Peak Performance
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Microcode Revision Guidance August 31, 2019 MCU Recommendations
microcode revision guidance August 31, 2019 MCU Recommendations Section 1 – Planned microcode updates • Provides details on Intel microcode updates currently planned or available and corresponding to Intel-SA-00233 published June 18, 2019. • Changes from prior revision(s) will be highlighted in yellow. Section 2 – No planned microcode updates • Products for which Intel does not plan to release microcode updates. This includes products previously identified as such. LEGEND: Production Status: • Planned – Intel is planning on releasing a MCU at a future date. • Beta – Intel has released this production signed MCU under NDA for all customers to validate. • Production – Intel has completed all validation and is authorizing customers to use this MCU in a production environment. -

Asrock G41C-VS Motherboard, a Reliable Motherboard Produced Under Asrock’S Consistently Stringent Quality Control
G41C-VS User Manual Version 1.0 Published October 2009 Copyright©2009 ASRock INC. All rights reserved. 1 Copyright Notice: No part of this manual may be reproduced, transcribed, transmitted, or translated in any language, in any form or by any means, except duplication of documentation by the purchaser for backup purpose, without written consent of ASRock Inc. Products and corporate names appearing in this manual may or may not be regis- tered trademarks or copyrights of their respective companies, and are used only for identification or explanation and to the owners’ benefit, without intent to infringe. Disclaimer: Specifications and information contained in this manual are furnished for informa- tional use only and subject to change without notice, and should not be constructed as a commitment by ASRock. ASRock assumes no responsibility for any errors or omissions that may appear in this manual. With respect to the contents of this manual, ASRock does not provide warranty of any kind, either expressed or implied, including but not limited to the implied warran- ties or conditions of merchantability or fitness for a particular purpose. In no event shall ASRock, its directors, officers, employees, or agents be liable for any indirect, special, incidental, or consequential damages (including damages for loss of profits, loss of business, loss of data, interruption of business and the like), even if ASRock has been advised of the possibility of such damages arising from any defect or error in the manual or product. This device complies with Part 15 of the FCC Rules. Operation is subject to the following two conditions: (1) this device may not cause harmful interference, and (2) this device must accept any interference received, including interference that may cause undesired operation. -

The Von Neumann Computer Model 5/30/17, 10:03 PM
The von Neumann Computer Model 5/30/17, 10:03 PM CIS-77 Home http://www.c-jump.com/CIS77/CIS77syllabus.htm The von Neumann Computer Model 1. The von Neumann Computer Model 2. Components of the Von Neumann Model 3. Communication Between Memory and Processing Unit 4. CPU data-path 5. Memory Operations 6. Understanding the MAR and the MDR 7. Understanding the MAR and the MDR, Cont. 8. ALU, the Processing Unit 9. ALU and the Word Length 10. Control Unit 11. Control Unit, Cont. 12. Input/Output 13. Input/Output Ports 14. Input/Output Address Space 15. Console Input/Output in Protected Memory Mode 16. Instruction Processing 17. Instruction Components 18. Why Learn Intel x86 ISA ? 19. Design of the x86 CPU Instruction Set 20. CPU Instruction Set 21. History of IBM PC 22. Early x86 Processor Family 23. 8086 and 8088 CPU 24. 80186 CPU 25. 80286 CPU 26. 80386 CPU 27. 80386 CPU, Cont. 28. 80486 CPU 29. Pentium (Intel 80586) 30. Pentium Pro 31. Pentium II 32. Itanium processor 1. The von Neumann Computer Model Von Neumann computer systems contain three main building blocks: The following block diagram shows major relationship between CPU components: the central processing unit (CPU), memory, and input/output devices (I/O). These three components are connected together using the system bus. The most prominent items within the CPU are the registers: they can be manipulated directly by a computer program. http://www.c-jump.com/CIS77/CPU/VonNeumann/lecture.html Page 1 of 15 IPR2017-01532 FanDuel, et al. -

