Utilizing Urban Geospatial Data to Understand Heritage Attractiveness in Amsterdam
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
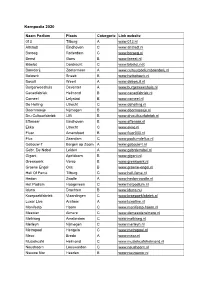
Kernpodia 2020
Kernpodia 2020 Naam Podium Plaats Catergorie Link website 013 Tilburg A www.013.nl Altstadt Eindhoven C www.altstadt.nl Baroeg Rotterdam C www.baroeg.nl Beest Goes B www.tbeest.nl Bibelot Dordrecht C www.bibelot.net Boerderij Zoetermeer A www.cultuurpodiumboerderij.nl Bolwerk Sneek B www.hetbolwerk.nl Bosuil Weert A www.debosuil.nl Burgerweeshuis Deventer A www.burgerweeshuis.nl Cacaofabriek Helmond B www.cacaofabriek.nl Corneel Lelystad B www.corneel.nl De Helling Utrecht C www.dehelling.nl Doornroosje Nijmegen B www.doornroosje.nl Dru Cultuurfabriek Ulft B www.drucultuurfabriek.nl Effenaar Eindhoven B www.effenaar.nl Ekko Utrecht C www.ekko.nl Fluor Amersfoort B www.fluor033.nl Flux Zaandam C www.podiumdeflux.nl Gebouw-T Bergen op Zoom A www.gebouw-t.nl Gebr. De Nobel Leiden A www.gebrdenobel.nl Gigant Apeldoorn B www.gigant.nl Grenswerk Venlo B www.grenswerk.nl Groene Engel Oss B www.groene-engel.nl Hall Of Fame Tilburg C www.hall-fame.nl Hedon Zwolle A www.hedon-zwolle.nl Het Podium Hoogeveen C www.hetpodium.nl Iduna Drachten B www.iduna.nu Kroepoekfabriek Vlaardingen C www.kroepoekfabriek.nl Luxor Live Arnhem A www.luxorlive.nl Manifesto Hoorn C www.manifesto-hoorn.nl Meester Almere C www.demeesteralmere.nl Melkweg Amsterdam C www.melkweg.nl Merleyn Nijmegen C www.merleyn.nl Metropool Hengelo C www.metropool.nl Mezz Breda A www.mezz.nl Muziekcafé Helmond C www.muziekcafehelmond.nl Neushoorn Leeuwarden C www.neushoorn.nl Nieuwe Nor Heerlen B www.nieuwenor.nl Nirwana Lierop C www.nirwana.nl OCCII Amsterdam C www.occii.org P3 Purmerend -

Hoofdlijnen Kunst En Cultuur 2021-2024 Bijlagen
Hoofdlijnen kunst en cultuur 2021-2024 Bijlagen Bijlage 1 Profielen stadsdelen Noord Het Buikslotermeerplein transformeert geleidelijk tot een centrum stedelijk gebied met een Amsterdam Noord is in beweging en biedt grote gevarieerd cultureel aanbod. Door de komst kansen voor kunst en cultuur. Bijvoorbeeld in de van de N/Z lijn is de bereikbaarheid sterk nieuwe wijken zoals Buiksloterham, Elzenhagen, verbeterd. Met een combinatie van bekende NDSM-west, Klaprozenbuurt en Hamerkwartier. en minder bekende lokale culturele instellingen De flinke groei van het aantal inwoners van kunnen onverwachte kruisbestuivingen ontstaan Noord in de komende periode vraagt om meer en kunnen we op dit plein veel verschillende podia, tentoonstellingsruimtes, broedplaatsen, doelgroepen bereiken, uit Noord en uit de rest debatpodia en andere culturele en creatieve van stad en verder. We willen bestaande, lokale plekken. Maar ook in de bestaande wijken, waar instellingen uitdagen om samen met partijen uit relatief weinig culturele voorzieningen zijn, is andere delen van de stad of daarbuiten nieuwe uitbreiding gewenst. initiatieven te ontplooien. Noord beschikt over vele kilometers IJ-oever waar Noord heeft ontwikkelbuurten en tuindorpen met diverse industriële gebouwen en fabriekshallen relatief veel kwetsbare bewoners en kinderen die te vinden zijn. In de afgelopen jaren zijn hier veel opgroeien in armoede. Kunst en cultuur kan hier vernieuwende culturele initiatieven ontstaan, vaak een positieve invloed hebben. Daarom willen we op plekken die nu getransformeerd worden tot hier wijkprogramma’s stimuleren door middel van woon- werkgebieden. Daarmee wordt de vrije onder andere (hoogwaardige) community art, ruimte schaars is Noord. cultuureducatie versterken en ruimte creëren voor talentontwikkeling voor jongeren. Ook de OBA Voor de komende periode zetten we in kan in deze wijken een belangrijke rol spelen. -

