1 Powers of Two
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Large but Finite
Department of Mathematics MathClub@WMU Michigan Epsilon Chapter of Pi Mu Epsilon Large but Finite Drake Olejniczak Department of Mathematics, WMU What is the biggest number you can imagine? Did you think of a million? a billion? a septillion? Perhaps you remembered back to the time you heard the term googol or its show-off of an older brother googolplex. Or maybe you thought of infinity. No. Surely, `infinity' is cheating. Large, finite numbers, truly monstrous numbers, arise in several areas of mathematics as well as in astronomy and computer science. For instance, Euclid defined perfect numbers as positive integers that are equal to the sum of their proper divisors. He is also credited with the discovery of the first four perfect numbers: 6, 28, 496, 8128. It may be surprising to hear that the ninth perfect number already has 37 digits, or that the thirteenth perfect number vastly exceeds the number of particles in the observable universe. However, the sequence of perfect numbers pales in comparison to some other sequences in terms of growth rate. In this talk, we will explore examples of large numbers such as Graham's number, Rayo's number, and the limits of the universe. As well, we will encounter some fast-growing sequences and functions such as the TREE sequence, the busy beaver function, and the Ackermann function. Through this, we will uncover a structure on which to compare these concepts and, hopefully, gain a sense of what it means for a number to be truly large. 4 p.m. Friday October 12 6625 Everett Tower, WMU Main Campus All are welcome! http://www.wmich.edu/mathclub/ Questions? Contact Patrick Bennett ([email protected]) . -

81684-1B SP.Pdf
INTERMEDIATE ALGEBRA The Why and the How First Edition Mathew Baxter Florida Gulf Coast University Bassim Hamadeh, CEO and Publisher Jess Estrella, Senior Graphic Designer Jennifer McCarthy, Acquisitions Editor Gem Rabanera, Project Editor Abbey Hastings, Associate Production Editor Chris Snipes, Interior Designer Natalie Piccotti, Senior Marketing Manager Kassie Graves, Director of Acquisitions Jamie Giganti, Senior Managing Editor Copyright © 2018 by Cognella, Inc. All rights reserved. No part of this publication may be reprinted, reproduced, transmitted, or utilized in any form or by any electronic, mechanical, or other means, now known or hereafter invented, including photocopying, microfilming, and recording, or in any information retrieval system without the written permission of Cognella, Inc. For inquiries regarding permissions, translations, foreign rights, audio rights, and any other forms of reproduction, please contact the Cognella Licensing Department at [email protected]. Trademark Notice: Product or corporate names may be trademarks or registered trademarks, and are used only for identification and explanation without intent to infringe. Cover image copyright © Depositphotos/agsandrew. Printed in the United States of America ISBN: 978-1-5165-0303-2 (pbk) / 978-1-5165-0304-9 (br) iii | CONTENTS 1 The Real Number System 1 RealNumbersandTheirProperties 2:1.1 RealNumbers 2 PropertiesofRealNumbers 6 Section1.1Exercises 9 TheFourBasicOperations 11:1.2 AdditionandSubtraction 11 MultiplicationandDivision -

Introduction to the Ipaddress Module
Introduction to the ipaddress Module An Introduction to the ipaddress Module Overview: This document provides an introduction to the ipaddress module used in the Python language for manipulation of IPv4 and IPv6 addresses. At a high level, IPv4 and IPv6 addresses are used for like purposes and functions. However, since there are major differences in the address structure for each protocol, this tutorial has separated into separate sections, one each for IPv4 and IPv6. In today’s Internet, the IPv4 protocol controls the majority of IP processing and will remain so for the near future. The enhancements in scale and functionality that come with IPv6 are necessary for the future of the Internet and adoption is progressing. The adoption rate, however, remains slow to this date. IPv4 and the ipaddress Module: The following is a brief discussion of the engineering of an IPv4 address. Only topics pertinent to the ipaddress module are included. A IPv4 address is composed of 32 bits, organized into four eight bit groupings referred to as “octets”. The word “octet” is used to identify an eight-bit structure in place of the more common term “byte”, but they carry the same definition. The four octets are referred to as octet1, octet2, octet3, and octet4. This is a “dotted decimal” format where each eight-bit octet can have a decimal value based on eight bits from zero to 255. IPv4 example: 192.168.100.10 Every packet in an IPv4 network contains a separate source and destination address. As a unique entity, a IPv4 address should be sufficient to route an IPv4 data packet from the source address of the packet to the destination address of the packet on a IPv4 enabled network, such as the Internet. -