UNIT 8B a Full Adder
UNIT 8B Computer Organization: Levels of Abstraction 15110 Principles of Computing, 1 Carnegie Mellon University - CORTINA A Full Adder C ABCin Cout S in 0 0 0 A 0 0 1 0 1 0 B 0 1 1 1 0 0 1 0 1 C S out 1 1 0 1 1 1 15110 Principles of Computing, 2 Carnegie Mellon University - CORTINA 1 A Full Adder C ABCin Cout S in 0 0 0 0 0 A 0 0 1 0 1 0 1 0 0 1 B 0 1 1 1 0 1 0 0 0 1 1 0 1 1 0 C S out 1 1 0 1 0 1 1 1 1 1 ⊕ ⊕ S = A B Cin ⊕ ∧ ∨ ∧ Cout = ((A B) C) (A B) 15110 Principles of Computing, 3 Carnegie Mellon University - CORTINA Full Adder (FA) AB 1-bit Cout Full Cin Adder S 15110 Principles of Computing, 4 Carnegie Mellon University - CORTINA 2 Another Full Adder (FA) http://students.cs.tamu.edu/wanglei/csce350/handout/lab6.html AB 1-bit Cout Full Cin Adder S 15110 Principles of Computing, 5 Carnegie Mellon University - CORTINA 8-bit Full Adder A7 B7 A2 B2 A1 B1 A0 B0 1-bit 1-bit 1-bit 1-bit ... Cout Full Full Full Full Cin Adder Adder Adder Adder S7 S2 S1 S0 AB 8 ⁄ ⁄ 8 C 8-bit C out FA in ⁄ 8 S 15110 Principles of Computing, 6 Carnegie Mellon University - CORTINA 3 Multiplexer (MUX) • A multiplexer chooses between a set of inputs. D1 D 2 MUX F D3 D ABF 4 0 0 D1 AB 0 1 D2 1 0 D3 1 1 D4 http://www.cise.ufl.edu/~mssz/CompOrg/CDAintro.html 15110 Principles of Computing, 7 Carnegie Mellon University - CORTINA Arithmetic Logic Unit (ALU) OP 1OP 0 Carry In & OP OP 0 OP 1 F 0 0 A ∧ B 0 1 A ∨ B 1 0 A 1 1 A + B http://cs-alb-pc3.massey.ac.nz/notes/59304/l4.html 15110 Principles of Computing, 8 Carnegie Mellon University - CORTINA 4 Flip Flop • A flip flop is a sequential circuit that is able to maintain (save) a state. -

Toshiba Hardware Portfolio – Microsoft Support by Family
Date created: 6/17/2020 Toshiba Hardware Portfolio – Microsoft Support by Family Windows 10 Windows 10 Windows 10 Toshiba Windows 10 Toshiba IoT IoT Enterprise Intel Platform Machine Intel Processor Model IoT Enterprise Family Enterprise LTSC 2019 Type LTSB 2015 LTSB 2016 Core i3 9100TE 777 TCx™ 700 4900 Core i5 9500T 787 9th Gen Core Core i7 9700T 797 (Coffee Lake Not Supported Refresh) Core i3 9100TE 371 TCx™ 300 4810 Core i5 9500T 381 Core i7 9700T 391 8th Gen Core TCx™ 300 4810 361 Celeron 4900T (Coffee Lake) TCx™ 700 4900 767 107 Available now and Core i7 7600U 117 supported until 137 Not Supported Jan 9, 2029 105 Core i5 7300U 115 7th Gen Core 135 TCx™ 800 6200 Available (Kaby Lake) 103 now and Core i3 7100U 113 supported until 133 Oct 13, 2026 10C Celeron 3965U 11C 13C N/A 4750 AMD GX-218GL D10 SoC Family Basics Celeron J1900 4818 T10 (Bay Trail) Quad Not Supported 6th Gen Core 145 TCxWave™ 6140 Core i5 6300U (Skylake/Q170) 155 Date created: 6/17/2020 14C Celeron 3955U 15C SoC Family Celeron J1900 A3R (Bay Trail) Quad Core i5 4950S 786 Available Core i3 4330 C86 now and TCx™ 700 4900 Celeron G1820 supported until 746 Oct 14, 2025 4th Gen Core Celeron G1820TE (Haswell/Q87) C46 Core i5 4570TE 380 TCx™ 300 4810 Core i3 4330TE 370 Celeron G1820TE 360 3rd Gen Core + TCxWave ™ 6140 Core i3 3217UE 120 2nd Gen PCH SurePOS (IvyBridge CPU + 4852 Core i5 3550S 580 CougarPoint PCH) 500 Toshiba Toshiba Limited TCxWave ™ 6140 Celeron 847E 100 Limited Support SurePOS Celeron G540 785 Support 2nd Gen Core 4900 700 Core i3 2120 C85 (SandyBridge/Q67) -

