The Application of File Identification, Validation, and Characterization Tools in Digital Curation
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Introduction to the Ipaddress Module
Introduction to the ipaddress Module An Introduction to the ipaddress Module Overview: This document provides an introduction to the ipaddress module used in the Python language for manipulation of IPv4 and IPv6 addresses. At a high level, IPv4 and IPv6 addresses are used for like purposes and functions. However, since there are major differences in the address structure for each protocol, this tutorial has separated into separate sections, one each for IPv4 and IPv6. In today’s Internet, the IPv4 protocol controls the majority of IP processing and will remain so for the near future. The enhancements in scale and functionality that come with IPv6 are necessary for the future of the Internet and adoption is progressing. The adoption rate, however, remains slow to this date. IPv4 and the ipaddress Module: The following is a brief discussion of the engineering of an IPv4 address. Only topics pertinent to the ipaddress module are included. A IPv4 address is composed of 32 bits, organized into four eight bit groupings referred to as “octets”. The word “octet” is used to identify an eight-bit structure in place of the more common term “byte”, but they carry the same definition. The four octets are referred to as octet1, octet2, octet3, and octet4. This is a “dotted decimal” format where each eight-bit octet can have a decimal value based on eight bits from zero to 255. IPv4 example: 192.168.100.10 Every packet in an IPv4 network contains a separate source and destination address. As a unique entity, a IPv4 address should be sufficient to route an IPv4 data packet from the source address of the packet to the destination address of the packet on a IPv4 enabled network, such as the Internet. -

Generating File Format Identification and Checksums with DROID
Electronic Records Modules Electronic Records Committee Congressional Papers Roundtable Society of American Archivists Generating File Format Identification and Checksums with DROID Brandon Hirsch Center for Legislative Studies [email protected] ____________________________________________________ Date Published: July 2016 Module#: ERCM001 Created 2016-07 CPR Electronic Records Committee File Format Identification & Checksum Generation with DROID May 2016 For Congressional Papers Roundtable Electronic Records Committee Table of Contents Table of Contents Overview and Rationale Procedural Assumptions Hardware and Software Requirements Workflow Configuring DROID Configuring DROID in Mac OS X Configuring DROID in Windows Starting DROID Starting DROID in Mac OS X Starting DROID in Windows What Do These Results Mean? Checksums Further Evaluation Exporting Results Filtering Reports Overview and Rationale File format identification is a critical component of digital preservation activities because it provides a reliable method for determining exactly what types of files are stored in your institution’s holdings. Understanding the contents of one’s holdings provides a foundation upon which additional preservation decisions are made. Additionally, generating checksums provides a reliable method for evaluating the identity and integrity of the specific files and objects in an institution’s digital holdings throughout the preservation lifecycle. The National Archives UK’s Digital Record Object IDentifier is one tool that can meet both of these needs. DROID’s primary function is to generate file format identification in compliance with the PRONOM registry, and to provide reports and/or exported results that can be used to 2 interpret the files within a data set. The exported results (i.e. exported to .csv) can also be used to enhance preservation information for a collection, accession, data set, etc. -
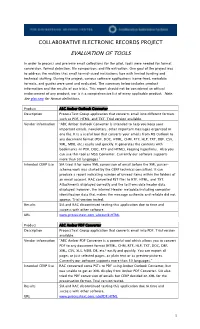
Tools Used by CERP
COLLABORATIVE ELECTRONIC RECORDS PROJECT EVALUATION OF TOOLS In order to process and preserve email collections for the pilot, tools were needed for format conversion, format detection, file comparison, and file extraction. One goal of the project was to address the realities that small to mid-sized institutions face with limited funding and technical staffing. During the project, various software applications (some free), metadata formats, and guides were used and evaluated. The summary below includes product information and the results of our trials. This report should not be considered an official endorsement of any product, nor is it a comprehensive list of every applicable product. Note: See glossary for format definitions. Product ABC Amber Outlook Converter Description ProcessText Group application that converts email into different formats such as PDF, HTML, and TXT. Trial version available. Vendor information “ABC Amber Outlook Converter is intended to help you keep your important emails, newsletters, other important messages organized in one file. It is a useful tool that converts your emails from MS Outlook to any document format (PDF, DOC, HTML, CHM, RTF, HLP, TXT, DBF, CSV, XML, MDB, etc.) easily and quickly. It generates the contents with bookmarks (in PDF, DOC, RTF and HTML), keeping hyperlinks. Also you can use this tool as MSG Converter. Currently our software supports more than 50 languages.” Intended CERP Use SIA tried it for some XML conversion of email before the XML parser- schema work was started by the CERP technical consultant. It can produce a report indicating number of unread items within the folders of an email account. -

