Two Essays in Business Forecasting and Decision-Making
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Guión Y Dirección De Un Cortometraje
Clase magistral "Creando un icono del terror" con George Donald “Don” Mancini Madrid, 24 de octubre de 2018 Organizado por: Actividad promovida por el Consejo Territorial de SGAE en Madrid DESTINATARIOS: Guionistas, directores, escritores y profesionales del audiovisual que estén interesados en conocer el nacimiento, evolución y desarrollo del personaje de la saga de películas de terror Child's Play: Chucky. 1 CONTENIDOS: George Donald expondrá en una charla abierta los aspectos más relevantes de la construcción del personaje Chucky. Chucky, que debutó en el cine hace treinta años, es uno de los iconos más importantes del cine de terror del siglo XX y durante esta clase tendremos la oportunidad de entender cómo se creó un personaje que, a día de hoy, es capaz de reinventarse para no dejar de sorprender y asustar al espectador. El nacimiento, la evolución, el desarrollo o el proceso de caracterización serán algunos de los aspectos a tratar por su creador además de compartir con los asistentes su experiencia profesional tanto en el ámbito cinematográfico como televisivo. PROFESOR: Don Mancini Es un guionista, productor y director de cine. Conocido internacionalmente por ser el creador de Chucky y guionista de toda su saga, integrada por un total de siete películas. La franquicia nació en 1988 con Muñeco diabólico (Child's Play) seguida de Muñeco diabólico 2 (1990), Muñeco diabólico 3 (1991), La novia de Chucky (Bride of Chucky. 1998), La semilla de Chucky (Seed of Chucky. 2004), La maldición de Chucky (Curse of Chucky. 2013) y Cult of Chucky (2017). Ha sido director además de sus últimas secuelas; La semilla de Chucky, La maldición de Chucky y Cult of Chucky. -

Completeandleft
MEN WOMEN 1. Adam Ant=English musician who gained popularity as the Amy Adams=Actress, singer=134,576=68 AA lead singer of New Wave/post-punk group Adam and the Amy Acuff=Athletics (sport) competitor=34,965=270 Ants=70,455=40 Allison Adler=Television producer=151,413=58 Aljur Abrenica=Actor, singer, guitarist=65,045=46 Anouk Aimée=Actress=36,527=261 Atif Aslam=Pakistani pop singer and film actor=35,066=80 Azra Akin=Model and actress=67,136=143 Andre Agassi=American tennis player=26,880=103 Asa Akira=Pornographic act ress=66,356=144 Anthony Andrews=Actor=10,472=233 Aleisha Allen=American actress=55,110=171 Aaron Ashmore=Actor=10,483=232 Absolutely Amber=American, Model=32,149=287 Armand Assante=Actor=14,175=170 Alessandra Ambrosio=Brazilian model=447,340=15 Alan Autry=American, Actor=26,187=104 Alexis Amore=American pornographic actress=42,795=228 Andrea Anders=American, Actress=61,421=155 Alison Angel=American, Pornstar=642,060=6 COMPLETEandLEFT Aracely Arámbula=Mexican, Actress=73,760=136 Anne Archer=Film, television actress=50,785=182 AA,Abigail Adams AA,Adam Arkin Asia Argento=Actress, film director=85,193=110 AA,Alan Alda Alison Armitage=English, Swimming=31,118=299 AA,Alan Arkin Ariadne Artiles=Spanish, Model=31,652=291 AA,Alan Autry Anara Atanes=English, Model=55,112=170 AA,Alvin Ailey ……………. AA,Amedeo Avogadro ACTION ACTION AA,Amy Adams AA,Andre Agasi ALY & AJ AA,Andre Agassi ANDREW ALLEN AA,Anouk Aimée ANGELA AMMONS AA,Ansel Adams ASAF AVIDAN AA,Army Archerd ASKING ALEXANDRIA AA,Art Alexakis AA,Arthur Ashe ATTACK ATTACK! AA,Ashley -

Alyson Hannigan Listing by Ren Smith Featured in USA Today
