The Genetic Structure of the Population of the Koplik Municipality Calculated by the Isonomy
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

V E N D I M Vendosa
REPUBLIKA E SHQIPËRISË KONTROLLI I LARTË I SHTETIT K R Y E T A R I Adresa: Rruga "Abdi Toptani" Nr.1 Tiranë. E-mail: klsh.org.al; ẁeb-site ẁẁẁ.klsh.org.al Nr. 259/6 Prot. Tiranë, më 27.06.2020 V E N D I M Nr. 73, Datë 27/06/2020 PËR AUDITIMIN E USHTRUAR NË BASHKINË MALËSI E MADHE “MBI AUDITIMIN FINANCIAR DHE TË PËRPUTHSHMËRISË” Për periudhën nga data 01.01.2018 deri më datën 30.03.2020 Në auditimin e ushtruar në subjektin Bashkinë Malësi e Madhe me objekt “Mbi auditimin financiar dhe të përputhshmërisë”, për periudhën 01.01.2018 deri më 30.03.2020, mbi shkallën e zbatueshmërisë nga subjekti, të rregullave, ligjeve dhe rregulloreve, u konstatuan të meta dhe mangësi në funksionimin e disa komponentëve të sistemit të kontrollit të brendshëm, devijime/shkelje nga kuadri ligjor dhe rregullator në fuqi, të rëndësisë materiale por jo të përhapura, efektet e të cilave justifikojnë dhënien e një opinioni financiar të kualifikuar. Pasi u njoha me Raportin Përfundimtar të Auditimit dhe Projektvendimin e paraqitur nga Grupi i Auditimit të Departamentit të Auditimit të Njësive të Vetëqeverisjes Vendore, shpjegimet e dhëna nga subjekti i audituar, si dhe vlerësimet mbi objektivitetin dhe cilësinë e auditimit nga Kryeaudituesi dhe Drejtori i Departamentit të mësipërm, Drejtori i Drejtorisë së Standardeve dhe Sigurimit të Cilësisë së Auditimit dhe Drejtori i Përgjithshëm, në mbështetje të neneve 10, 15, 25 dhe 30, të ligjit nr. 154/2014 miratuar në datën 27.11.2014 “Për Organizimin dhe Funksionimin e Kontrollit të Lartë të Shtetit”, me qëllim përmirësimin e gjendjes. -
Crystal Reports
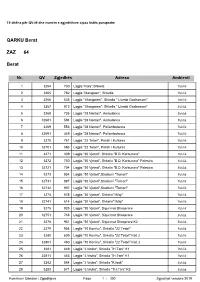
Të dhëna për QV-të dhe numrin e zgjedhësve sipas listës paraprake QARKU Berat ZAZ 64 Berat Nr. QV Zgjedhës Adresa Ambienti 1 3264 730 Lagjia "Kala",Shkolla Publik 2 3265 782 Lagjia "Mangalen", Shkolla Publik 3 3266 535 Lagjia " Mangalem", Shkolla " Llambi Goxhomani" Publik 4 3267 813 Lagjia " Mangalem", Shkolla " Llambi Goxhomani" Publik 5 3268 735 Lagjia "28 Nentori", Ambulanca Publik 6 32681 594 Lagjia "28 Nentori", Ambulanca Publik 7 3269 553 Lagjia "28 Nentori", Poliambulanca Publik 8 32691 449 Lagjia "28 Nentori", Poliambulanca Publik 9 3270 751 Lagjia "22 Tetori", Pallati I Kultures Publik 10 32701 593 Lagjia "22 Tetori", Pallati I Kultures Publik 11 3271 409 Lagjia "30 Vjetori", Shkolla "B.D. Karbunara" Publik 12 3272 750 Lagjia "30 Vjetori", Shkolla "B.D. Karbunara" Palestra Publik 13 32721 704 Lagjia "30 Vjetori", Shkolla "B.D. Karbunara" Palestra Publik 14 3273 854 Lagjia "30 Vjetori",Stadiumi "Tomori" Publik 15 32731 887 Lagjia "30 Vjetori",Stadiumi "Tomori" Publik 16 32732 907 Lagjia "30 Vjetori",Stadiumi "Tomori" Publik 17 3274 578 Lagjia "30 Vjetori", Shkolla"1Maji" Publik 18 32741 614 Lagjia "30 Vjetori", Shkolla"1Maji" Publik 19 3275 925 Lagjia "30 Vjetori", Sigurimet Shoqerore Publik 20 32751 748 Lagjia "30 Vjetori", Sigurimet Shoqerore Publik 21 3276 951 Lagjia "30 Vjetori", Sigurimet Shoqerore K2 Publik 22 3279 954 Lagjia "10 Korriku", Shkolla "22 Tetori" Publik 23 3280 509 Lagjia "10 Korriku", Shkolla "22 Tetori" Kati 2 Publik 24 32801 450 Lagjia "10 Korriku", Shkolla "22 Tetori" Kati 2 Publik 25 3281 649 Lagjia "J.Vruho", -

