Folding Proteins with Both Alpha and Beta Structures in a Reduced Model
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Heterogeneous Impacts of Protein-Stabilizing Osmolytes On
bioRxiv preprint doi: https://doi.org/10.1101/328922; this version posted May 23, 2018. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. Heterogeneous Impacts of Protein-Stabilizing Osmolytes on Hydrophobic Interaction Mrinmoy Mukherjee and Jagannath Mondal⇤ Tata Institute of Fundamental Research Hyderabad, 500107 India E-mail: [email protected],+914020203091 Abstract Osmolytes’ mechanism of protecting proteins against denaturation is a longstanding puzzle, further complicated by the complex diversities inherent in protein sequences. An emergent approach in understanding osmolytes’ mechanism of action towards biopoly- mer has been to investigate osmolytes’ interplay with hydrophobic interaction, the ma- jor driving force of protein folding. However, the crucial question is whether all these protein-stabilizing osmolytes display a single unified mechanism towards hydrophobic interactions. By simulating the hydrophobic collapse of a macromolecule in aqueous solutions of two such osmoprotectants, Glycine and Trimethyl N-oxide (TMAO), both of which are known to stabilize protein’s folded conformation, we here demonstrate that these two osmolytes can impart mutually contrasting effects towards hydropho- bic interaction. While TMAO preserves its protectant nature across diverse range of polymer-osmolyte interactions, glycine is found to display an interesting cross-over from being a protectant at weaker polymer-osmolyte interaction to a denaturant of hydrophobicity at stronger polymer-osmolyte interactions. A preferential-interaction analysis reveals that a subtle balance of conformation-dependent exclusion/binding of ⇤To whom correspondence should be addressed 1 bioRxiv preprint doi: https://doi.org/10.1101/328922; this version posted May 23, 2018. -

Simulations of Я-Hairpin Folding Confined to Spherical Pores Using
Simulations of -hairpin folding confined to spherical pores using distributed computing D. K. Klimov*†, D. Newfield‡, and D. Thirumalai*† *Institute for Physical Science and Technology, University of Maryland, College Park, MD 20742; and ‡Parabon Computation, 3930 Walnut Street, Suite 100, Fairfax, VA 22030-4738 Communicated by George H. Lorimer, University of Maryland, College Park, MD, April 12, 2002 (received for review December 18, 2001) 3 ϱ We report the thermodynamics and kinetics of an off-lattice Go radius of gyration of a chain Rg at D (the size of a chain in  Ӎ model -hairpin from Ig-binding protein confined to an inert bulk solution) to N according to Rg aN . If the chain is ideal, ϭ ⌬ ϭ ͞ 2 spherical pore. Confinement enhances the stability of the hairpin then 0.5 and FU RTN(a D) . Because of the reduction due to the decrease in the entropy of the unfolded state. Compared in the translational entropy, confinement also increases the free ⌬ Ͼ ⌬ ͞⌬ ϽϽ with their values in the bulk, the rates of hairpin formation increase energy of the native state, i.e., FN 0. If FN FU 1, then in the spherical pore. Surprisingly, the dependence of the rates on localization of a protein in a confined space stabilizes the native the pore radius, Rs, is nonmonotonic. The rates reach a maximum state compared with the bulk. It also follows that there is a range ͞ b Ӎ b at Rs Rg,N 1.5, where Rg,N is the radius of gyration of the folded of D values over which stability is maximized. -