Class-Action Lawsuit
Case 3:20-cv-00863-SI Document 1 Filed 05/29/20 Page 1 of 279 Steve D. Larson, OSB No. 863540 Email: [email protected] Jennifer S. Wagner, OSB No. 024470 Email: [email protected] STOLL STOLL BERNE LOKTING & SHLACHTER P.C. 209 SW Oak Street, Suite 500 Portland, Oregon 97204 Telephone: (503) 227-1600 Attorneys for Plaintiffs [Additional Counsel Listed on Signature Page.] UNITED STATES DISTRICT COURT DISTRICT OF OREGON PORTLAND DIVISION BLUE PEAK HOSTING, LLC, PAMELA Case No. GREEN, TITI RICAFORT, MARGARITE SIMPSON, and MICHAEL NELSON, on behalf of CLASS ACTION ALLEGATION themselves and all others similarly situated, COMPLAINT Plaintiffs, DEMAND FOR JURY TRIAL v. INTEL CORPORATION, a Delaware corporation, Defendant. CLASS ACTION ALLEGATION COMPLAINT Case 3:20-cv-00863-SI Document 1 Filed 05/29/20 Page 2 of 279 Plaintiffs Blue Peak Hosting, LLC, Pamela Green, Titi Ricafort, Margarite Sampson, and Michael Nelson, individually and on behalf of the members of the Class defined below, allege the following against Defendant Intel Corporation (“Intel” or “the Company”), based upon personal knowledge with respect to themselves and on information and belief derived from, among other things, the investigation of counsel and review of public documents as to all other matters. INTRODUCTION 1. Despite Intel’s intentional concealment of specific design choices that it long knew rendered its central processing units (“CPUs” or “processors”) unsecure, it was only in January 2018 that it was first revealed to the public that Intel’s CPUs have significant security vulnerabilities that gave unauthorized program instructions access to protected data. 2. A CPU is the “brain” in every computer and mobile device and processes all of the essential applications, including the handling of confidential information such as passwords and encryption keys. -

Lecture Notes
Lecture #4-5: Computer Hardware (Overview and CPUs) CS106E Spring 2018, Young In these lectures, we begin our three-lecture exploration of Computer Hardware. We start by looking at the different types of computer components and how they interact during basic computer operations. Next, we focus specifically on the CPU (Central Processing Unit). We take a look at the Machine Language of the CPU and discover it’s really quite primitive. We explore how Compilers and Interpreters allow us to go from the High-Level Languages we are used to programming to the Low-Level machine language actually used by the CPU. Most modern CPUs are multicore. We take a look at when multicore provides big advantages and when it doesn’t. We also take a short look at Graphics Processing Units (GPUs) and what they might be used for. We end by taking a look at Reduced Instruction Set Computing (RISC) and Complex Instruction Set Computing (CISC). Stanford President John Hennessy won the Turing Award (Computer Science’s equivalent of the Nobel Prize) for his work on RISC computing. Hardware and Software: Hardware refers to the physical components of a computer. Software refers to the programs or instructions that run on the physical computer. - We can entirely change the software on a computer, without changing the hardware and it will transform how the computer works. I can take an Apple MacBook for example, remove the Apple Software and install Microsoft Windows, and I now have a Window’s computer. - In the next two lectures we will focus entirely on Hardware. -
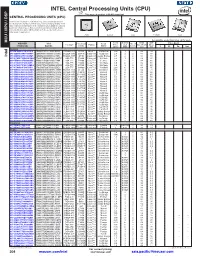
INTEL Central Processing Units (CPU) This Page of Product Is Rohs Compliant
INTEL Central Processing Units (CPU) This page of product is RoHS compliant. CENTRAL PROCESSING UNITS (CPU) Intel Processor families include the most powerful and flexible Central Processing Units (CPUs) available today. Utilizing industry leading 22nm device fabrication techniques, Intel continues to pack greater processing power into smaller spaces than ever before, providing desktop, mobile, and embedded products with maximum performance per watt across a wide range of applications. Atom Celeron Core Pentium Xeon For quantities greater than listed, call for quote. MCU \ MPU / DSP MPU / MCU \ MOUSER Intel Core Cache Data TDP Price Each Package Processor Family Code Freq. Size No. of Bus Width (Max) STOCK NO. Part No. Series Name (GHz) (MB) Cores (bit) (W) 1 25 50 100 Desktop 607-DF8064101211300Y DF8064101211300S R0VY FCBGA-559 D2550 Atom™ Cedarview 1.86 1 2 64 10 607-CM8063701444901S CM8063701444901S R10K FCLGA-1155 G1610 Celeron® Ivy Bridge 2.6 2 2 64 55 Intel 607-CM8062301046804S CM8062301046804S R05J FCLGA-1155 G540 Celeron® Sandy Bridge 2.5 2 2 64 65 607-AT80571RG0641MLS AT80571RG0641MLS LGTZ LGA-775 E3400 Celeron® Wolfdale 2.6 1 2 64 65 607-HH80557PG0332MS HH80557PG0332MS LA99 LGA-775 E4300 Core™ 2 Conroe 1.8 2 2 64 65 607-AT80570PJ0806MS AT80570PJ0806MS LB9J LGA-775 E8400 Core™ 2 Wolfdale 3.0 6 2 64 65 607-AT80571PH0723MLS AT80571PH0723MLS LGW3 LGA-775 E7400 Core™ 2 Wolfdale 2.8 3 2 64 65 607-AT80580PJ0676MS AT80580PJ0676MS LB6B LGA-775 Q9400 Core™ 2 Yorkfield 2.66 6 4 64 95 607-CM80616003060AES CM80616003060AES LBTD FCLGA-1156 -