ACTA HISTRIAE 25, 2017, 2, Pp
ACTA HISTRIAE ACTA ACTA HISTRIAE 25, 2017, 2 25, 2017, 2 ISSN 1318-0185 Cena: 11,00 EUR UDK/UDC 94(05) ACTA HISTRIAE 25, 2017, 2, pp. 219-456 ISSN 1318-0185 UDK/UDC 94(05) ISSN 1318-0185 Zgodovinsko društvo za južno Primorsko - Koper Società storica del Litorale - Capodistria ACTA HISTRIAE 25, 2017, 2 KOPER 2017 ACTA HISTRIAE • 25 • 2017 • 2 ISSN 1318-0185 UDK/UDC 94(05) Letnik 25, leto 2017, številka 2 Odgovorni urednik/ Direttore responsabile/ Darko Darovec Editor in Chief: Uredniški odbor/ Gorazd Bajc, Furio Bianco (IT), Flavij Bonin, Dragica Čeč, Lovorka Comitato di redazione/ Čoralić (HR), Darko Darovec, Marco Fincardi (IT), Darko Friš, Aleksej Board of Editors: Kalc, Borut Klabjan, John Martin (USA), Robert Matijašić (HR), Darja Mihelič, Edward Muir (USA), Egon Pelikan, Luciano Pezzolo (IT), Jože Pirjevec, Claudio Povolo (IT), Marijan Premović (MNE), Vida Rožac Darovec, Andrej Studen, Marta Verginella, Salvator Žitko Urednik/Redattore/ Editor: Gorazd Bajc, Urška Lampe Prevodi/Traduzioni/ Translations: Urška Lampe (slo.), Gorazd Bajc (it.) Lektorji/Supervisione/ Language Editor: Urška Lampe (angl., slo.), Gorazd Bajc (it.) Stavek/Composizione/ Typesetting: Grafis trade d.o.o. Izdajatelj/Editore/ Published by: Zgodovinsko društvo za južno Primorsko / Società storica del Litorale© Sedež/Sede/Address: Zgodovinsko društvo za južno Primorsko, SI-6000 Koper-Capodistria, Garibaldijeva 18 / Via Garibaldi 18 e-mail: [email protected]; www.zdjp.si Tisk/Stampa/Print: Grafis trade d.o.o. Naklada/Tiratura/Copies: 300 izvodov/copie/copies Finančna podpora/ Javna agencija za raziskovalno dejavnost Republike Slovenije / Slovenian Supporto finanziario/ Research Agency, Mestna občina Koper, Luka Koper d.d. Financially supported by: Slika na naslovnici/ Foto di copertina/ Picture on the cover: Giaquinto Corrado: Justice and Peace – 18th Century / Pravica in mir – 18. -

Plani I Zhvillimit Të Sektorit 3 2.6.9 Nënmavriq - Niveli II
AUTORËSIA DHE KONTRIBUTET Ky dokument u hartua në kuadër të projektit "Përgatitja e masterplanit dhe studimeve të fizibilitetit për projekte infrastrukturore në zonën e Alpeve të Shqipërisë" të zbatuar nga Fondi Shqiptar i Zhvillimit, me mbështetjen financiare të Fondit të Përbashkët Evropian të Ballkanit Perëndimor nën kornizën e investimeve në rajon, përfituar nëpërmjet Bankës për Zhvillim të Këshillit të Evropës. Opinionet, gjetjet, konkluzionet dhe rekomandimet e shprehura në këtë dokument janë të autor-it/ve (konsorciumi që përbëhet nga PM Group, Archidata, Globaldit, Instituti i Politikave Publike e Private IP3, Seda) dhe nuk përfaqësojnë domosdoshmërisht ato të kontribuesve në Fondin e Përbashkët Evropian të Ballkanit Perëndimor, të EBRD, si