Protein Structure & Folding
6 Protein Structure & Folding To understand protein folding In the last chapter we learned that proteins are composed of amino acids Goal as a chemical equilibrium. linked together by peptide bonds. We also learned that the twenty amino acids display a wide range of chemical properties. In this chapter we will see Objectives that how a protein folds is determined by its amino acid sequence and that the three-dimensional shape of a folded protein determines its function by After this chapter, you should be able to: the way it positions these amino acids. Finally, we will see that proteins fold • describe the four levels of protein because doing so minimizes Gibbs free energy and that this minimization structure and the thermodynamic involves both making the most favorable bonds and maximizing disorder. forces that stabilize them. • explain how entropy (S) and enthalpy Proteins exhibit four levels of structure (H) contribute to Gibbs free energy. • use the equation ΔG = ΔH – TΔS The structure of proteins can be broken down into four levels of to determine the dependence of organization. The first is primary structure, the linear sequence of amino the favorability of a reaction on acids in the polypeptide chain. By convention, the primary sequence is temperature. written in order from the amino acid at the N-terminus (by convention • explain the hydrophobic effect and its usually on the left) to the amino acid at the C-terminus. The second level role in protein folding. of protein structure, secondary structure, is the local conformation adopted by stretches of contiguous amino acids. -
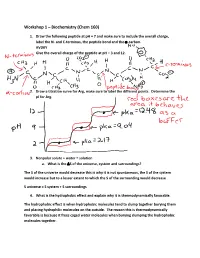
Workshop 1 – Biochemistry (Chem 160)
Workshop 1 – Biochemistry (Chem 160) 1. Draw the following peptide at pH = 7 and make sure to include the overall charge, label the N- and C-terminus, the peptide bond and the -carbon. AVDKY Give the overall charge of the peptide at pH = 3 and 12. 2. Draw a titration curve for Arg, make sure to label the different points. Determine the pI for Arg. 3. Nonpolar solute + water = solution a. What is the S of the universe, system and surroundings? The S of the universe would decrease this is why it is not spontaneous, the S of the system would increase but to a lesser extent to which the S of the surrounding would decrease S universe = S system + S surroundings 4. What is the hydrophobic effect and explain why it is thermodynamically favorable. The hydrophobic effect is when hydrophobic molecules tend to clump together burying them and placing hydrophilic molecules on the outside. The reason this is thermodynamically favorable is because it frees caged water molecules when burying clumping the hydrophobic molecules together. 5. Urea dissolves very readily in water, but the solution becomes very cold as the urea dissolves. How is this possible? Urea dissolves in water because when dissolving there is a net increase in entropy of the universe. The heat exchange, getting colder only reflects the enthalpy (H) component of the total energy change. The entropy change is high enough to offset the enthalpy component and to add up to an overall -G 6. A mutation that changes an alanine residue in the interior of a protein to valine is found to lead to a loss of activity. -

The Future of Protein Secondary Structure Prediction Was Invented by Oleg Ptitsyn
biomolecules Review The Future of Protein Secondary Structure Prediction Was Invented by Oleg Ptitsyn 1, 1, 1 2 1,3 Daniel Rademaker y, Jarek van Dijk y, Willem Titulaer , Joanna Lange , Gert Vriend and Li Xue 1,* 1 Centre for Molecular and Biomolecular Informatics (CMBI), Radboudumc, 6525 GA Nijmegen, The Netherlands; [email protected] (D.R.); [email protected] (J.v.D.); [email protected] (W.T.); [email protected] (G.V.) 2 Bio-Prodict, 6511 AA Nijmegen, The Netherlands; [email protected] 3 Baco Institute of Protein Science (BIPS), Mindoro 5201, Philippines * Correspondence: [email protected] These authors contributed equally to this work. y Received: 15 May 2020; Accepted: 2 June 2020; Published: 16 June 2020 Abstract: When Oleg Ptitsyn and his group published the first secondary structure prediction for a protein sequence, they started a research field that is still active today. Oleg Ptitsyn combined fundamental rules of physics with human understanding of protein structures. Most followers in this field, however, use machine learning methods and aim at the highest (average) percentage correctly predicted residues in a set of proteins that were not used to train the prediction method. We show that one single method is unlikely to predict the secondary structure of all protein sequences, with the exception, perhaps, of future deep learning methods based on very large neural networks, and we suggest that some concepts pioneered by Oleg Ptitsyn and his group in the 70s of the previous century likely are today’s best way forward in the protein secondary structure prediction field. -