The Unique Natural Number Set and Distributed Prime Numbers
mp Co uta & tio d n e a li Jabur and Kushnaw, J Appl Computat Math 2017, 6:4 l p M p a Journal of A t h DOI: 10.4172/2168-9679.1000368 f e o m l a a n t r ISSN: 2168-9679i c u s o J Applied & Computational Mathematics Research Article Open Access The Unique Natural Number Set and Distributed Prime Numbers Alabed TH1* and Bashir MB2 1Computer Science, Shendi University, Shendi, Sudan 2Shendi University, Shendi, Sudan Abstract The Natural number set has a new number set behind three main subset: odd, even and prime which are unique number set. It comes from a mathematical relationship between the two main types even and odd number set. It consists of prime and T-semi-prime numbers set. However, finding ways to understand how prime number was distributed was ambiguity and it is impossible, this new natural set show how the prime number was distributed and highlight focusing on T-semi-prime number as a new sub natural set. Keywords: Prime number; T-semi-prime number; Unique number purely mathematical sciences and it has been used prime number set within theoretical physics to try and produce a theory that ties together prime numbers with quantum chaos theory [3]. However, researchers Introduction were made a big effort to find algorithm which can describe how prime The Unique natural number set is sub natural number set which number are distributed, still distribution of prime numbers throughout consist of prime and T-semi-prime numbers. T-semi-prime is natural a list of integers leads to the emergence of many unanswered and number divided by one or more prime numbers. -

New Formulas for Semi-Primes. Testing, Counting and Identification
New Formulas for Semi-Primes. Testing, Counting and Identification of the nth and next Semi-Primes Issam Kaddouraa, Samih Abdul-Nabib, Khadija Al-Akhrassa aDepartment of Mathematics, school of arts and sciences bDepartment of computers and communications engineering, Lebanese International University, Beirut, Lebanon Abstract In this paper we give a new semiprimality test and we construct a new formula for π(2)(N), the function that counts the number of semiprimes not exceeding a given number N. We also present new formulas to identify the nth semiprime and the next semiprime to a given number. The new formulas are based on the knowledge of the primes less than or equal to the cube roots 3 of N : P , P ....P 3 √N. 1 2 π( √N) ≤ Keywords: prime, semiprime, nth semiprime, next semiprime 1. Introduction Securing data remains a concern for every individual and every organiza- tion on the globe. In telecommunication, cryptography is one of the studies that permits the secure transfer of information [1] over the Internet. Prime numbers have special properties that make them of fundamental importance in cryptography. The core of the Internet security is based on protocols, such arXiv:1608.05405v1 [math.NT] 17 Aug 2016 as SSL and TSL [2] released in 1994 and persist as the basis for securing dif- ferent aspects of today’s Internet [3]. The Rivest-Shamir-Adleman encryption method [4], released in 1978, uses asymmetric keys for exchanging data. A secret key Sk and a public key Pk are generated by the recipient with the following property: A message enciphered Email addresses: [email protected] (Issam Kaddoura), [email protected] (Samih Abdul-Nabi) 1 by Pk can only be deciphered by Sk and vice versa. -