bashkë-menaxher i Fondit të Përbashkët për Ballkanin Perëndimor, apo Bankës për Zhvillim të Këshillit të Evropës si institucion financiar kryesor në lidhje me projektin. EKSPERTËT KRYESORË (KEY EXPERTs) Gabriele Bonafede, udhëheqësi i grupit; Manfred Kojan, ekspert për marketimin dhe turizmin; Max Haberstroh, ekspert i turizmit; David Lyth, ekspert mjedisi; Fredrik Pitzner-Jorgensen, ekonomist për investimet; Ariela Kushi, ekspert i planifikimit urban; Romina Sahiti, ekspert i planifikimit urban; Endri Noçka, ekonomist urban; Gent Nechwatal, ekspert i transportit; Luan Mlloja, ekspert për ujësjellës-kanalizime; Bukurosh Onuzi, ekspert i turizmit; Genc Metohu, ekspert i turizmit; Abdulla Diku, ekspert mjedisi; Artur Galanxhi; ekspert i bujqësisë; Erin Mlloja, ekspert GIS. EKSPERTËT MBËSHTETËS (Non-KEY EXPERTs) Iva Tavanxhiu, ekspert i planifikimit urban; Orinda Biba, ekspert mjedisi; Kreshnik Bajraktari, ekspert transporti; Besmira Vishe, ekspert ligjor. 2 Alpet e Shqipërisë, 2031 P ËRMbAJTJA 1. HYRJE ............................................................................................................................. 8 1.1 ZONA NË STUDIM DHE POZICIONI RAJONAL .......................................................... 9 1.2 KONSIDERATA NGA PPK DHE STRATEGJIA KOMbËTARE E TURIZMIT ................. -

Albania: Average Precipitation for December
MA016_A1 Kelmend Margegaj Topojë Shkrel TRO PO JË S Shalë Bujan Bajram Curri Llugaj MA LËSI Lekbibaj Kastrat E MA DH E KU KË S Bytyç Fierzë Golaj Pult Koplik Qendër Fierzë Shosh S HK O D Ë R HAS Krumë Inland Gruemirë Water SHK OD RË S Iballë Body Postribë Blerim Temal Fajza PUK ËS Gjinaj Shllak Rrethina Terthorë Qelëz Malzi Fushë Arrëz Shkodër KUK ËSI T Gur i Zi Kukës Rrapë Kolsh Shkodër Qerret Qafë Mali ´ Ana e Vau i Dejës Shtiqen Zapod Pukë Malit Berdicë Surroj Shtiqen 20°E 21°E Created 16 Dec 2019 / UTC+01:00 A1 Map shows the average precipitation for December in Albania. Map Document MA016_Alb_Ave_Precip_Dec Settlements Borders Projection & WGS 1984 UTM Zone 34N B1 CAPITAL INTERNATIONAL Datum City COUNTIES Tiranë C1 MUNICIPALITIES Albania: Average Produced by MapAction ADMIN 3 mapaction.org Precipitation for D1 0 2 4 6 8 10 [email protected] Precipitation (mm) December kilometres Supported by Supported by the German Federal E1 Foreign Office. - Sheet A1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 Data sources 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 - - - 1 1 1 1 1 1 1 1 1 1 2 2 2 The depiction and use of boundaries, names and - - - - - - - - - - - - - F1 .1 .1 .1 GADM, SRTM, OpenStreetMap, WorldClim 0 0 0 .1 .1 .1 .1 .1 .1 .1 .1 .1 .1 .1 .1 .1 associated data shown here do not imply 6 7 8 0 0 0 0 0 0 0 0 0 0 0 0 0 9 0 1 2 3 4 5 6 7 8 9 0 1 endorsement or acceptance by MapAction. -

Rregjimi Komunist Vrau Dhe Pushkatoi 226 Malësorë