Media Kit 2018 Farai Shot by Vicky by Shot 08 Issue Farai Subbacultcha Magazine, London Grout in for Subbacultcha
media kit 2018 Farai shot by Vicky by shot 08 Issue Farai Subbacultcha magazine, Grout London in for Subbacultcha We are an independent music platform based in Amsterdam. — We produce progressive shows accompanied by a quarterly music magazine. With the support of a loyal community of members, we have set in place a unique system that enables us to introduce a large and diverse young audience to the emerging music that excites us. Shows Subbacultcha hosts 10+ unruly shows a month, booked in-house and organized by us at venues of our choice. Subbacultcha shows Collaboration and co-hosting We are all about shows. We aim to book and promote unconventional, Besides organizing and producing our own events, we also curate unruly artists at the very start of their careers – right about the time and co-promote shows, festivals and events in collaboration with when they release their first album or tour Europe for the first time. our partners such as Muziekgebouw aan ‘t IJ, Melkweg, Progress Bar, We take cues from independent labels and intertwined networks across Motel Mozaique and many more. the world to unearth the most interesting music-makers out there today. We host shows at our homebase De School, Amsterdam and work closely with small alternative venues in Amsterdam and Rotterdam, organizing Custom events for brands & partners shows where the right audience meets the right artist. We also organize and produce events for brands and partners. Ranging from booking artists and DJs to producing and promoting entire events. Support your Local Area Network Some of the partners we work with are Order, Dr Martens, American Apparel, Urban Outfitters and Goose Island. -

Page 1 of 2 Quarles Van Ufford 5/28/2007 File://D:\Websites
quarles van ufford Page 1 of 2 news shows music bio issues news 17 january 2006 Dear fans, You probably already know it and have been bursting into tears hysterically about it a couple of times. This is all completely appropriate, but it doesn't change anything about the fact that Quarles van Ufford doesn't exist anymore after their gig last saturday at the Patronaat in Haarlem. The band calls it quits. But everyone already knew this. All the E-mail Quarles van Ufford: people that helped Quarles van Ufford in any way in the last couple of months: thanks! contact @ quarlesvanufford.com If you want to see Daan play live in the future, check out a Solid Rocket Boosters gig. He plays in this band. Meanwhile, he is also busy trying to become famous building a bass guitar. Jeroen will continue playing in Gone Bald. Jeroen and Gabry will continue playing together in Boutros Bubba. Jeroen does guitar and vocals, Gabry does the drums, mathematics do the rest. In the meantime, the website will exist in its present form but during the year probably will be changed into something offensive. Later Gabry, Daan & Jeroen 17 november 2005 Internetpeople, A short update from QvU. Some weeks ago we did a mini-tour in Germany and Holland with Gentle Veincut from Frankfurt. We had a great time travelling around, playing and drinking and we would like to thank everybody involved. I would very much like to show you what kind of places we've been by putting some pics on this site but we practically didn't make any pictures and the pictures that we did make are probably destroyed. -