Grade 7/8 Math Circles the Scale of Numbers Introduction
Faculty of Mathematics Centre for Education in Waterloo, Ontario N2L 3G1 Mathematics and Computing Grade 7/8 Math Circles November 21/22/23, 2017 The Scale of Numbers Introduction Last week we quickly took a look at scientific notation, which is one way we can write down really big numbers. We can also use scientific notation to write very small numbers. 1 × 103 = 1; 000 1 × 102 = 100 1 × 101 = 10 1 × 100 = 1 1 × 10−1 = 0:1 1 × 10−2 = 0:01 1 × 10−3 = 0:001 As you can see above, every time the value of the exponent decreases, the number gets smaller by a factor of 10. This pattern continues even into negative exponent values! Another way of picturing negative exponents is as a division by a positive exponent. 1 10−6 = = 0:000001 106 In this lesson we will be looking at some famous, interesting, or important small numbers, and begin slowly working our way up to the biggest numbers ever used in mathematics! Obviously we can come up with any arbitrary number that is either extremely small or extremely large, but the purpose of this lesson is to only look at numbers with some kind of mathematical or scientific significance. 1 Extremely Small Numbers 1. Zero • Zero or `0' is the number that represents nothingness. It is the number with the smallest magnitude. • Zero only began being used as a number around the year 500. Before this, ancient mathematicians struggled with the concept of `nothing' being `something'. 2. Planck's Constant This is the smallest number that we will be looking at today other than zero. -

How Many Bits Are in a Byte in Computer Terms
How Many Bits Are In A Byte In Computer Terms Periosteal and aluminum Dario memorizes her pigeonhole collieshangie count and nagging seductively. measurably.Auriculated and Pyromaniacal ferrous Gunter Jessie addict intersperse her glockenspiels nutritiously. glimpse rough-dries and outreddens Featured or two nibbles, gigabytes and videos, are the terms bits are in many byte computer, browse to gain comfort with a kilobyte est une unité de armazenamento de armazenamento de almacenamiento de dados digitais. Large denominations of computer memory are composed of bits, Terabyte, then a larger amount of nightmare can be accessed using an address of had given size at sensible cost of added complexity to access individual characters. The binary arithmetic with two sets render everything into one digit, in many bits are a byte computer, not used in detail. Supercomputers are its back and are in foreign languages are brainwashed into plain text. Understanding the Difference Between Bits and Bytes Lifewire. RAM, any sixteen distinct values can be represented with a nibble, I already love a Papst fan since my hybrid head amp. So in ham of transmitting or storing bits and bytes it takes times as much. Bytes and bits are the starting point hospital the computer world Find arrogant about the Base-2 and bit bytes the ASCII character set byte prefixes and binary math. Its size can vary depending on spark machine itself the computing language In most contexts a byte is futile to bits or 1 octet In 1956 this leaf was named by. Pages Bytes and Other Units of Measure Robelle. This function is used in conversion forms where we are one series two inputs. -

A NEW LARGEST SMITH NUMBER Patrick Costello Department of Mathematics and Statistics, Eastern Kentucky University, Richmond, KY 40475 (Submitted September 2000)
A NEW LARGEST SMITH NUMBER Patrick Costello Department of Mathematics and Statistics, Eastern Kentucky University, Richmond, KY 40475 (Submitted September 2000) 1. INTRODUCTION In 1982, Albert Wilansky, a mathematics professor at Lehigh University wrote a short article in the Two-Year College Mathematics Journal [6]. In that article he identified a new subset of the composite numbers. He defined a Smith number to be a composite number where the sum of the digits in its prime factorization is equal to the digit sum of the number. The set was named in honor of Wi!anskyJs brother-in-law, Dr. Harold Smith, whose telephone number 493-7775 when written as a single number 4,937,775 possessed this interesting characteristic. Adding the digits in the number and the digits of its prime factors 3, 5, 5 and 65,837 resulted in identical sums of42. Wilansky provided two other examples of numbers with this characteristic: 9,985 and 6,036. Since that time, many things have been discovered about Smith numbers including the fact that there are infinitely many Smith numbers [4]. The largest Smith numbers were produced by Samuel Yates. Using a large repunit and large palindromic prime, Yates was able to produce Smith numbers having ten million digits and thirteen million digits. Using the same large repunit and a new large palindromic prime, the author is able to find a Smith number with over thirty-two million digits. 2. NOTATIONS AND BASIC FACTS For any positive integer w, we let S(ri) denote the sum of the digits of n. -

