Predicting Shifting Individuals Using Text Mining and Graph Machine Learning on Twitter
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Plataforma Juntos Por El Cambio Paso 2019
PLATAFORMA JUNTOS POR EL CAMBIO PASO 2019 Creemos en la responsabilidad del Estado en brindar servicios educativos y defensa de la cohesión social, la búsqueda del equilibrio territorial y la promo- al por la educación, para garantizar la universalidad y preparar nuestras a) Defensa de la democracia institucional. JUNTOS POR EL CAMBIO se PLATAFORMA de salud de calidad para el mejoramiento de la sociedad y su preparación ción de la innovación. En sentido contrario, nos comprometemos a dejar atrás escuelas para las demandas del futuro, siempre con los docentes como reconoce como un espacio de defensa del liberalismo político, admite la PLATAFORMA para los desafíos del futuro. el desorden macroeconómico, la presión fiscal desbordada, los monopolios, las centro de cualquier estrategia. diversidad de opiniones y reconoce que la democracia liberal es un sistema JUNTOS POR EL CAMBIO ventajas sectoriales y los malos incentivos que erosionaron nuestro potencial. idóneo –el mejor inventado hasta ahora– para proteger a las minorías, PASOJUNTOS 2019 POR EL CAMBIO Creemos también en la igualdad ante la ley, fundamento del Estado Los miembros de esta coalición también vemos a la integración internacional defender los derechos civiles y sociales, y procesar las diferencias políticas democrático de derecho, porque ningún dirigente y ninguna corporación JUNTOS POR EL CAMBIO cree que el principal problema económico de la más como una oportunidad que como una amenaza. La globalidad nos inter- entre los distintos grupos de la sociedad. PASO 2019 pueden reclamar un trato preferencial. Creemos en una verdadera igualdad Argentina es la pobreza y que todas las acciones de gobierno deben estar pela; nuestras conversaciones, nuestros consumos y nuestras relaciones son de oportunidades, que le permita a cada habitante de la Argentina tomar en orientadas a reducirla. -

Encuesta De Satisfacción Política Y Opinión Pública
Encuesta de Satisfacción Política y Opinión Pública #ESPOP Abril 2018 1 Metodología • Estos son hallazgos de la encuesta de satisfacción política y opinion pública de la Universidad de San Andrés. En total fueron realizadas 1004 entrevistas entre el 16 y el 23 de Abril de 2018 a adultos de 18-64 años conectados a internet, en Argentina. • La encuesta se realiza en 23 provincias y la Ciudad Autónoma de Buenos Aires vía el Panel online de Netquest. La muestra es proporcional al tamaño de las provincias (con algunos ajustes para garantizar base de lectura) y representativa a nivel de las regiones. Las provincias fueron agrupadas en 5 regiones: NOA, NEA, Cuyo, Centro, Patagonia, y Buenos Aires dividida a su vez en CABA, GBA e interior de la Provincia de Buenos Aires. Se aplicaron cuotas de sexo, edad y nivel socioeconómico. • La encuesta versa sobre satisfacción con el desempeño de los poderes políticos y las políticas públicas y sobre la opinion respecto de los principals líderes politicos nacionales, grupos y sectores, ministros y gobernadores. Algunas preguntas siguen una serie de tiempo basada en la encuesta de Indicadores de Satisfacción Política Institucional (ISPI) realizada por la Universidad de San Andrés e Ipsos de Marzo de 2016 a Mayo de 2017. En la presente investigación se modificaron las escalas numéricas de satisfacción y opinion (antes de 1-10) por escalasordinales de 4 categorías (dos positivas y dos negativas). Los valores de las series de tiempo fueron recategorizados para ser comparabales con las nuevas mediciones. • Cuando los resultados no sumen 100, eso puede deberse a redondeos computacionales,, respuestas múltiples o la exclusión de los que no saben o no contestan. -

2021 Year Ahead