Gehonoreerde Aanvragen Podiumstartregeling Voor Op Website
Overzicht podia SKIP-podia 2018-2019 / 2020-2021 categorie 2 en 3 | Kernpodia | SRP-podia middelgrote zalen De Kring Roosendaal 't Beest (Vereniging) Nirwana Lierop Aan de Slinger Altstadt Live Bibelot Cacaofabriek Café Mezrab CC Amstel Chassé Theater N.V. Concordia Cool kunst en cultuur Cultura Cultureel Centrum 't Paard Cultureel Centrum Corrosia Cultureel Centrum De Effenaar Cultureel Podium t ukien Cultuur in Helmond Cultuurcentrum VU, Griffioen Cultuurhuis Hoogeveen Cultuurpodium Boerderij Dans aan het IJ De Goudse Schouwburg De Helling De Kom Stadstheater en Kunstencentrum De Kroepoekfabriek De Link De Neushoorn De Nieuwe Vorst De Pul / Compass De Ruimte Doornroosje Dru Cultuurfabriek ECI Ekko FluX Frascati Gebr. Nobel - voorheen Leids vrijetijds Centrum (LVC) Gigant Goede Rede Concerten Grand Futura Groene Engel GROUNDS Hall of Fame Hedon Het Cultuurgebouw Het Huis Utrecht Het Klooster Het Nationale Theater Iduna Ins Blau Jazz International Rotterdam Jeugdtheater de Krakeling Korzo Kunstenhuis De Bilt-Zeist Live At Rotown LUX Nijmegen Luxor Live Maas theater en dans Manifesto (Netwerk) Melkweg Mezz Concerts & Dance Musica Antica da Camera Muziek- & Danscafé Merleyn (Doornroosje Twee) Muziekcentrum de Bosuil Muziekpodium DJS Muziekpodium Paradox Nieuwe Muziek Zeeland Noorderkerkconcerten Onafhankelijk Cultureel Centrum In It (OCCII) Open Jongeren Centrum Baroeg P3 Purmerend P60 Pardoes Parkstad Limburg Theaters Patronaat Plein Theater Podium Asteriks Podium De Vorstin Podium Mozaïek Podium Victorie Popcluster (013 Poppodium) Poppodium Corneel Poppodium de Meester Poppodium FLUOR Poppodium Gebouw-T Poppodium Grenswerk Poppodium Het Bolwerk (Cultureel Kwartier Sneek) Poppodium Het Burgerweeshuis poppodium NIEUWE NOR Poppodium Simplon Poppodium Twente Poppodium Volt Porgy en Bess Programma Posthuis Theater Heerenveen Prime ProJazz Schouwburg & Filmtheater Agnietenhof Schouwburg en Congrescentrum Het Park B.V. -

Xango Music Distribution Release #6 – 2019 Pagina | 1
Xango Music local music from all over the world Office: Singelstraat 1, 3513 BL Utrecht, NL www.xmd.nl - [email protected] - +31 6 260 263 60 Warehouse: Berenkoog 53 C, 1822 BN, Alkmaar (NL) e: [email protected] t: +31 (0)72 - 567 3030 NEW RELEASES NO. 6 – 2019 The Liberation Project: Songs That Made Us Free CDJUST 802 / 6009707283369 / label: Just Music / format: 3CD / South Africa – Popular The Liberation Project is driven from South Africa and features a unique collaboration of musicians mainly from South Africa, Italy and Cuba who have joined forces to celebrate their liberation struggles from various different corners of the world with the main focus being on music from South Africa, Italy and Cuba. Musicians from France, La Reunion, Guinea, Burundi, the USA, Brazil, the United Kingdom and from much more countries have also contributed. 34 songs plus 3 bonus tracks over 3 CD’s with 69 musicians from 17 different countries out of 17 studios all over the world contributing their passion and talent for the cause. Throughout history, music and protest songs have inspired and celebrated social change. This record includes well-known and traditional songs on the liberation theme, together with newly penned ones which share the same subject matter. Listen to a track. The Nile Project: Tana ZAM 3 / 0888295843317 / label: The Nile Project / format: CD / Various – Popular One of the tightest cross-cultural collaborations in musical history, the Nile Project brings together artists from the 11 Nile countries, representing over 450 million people, to compose new songs that combine the rich diversity of one of the oldest places on Earth. -

Karayazi 1281941
Eindhoven University of Technology MASTER The relevance of newly available big data and urban heritage tourism investigating the popularity of urban heritage areas in Amsterdam using Flickr data Karayazı, S.S. Award date: 2019 Link to publication Disclaimer This document contains a student thesis (bachelor's or master's), as authored by a student at Eindhoven University of Technology. Student theses are made available in the TU/e repository upon obtaining the required degree. The grade received is not published on the document as presented in the repository. The required complexity or quality of research of student theses may vary by program, and the required minimum study period may vary in duration. General rights Copyright and moral rights for the publications made accessible in the public portal are retained by the authors and/or other copyright owners and it is a condition of accessing publications that users recognise and abide by the legal requirements associated with these rights. • Users may download and print one copy of any publication from the public portal for the purpose of private study or research. • You may not further distribute the material or use it for any profit-making activity or commercial gain THE RELEVANCE OF NEWLY AVAILABLE BIG DATA AND URBAN HERITAGE TOURISM INVESTIGATING THE POPULARITY OF URBAN HERITAGE AREAS IN AMSTERDAM USING FLICKR DATA SEVIM SEZI KARAYAZI EINDHOVEN UNIVERSITY OF TECHNOLOGY (TU/E) | CONSTRUCTION MANAGEMENT AND ENGINEERING (CME) 2017-2019 This page is intentionally left blank COLOPHON TitlE: ThE rElEvancE of nEwly availablE big data and urban hEritagE tourism Sub-titlE: Investigating thE popularity of urban hEritagE arEas in AmstErdam using Flickr data DocumEnt: Master thEsis Date: 15/08/2019 Author: SEvim SEzi Karayazı StudEnt numbEr: 1281941 UnivErsity: EindhovEn UnivErsity of TEchnology (TU/E) Faculty: DepartmEnt of Built EnvironmEnt Program: Construction ManagEmEnt and EnginEEring (CME) Chairman: Prof. -