Chapter 4 the Three-Dimensional Structure of Proteins
Chapter 4 The Three-Dimensional Structure of Proteins Multiple Choice Questions 1. Answer: D All of the following are considered “weak” interactions in proteins, except: A) hydrogen bonds. B) hydrophobic interactions. C) ionic bonds. D) peptide bonds. E) van der Waals forces. 2. Answer: D In an aqueous solution, protein conformation is determined by two major factors. One is the formation of the maximum number of hydrogen bonds. The other is the: A) formation of the maximum number of hydrophilic interactions. B) maximization of ionic interactions. C) minimization of entropy by the formation of a water solvent shell around the protein. D) placement of hydrophobic amino acid residues within the interior of the protein. E) placement of polar amino acid residues around the exterior of the protein. 3. 3 Answer: A In the diagram below, the plane drawn behind the peptide bond indicates the: A) absence of rotation around the C—N bond because of its partial double-bond character. B) plane of rotation around the C—N bond. C) region of steric hindrance determined by the large C=O group. D) region of the peptide bond that contributes to a Ramachandran plot. E) theoretical space between –180 and +180 degrees that can be occupied by the and angles in the peptide bond. 4. Answer: D Which of the following best represents the backbone arrangement of two peptide bonds? A) C—N—C—C—C—N—C—C B) C—N—C—C—N—C C) C—N—C—C—C—N D) C—C—N—C—C—N Chapter 4 The Three-Dimensional Structure of Proteins E) C—C—C—N—C—C—C 5. -

Conformational Properties of Constrained Proline Analogues and Their Application in Nanobiology”
UNIVERSITAT POLITÈCNICA DE CATALUNYA DEPARTAMENT D’ENGINYERIA QUÍMICA “CONFORMATIONAL PROPERTIES OF CONSTRAINED PROLINE ANALOGUES AND THEIR APPLICATION IN NANOBIOLOGY” Alejandra Flores Ortega Supervisors: Dr. Carlos Alemán Llansó and Dr. Jordi Casanovas Salas. th Barcelona, 27 January 2009 “Chance is a word void of sense; nothing can exist without a cause”. François-Marie Arouet, Voltaire “Imagination will often carry us to worlds that never were. But without it, we go nowhere”. Carl Sagan iii ACKNOWLEDGEMENTS I would like to acknowledge to Dr. Carlos Aleman and Dr. Jordi Cassanovas Salas for an interesting research theme, and scientific support. I gratefully acknowledge to Dr. David Zanuy for interesting suggestions and strong discussions, without their support this would be an unfulfilled task. Also I, would like to address my thanks to all my colleagues in my group and department, specially Elaine Armelin for assiting me in many different ways. I thank not only my friends, but also colleagues for helping me to overcome the stressful time, without whom it would have been difficult to cope up. I wish to express my gratefulness to my parents, specially to my mother, María Esther, for all his care, and support. Also I will like to thanks to my friends and specially Jesus, Merches, Laura y Arturo. My PhD thesis have been finished for all this support. I am greatly indepted to Dr. Ruth Nussinov at NCI, Dr. Carlos Cativiela at the University of Zaragoza and Ana I. Jiménez at the “Instituto de Ciencias de Materiales de Aragon” for a collaborative effort. I wish to thank all my colleague in the “Chimie et Biochimie Théoriques, Faculté des Sciences et Techniques” in Nancy France, I will be grateful to have worked with : Pr. -