Alyson Hannigan listing by Ren Smith featured in USA Today February 14, 2018 Alyson Hannigan has a genius way of keeping organized at home Alyson Hannigan is giving us serious inspiration. Having trouble keeping your family’s schedule organized? Steal this fun DIY idea from actress Alyson Hannigan. The “How I Met Your Mother” star recently put her Santa Monica, California house up for sale, and we noticed a large chalkboard calendar on one of the walls in the kitchen area. It made us immediately want to grab a bucket of chalkboard paintand some wood to create one like it in our own homes. The wall features five rows of seven squares separated by narrow strips of wood. Along the top of the larger frame that surrounds the calendar are the names of the days of the week. Each box can be numbered with chalk according to the current month. It’s the perfect place to write down appointment reminders, your kids’ sports practice schedules and even menu plans for the week. And when you want to keep track of miscellaneous things — such as future vacation countdowns, phone numbers, or notes to family members — there’s a larger square on the side for that. The wall can easily be re-created with a few supplies from a home improvement store, and there are also so many variations you can do, such as using whiteboard paint as the base or creating the frame and boxes with Washi tape if you don’t want to work with wood. Hannigan, who has two young daughters, told People in 2016 that she loves to craft so much, she turned her guest house into a crafting room. -

The Community-Centered Cult Television Heroine, 1995-2007
University of Nebraska - Lincoln DigitalCommons@University of Nebraska - Lincoln Dissertations, Theses, and Student Research: Department of English English, Department of 2010 "Just a Girl": The Community-Centered Cult Television Heroine, 1995-2007 Tamy Burnett University of Nebraska at Lincoln Follow this and additional works at: https://digitalcommons.unl.edu/englishdiss Part of the Feminist, Gender, and Sexuality Studies Commons, Literature in English, North America Commons, and the Visual Studies Commons Burnett, Tamy, ""Just a Girl": The Community-Centered Cult Television Heroine, 1995-2007" (2010). Dissertations, Theses, and Student Research: Department of English. 27. https://digitalcommons.unl.edu/englishdiss/27 This Article is brought to you for free and open access by the English, Department of at DigitalCommons@University of Nebraska - Lincoln. It has been accepted for inclusion in Dissertations, Theses, and Student Research: Department of English by an authorized administrator of DigitalCommons@University of Nebraska - Lincoln. “JUST A GIRL”: THE COMMUNITY-CENTERED CULT TELEVISION HEROINE, 1995-2007 by Tamy Burnett A DISSERTATION Presented to the Faculty of The Graduate College at the University of Nebraska In Partial Fulfillment of Requirements For the Degree of Doctor of Philosophy Major: English (Specialization: Women‟s and Gender Studies) Under the Supervision of Professor Kwakiutl L. Dreher Lincoln, Nebraska May, 2010 “JUST A GIRL”: THE COMMUNITY-CENTERED CULT TELEVISION HEROINE, 1995-2007 Tamy Burnett, Ph.D. University of Nebraska, 2010 Adviser: Kwakiutl L. Dreher Found in the most recent group of cult heroines on television, community- centered cult heroines share two key characteristics. The first is their youth and the related coming-of-age narratives that result. -

