s Coding Theorem The sphere packing bound by Shannon [18] provides a lower bound to the frame error rate (FER) achievable by an (n, k, d) code but is not directly applicable to binary codes. Gallager [4] presented his coding theorem for the average FER for the ensemble of all random binary (n, k, d) codes. There are 2n possible binary combinations for each codeword which in terms of the n-dimensional signal space hypercube corresponds to one vertex taken from 2n possible vertices. There are 2k codewords, and therefore 2nk different possible random codes. The receiver is considered to be composed of 2k matched filters, one for each codeword and a decoder error occurs if any of the matched filter receivers has a larger output than the matched filter receiver corresponding to the transmitted codeword. Consider this matched filter receiver and another different matched filter receiver, and assume that the two codewords differ in d bit positions. The Hamming distance between the two = k codewords is d. The energy per transmitted bit is Es n Eb, where Eb is the energy σ 2 = N0 per information bit. The noise variance per matched filtered received bit, 2 , where N0 is the single sided noise spectral density. In the absence√ of noise, the output of the matched filter receiver for the transmitted codeword√ is n Es and the output of the other codeword matched filter receiver is (n − 2d) Es . The noise voltage at the output of the matched filter receiver for the transmitted codeword is denoted as nc − n1, and the noise voltage at the output of the other matched filter receiver will be nc + n1. -

Lecture 16: Plotkin Bound 1 Plotkin Bound
Error Correcting Codes: Combinatorics, Algorithms and Applications (Fall2007) Lecture 16: Plotkin Bound October 2, 2007 Lecturer:AtriRudra Scribe:NathanRussell&AtriRudra 1 In the last lecture we proved the GV bound, which states that for all δ with 0 ≤ δ ≤ 1− q , there exists a q-ary code of distance δ and rate at least 1 − Hq(δ) − ε, for every ε> 0. In fact we proved that with high probability, a random linear code C lies on the GV bound. We picked a generator matrix G at random and proved the latter result. At this point, we might ask what happens if G does not have full rank? There are two ways to deal with this. First, we can show that with high probability G does have full rank, so that |C| = qk. However, the proof from last lecture already showed that, with high probability, the distance is greater than zero, which implies that distinct messages will be mapped to distinct codewords and thus |C| = qk. 1 Further, the proof required that δ ≤ 1 − q because it is needed for the volume bound – Hq(δ)n V olq(0, δn) ≤ q – to hold. It is natural to wonder if the above is just an artifact of the 1 proof or, for example, is it possible to get R > 0 and δ > 1 − q ? In today’s lecture, we will show that this cannot be the case by proving the Plotkin bound. 1 Plotkin Bound We start by stating the Plotkin bound. Theorem 1.1 (Plotkin bound). The following holds for any C ⊆ [q]n with distance d: 1 1. -

MT361/MT461/MT5461 Error Correcting Codes
MT361/MT461/MT5461 Error Correcting Codes Mark Wildon, [email protected] I Please take a handout, the preliminary problem sheet, and the sheet of challenge problems. I All handouts and problem sheets will be put on the Moodle page for MT361. Everyone has access to this page. If you are not yet registered for the course, bookmark this link: moodle.rhul.ac.uk/course/view.php?id=381 I Lectures are at: Monday 3pm in MFLEC, Tuesday 3pm in BLT2, Thursday 10am in BLT2. I There is an additional lecture at Thursday noon for MT4610 and MT5461 in ABLT3. Correction: in week TWO only, this lecture will be moved to Friday 2pm in C219. I Office hours: Tuesday 11am, Thursday 2pm and Friday 11am. (This week as normal.) But in the modern world we want to store and process huge amounts of data. Think of a ‘bit’ as a single piece of information: on or off, 0 or 1. I A small QR-code: 441 bits I Text on first page of handout: 7144 bits I First 14 pages of handout: I Compact disc of Beethoven 9th: 700 MB I Bluray disc of 3 hour film: 50 GB I Large Hadron Collider data, per second: 300 GB Why Coding Theory? We want to communicate reliably in the presence of noise. With small amounts of data, we can do this quite easily. I Text on first page of handout: 7144 bits I First 14 pages of handout: I Compact disc of Beethoven 9th: 700 MB I Bluray disc of 3 hour film: 50 GB I Large Hadron Collider data, per second: 300 GB Why Coding Theory? We want to communicate reliably in the presence of noise. -
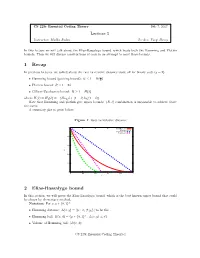
Lecture 5 1 Recap 2 Elias-Bassalygo Bound
CS 229r Essential Coding Theory Feb 7, 2017 Lecture 5 Instructor: Madhu Sudan Scribes: Yueqi Sheng In this lecture we will talk about the Elias-Bassalygo bound, which beats both the Hamming and Plotkin bounds. Then we will discuss constructions of code in an attempt to meet those bounds. 1 Recap In previous lectures, we talked about the rate vs relative distance trade off for binary code (q = 2). δ • Hamming bound (packing bound): R ≤ 1 − H( 2 ) • Plotkin bound: R ≤ 1 − 2δ • Gilbert-Varshamov bound: R ≥ 1 − H(δ) where H(δ) = H2(δ) = −(δ log δ + (1 − δ) log(1 − δ)). Note that Hamming and plotkin give upper bounds: (R; δ) combination is impossible to achieve above the curve. A summary plot is given below: Figure 1: Rate vs Relative distance 1 Hamming bound GV bound Singleton bound Plotkin bound 0.8 0.6 R 0.4 0.2 0 0 0.2 0.4 0.6 0.8 1 δ Figure 4.5: The current bounds on the rate R vs. relative distance δ for binary codes. The GV 2 Elias-Bassalygobound is a lower bound bound on rate while the other three bounds are upperboundsonR. In this section, weNote will that prove Corollary the 4.4.2 Elias-Bassalygo implies that for bound, any q-ary which code ofis rate theR bestand knownrelative distance upper boundδ that could (where q is a constant independent of the block length of the code), R 1 δ.Inotherwords, be shown by elementary method. < − Notation:this For answersx; y 2 Question f0; 1gn, 4.3.1 in the negative.