Intel® Celeron® Processor 900 Series and Ultra Low Voltage 700 Series
Intel® Celeron® Processor 900 Series and Ultra Low Voltage 700 Series Datasheet For platforms based on Mobile Intel® 4 Series Chipset family February 2010 Document Number: 320389-003 INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL® PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROPERTY RIGHTS IS GRANTED BY THIS DOCUMENT. EXCEPT AS PROVIDED IN INTEL'S TERMS AND CONDITIONS OF SALE FOR SUCH PRODUCTS, INTEL ASSUMES NO LIABILITY WHATSOEVER, AND INTEL DISCLAIMS ANY EXPRESS OR IMPLIED WARRANTY, RELATING TO SALE AND/OR USE OF INTEL PRODUCTS INCLUDING LIABILITY OR WARRANTIES RELATING TO FITNESS FOR A PARTICULAR PURPOSE, MERCHANTABILITY, OR INFRINGEMENT OF ANY PATENT, COPYRIGHT OR OTHER INTELLECTUAL PROPERTY RIGHT. UNLESS OTHERWISE AGREED IN WRITING BY INTEL, THE INTEL PRODUCTS ARE NOT DESIGNED NOR INTENDED FOR ANY APPLICATION IN WHICH THE FAILURE OF THE INTEL PRODUCT COULD CREATE A SITUATION WHERE PERSONAL INJURY OR DEATH MAY OCCUR. Intel may make changes to specifications and product descriptions at any time, without notice. Designers must not rely on the absence or characteristics of any features or instructions marked “reserved” or “undefined.” Intel reserves these for future definition and shall have no responsibility whatsoever for conflicts or incompatibilities arising from future changes to them. The information here is subject to change without notice. Do not finalize a design with this information. The products described in this document may contain design defects or errors known as errata which may cause the product to deviate from published specifications. Current characterized errata are available on request. Contact your local Intel sales office or your distributor to obtain the latest specifications and before placing your product order. -

HC19.21.810.45Nm Next Generation Intel® Core™ Microarchitecture
45nm Next Generation Intel® Core™ Microarchitecture (Penryn) HOT CHIPS 2007 Varghese George Principal Engineer, Intel Corp Legal Disclaimer Today’s presentation may contain forward-looking statements. All statements made that are not historical facts are subject to a number of risks and uncertainties, and actual results may differ materially. Please refer to our most recent Earnings Release and our most recent Form 10-Q or 10-K filing available on our website for more information on the risk factors that could cause actual results to differ. INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL® PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROPERTY RIGHTS IS GRANTED BY THIS DOCUMENT. EXCEPT AS PROVIDED IN INTEL’S TERMS AND CONDITIONS OF SALE FOR SUCH PRODUCTS, INTEL ASSUMES NO LIABILITY WHATSOEVER, AND INTEL DISCLAIMS ANY EXPRESS OR IMPLIED WARRANTY, RELATING TO SALE AND/OR USE OF INTEL PRODUCTS INCLUDING LIABILITY OR WARRANTIES RELATING TO FITNESS FOR A PARTICULAR PURPOSE, MERCHANTABILITY, OR INFRINGEMENT OF ANY PATENT, COPYRIGHT OR OTHER INTELLECTUAL PROPERTY RIGHT. Intel products are not intended for use in medical, life saving, or life sustaining applications. Intel may make changes to specifications and product descriptions at any time, without notice. Designers must not rely on the absence or characteristics of any features or instructions marked "reserved" or "undefined." Intel reserves these for future definition and shall have no responsibility whatsoever for conflicts or incompatibilities arising from future changes to them. The Intel® Core™ Microarchitecture, Intel® Pentium, Intel® Pentium II, Intel® Pentium III, Intel® Pentium 4, Intel® Pentium Pro, Intel® Pentium D, Intel® Pentium M , Itanium®, Xeon® may contain design defects or errors known as errata which may cause the product to deviate from published specifications. -