2021 YEAR AHEAD Claudio Brocado Anthony Brocado January 29, 2021 1 2020 turned out to be quite unusual. What may the year ahead and beyond bring? As the year got started, the consensus was that a strong 2019 for equities would be followed by a positive first half, after which meaningful volatility would kick in due to the US presidential election. In the spirit of our prefer- ence for a contrarian stance, we had expected somewhat the opposite: some profit-taking in the first half of 2020, followed by a rally that would result in a positive balance at year-end. But in the way of the markets – which always tend to catch the largest number of participants off guard – we had what some would argue was one of the strangest years in recent memory. 2 2020 turned out to be a very eventful year. The global virus crisis (GVC) brought about by the coronavirus COVID-19 pandemic was something no serious market observer had anticipated as 2020 got started. Volatility had been all but nonexistent early in what we call ‘the new 20s’, which had led us to expect the few remaining volatile asset classes, such as cryptocurrencies, to benefit from the search for more extreme price swings. We had expected volatilities across asset classes to show some convergence. The markets delivered, but not in the direction we had expected. Volatilities surged higher across many assets, with the CBOE volatility index (VIX) reaching some of the highest readings in many years. As it became clear that what was commonly called the novel coronavirus would bring about a pandemic as it spread to the remotest corners of the world at record speeds, the markets feared the worst. -

“No Se Dejen Robar La Esperanza”
K Y M C Caso Píparo: 40.000 confirman que Ejemplares Isidro murió por De distribución Año XX • Nº6828 Entrega bajo puerta: $3,00 el tiro a Carolina gratuita Edición de 40 páginas En la noticia Recargo Interior: $0,50 La Plata, martes 26 de marzo de 2013 - PAG. 20 “No se dejen robar la esperanza” La frase del Papa Francisco está inspirando a muchos de los que organizan -para el 18 de abril- una masiva movilización en todo el país. Reclamos por la inflación, la crisis Camino hacia el educativa, la inseguridad y los ataques al periodismo independiente #18A - PAGS. 3 A 5 Provincia: se viene un paro docente de 72 horas y denuncian intento destituyente - PAG. 7 Barsottini, el Desde las 17, ídolo tripero Argentina visita que se ilusiona a Bolivia con el ascenso - EL C LASICO - EL C LASICO La Plata, martes 26 2 Diario en la noticia de marzo de 2013 A los lectores Más de 172 mil Los K no se hacen cargo de la casos de doble Estando a una altura de mes donde gran parte de los trabajadores están con las mo- afiliación nedas justas, y teniendo en cuenta que el país atraviesa por momentos políticos y falta de reparto de fondos La Junta Electoral económicos cruciales, el diario Hoy vuelve a bonaerense detectó más de realizar un enorme esfuerzo editorial dis- 172 mil casos de personas tribuyendo –durante la presente jornada- 40 o hay ninguna guerra con- con doble afiliación a par- mil ejemplares gratuitos en La Plata, Berisso, “N tra (Daniel) Scioli", dijo tidos políticos provinciales y Ensenada, Quilmes y Berazategui. -

ARGENTINA Y URUGUAY ACUERDAN EN BRASIL Hay Muchas Expectativas Por El Encuentro De Cristina Kirchner Y Pepe Mujica En Brasilia P
Viernes 27 de julio de 2012 ARGENTINA Y URUGUAY ACUERDAN EN BRASIL Hay muchas expectativas por el encuentro de Cristina Kirchner y Pepe Mujica en Brasilia para destrabar el conflicto por el dragado del canal Martín García. Aunque también hay fuertes sospechas tanto en Uruguay como en Argentina que antes del martes -que es la reunión del Mercosur en Brasil- pueda haber novedades en cuanto a las denuncias por presuntas coimas en el contrato para las obras de mantenimiento del Martín García. Del lado argentino, el juez Bonadío avanza en una investigación en la que podría citar a embajadores argentinos. En tanto, del lado uruguayo amenazan con revelar datos secretos del informe de la Comisión Administradora del Río de la Plata que mencionarían encuentros y charlas entre el ex embajador Bustillo y funcionarios argentinos vinculados con pedidos de sobornos para mantener el contrato con una empresa. Además si no se logra un acuerdo el martes en Brasilia los uruguayos avanzarán en forma unilateral en la convocatoria a la licitación de obras de dragado lo que profundizará el conflicto bilateral. LA RESPONSABILIDAD DE CRISTINA Se sabe ahora que de la lista de encuestas que le llegaron, la que la decidió a Cristina Fernández a ordenar un prudente freno en la estrategia de embestir contra Daniel Scioli y soltarle los fondos de la Anses que le había negado quince días antes, fue la de Artemio López, su consultor de cabecera. López le mostró un sondeo realizado en todo el ámbito provincial que terminó de convencerla para ordenar aquel freno: el 60 por ciento de los consultados dijo que Cristina Fernández era la responsable de la crisis que derivó en el pago en cuotas del medio aguinaldo a los trabajadores estatales. -