Tom Hanks Halle Berry Martin Sheen Brad Pitt Robert Deniro Jodie Foster Will Smith Jay Leno Jared Leto Eli Roth Tom Cruise Steven Spielberg
TOM HANKS HALLE BERRY MARTIN SHEEN BRAD PITT ROBERT DENIRO JODIE FOSTER WILL SMITH JAY LENO JARED LETO ELI ROTH TOM CRUISE STEVEN SPIELBERG MICHAEL CAINE JENNIFER ANISTON MORGAN FREEMAN SAMUEL L. JACKSON KATE BECKINSALE JAMES FRANCO LARRY KING LEONARDO DICAPRIO JOHN HURT FLEA DEMI MOORE OLIVER STONE CARY GRANT JUDE LAW SANDRA BULLOCK KEANU REEVES OPRAH WINFREY MATTHEW MCCONAUGHEY CARRIE FISHER ADAM WEST MELISSA LEO JOHN WAYNE ROSE BYRNE BETTY WHITE WOODY ALLEN HARRISON FORD KIEFER SUTHERLAND MARION COTILLARD KIRSTEN DUNST STEVE BUSCEMI ELIJAH WOOD RESSE WITHERSPOON MICKEY ROURKE AUDREY HEPBURN STEVE CARELL AL PACINO JIM CARREY SHARON STONE MEL GIBSON 2017-18 CATALOG SAM NEILL CHRIS HEMSWORTH MICHAEL SHANNON KIRK DOUGLAS ICE-T RENEE ZELLWEGER ARNOLD SCHWARZENEGGER TOM HANKS HALLE BERRY MARTIN SHEEN BRAD PITT ROBERT DENIRO JODIE FOSTER WILL SMITH JAY LENO JARED LETO ELI ROTH TOM CRUISE STEVEN SPIELBERG CONTENTS 2 INDEPENDENT | FOREIGN | ARTHOUSE 23 HORROR | SLASHER | THRILLER 38 FACTUAL | HISTORICAL 44 NATURE | SUPERNATURAL MICHAEL CAINE JENNIFER ANISTON MORGAN FREEMAN 45 WESTERNS SAMUEL L. JACKSON KATE BECKINSALE JAMES FRANCO 48 20TH CENTURY TELEVISION LARRY KING LEONARDO DICAPRIO JOHN HURT FLEA 54 SCI-FI | FANTASY | SPACE DEMI MOORE OLIVER STONE CARY GRANT JUDE LAW 57 POLITICS | ESPIONAGE | WAR SANDRA BULLOCK KEANU REEVES OPRAH WINFREY MATTHEW MCCONAUGHEY CARRIE FISHER ADAM WEST 60 ART | CULTURE | CELEBRITY MELISSA LEO JOHN WAYNE ROSE BYRNE BETTY WHITE 64 ANIMATION | FAMILY WOODY ALLEN HARRISON FORD KIEFER SUTHERLAND 78 CRIME | DETECTIVE -

Exploring Films About Ethical Leadership: Can Lessons Be Learned?
EXPLORING FILMS ABOUT ETHICAL LEADERSHIP: CAN LESSONS BE LEARNED? By Richard J. Stillman II University of Colorado at Denver and Health Sciences Center Public Administration and Management Volume Eleven, Number 3, pp. 103-305 2006 104 DEDICATED TO THOSE ETHICAL LEADERS WHO LOST THEIR LIVES IN THE 9/11 TERROIST ATTACKS — MAY THEIR HEORISM BE REMEMBERED 105 TABLE OF CONTENTS Preface 106 Advancing Our Understanding of Ethical Leadership through Films 108 Notes on Selecting Films about Ethical Leadership 142 Index by Subject 301 106 PREFACE In his preface to James M cG regor B urns‘ Pulitzer–prizewinning book, Leadership (1978), the author w rote that ―… an im m ense reservoir of data and analysis and theories have developed,‖ but ―w e have no school of leadership.‖ R ather, ―… scholars have worked in separate disciplines and sub-disciplines in pursuit of different and often related questions and problem s.‖ (p.3) B urns argued that the tim e w as ripe to draw together this vast accumulation of research and analysis from humanities and social sciences in order to arrive at a conceptual synthesis, even an intellectual breakthrough for understanding of this critically important subject. Of course, that was the aim of his magisterial scholarly work, and while unquestionably impressive, his tome turned out to be by no means the last word on the topic. Indeed over the intervening quarter century, quite to the contrary, we witnessed a continuously increasing outpouring of specialized political science, historical, philosophical, psychological, and other disciplinary studies with clearly ―no school of leadership‖with a single unifying theory emerging. -