Feminist Periodicals
The U n vers ty o f W scons n System Feminist Periodicals A current listing of contents WOMEN'S STUDIES Volume 21, Number 1, Spring 2001 Published by Phyllis Holman Weisbard LIBRARIAN Women's Studies Librarian Feminist Periodicals A current listing ofcontents Volume 21, Number 1 Spring 2001 Periodicallilerature is the cutting edge ofwomen's scholarship, feminist theory, and much ofwomen's culture, Feminisf Periodicals: A Current Listing of Contents is published by the Office of the University of Wisconsin System Women's Studies Librarian on a quarterly basis with the intent of increasing public awareness of feminist periodicals, It is our hope that Feminist Periodicals will serve several purposes: to keep the reader abreast of current topics in feminist literature; to increase readers' familiarity with a wide spectrum of feminist periodicals; and to provide the requisite bibliographic information should a reader wish to subscribe to ajournal or to obtain a particular article at her library or through interlibrary loan, (Users will need to be aware of the limitations of the new copyright law with regard to photocopying of copyrighted materials.) Table ofcontents pages from current issues ofmajorfeministjournals are reproduced in each issue of Feminist Periodicals, preceded by a comprehensive annotated listing of all journals we have selected, As publication schedules vary enormously, not every periodical will have table of contents pages reproduced in each issue of FP. The annotated listing provides the following information on each journal: 1, Year of first publication, 2. Frequency of pUblication, 3. U.S, subscription price(s), 4, SUbscription address, 5. Current editor. -

Amsterdam 12
©Lonely Planet Publications Pty Ltd Plan Your Trip 12 Amsterdam “All you’ve got to do is decide to go and the hardest part is over. So go!” TONY WHEELER, COFOUNDER – LONELY PLANET CATHERINE LE NEVEZ, KATE MORGAN, BARBARA WOOLSEY Contents PlanPlan Your Your Trip Trip page 1 4 Welcome to If You Like... ................. 20 Museums & Amsterdam ....................4 ..................... Month by Month ......... 23 Galleries 40 Amsterdam’s Top 10 .....6 ......................... Travel with Kids .......... 26 Eating 43 What’s New ..................13 By Bike ......................... 29 Drinking & ..................... Need to Know .............. 14 Nightlife 48 Like a Local .................. 31 .......... First Time Entertainment 55 For Free ....................... 33 Amsterdam .................. 16 Shopping .....................57 Canals ......................... 35 Top Itineraries .............18 Explore Amsterdam 60 Neighbourhoods Southern Oosterpark & at a Glance ................. 62 Canal Ring .................. 118 East of the Amstel .....189 Medieval Centre & Jordaan & the West ...136 Amsterdam Noord ....198 Red Light District ....... 64 Vondelpark & Daytrips Nieuwmarkt, Plantage the South.................... 151 from Amsterdam ... 206 & the Eastern Islands ....87 De Pijp ........................ 175 Sleeping ....................217 Western Canal Ring ...104 Understand Amsterdam 229 Amsterdam Today ...230 Dutch Painting .......... 242 Dutch Design ............ 258 History ....................... 232 Architecture in Amsterdam ...........250 -