PRIMARY ELECTIONS Special Report
PRIMARY ELECTIONS Special Report WHAT IS AT STAKE? Provincial Elections President 24 130 National Representatives Provinces of Catamarca, Buenos Aires, and the City of Vicepresident National Senators Buenos Aires held primary elections to governor while Santa Cruz had general election. NATIONAL PROVISIONAL RESULTS OF THE PRIMARY ELECTIONS s 47.65% PARTICIPATION: 75,78% Alberto Fernández – Cristina Fernández de Kirchner 32.08% Mauricio Macri - Miguel Ángel Pichetto 8.22% Roberto Lavagna – Juan Manuel Urtubey 2.86% Nicolás del Caño – Romina del Pla 2.63% Juan J. Gómez Centurión – Cynthia Hotton 2.18% José Luis Espert – Luis Rosales ELECTORAL THRESHOLD 1.5% 0.71% Manuela Castañeira – Eduardo Mulhall 0.24% Alejandro Biondini – Enrique Venturino 0.14% Raul Albarracín – Sergio Pastore 0.13% José Antonio Romero Feris – Guillermo Sueldo POLITICAL SUPPORT KEYS #1 THE CENTER REGION VOTE #2 BUENOS AIRES SUPPORT #3 THE REST OF THE COUNTRY The National Government In the first section of the Other provinces, mainly driven expected to count with greater province of Buenos Aires, by the support of several support in Córdoba and Santa bastion of Cambiemos in 2015 Peronist governors, also added Fe, that along with Mendoza, and 2017, the officialism got an important part of votes that would provide a number of adverse results from expected summed up in the final result votes to face the tight scenario while in the other two -of an led Alberto Fernández to win in the province of Buenos Aires, average lower income-, the with several points ahead. but finally it turned the opposite Frente de Todos prevailed with way. -

Meeting of the OECD Global Parliamentary Network 1-2 October 2020 List of Participants
as of 02/10/2020 Meeting of the OECD Global Parliamentary Network 1-2 October 2020 List of participants MP or Chamber or Political Party Country Parliamentary First Name Last Name Organisation Job Title Biography (MPs only) Official represented Pr. Ammar Moussi was elected as Member of the Algerian Parliament (APN) for the period 2002-2007. Again, in the year Algerian Parliament and Member of Peace Society 2017 he was elected for the second term and he's now a member of the Finance and Budget commission of the National Algeria Moussi Ammar Parliamentary Assembly Member of Parliament Parliament Movement. MSP Assembly. In addition, he's member of the parliamentary assembly of the Mediterranean PAM and member of the executif of the Mediterranean bureau of tha Arab Renewable Energy Commission AREC. Abdelmajid Dennouni is a Member of Parliament of the National People’s Assembly and a Member of finances and Budget Assemblée populaire Committee, and Vice president of parliamentary assembly of the Mediterranean. He was previously a teacher at Oran Member of nationale and Algeria Abdelmajid Dennouni Member of Parliament University, General Manager of a company and Member of the Council of Competitiveness, as well as Head of the Parliament Parliamentary Assembly organisaon of constucng, public works and hydraulics. of the Mediterranean Member of Assemblée Populaire Algeria Amel Deroua Member of Parliament WPL Ambassador for Algeria Parliament Nationale Assemblée Populaire Algeria Parliamentary official Safia Bousnane Administrator nationale Lucila Crexell is a National Senator of Argentina and was elected by the people of the province of Neuquén in 2013 and reelected in 2019. -

ENCUESTA NACIONAL Sobre ELECCIONES PRESIDENCIALES 2015