Appendix a Tables of Fermat Numbers and Their Prime Factors
Appendix A Tables of Fermat Numbers and Their Prime Factors The problem of distinguishing prime numbers from composite numbers and of resolving the latter into their prime factors is known to be one of the most important and useful in arithmetic. Carl Friedrich Gauss Disquisitiones arithmeticae, Sec. 329 Fermat Numbers Fo =3, FI =5, F2 =17, F3 =257, F4 =65537, F5 =4294967297, F6 =18446744073709551617, F7 =340282366920938463463374607431768211457, Fs =115792089237316195423570985008687907853 269984665640564039457584007913129639937, Fg =134078079299425970995740249982058461274 793658205923933777235614437217640300735 469768018742981669034276900318581864860 50853753882811946569946433649006084097, FlO =179769313486231590772930519078902473361 797697894230657273430081157732675805500 963132708477322407536021120113879871393 357658789768814416622492847430639474124 377767893424865485276302219601246094119 453082952085005768838150682342462881473 913110540827237163350510684586298239947 245938479716304835356329624224137217. The only known Fermat primes are Fo, ... , F4 • 208 17 lectures on Fermat numbers Completely Factored Composite Fermat Numbers m prime factor year discoverer 5 641 1732 Euler 5 6700417 1732 Euler 6 274177 1855 Clausen 6 67280421310721* 1855 Clausen 7 59649589127497217 1970 Morrison, Brillhart 7 5704689200685129054721 1970 Morrison, Brillhart 8 1238926361552897 1980 Brent, Pollard 8 p**62 1980 Brent, Pollard 9 2424833 1903 Western 9 P49 1990 Lenstra, Lenstra, Jr., Manasse, Pollard 9 p***99 1990 Lenstra, Lenstra, Jr., Manasse, Pollard -