AA the Metro Network of Music (Arnold De Boer)
The metro network of music Far below sea level, in the basement of the underground of the Rhine and Meuse delta you find people and places that are connected to a world wide network of autonomous music. It can be described as a subway network where musicians and music fanatics travel from station to station but also are part of a station themselves. Those people are the ones who set up shows, volunteer at the venues, squats or bars, put down matrasses for artists, stick posters on the walls, spam the social media and cook the meals for all people involved in the show of some particular night. And most often they are a musician or a DJ or a booker or label owner or a promoter or a record seller too. I am such a person; a musician but also promoter and volunteer at an underground music venue and quite often artists sleep at my house. I have also done around 2000 gigs in at least 35 different countries and met like- minded people everywhere. All the time there were people waiting for me, who set up a show, organize food and drinks and a place to sleep, did the promotion and arranged a stage and sound system. I know them through other musicians or because they passed by Amsterdam and invited me to their neck of the woods. This network goes all over Europe and North America but also pretty deep into South America, Asia and Australia and is sometimes touching Africa too. In January 2015 a little baby was born, my first child, and I decided for this year to not book three week Zea (my solo project) tours. -

The Groene Voltage
Published 2012 by [email protected] Dedicated to all squatters GROENE VOLTAGE The Groene Voltage A Temporary Autonomous Zone in Rotterdam GROENE VOLTAGE CONTENTS Preface 7 Introduction 9 What we did 11 What we achieved 15 What we could have done better 20 The collective 24 The next steps 27 Conclusion 29 GROENE VOLTAGE PREFACE This pamphlet is based on an article originally published on Indymedia Netherlands in 2008. It has been revised somewhat and is being republished since the themes it deals with are considered relevant to other (squatted) social centres. In some ways we achieved a lot, in others we got caught in the traps common to all projects. Note - it can only be read as one person's viewpoint. It is likely that other people from the collective would see things differently. 7 GROENE VOLTAGE 8 INTRODUCTION The Groene Voltage was a squatted social centre in Rotterdam. It was situated five minutes from Central Station in a residential area, beside a busy road which leads to the ringroad and then to motorways in the direction of Den Haag and Utrecht (apparently it's one of the most polluted roads in the Netherlands). It stood on the corner of a large cityblock and the four floors above it were also squatted separately as residential space for six people. It lasted for almost exactly one year, from October 2006 to October 2007. The eviction was not contested, but rather the keys were handed back to the owners (a housing corporation called PWS - Patrimoniums Woningstichting) because they had announced their intention to renovate the entire building. -
Unity Jaarverslag 2019
Jaarverslag 2019 Unity is een vrijwilligersproject waarbij jonge mensen uit de dancescene op festivals en feesten voorlichting geven over uitgaan, alcohol en andere drugs en de risico’s die daarbij komen kijken. De peer educators van Unity zijn er niet om drugsgebruik te veroordelen maar om te reageren op behoeften en vragen van hun medefeestgangers over gebruik en beperking van de risico’s. Pink Unity is een project voor en door mannen uit de Amsterdamse gay-scene, ondersteund door Jellinek en GGD Amsterdam. Op (seks)parties en in clubs geven zij objectief en open-minded voorlichting over veilig(er) gebruik van alcohol en andere drugs en veilig(er) seksgedrag. Kerncijfers 2019 Aantal feesten totaal Contacten totaal 181 17212 Gestelde losse vragen 41 1403 58 10 Alcohol 6% Amfetamine 6% 15 Algemeen / 4-FA 5% 22 anders 24% Ketamine 5% 8 Cannabis 4% GHB 4% 27 Cocaïne 3% 3-MMC/4-MMC 3% LSD 3% 2C-B 2% Lachgas 2% MDMA 31% NPS (niet 4-FA, 3-MMC of 4-MMC) 2% Samenstelling Unity Highlights 2019 Samenwerking met Celebrate Safe: 17 Slaapcampagne: voorlichting met aandacht voor slapen medewerkers Ear check: onderzoek naar gehoorbescherming Unity Colleges: 26 Brabant: Cannabis: wiet, waar en waarom? peer coaches Utrecht: XTC en empathie Nog nooit waren er zo veel peer educators voor Unity landelijk actief 160 Nieuwe samenwerkingspartners: peer educators Verknipt Poppodium 013 Effenaar Landelijk uitje voor peer educators Online statistieken 53503 5036 912 846 558 Unieke bezoekers Unity.nl Facebook fans Twitter volgers Instagram volgers YouTube volgers Info standbezoekers In 2019 zijn de gegevens van 6250 bezoekers van de Unity-stand, die de achterkant van de kennisquiz hebben ingevuld, geanalyseerd.