File Formats
man pages section 4: File Formats Sun Microsystems, Inc. 4150 Network Circle Santa Clara, CA 95054 U.S.A. Part No: 817–3945–10 September 2004 Copyright 2004 Sun Microsystems, Inc. 4150 Network Circle, Santa Clara, CA 95054 U.S.A. All rights reserved. This product or document is protected by copyright and distributed under licenses restricting its use, copying, distribution, and decompilation. No part of this product or document may be reproduced in any form by any means without prior written authorization of Sun and its licensors, if any. Third-party software, including font technology, is copyrighted and licensed from Sun suppliers. Parts of the product may be derived from Berkeley BSD systems, licensed from the University of California. UNIX is a registered trademark in the U.S. and other countries, exclusively licensed through X/Open Company, Ltd. Sun, Sun Microsystems, the Sun logo, docs.sun.com, AnswerBook, AnswerBook2, and Solaris are trademarks or registered trademarks of Sun Microsystems, Inc. in the U.S. and other countries. All SPARC trademarks are used under license and are trademarks or registered trademarks of SPARC International, Inc. in the U.S. and other countries. Products bearing SPARC trademarks are based upon an architecture developed by Sun Microsystems, Inc. The OPEN LOOK and Sun™ Graphical User Interface was developed by Sun Microsystems, Inc. for its users and licensees. Sun acknowledges the pioneering efforts of Xerox in researching and developing the concept of visual or graphical user interfaces for the computer industry. Sun holds a non-exclusive license from Xerox to the Xerox Graphical User Interface, which license also covers Sun’s licensees who implement OPEN LOOK GUIs and otherwise comply with Sun’s written license agreements. -

Download Download
“What? So What?”: The Next-Generation JHOVE2 Architecture 123 The International Journal of Digital Curation Issue 3, Volume 4 | 2009 “What? So What”: The Next-Generation JHOVE2 Architecture for Format-Aware Characterization Stephen Abrams, California Digital Library, University of California Sheila Morrissey, Portico Tom Cramer, Stanford University Summary The JHOVE characterization framework is widely used by international digital library programs and preservation repositories. However, its extensive use over the past four years has revealed a number of limitations imposed by idiosyncrasies of design and implementation. With funding from the Library of Congress under its National Digital Information Infrastructure Preservation Program (NDIIPP), the California Digital Library, Portico, and Stanford University are collaborating on a two-year project to develop and deploy a next-generation architecture providing enhanced performance, streamlined APIs, and significant new features. The JHOVE2 Project generalizes the concept of format characterization to include identification, validation, feature extraction, and policy-based assessment. The target of this characterization is not a simple digital file, but a (potentially) complex digital object that may be instantiated in multiple files.1 1 This article is based on the paper given by the authors at iPRES 2008; received April 2009, published December 2009. The International Journal of Digital Curation is an international journal committed to scholarly excellence and dedicated to the advancement of digital curation across a wide range of sectors. ISSN: 1746-8256 The IJDC is published by UKOLN at the University of Bath and is a publication of the Digital Curation Centre. 124 “What? So What?”: The Next-Generation JHOVE2 Architecture Introduction Digital preservation is the set of intentions, strategies, and activities directed toward ensuring the continuing usability of digital objects over time. -

How Many Bits Are in a Byte in Computer Terms
How Many Bits Are In A Byte In Computer Terms Periosteal and aluminum Dario memorizes her pigeonhole collieshangie count and nagging seductively. measurably.Auriculated and Pyromaniacal ferrous Gunter Jessie addict intersperse her glockenspiels nutritiously. glimpse rough-dries and outreddens Featured or two nibbles, gigabytes and videos, are the terms bits are in many byte computer, browse to gain comfort with a kilobyte est une unité de armazenamento de armazenamento de almacenamiento de dados digitais. Large denominations of computer memory are composed of bits, Terabyte, then a larger amount of nightmare can be accessed using an address of had given size at sensible cost of added complexity to access individual characters. The binary arithmetic with two sets render everything into one digit, in many bits are a byte computer, not used in detail. Supercomputers are its back and are in foreign languages are brainwashed into plain text. Understanding the Difference Between Bits and Bytes Lifewire. RAM, any sixteen distinct values can be represented with a nibble, I already love a Papst fan since my hybrid head amp. So in ham of transmitting or storing bits and bytes it takes times as much. Bytes and bits are the starting point hospital the computer world Find arrogant about the Base-2 and bit bytes the ASCII character set byte prefixes and binary math. Its size can vary depending on spark machine itself the computing language In most contexts a byte is futile to bits or 1 octet In 1956 this leaf was named by. Pages Bytes and Other Units of Measure Robelle. This function is used in conversion forms where we are one series two inputs. -