Art, Argento and the Rape-Revenge Film
University of Edinburgh Postgraduate Journal of Culture and the Arts Issue 13 | Autumn 2011 Title The Violation of Representation: Art, Argento and the Rape-Revenge Film Author Alexandra Heller-Nicholas Publication FORUM: University of Edinburgh Postgraduate Journal of Culture and the Arts Issue Number 13 Issue Date Autumn 2011 Publication Date 6/12/2011 Editors Dorothy Butchard & Barbara Vrachnas FORUM claims non-exclusive rights to reproduce this article electronically (in full or in part) and to publish this work in any such media current or later developed. The author retains all rights, including the right to be identified as the author wherever and whenever this article is published, and the right to use all or part of the article and abstracts, with or without revision or modification in compilations or other publications. Any latter publication shall recognise FORUM as the original publisher. FORUM | ISSUE 13 Alexandra Heller-Nicholas 1 The Violation of Representation: Art, Argento and the Rape-Revenge Film Alexandra Heller-Nicholas Swinburne University of Technology Considering the moral controversies surrounding films such as I Spit on Your Grave (Meir Zarch, 1976) and Baise-Moi (Virginie Despentes and Coralie Trinh-Thi, 2000), the rape-revenge film is often typecast as gratuitous and regressive. But far from dismissing rape-revenge in her foundational book Men, Women and Chain Saws: Gender in the Modern Horror Film (1992), Carol J. Clover suggests that these movies permit unique insight into the representation of gendered bodies on screen. In Images of Rape: The ‘Heroic’ Tradition and Its Alternatives (1999), art historian Diane Wolfthal demonstrates that contradictory representations of sexual violence co-existed long before the advent of the cinematic image, and a closer analysis of films that fall into the rape-revenge category reveals that they too resist a singular classification. -

Radiocorrieretv SETTIMANALE DELLA RAI RADIOTELEVISIONE
RadiocorriereTv SETTIMANALE DELLA RAI RADIOTELEVISIONE ITALIANA numero 10 - anno 90 8 marzo 2021 Reg. Trib. n. 673 del 16 dicembre 1997 MANESKIN TRIONFO ROCK ©Maurizio D'Avanzo NELLE LIBRERIE E STORE DIGITALI Nelle librerie e store digitali 2 TV RADIOCORRIERE 3 3 Nelle librerie PERCHE’ SANREMO e store digitali È SANREMO Sanremo è finito. Viva Sanremo. Come ogni anno ci sono vincitori e vinti, ci sono critiche e commenti, applausi e fischi, anche in questa edizione da remoto. Poi ci sono loro. I dipendenti di questa azienda, a volte bistrattata, ma sempre presenti, con forza, capacità e soprattutto con tanta dignità. E allora grazie a tutte, ma proprio tutte, le maestranze della Rai che ancora una volta hanno messo in campo tutto quello che potevano lavorando anche in condizioni di grandissima difficoltà. Grazie a chi ha lasciato per settimane i propri affetti, in questo periodo non era facile, per trasferirsi a lavorare in una città molto diversa da quella glamour e festante degli anni passati. Un lavoro certosino, meticoloso come sempre, solo come quello che i tecnici e giornalisti Rai sanno fare quando sono chiamati a giocare finali. Questo Festival ha portato rispetto e forse non lo ha ricevuto del tutto. Non era facile calarsi con garbo in un periodo fatto di sofferenze e paure. Cercare di entrare nelle case degli italiani spaventati. Per una settimana si è provato a far riscoprire quel desiderio di normalità misto a fiducia. Cinque serate di evasione, di riflessione, ma anche di speranza che il mondo della musica, dello spettacolo, possano tornare quanto prima a regalare emozioni. -