Encuesta de Opinión Pública en la República Argentina IMAGEN CRISTINA KIRCHNER 0,5% 2,4% Cristina 10,2% 17,5% 25,2% 21,2% 23,0% KIRCHNER Muy Buena Buena Regular Mala Muy Mala No lo conozco Ns/Nc Imagen CONSOLIDADA 0,5% 2,4% Cristina 27,7% 25,2% 44,2% KIRCHNER Positiva Regular Negativa No lo conozco Ns/Nc Avenida de Mayo 1410 4º Of. 37 - (C1085ABR) Ciudad Autónoma de Buenos Aires - Tel.: (011) 5218-7777/78/79 www.giacobbeconsultores.com | [email protected] | @GiacobbeOP Encuesta de Opinión Pública en la República Argentina ¿Con qué nota calificaría la gestión del Gobierno Nacional? Puntaje % 1 16,0% 10 2 7,1% 9 3 11,2% 8 4 12,2% 7 5 15,0% 6 6 9,2% 5 4,64 7 9,6% 4 8 8,8% 9 3,7% 3 10 3,3% 2 Ns/Nc 3,9% 1 Total 100% 0 PROMEDIO 4,64 Gobierno Nacional Avenida de Mayo 1410 4º Of. 37 - (C1085ABR) Ciudad Autónoma de Buenos Aires - Tel.: (011) 5218-7777/78/79 www.giacobbeconsultores.com | [email protected] | @GiacobbeOP Encuesta de Opinión Pública en la República Argentina ¿Qué imagen personal tiene de las siguientes figuras políticas? Muy Muy No lo Opción Buena Regular Mala Ns/Nc buena mala conozco Mauricio MACRI 12,0% 32,2% 21,9% 11,7% 14,5% 1,8% 5,9% Daniel SCIOLI 7,4% 30,1% 28,7% 17,1% 8,9% 2,6% 5,2% Sergio MASSA 9,0% 27,7% 27,4% 13,9% 10,5% 5,0% 6,5% Hermes BINNER 3,7% 24,5% 26,3% 12,9% 4,1% 21,0% 7,5% Julio COBOS 7,0% 19,6% 27,7% 18,2% 11,4% 8,6% 7,5% Florencio RANDAZZO 5,0% 18,6% 27,0% 18,2% 10,0% 12,4% 8,8% Avenida de Mayo 1410 4º Of. -
Subsecretaría De ANIVERSARIO Actividades Portuarias
NEWSLETTER Subsecretaría de ANIVERSARIO Actividades Portuarias Nuestros Puertos en la Asamblea Legislativa El gobernador Daniel Scioli inauguró las sesiones 2011, ante una Cámara Legislativa colmada por diputados, senadores y funcionarios provinciales. Durante el discurso, el gobernador destacó el gran año 2010 que tuvieron los Puertos, enfatizando las mejoras en infraestructura portuaria en el Luis Abot corredor fluvial del río Paraná y Dock Sud, como así también el desarrollo Dos años de Gestión futuro de los Puertos de Bahía Blanca y La Plata, y la inauguración de la Es un gusto para mí compartir esta Edición Especial dirigida a la Zona Franca Bahía Blanca-Coronel Rosales. Ver más en: Comunidad Portuaria. En esta oportunidad quiero destacar el http://www.cronista.com/transportycargo/El-gobernador-Scioli-hizo- invalorable aporte de cada uno de los trabajadores, profesionales y foco-en-elcrecimiento-de-los-puertos-bonaerenses-20110309-0007.html amigos que hicieron posible cumplir dos años frente a la Subsecretaría de Actividades Portuarias. Durante estos dos años, los que llevo con orgullo en la gestión, hemos trabajado: Estado, Empresas y Trabajadores unidos para articular cada sector en pos de políticas comunes para el desarrollo portuario y para atraer nuevas inversiones que generen más empleo para todos. Por eso, quiero aprovechar estas líneas para recordarles una frase del Gobernador: “los resultados llegan más rápido si se articula el sector público con el privado”. Esta es la estrategia diseñada por el Reunión con los Consorcios portuarios Gobernador, Daniel Scioli, y el Ministro de la Producción, Martín El Ministro de la Producción, Martín Ferré, encabezó una reunión con los Ferré, e implementada por los Puertos. -
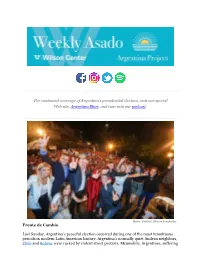
For Continued Coverage of Argentina's Presidential Election, Visit Our
For continued coverage of Argentina’s presidential election, visit our special Web site, Argentina Elige, and tune into our podcast. Photo: Twitter/ Alberto Fernández Frente de Cambio Last Sunday, Argentina’s peaceful election occurred during one of the most tumultuous periods in modern Latin American history. Argentina’s normally quiet Andean neighbors, Chile and Bolivia, were racked by violent street protests. Meanwhile, Argentines, suffering their most severe economic crisis in decades, participated in peaceful campaign rallies and then 26.6 million Argentines – more than 80 percent of the electorate – voted without incident. President Mauricio Macri’s close second-place finish means that, for the first time since 1928, a non-Peronist president will finish his term and peacefully hand over power to a Peronist successor, in this case, Alberto Fernández. That is no small feat for a country famous for economic and political instability. But amid the justifiable enthusiasm over Argentina’s maturing democracy, the country’s near-term future is worrisome. Mr. Fernández’s performance in the election fell short of expectations, and raised questions about the capacity of his government to navigate one of the worst economic calamities to hit Argentina since 2001. There are also concerns about Argentina’s future foreign policy. Mr. Fernández wore his foreign policy on his sleeve on election night, praising Lula and Evo Morales, and raising fears of a major regional realignment that would isolate Argentina from its neighbors, the United States and Europe at a time when it is deeply dependent on international goodwill. The Results Mr. Macri lost his reelection bid, capturing 40 percent of the vote – only the third incumbent in Latin America to be voted out of office since the 1980s. -