E PAVARUR, INFORMATIVE, HISTORIKE DHE PATRIOTIKE Botues; Vasel GILAJ, Viti i botim XXI, Nr 57, Çmimi 2 USD, New York Mars 2016 [email protected] Janar 1945 forcat e Prek Calit vrasin 57 partizanë FAQE 20-21 Zenel Shabani, “Gjenerali me xhamadan” i atdhetarisë FAQE 22-25 Pretash Zeka Ulaj, bajraktari i Kojës dhe kufinjve të Shqipërisë FAQE 26-29 Lukë Kaçaj, Shaljapini sss Shqipetar FAQE 32-35 Malësorët e Plavë e Gucisë një shekull të masakruar Rregjimi komunist FAQE 36-41 Shasi vendbanimi i hershëm ilir, qyteti vrau dhe pushkatoi i 365 kishave FAQE 42-45 Adem Demaci, Profeti i 226 malësorë Kosoves FAQE 46-48 MARS 2016 2 Ju fton të kontriboni, për promovimin dhe mbrojtjen e vlerave të patjetërsueshme që trashëguam si amanet nga të parët! E PAVARUR, INFORMATIVE, HISTORIKE DHE PATRIOTIKE INFORMATIVE, E PAVARUR, MARS 2016 3 Urdhër lirie apo ikje për liri ite me pare ne Bashkin e qytetit te shkodres,keshilli bashkiak dha nje titull nderi. Gazetaret e pranishem e pyeten kryetarin e keshillit se c’ fare ka bere ky person qe nuk e njohim,nuk e dini i pyeti Kryetari gazetaret jo than serish ata,po ky ka Vbere kerkese sqaroi kryetari. Keshtu me duket se ka ndollur edhe me Dekoraten e dhen Shoqatave Malesia e Madhe ne Detroid dhe New York,tashme nga ishe Presidentja e Kosoves A.Jahjaga ne muajin Shkurt te ketij viti,me titullin Urdheri i Lirise. Nisur nga ky fakt dhe vecanarishte nga trumbetimi dhe tundja qe po i bejne keto shoqata kesaj dekorate,dhe posacerishte ata te Detroidit ketyre zoterinjeve deshiroj tu jape dhe pa dyshim miqesishte,disa argumente per mendimin time kundershtues. -

MAPPING the GENETIC RESOURCES of AUTOCHTHONOUS FARM ANIMALS in ALBANIA Report Prepared by Prof
MAPPING THE GENETIC RESOURCES OF AUTOCHTHONOUS FARM ANIMALS IN ALBANIA Report prepared by Prof. Ass. Dr. Fatmira LEKA (SULAJ) in the framework of the UNDP-GEF Project “Strengthening human resources, legal frameworks, and institutional capacities to implement the Nagoya Protocol” (Global ABS Project). MAPPING THE GENETIC RESOURCES OF AUTOCHTHONOUS FARM ANIMALS IN ALBANIA ALBANIA, NOVEMBER 2019 TABLE OF CONTENTS List of abbreviations 6 Chapter 1. Livestock production, the methodology of national management of animal Genetic resources 8 1.1. Livestock production 8 1.2. Develop a methodology 14 1.3. Genetic diversity 18 Chapter 2. Institutional and legislative framework 22 2.1. The governmental institutions related to the management of autochthonous genetic resources in farm animals 22 2.1.1. Ministry of Agriculture and Rural Development 22 2.1.2. Ministry of Tourism and Environment 23 2.1.3. Research Institutions 24 Institute of Food Security and Veterinary and 24 Agricultural Technology Transfer Centres (ATTCS) of fushë Krujë, Korça 24 2.1.4 High Agriculture Universities 24 2.1.5 National Agency of Protected Areas in Albania (NAPA) 24 2.2 Non-governmental organizations related to the management of autochthonous genetic resources in farm animals 25 2.3 Legal framework 26 2.3.1 The legal acts related to animal genetic resources (ANGR) 26 Chapter 3. Animal genetic resources (autochthonous animal breeds/ecotypes) 28 3.1 Population size and structure 28 3.1.1 Goat 31 3.1.2 Sheep 37 4 Mapping the genetic resources of autochthonous farm animals in Albania 3.1.3 Cattle 44 Local cattle “Cow of Prespa” 46 Local cattle population - Illyrian Dwarf cattle – Lekbibaj – Tropojë 46 Local cattle population - Illyrian Dwarf cattle – Sinanaj – Tepelene 47 3.1.4 Buffalo 49 3.1.5 Pig 50 3.1.6 Poultry 52 Chapter 4. -