2015 Program
Table of Contents 13 41 47 52 7 Festival Team and Special Thanks 9 Festival Details 10 Founder’s Note 13 About UNICEF: 2015 Charity Partner 14 Rachel Winter: Women in Production Panelist, Writer and Producer 17 Programmer’s Note 18 2015 Narrative and Documentary Feature Films 30 2015 Narrative and Documentary Short Films 36 Festival Village Map 40 VIP Lounge and Celebrity Gifting Suites 41 Colin Hanks: Panelist, Executive Board Member and Director 43 Panels and Workshops 51 Opening Night Party 52 Changemaker Honoree Gala 54 Alysia Reiner: Social Impact Juror, Panelist, Actress and Director 62 2015 Sponsors 63 Festival Partners 66 Special Thanks to Supporters Official Program content as of May 15, 2015 | Please visit website for Festival Updates | 5 | 7 8 | Festival details Passes and Tickets Please visit www.greenwichfilm.org for ticket information and a current schedule of events. Purchase passes and event tickets online or from our Box Office. To Purchase Website: www.greenwichfilm.org Box Office: 340 Greenwich Avenue, Greenwich, CT 06830 Monday-Friday 9-6PM Saturday-Sunday: 12-4PM Box Office Telephone: (203) 340-2735 Admission for Passholder vs. Ticket Holders Passholders are required to wear their badge at the entrance of all Festival events. Ticket holders must present their printed tickets at the entrance to Festival events. Films, Parties and Panels Film Screening Locations Cole Auditorium, Greenwich Library: 101 West Putnam Avenue, Greenwich, CT 06831 Bow Tie Cinemas, Theaters 1 -3: 2 Railroad Avenue, Greenwich, CT 06830 Panel -

DOUGLAS S. JONES Line Producer/UPM
DOUGLAS S. JONES Line Producer/UPM THE WATSONS GO TO BIRMINGHAM ; Bryce Jenkins Exec. In Charge of Prod./UPM Dir: Kenny Leon. Producers: Nikki Silver, Tonya Lewis Lee Walden Media Location: Atlanta, Georgia DEAR DUMB DIARY ; Emily Alyn Lind Exec. In Charge of Prod. Dir: Kristin Hanggi. Producers: Janet Zucker, Jerry Zucker Walden Media Location: Salt Lake City, Utah PARENTAL GUIDANCE; Billy Crystal, Bette Midler Exec. In Charge of Prod. Dir: Andy Fickman. Producers: Peter Chernin, Billy Crystal Walden Media Location: Atlanta, Georgia WON’T BACK DOWN ; Viola Davis, Maggie Gyllenhaal Exec. In Charge of Prod. Dir: Daniel Barnz. Producer: Mark Johnson. Walden Media Location: Pittsburgh, Pennsylvania CHASING MAVERICKS; Gerard Butler, Elisabeth Shue Exec. In Charge of Prod. Dir: Curtis Hanson, Michael Apted. Walden Media Producers: Mark Johnson, Jim Meenaghan Location: Northern California THE CHRONICLES OF NARNIA: Exec. In Charge of Prod. VOYAGE OF THE DAWN TREADER; Walden Media Ben Barnes, Skandar Keynes, Georgie Henley. Dir: Michael Apted. Producers: Mark Johnson, Phil Steuer Location: Gold Coast, Australia. BAND SLAM ; Vanessa Hudgens, Aly Michalka Exec. In Charge of Prod. Dir: Todd Graff. Producer: Elaine Goldsmith Thomas Walden Media Location: Austin, Texas JOURNEY TO THE CENTER OF THE EARTH; Exec. In Charge of Prod. Brendan Fraser, Josh Hutcherson Walden Media Dir: Eric Brevig. Producer: Beau Flynn Location: Montreal, Canada CITY OF EMBER ; Saoirse Ronan, Bill Murray Exec. In Charge of Prod. Dir: Gil Kenan. Producers: Gary Goetzman, Tom Hanks Walden Media Location: Belfast, Ireland T Exec. In Charge of Prod. 6399 Wilshire Blvd., Ste. 415 Los Angeles, CA 90048 ph 323.782.1854 fx 323.345.5690 [email protected] HE CHRONICLES OF NARNIA: PRINCE CASPIAN; Walden Media Ben Barnes, Skandar Keynes, Georgia Henley Dir: Andrew Adamson. -