Juzgado Electoral De La Provincia De Corrientes
Juzgado Electoral de la Provincia de Corrientes ELECCIONES MUNICIPALES Expte. N° 189767 27 DE OCTUBRE DE 2019 Listado de Alianzas y Partidos Reconocidos para las ALIANZAS ELECTORALES y PARTIDOS POLÍTICOS Elecciones Municipales Categorías N° de Orden: Concejales BONPLAND Tit: 1 10 Supl: 1 N°Expte. Lista Alianza Lista Partidos Apoderados 3 UNIÓN CIVICA RADICAL OSCAR MARTÍNEZ 4 MOVIMIENTO SIEMPRE CORRIENTES FABIÁN A. DARRÉ 9 DEMÓCRATA PROGRESISTA 14 ACCIÓN POR CORRIENTES 15 UNIDOS POR CORRIENTES 17 LABORISTA AUTÓNOMO 18 ELI - ENCUENTRO LIBERAL 23 FE 25 UNIÓN POPULAR 27 ENCUENTRO CORRELIGIONARIO ENCUENTRO POR CORRIENTES - ECO 28 CAMBIO AUSTERIDAD Y PROGRESO 190052 204 + JUNTOS POR EL CAMBIO 31 CONSERVADOR POPULAR 34 ACCIÓN POPULAR DE LOS TRABAJADORES 44 ACCIÓN POR LA REPÚBLICA 47 AFIRMACIÓN PARA UNA REPÚBLICA IGUALITARIA (A.R.I.) 51 LIBERAL 52 AUTONOMISTA 57 PROYECTO CORRIENTES 64 PRO - PROPUESTA REPUBLICANA 169 POPULAR 173 UNIÓN CELESTE Y BLANCO 175 COMPROMISO CORRENTINO Juzgado Electoral de la Provincia de Corrientes ELECCIONES MUNICIPALES Expte. N° 189767 27 DE OCTUBRE DE 2019 Listado de Alianzas y Partidos Reconocidos para las ALIANZAS ELECTORALES y PARTIDOS POLÍTICOS Elecciones Municipales Categorías N° de Orden: Concejales BONPLAND Tit: 1 10 Supl: 1 N°Expte. Lista Alianza Lista Partidos Apoderados 2 JUSTICIALISTA ALFREDO A. GÓMEZ 10 RENOVADOR FEDERAL RAÚL GERMÁN BITTEL 12 COMUNISTA 13 ENCUENTRO POR LA DEM. Y LA EQUID. 19 CAMBIO POPULAR 190041 212 FRENTE DE TODOS 21 CONVOCATORIA POPULAR 24 NUESTRA CAUSA 26 DE LA CULTURA, LA EDUCACIÓN Y EL TRABAJO 54 DE LA VICTORIA 170 CRECER CON TODOS 192 KOLINA Juzgado Electoral de la Provincia de Corrientes ELECCIONES MUNICIPALES Expte. -

ONLINE INFLUENCE GRID of ARGENTINIAN POLITICS: the Humanization of Political Candidates February, 2016
ONLINE INFLUENCE GRID OF ARGENTINIAN POLITICS: The humanization of political candidates February, 2016 BARCELONA BOGOTA BUENOS AIRES LIMA LISBON MADRID MEXICO CITY MIAMI PANAMA CITY QUITO RIO J SAO PAULO SANTIAGO STO DOMINGO Index Introduction 3 Government Campaign and 4 Communication Online Influence 5 What really matters is not getting to 6 the top, but learning how to stay there The influence on the network: 7 Tables and graphs Team of Specialists 13 Introduction Digital Identity may be defined as all information on Despite trailing behind opponent Daniel Scioli and, a specific person which is available on the Internet notably, behind former President Cristina Fernandez, as (personal data, pictures, records, news, comments, etc.) regards the number of followers on social networks, the and which shapes the profile of the aforementioned current Argentine President, Mauricio Macri, ultimately individual on the digital front. “Owning” that managed to come out on top. After almost two months information is key for the management of our personal working as President, he has already become the most reputation, particularly when important political offices influential political figure in Argentina. such as the Presidency are at stake. This survey was carried out by the Digital and Public The Online Argentine Political Influence Grid shows Affairs Areas and aimed at providing a cross-cutting how the 2.0 personality of important actors in this field look at a process that goes beyond the political sphere and their relationship with the digital environment, and involves the daily lives of the whole Argentine have impacted the 22N electoral results. nation. 3 Government Campaign and Communication The concept of “Permanent Campaign” – promoted by is what generates value: the social network “liveliness” consultants James Carville and Dick Morris when they is generated by its users and the way in which they use arrived to Argentina following the 2001 crisis – became these platforms.