GEF/UNDP/GWP-MED Projetc “Enabling Transboundary Cooperation and Integrated Water Resources Management in the Extended Drin River Basin”
GEF/UNDP/GWP-MED Projetc “Enabling Transboundary Cooperation and Integrated Water Resources Management in the Extended Drin River Basin” In the framework of the Memorandum of Understanding for the Management of the Extended Transboundary Drin Basin Pilot activity “Preparation of Wastewater Management Decision Support Tool” Wastewater management solutions in the Shkodra city Shtojcë 3: ITUN qendror apo ITUN të vegjël për vendbanimet përqark liqenit të Shkodrës 1 The Coordinated Action for the implementation of the Memorandum of Understanding for the management of the Drin basin (Drin CORDA) is supported by the GEF Drin Project. Thus, the latter constitutes an institutional project implemented by the United Nations Development Programme (UNDP) and executed by the Global Water Partnership (GWP) through GWP-Mediterranean (GWP- Med), in cooperation with the United Nations Economic Commission for Europe (UNECE). The Drin Core Group (DCG), being the multilateral body responsible for the implementation of the Memorandum of Understanding serves as the Steering Committee of the Project. GWP-Med serves as the Secretariat of the DCG. Disclaimer: The document adheres to the UN rules and policies regarding the names and international status of countries and/or other geographical areas etc. The use of characterizations, names, maps or other geographical statements in this document in no way implies any political view or positions of the Parties which are executing and implementing the Project. 2 PËRMBAJTJA PËRMBAJTJA......................................................................................................................................... -

Dwelling and Living Conditions
Swiss Agency for Development and Cooperation SDC ALBANIA DWELLING AND LIVING CONDITIONS M a y, 2 0 1 4 ALBANIA DWELLING AND LIVING CONDITIONS Preface and Acknowledgment May, 2014 The 2011 Population and Housing Census of Albania is the 11th census performed in the history of Director of the Publication: Albania. The preparation and implementation of this commitment required a significant amount Gjergji FILIPI, PhD of financial and human resources. For this INSTAT has benefitted by the support of the Albanian government, the European Union and international donors. The methodology was based on the EUROSTAT and UN recommendations for the 2010 Population and Housing Censuses, taking into INSTAT consideration the specific needs of data users of Albania. Ledia Thomo Anisa Omuri In close cooperation with international donors, INSTAT has initiated a deeper analysis process in Ruzhdie Bici the census data, comparing them with other administrative