With Extreme Scale Computing the Rules Have Changed
With Extreme Scale Computing the Rules Have Changed Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester 11/17/15 1 • Overview of High Performance Computing • With Extreme Computing the “rules” for computing have changed 2 3 • Create systems that can apply exaflops of computing power to exabytes of data. • Keep the United States at the forefront of HPC capabilities. • Improve HPC application developer productivity • Make HPC readily available • Establish hardware technology for future HPC systems. 4 11E+09 Eflop/s 362 PFlop/s 100000000100 Pflop/s 10000000 10 Pflop/s 33.9 PFlop/s 1000000 1 Pflop/s SUM 100000100 Tflop/s 166 TFlop/s 1000010 Tflop /s N=1 1 Tflop1000/s 1.17 TFlop/s 100 Gflop/s100 My Laptop 70 Gflop/s N=500 10 59.7 GFlop/s 10 Gflop/s My iPhone 4 Gflop/s 1 1 Gflop/s 0.1 100 Mflop/s 400 MFlop/s 1994 1996 1998 2000 2002 2004 2006 2008 2010 2012 2014 2015 1 Eflop/s 1E+09 420 PFlop/s 100000000100 Pflop/s 10000000 10 Pflop/s 33.9 PFlop/s 1000000 1 Pflop/s SUM 100000100 Tflop/s 206 TFlop/s 1000010 Tflop /s N=1 1 Tflop1000/s 1.17 TFlop/s 100 Gflop/s100 My Laptop 70 Gflop/s N=500 10 59.7 GFlop/s 10 Gflop/s My iPhone 4 Gflop/s 1 1 Gflop/s 0.1 100 Mflop/s 400 MFlop/s 1994 1996 1998 2000 2002 2004 2006 2008 2010 2012 2014 2015 1E+10 1 Eflop/s 1E+09 100 Pflop/s 100000000 10 Pflop/s 10000000 1 Pflop/s 1000000 SUM 100 Tflop/s 100000 10 Tflop/s N=1 10000 1 Tflop/s 1000 100 Gflop/s N=500 100 10 Gflop/s 10 1 Gflop/s 1 100 Mflop/s 0.1 1996 2002 2020 2008 2014 1E+10 1 Eflop/s 1E+09 100 Pflop/s 100000000 10 Pflop/s 10000000 1 Pflop/s 1000000 SUM 100 Tflop/s 100000 10 Tflop/s N=1 10000 1 Tflop/s 1000 100 Gflop/s N=500 100 10 Gflop/s 10 1 Gflop/s 1 100 Mflop/s 0.1 1996 2002 2020 2008 2014 • Pflops (> 1015 Flop/s) computing fully established with 81 systems. -

Theoretical Peak FLOPS Per Instruction Set on Modern Intel Cpus
Theoretical Peak FLOPS per instruction set on modern Intel CPUs Romain Dolbeau Bull – Center for Excellence in Parallel Programming Email: [email protected] Abstract—It used to be that evaluating the theoretical and potentially multiple threads per core. Vector of peak performance of a CPU in FLOPS (floating point varying sizes. And more sophisticated instructions. operations per seconds) was merely a matter of multiplying Equation2 describes a more realistic view, that we the frequency by the number of floating-point instructions will explain in details in the rest of the paper, first per cycles. Today however, CPUs have features such as vectorization, fused multiply-add, hyper-threading or in general in sectionII and then for the specific “turbo” mode. In this paper, we look into this theoretical cases of Intel CPUs: first a simple one from the peak for recent full-featured Intel CPUs., taking into Nehalem/Westmere era in section III and then the account not only the simple absolute peak, but also the full complexity of the Haswell family in sectionIV. relevant instruction sets and encoding and the frequency A complement to this paper titled “Theoretical Peak scaling behavior of current Intel CPUs. FLOPS per instruction set on less conventional Revision 1.41, 2016/10/04 08:49:16 Index Terms—FLOPS hardware” [1] covers other computing devices. flop 9 I. INTRODUCTION > operation> High performance computing thrives on fast com- > > putations and high memory bandwidth. But before > operations => any code or even benchmark is run, the very first × micro − architecture instruction number to evaluate a system is the theoretical peak > > - how many floating-point operations the system > can theoretically execute in a given time.