Packing of Secondary Structures II
7.88 Lecture Notes - 5 7.24/7.88J/5.48J The Protein Folding and Human Disease Packing of Secondary Structures • Packing of Helices against sheets • Packing of sheets against sheets • Parallel • Orthogonal Table: “Amino Acid Composition of the Ten Proteins and of the Residues at the Helix to Helix Interfaces” Name Total % Total At contacts % at contacts Gly 182 9 15 4 Ala 191 9 49 12 Val 151 7 46 12 Leu 148 7 48 12 Ile 114 6 36 9 Pro 67 3 41 1 Phe 68 3 25 6 Tyr 87 6 14 4 Trp 35 2 7 2 His 45 2 18 5 ½Cys 21 1 3 1 Met 29 1 10 3 Ser 165 8 19 5 Thr 132 7 21 5 Asp 112 6 14 4 Asn 113 6 13 3 Glu 94 5 13 3 Gln 70 3 12 3 Lys 125 6 19 5 Arg 76 4 13 3 A. Factors Contributing to Stability of Correctly Folded Native State 1. Major source of stability = removal of hydrophobic side chains atoms from the solvent and burying in environment which excludes the solvent (Entropic contribution from water structure). 1 2. Formation of hydrogen bonds between buried amide and carbonyl groups is maximized 3. Retention of backbone conformations close to the minimal energies. 4. Close packing means optimal Van der Waals interactions. You have read about alpha/beta proteins in Brandon and Tooze. B. Helix to Sheet Packing Lets examine buried contacts between the helices and the sheets. First a quick review of beta sheet structure: Colored transparency: Theoretical model, not actual sheet. -

Mechanism of Resilin Elasticity
ARTICLE Received 24 Oct 2011 | Accepted 11 Jul 2012 | Published 14 Aug 2012 DOI: 10.1038/ncomms2004 Mechanism of resilin elasticity Guokui Qin1,*, Xiao Hu1,*, Peggy Cebe2 & David L. Kaplan1 Resilin is critical in the flight and jumping systems of insects as a polymeric rubber-like protein with outstanding elasticity. However, insight into the underlying molecular mechanisms responsible for resilin elasticity remains undefined. Here we report the structure and function of resilin from Drosophila CG15920. A reversible beta-turn transition was identified in the peptide encoded by exon III and for full-length resilin during energy input and release, features that correlate to the rapid deformation of resilin during functions in vivo. Micellar structures and nanoporous patterns formed after beta-turn structures were present via changes in either the thermal or the mechanical inputs. A model is proposed to explain the super elasticity and energy conversion mechanisms of resilin, providing important insight into structure–function relationships for this protein. Furthermore, this model offers a view of elastomeric proteins in general where beta-turn-related structures serve as fundamental units of the structure and elasticity. 1 Department of Biomedical Engineering, Tufts University, Medford, Massachusetts 02155, USA. 2 Department of Physics and Astronomy, Tufts University, Medford, Massachusetts 02155, USA. *These authors contributed equally to this work. Correspondence and requests for materials should be addressed to D.L.K. (email: [email protected]). -