indicators or indicators from different Eriona Dhamo surveys. The deepened analysis of Population and Housing Census 2011 will serve in the future to better understand and interpret correctly the Albanian society features. The information collected by TECHNICAL ASSISTENCE census is multidimensional and the analyses express several novelties like: Albanian labour market Juna Miluka and its structure, emigration dynamics, administrative division typology, population projections Kozeta Sevrani and the characteristics of housing and dwelling conditions. The series of these publications presents a new reflection on the situation of the Albanian society, helping to understand the way to invest in the infrastructure, how to help local authorities through Copyright © INSTAT 2014 urbanization phenomena, taking in account the pace of population growth in the future, or how to address employment market policies etc. -

Population and Housing Census, Shkodër 2011
Shkodër CENSUSI I POPULLSISË DHE BANESAVE 2011 POPULATION AND HOUSING CENSUS 2011 Drejtor Botimi Ph.D Ines NURJA INSTAT ASISTENCA TEKNIKE Alma Kondi Bart de Brujin Altin Xhikneli Guido Pieraccini Anila Kasneci Roberto Bianchini Anisa Omuri Blerina Subashi Emira Galanxhi Eriona Dhamo Ervin Shameti Fatjona Kraja Ledia Thomo Majlinda Nesturi Nurije Çaushi Ogerta Elezaj Olgeta Dhono Rudin Hoxha Ruzhdie Bici Teranda Jahja Copyright © INSTAT 2013 Ndalohet riprodhimi i këtij botimi apo transmetimi i tij në cilëndo formë, pa autorizim paraprak me shkrim të mbajtësit të së drejtës së autorit. No part of this publication can be reproduced or transmitted in any form or by any means without the prior written permission of the copyright holder Faqosje: Gjergji KOLLUMBI, Julian ALLIU INSTAT INSTITUTI I STATISTIKES, Blv. “Zhan D’Ark” Nr. 3, Tiranë Tel : + 355 4 2222411 / 2233356 Fax : + 355 4 2228300 E-mail : [email protected] Shtypshkronja “Adel Print” CENSUSI I POPULLSISË DHE BANESAVE 2011 SHKODËR 2 Parathënie dhe falenderime Preface and acknowledgements INSTAT mbas publikimit të Rezultateve kryesore të INSTAT after the publication of the Population and Censusit të Popullsisë dhe Banesave, vë në dispozicion Dwelling Census main results, provide to the users të përdoruesve serinë e 12 botimeve të Censusit në nivel the set of 12 publications at the Prefecture Level. Qarku. Kjo seri përmban rezultatet në nivel qarku dhe This set includes final results at the prefecture and bashkie/komune. Secili prej botimeve sjell mundësinë municipality/commune level. Each of the publications e njohjes së situatës demografike dhe sociale dhe të gives the possibility of the presantation of the soci0 ndryshimeve kryesore të hasura gjatë 10 viteteve të demographic situation and of the main changes fundit në nivel qarku dhe bashkie/komune. -

Rranxat E Malsisë Apo Myslimanët E Mbishkodrës