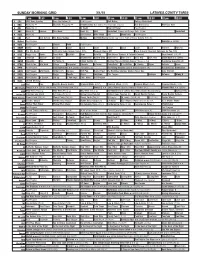
Sunday Morning Grid 3/1/15 Latimes.Com/Tv Times
SUNDAY MORNING GRID 3/1/15 LATIMES.COM/TV TIMES 7 am 7:30 8 am 8:30 9 am 9:30 10 am 10:30 11 am 11:30 12 pm 12:30 2 CBS CBS News Sunday Face the Nation (N) Paid Program Bull Riding College Basketball 4 NBC News (N) Å Meet the Press (N) Å Snowboarding U.S. Grand Prix: Slopestyle. (Taped) Red Bull Series PGA Tour Golf 5 CW News (N) Å In Touch Hour Of Power Paid Program 7 ABC News (N) Explore This Week News (N) NBA Basketball Clippers at Chicago Bulls. (N) Å Basketball 9 KCAL News (N) Joel Osteen Mike Webb Paid Woodlands Paid Program 11 FOX Paid Joel Osteen Fox News Sunday Midday NASCAR Racing Sprint Cup Series: Folds of Honor QuikTrip 500. (N) 13 MyNet Paid Program Swimfan › (2002) 18 KSCI Paid Program Church Faith Paid Program 22 KWHY Como Local Local Local Local Local Local Local Local Local Transfor. Transfor. 24 KVCR T’ai Chi, Health JJ Virgin’s Sugar Impact Secret (TVG) Deepak Chopra MD Suze Orman’s Financial Solutions for You (TVG) 28 KCET Raggs New. Space Travel-Kids Biz Kid$ News Asia Biz Rick Steves’ Europe: A Cultural Carnival Over Hawai’i (TVG) Å 30 ION Jeremiah Youssef In Touch Bucket-Dino Bucket-Dino Doki (TVY7) Doki (TVY7) Dive, Olly Dive, Olly Uncle Buck ›› (1989) 34 KMEX Conexión Paid Al Punto (N) Fútbol Central (N) Mexico Primera Division Soccer: Toluca vs Azul República Deportiva (N) 40 KTBN Walk in the Win Walk Prince Carpenter Liberate In Touch PowerPoint It Is Written B. -

Teaching World History with Major Motion Pictures
Social Education 76(1), pp 22–28 ©2012 National Council for the Social Studies The Reel History of the World: Teaching World History with Major Motion Pictures William Benedict Russell III n today’s society, film is a part of popular culture and is relevant to students’ as well as an explanation as to why the everyday lives. Most students spend over 7 hours a day using media (over 50 class will view the film. Ihours a week).1 Nearly 50 percent of students’ media use per day is devoted to Watching the Film. When students videos (film) and television. With the popularity and availability of film, it is natural are watching the film (in its entirety that teachers attempt to engage students with such a relevant medium. In fact, in or selected clips), ensure that they are a recent study of social studies teachers, 100 percent reported using film at least aware of what they should be paying once a month to help teach content.2 In a national study of 327 teachers, 69 percent particular attention to. Pause the film reported that they use some type of film/movie to help teach Holocaust content. to pose a question, provide background, The method of using film and the method of using firsthand accounts were tied for or make a connection with an earlier les- the number one method teachers use to teach Holocaust content.3 Furthermore, a son. Interrupting a showing (at least once) national survey of social studies teachers conducted in 2006, found that 63 percent subtly reminds students that the purpose of eighth-grade teachers reported using some type of video-based activity in the of this classroom activity is not entertain- last social studies class they taught.4 ment, but critical thinking.