Amino Acid Preference Against Beta Sheet Through Allowing Backbone Hydration Enabled by the Presence of Cation
Amino acid preference against beta sheet through allowing backbone hydration enabled by the presence of cation John N. Sharley, University of Adelaide. arXiv 2016-10-03 [email protected] Table of Contents 1 Abstract 1 2 Introduction 2 2.1 Alpha helix preferring amino acid residues in a beta sheet 2 2.2 Cation interactions with protein backbone oxygen 3 2.3 Quantum molecular dynamics with quantum mechanical treatment of every water molecule 3 3 Methods 4 4 Results 5 4.1 Preparation 5 4.2 Experiment 1302 5 4.3 Experiment 1303 7 5 Discussion 9 5.1 HB networks of water 9 5.2 Subsequent to rupture of a transient beta sheet 9 5.3 Hofmeister effects 10 6 Conclusion 11 7 Future work 12 8 Acknowledgements 13 9 References 14 10 Appendix 1. Backbone hydration in experiment 1302 16 11 Appendix 2. Backbone hydration in experiment 1303 17 1 Abstract It is known that steric blocking by peptide sidechains of hydrogen bonding, HB, between water and peptide groups, PGs, in beta sheets accords with an amino acid intrinsic beta sheet preference [1]. The present observations with Quantum Molecular Dynamics, QMD, simulation with Quantum Mechanical, QM, treatment of every water molecule solvating a beta sheet that would be transient in nature suggest that this steric blocking is not applicable in a hydrophobic region unless a cation is present, so that the amino acid beta sheet preference due to this steric blocking is only effective in the presence of a cation. We observed backbone hydration in a polyalanine and to a lesser extent polyvaline alpha helix without a cation being present, but a cation could increase the strength of these HBs. -
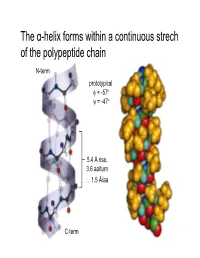
The Α-Helix Forms Within a Continuous Strech of the Polypeptide Chain
The α-helix forms within a continuous strech of the polypeptide chain N-term prototypical φ = -57 ° ψ = -47 ° 5.4 Å rise, 3.6 aa/turn ∴ 1.5 Å/aa C-term α-Helices have a dipole moment, due to unbonded and aligned N-H and C=O groups β-Sheets contain extended (β-strand) segments from separate regions of a protein prototypical φ = -139 °, ψ = +135 ° prototypical φ = -119 °, ψ = +113 ° (6.5Å repeat length in parallel sheet) Antiparallel β-sheets may be formed by closer regions of sequence than parallel Beta turn Figure 6-13 The stability of helices and sheets depends on their sequence of amino acids • Intrinsic propensity of an amino acid to adopt a helical or extended (strand) conformation The stability of helices and sheets depends on their sequence of amino acids • Intrinsic propensity of an amino acid to adopt a helical or extended (strand) conformation The stability of helices and sheets depends on their sequence of amino acids • Intrinsic propensity of an amino acid to adopt a helical or extended (strand) conformation • Interactions between adjacent R-groups – Ionic attraction or repulsion – Steric hindrance of adjacent bulky groups Helix wheel The stability of helices and sheets depends on their sequence of amino acids • Intrinsic propensity of an amino acid to adopt a helical or extended (strand) conformation • Interactions between adjacent R-groups – Ionic attraction or repulsion – Steric hindrance of adjacent bulky groups • Occurrence of proline and glycine • Interactions between ends of helix and aa R-groups His Glu N-term C-term -

Chapter 6 Protein Structure and Folding
Chapter 6 Protein Structure and Folding 1. Secondary Structure 2. Tertiary Structure 3. Quaternary Structure and Symmetry 4. Protein Stability 5. Protein Folding Myoglobin Introduction 1. Proteins were long thought to be colloids of random structure 2. 1934, crystal of pepsin in X-ray beam produces discrete diffraction pattern -> atoms are ordered 3. 1958 first X-ray structure solved, sperm whale myoglobin, no structural regularity observed 4. Today, approx 50’000 structures solved => remarkable degree of structural regularity observed Hierarchy of Structural Layers 1. Primary structure: amino acid sequence 2. Secondary structure: local arrangement of peptide backbone 3. Tertiary structure: three dimensional arrangement of all atoms, peptide backbone and amino acid side chains 4. Quaternary structure: spatial arrangement of subunits 1) Secondary Structure A) The planar peptide group limits polypeptide conformations The peptide group ha a rigid, planar structure as a consequence of resonance interactions that give the peptide bond ~40% double bond character The trans peptide group The peptide group assumes the trans conformation 8 kJ/mol mire stable than cis Except Pro, followed by cis in 10% Torsion angles between peptide groups describe polypeptide chain conformations The backbone is a chain of planar peptide groups The conformation of the backbone can be described by the torsion angles (dihedral angles, rotation angles) around the Cα-N (Φ) and the Cα-C bond (Ψ) Defined as 180° when extended (as shown) + = clockwise, seen from Cα Not