Manjola Arizaj (Zeka) Gojard Kodra: shembulli i kurajës, Është privilegj të luaj besimit dhe muzikë për shqiptarët e përkushtimit diaspores në 27 shtete! FAQE 20-24 FAQE 33-37 E PAVARUR, INFORMATIVE, HISTORIKE DHE PATRIOTIKEBotues; Vasel GILAJ, Viti II i botimit, Nr 3, New York, TETOR 2018 [email protected] Lohja e Vogel me histori Pse Malsia te madhe, Shirgji, Ublat dhe prejardhja FAQE 25-28 duhet të ketë Fiset joshqipetare të Shkodrës, cilët janë?! dy bashki?! FAQE 15-16 FAQE 10-11 Sa e prishën qytetin e Shkodrës malsorët?! FAQE 12-14 Skënderbeu e mori Krujën me ferman të rremë FAQE 39 Pse i’a ndryshoi Shtjefën Gjeçovi emrin Kanunit?! FAQE 40-41 Arsa, qyteti ilir me histori të grabitur! FAQE 45-46 Ura e Zhajës, Rranxat e Malsisë ku u shkrua historia me gjak apo myslimanët FAQE 47-50 Kur do ja kthejne malsoret borxhin Gjergj Fishtes e Mbishkodrës FAQE 17-18 FAQE 11-13 Tetor 2018 2 Për reklama në gazetën “Zani i Malsisë” dhe web-in www.zanimalsise.com mund të kontaktoni në numrin tel.347-932-6629 dhe email [email protected] Tetor 2018 3 “Brothers Taverna”, aty ju mundësohet, cilësia dhe korrektësia, tradita dhe modernia, shija dhe eleganca. “Brothers Taverna”, mes shumë mundësish, kjo është më e mira! KONTAKT Address: 23-01 Steinway Street, Astoria, NY 11105 C: (646) 584-9615 T: (718) 721-2424 T: (718) 721-2422 Web: brotherstavernanyc.com E-mail: [email protected] Gjithashtu, mund të na ndiqni në Facebook dhe Instagram Tetor 2018 4 Një mundësi, një zgjedhje, “Cakor” një zgjidhje Restaurant Bar - Kuzhine speciale e të gjitha llojeve - Te Cakor këndojnë këngëtarët më të mirë të të gjitha trojeve Shqipe- tare në Ballkan. -

Linjat Dhe Oraret Nderqytetase Me Autobus.Xlsx
County City Hall Company Origin Destination Place of departure Timetable Through: BERAT BERAT ALBIAN BERAT BALLSH TERMINAL 06:15; 10:15 BERAT BERAT MIRASOL BERAT CERRIK TERMINAL 7:30 BERAT BERAT OSUMI? BERAT ÇOROVODE TERMINAL 8:00; 9:00; 11:00 BERAT BERAT NIAGARA BERAT DURRËS TERMINAL 6:15; 7:10; 8:10 BERAT BERAT TROKA BERAT ELBASAN TERMINAL 5:540; 7:20; 8:45; 10:45 BERAT BERAT AIDA TRANS BERAT FIER TERMINAL 07:00; 08;00; 09:20; 12:30; 13:30 BERAT BERAT ERVISI BERAT GRAMSH TERMINAL 5:45 ;6:45 BERAT BERAT ALKET TRAVEL BERAT HIMARE TERMINAL 5:30 BERAT BERAT BACO BERAT KONISPOL TERMINAL 5:45 BERAT BERAT BITRI BERAT KORÇË TERMINAL 4:30; 5:00 BERAT BERAT STELA AR BERAT KRUJE TERMINAL 05:15; 6:30 6:30; 7:10; 8:00; 8:50; 9:30; 13:0013:40; 14:20; BERAT BERAT SHQIPONJA BERAT KUÇOVE TERMINAL 15:00; BERAT BERAT ALFA DAY BERAT LEZHE TERMINAL 5:40 BERAT BERAT LEKSI OR BERAT LUSHNJE TERMINAL 07:00; 10:00; 15:00 BERAT BERAT ALIDA BERAT PËRMET TERMINAL 7:30 BERAT BERAT KUTELLI BERAT POGRADEC TERMINAL 05:25; 6:30 BERAT BERAT OSUMI? BERAT POLIÇAN TERMINAL 6:30; 10:00; 11:45; 16:00 BERAT BERAT NIKJORG BERAT SARANDE TERMINAL 8:00 KAKAVIJE 4:30; 5:00; 5:20; 6:00; 6:30; 7:00; 7:30; 8:00; 8:30; BERAT BERAT MANGALEMI BERAT TIRANE TERMINAL 9:00; BERAT BERAT LEKSI OR BERAT VLORË TERMINAL 6:00;6:30;7:30:8:30:9:20:10:00 BERAT ÇOROVODE ARTIO DULLLARI ÇOROVODE POLIÇAN CENTER 6:30; 10:45 BERAT ÇOROVODE OSUMI ÇOROVODE TIRANE CENTER 5:00; 7:00; 9:00; 10:30 BERAT KUÇOVE DOLESE KUÇOVE BERAT CENTER 6:15 until 9:30; 12:45 until 16:00 every 15 minutes BERAT KUÇOVE ALB‐ENIO