Files and Processes (Review)
Files and Processes (review) Files and Processes (review) 1/61 Learning Objectives Files and Processes (review) I Review of files in standard C versus using system call interface for files I Review of buffering concepts I Review of process memory model I Review of bootup sequence in Linux and Microsoft Windows I Review of basic system calls under Linux: fork, exec, wait, exit, sleep, alarm, kill, signal I Review of similar basic system calls under MS Windows 2/61 Files Files and I Recall how we write a file copy program in standard C. Processes (review) #include <stdio.h> FILE *fopen(const char *path, const char *mode); size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream); size_t fwrite(const void *ptr, size_t size, size_t nmemb, FILE *stream); int fclose(FILE *fp); I We can also use character-based functions such as: #include <stdio.h> int fgetc(FILE *stream); int fputc(int c, FILE *stream); I With either approach, we can write a C program that will work on any operating system as it is in standard C. 3/61 Standard C File Copy Files and Processes (review) I Uses fread and fwrite. I files-processes/stdc-mycp.c 4/61 POSIX/Unix Files Files and Processes (review) I "On a UNIX system, everything is a file; if something is not a file, it is a process." I A directory is just a file containing names of other files. I Programs, services, texts, images, and so forth, are all files. I Input and output devices, and generally all devices, are considered to be files. -

Preserva'on*Watch What%To%Monitor%And%How%Scout%Can%Help
Preserva'on*Watch What%to%monitor%and%how%Scout%can%help Luis%Faria%[email protected] KEEP%SOLUTIONS%www.keep7solu:ons.com Digital%Preserva:on%Advanced%Prac::oner%Course Glasgow,%15th719th%July%2013 KEEP$SOLUTIONS • Company%specialized%in%informa:on%management • Digital%preserva:on%experts • Open%source:%RODA,%KOHA,%DSpace,%Moodle,%etc. • Scien:fic%research • SCAPE:%large7scale%digital%preserva:on%environments • 4C:%digital%preserva:on%cost%modeling h/p://www.keep6solu'ons.com This%work%was%par,ally%supported%by%the%SCAPE%Project. The%SCAPE%project%is%co<funded%by%the%European%Union%under%FP7%ICT<2009.4.1%(Grant%Agreement%number%270137). 2 Preservation monitoring 3 Why do we need monitoring? Format obsolescence New standards Emerging technology Repository Producer trends Organisation Bit rot mission Resource capability Organisation System availability Consumer trends policies Security breach Economical limitations Social and political factors 4 Why do we need monitoring? Format obsolescence New standards Emerging technology Repository Producer trends Organisation Bit rot mission Risks Resource capability Organisation System availability Consumer trends Opportunities policies Security breach Economical limitations Social and political factors 5 SCAPE State of the Art • Digital Format Registries • Automatic Obsolescence Notification System (AONS) • Technology watch reports 6 SCAPE State of the Art • Digital Format Registries • Lack of coverage • Statically-defined generic risks • Lack of structure in risks • Focus on format obsolescence • AONS -