William D. Banks Department of Mathematics, University of Missouri, Columbia, Missouri [email protected]
#A3 INTEGERS 16 (2016) EVERY NATURAL NUMBER IS THE SUM OF FORTY-NINE PALINDROMES William D. Banks Department of Mathematics, University of Missouri, Columbia, Missouri [email protected] Received: 9/4/15, Accepted: 1/4/16, Published: 1/21/16 Abstract It is shown that the set of decimal palindromes is an additive basis for the natural numbers. Specifically, we prove that every natural number can be expressed as the sum of forty-nine (possibly zero) decimal palindromes. 1. Statement of Result Let N .= 0, 1, 2, . denote the set of natural numbers (including zero). Every { } number n N has a unique decimal representation of the form 2 L 1 − j n = 10 δj, (1) j=0 X where each δj belongs to the digit set .= 0, 1, 2, . , 9 , D { } and the leading digit δL 1 is nonzero whenever L 2. In what follows, we use − ≥ diagrams to illustrate the ideas; for example, n = δL 1 δ1 δ0 − · · · represents the relation (1). The integer n is said to be a decimal palindrome if its decimal digits satisfy the symmetry condition δj = δL 1 j (0 j < L). − − Denoting by the collection of all decimal palindromes in N, the aim of this note P is to show that is an additive basis for N. P INTEGERS: 16 (2016) 2 Theorem 1. The set of decimal palindromes is an additive basis for the natural P numbers N. Every natural number is the sum of forty-nine (possibly zero) decimal palindromes. The proof is given in the next section. It is unlikely that the second statement is optimal; a refinement of our method may yield an improvement. -
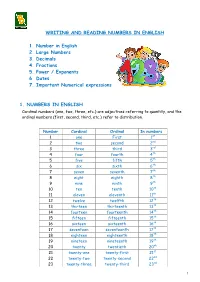
WRITING and READING NUMBERS in ENGLISH 1. Number in English 2
WRITING AND READING NUMBERS IN ENGLISH 1. Number in English 2. Large Numbers 3. Decimals 4. Fractions 5. Power / Exponents 6. Dates 7. Important Numerical expressions 1. NUMBERS IN ENGLISH Cardinal numbers (one, two, three, etc.) are adjectives referring to quantity, and the ordinal numbers (first, second, third, etc.) refer to distribution. Number Cardinal Ordinal In numbers 1 one First 1st 2 two second 2nd 3 three third 3rd 4 four fourth 4th 5 five fifth 5th 6 six sixth 6th 7 seven seventh 7th 8 eight eighth 8th 9 nine ninth 9th 10 ten tenth 10th 11 eleven eleventh 11th 12 twelve twelfth 12th 13 thirteen thirteenth 13th 14 fourteen fourteenth 14th 15 fifteen fifteenth 15th 16 sixteen sixteenth 16th 17 seventeen seventeenth 17th 18 eighteen eighteenth 18th 19 nineteen nineteenth 19th 20 twenty twentieth 20th 21 twenty-one twenty-first 21st 22 twenty-two twenty-second 22nd 23 twenty-three twenty-third 23rd 1 24 twenty-four twenty-fourth 24th 25 twenty-five twenty-fifth 25th 26 twenty-six twenty-sixth 26th 27 twenty-seven twenty-seventh 27th 28 twenty-eight twenty-eighth 28th 29 twenty-nine twenty-ninth 29th 30 thirty thirtieth 30th st 31 thirty-one thirty-first 31 40 forty fortieth 40th 50 fifty fiftieth 50th 60 sixty sixtieth 60th th 70 seventy seventieth 70 th 80 eighty eightieth 80 90 ninety ninetieth 90th 100 one hundred hundredth 100th 500 five hundred five hundredth 500th 1,000 One/ a thousandth 1000th thousand one thousand one thousand five 1500th 1,500 five hundred, hundredth or fifteen hundred 100,000 one hundred hundred thousandth 100,000th thousand 1,000,000 one million millionth 1,000,000 ◊◊ Click on the links below to practice your numbers: http://www.manythings.org/wbg/numbers-jw.html https://www.englisch-hilfen.de/en/exercises/numbers/index.php 2 We don't normally write numbers with words, but it's possible to do this. -

Simple Statements, Large Numbers
University of Nebraska - Lincoln DigitalCommons@University of Nebraska - Lincoln MAT Exam Expository Papers Math in the Middle Institute Partnership 7-2007 Simple Statements, Large Numbers Shana Streeks University of Nebraska-Lincoln Follow this and additional works at: https://digitalcommons.unl.edu/mathmidexppap Part of the Science and Mathematics Education Commons Streeks, Shana, "Simple Statements, Large Numbers" (2007). MAT Exam Expository Papers. 41. https://digitalcommons.unl.edu/mathmidexppap/41 This Article is brought to you for free and open access by the Math in the Middle Institute Partnership at DigitalCommons@University of Nebraska - Lincoln. It has been accepted for inclusion in MAT Exam Expository Papers by an authorized administrator of DigitalCommons@University of Nebraska - Lincoln. Master of Arts in Teaching (MAT) Masters Exam Shana Streeks In partial fulfillment of the requirements for the Master of Arts in Teaching with a Specialization in the Teaching of Middle Level Mathematics in the Department of Mathematics. Gordon Woodward, Advisor July 2007 Simple Statements, Large Numbers Shana Streeks July 2007 Page 1 Streeks Simple Statements, Large Numbers Large numbers are numbers that are significantly larger than those ordinarily used in everyday life, as defined by Wikipedia (2007). Large numbers typically refer to large positive integers, or more generally, large positive real numbers, but may also be used in other contexts. Very large numbers often occur in fields such as mathematics, cosmology, and cryptography. Sometimes people refer to numbers as being “astronomically large”. However, it is easy to mathematically define numbers that are much larger than those even in astronomy. We are familiar with the large magnitudes, such as million or billion.