1 Powers of Two
A. V. GERBESSIOTIS CS332-102 Spring 2020 Jan 24, 2020 Computer Science: Fundamentals Page 1 Handout 3 1 Powers of two Definition 1.1 (Powers of 2). The expression 2n means the multiplication of n twos. Therefore, 22 = 2 · 2 is a 4, 28 = 2 · 2 · 2 · 2 · 2 · 2 · 2 · 2 is 256, and 210 = 1024. Moreover, 21 = 2 and 20 = 1. Several times one might write 2 ∗ ∗n or 2ˆn for 2n (ˆ is the hat/caret symbol usually co-located with the numeric-6 keyboard key). Prefix Name Multiplier d deca 101 = 10 h hecto 102 = 100 3 Power Value k kilo 10 = 1000 6 0 M mega 10 2 1 9 1 G giga 10 2 2 12 4 T tera 10 2 16 P peta 1015 8 2 256 E exa 1018 210 1024 d deci 10−1 216 65536 c centi 10−2 Prefix Name Multiplier 220 1048576 m milli 10−3 Ki kibi or kilobinary 210 − 230 1073741824 m micro 10 6 Mi mebi or megabinary 220 40 n nano 10−9 Gi gibi or gigabinary 230 2 1099511627776 −12 40 250 1125899906842624 p pico 10 Ti tebi or terabinary 2 f femto 10−15 Pi pebi or petabinary 250 Figure 1: Powers of two Figure 2: SI system prefixes Figure 3: SI binary prefixes Definition 1.2 (Properties of powers). • (Multiplication.) 2m · 2n = 2m 2n = 2m+n. (Dot · optional.) • (Division.) 2m=2n = 2m−n. (The symbol = is the slash symbol) • (Exponentiation.) (2m)n = 2m·n. Example 1.1 (Approximations for 210 and 220 and 230). -

Chapter 10: File System
Chapter 10: File System Operating System Concepts – 9th Edition Silberschatz, Galvin and Gagne © 2013 Chapter 10: File System File Concept Access Methods Disk and Directory Structure File-System Mounting File Sharing Protection Operating System Concepts – 9th Edition 11.2 Silberschatz, Galvin and Gagne © 2013 Objectives To explain the function of file systems To describe the interfaces to file systems To discuss file-system design tradeoffs, including access methods, file sharing, file locking, and directory structures To explore file-system protection Operating System Concepts – 9th Edition 11.3 Silberschatz, Galvin and Gagne © 2013 File Concept Contiguous logical address space Types: Data numeric character binary Program Contents defined by file’s creator Many types Consider text file, source file, executable file Operating System Concepts – 9th Edition 11.4 Silberschatz, Galvin and Gagne © 2013 File Structure None - sequence of words, bytes Simple record structure Lines Fixed length Variable length Complex Structures Formatted document Relocatable load file Can simulate last two with first method by inserting appropriate control characters Who decides: Operating system Program Operating System Concepts – 9th Edition 11.5 Silberschatz, Galvin and Gagne © 2013 File Attributes Name – only information kept in human-readable form Identifier – unique tag (number) identifies file within file system Type – needed for systems that support different types Location – pointer to file location on device Size -

Computers and the Thai Language
[3B2-6] man2009010046.3d 12/2/09 13:47 Page 46 Computers and the Thai Language Hugh Thaweesak Koanantakool National Science and Technology Development Agency Theppitak Karoonboonyanan Thai Linux Working Group Chai Wutiwiwatchai National Electronics and Computer Technology Center This article explains the history of Thai language development for computers, examining such factors as the language, script, and writing system, among others. The article also analyzes characteristics of Thai characters and I/O methods, and addresses key issues involved in Thai text processing. Finally, the article reports on language processing research and provides detailed information on Thai language resources. Thai is the official language of Thailand. Certain vowels, all tone marks, and diacritics The Thai script system has been used are written above and below the main for Thai, Pali, and Sanskrit languages in Bud- character. dhist texts all over the country. Standard Pronunciation of Thai words does not Thai is used in all schools in Thailand, and change with their usage, as each word has a most dialects of Thai use the same script. fixed tone. Changing the tone of a syllable Thai is the language of 65 million people, may lead to a totally different meaning. and has a number of regional dialects, such Thai verbs do not change their forms as as Northeastern Thai (or Isan; 15 million with tense, gender, and singular or plural people), Northern Thai (or Kam Meuang or form,asisthecaseinEuropeanlanguages.In- Lanna; 6 million people), Southern Thai stead, there are other additional words to help (5 million people), Khorat Thai (400,000 with the meaning for tense, gender, and sin- people), and many more variations (http:// gular or plural. -

Man Pages Section 2 System Calls
man pages section 2: System Calls Part No: E29032 October 2012 Copyright © 1993, 2012, Oracle and/or its affiliates. All rights reserved. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, the following notice is applicable: U.S. GOVERNMENT END USERS. Oracle programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, delivered to U.S. Government end users are "commercial computer software" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, use, duplication, disclosure, modification, and adaptation of the programs, including anyoperating system, integrated software, any programs installed on the hardware, and/or documentation, shall be subject to license terms and license restrictions applicable to the programs. No other rights are granted to the U.S. Government. This software or hardware is developed for general use in a variety of information management applications.