Analysis of New Trends in the Web from a Network Perspective
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Characterizing Pixel Tracking Through the Lens of Disposable Email Services
Characterizing Pixel Tracking through the Lens of Disposable Email Services Hang Hu, Peng Peng, Gang Wang Department of Computer Science, Virginia Tech fhanghu, pengp17, [email protected] Abstract—Disposable email services provide temporary email services are highly popular. For example, Guerrilla Mail, one addresses, which allows people to register online accounts without of the earliest services, has processed 8 billion emails in the exposing their real email addresses. In this paper, we perform past decade [3]. the first measurement study on disposable email services with two main goals. First, we aim to understand what disposable While disposable email services allow users to hide their email services are used for, and what risks (if any) are involved real identities, the email communication itself is not necessar- in the common use cases. Second, we use the disposable email ily private. More specifically, most disposable email services services as a public gateway to collect a large-scale email dataset maintain a public inbox, allowing any user to access any for measuring email tracking. Over three months, we collected a dataset from 7 popular disposable email services which contain disposable email addresses at any time [6], [5]. Essentially 2.3 million emails sent by 210K domains. We show that online disposable email services are acting as a public email gateway accounts registered through disposable email addresses can be to receive emails. The “public” nature not only raises interest- easily hijacked, leading to potential information leakage and ing questions about the security of the disposable email service financial loss. By empirically analyzing email tracking, we find itself, but also presents a rare opportunity to empirically collect that third-party tracking is highly prevalent, especially in the emails sent by popular services. -

035021-F E-Online
ÉLECTRONIQUE EN LIGNE yEnc & Co Méthodes de codage des fichiers attachés Harry Baggen Bien que la plupart des utilisateurs d’Internet se contentent, par le biais de leur ordinateur, de visiter des sites au graphisme attrayant et d’envoyer/recevoir des E-mails, la Toile, ce médium englobant notre bonne vieille Terre, offre bien d’autres potentialités. Il existe ainsi des dizaines de milliers de groupes de discussion (newsgroup) qui permettent à des amateurs de tous poils d’échanger des données concernant leurs violons d’Ingres. Le problème est que l’on se trouve confronté, lors de sa première « plongée » dans ce monde, un certain nombre de méthodes de codage, telles que yEnc et uuencode, qui, au premier abord, peuvent paraître étranges. certain Outtime BBS dont le maître d’oeuvre était Stéphane Boudin, BBS qui lui a permis de faire ses pre- mières armes dans le monde des modems...). À l’époque déjà, le télé- chargement de programmes, d’images et de toutes autres sortes de fichiers faisait le bonheur de nombre d’utilisateurs de PC. De nos jours, sur Internet, cette fonc- tion a été reprise par les Groupes comme les appelle Yahoo!, l’en- semble du réseau ayant en fait été baptisé usenet (user’s network). À l’origine, usenet était une partie d’In- ternet destinée à la transmission de messages pouvant intéresser un grand nombre de personnes. Les pères spirituels de ce concept n’avaient pas pensé à l’époque que les utilisateurs futurs se serviraient de ce moyen pour la transmission de fichiers binaires (programmes, images, musique). -

Download the Index
41_067232945x_index.qxd 10/5/07 1:09 PM Page 667 Index NUMBERS 3D video, 100-101 10BaseT Ethernet NIC (Network Interface Cards), 512 64-bit processors, 14 100BaseT Ethernet NIC (Network Interface Cards), 512 A A (Address) resource record, 555 AbiWord, 171-172 ac command, 414 ac patches, 498 access control, Apache web server file systems, 536 access times, disabling, 648 Accessibility module (GNOME), 116 ACPI (Advanced Configuration and Power Interface), 61-62 active content modules, dynamic website creation, 544 Add a New Local User screen, 44 add command (CVS), 583 address books, KAddressBook, 278 Administrator Mode button (KDE Control Center), 113 Adobe Reader, 133 AFPL Ghostscript, 123 41_067232945x_index.qxd 10/5/07 1:09 PM Page 668 668 aggregators aggregators, 309 antispam tools, 325 aKregator (Kontact), 336-337 KMail, 330-331 Blam!, 337 Procmail, 326, 329-330 Bloglines, 338 action line special characters, 328 Firefox web browser, 335 recipe flags, 326 Liferea, 337 special conditions, 327 Opera web browser, 335 antivirus tools, 331-332 RSSOwl, 338 AP (Access Points), wireless networks, 260, 514 aKregator webfeeder (Kontact), 278, 336-337 Apache web server, 529 album art, downloading to multimedia dynamic websites, creating players, 192 active content modules, 544 aliases, 79 CGI programming, 542-543 bash shell, 80 SSI, 543 CNAME (Canonical Name) resource file systems record, 555 access control, 536 local aliases, email server configuration, 325 authentication, 536-538 allow directive (Apache2/httpd.conf), 536 installing Almquist shells -

Bedienungsanleitung HTC Touch 3G
Handbuch www.htc.com Bitte zuerst lesen WENN SIE DEN AKKU AUS DEM KARTON ENTNEHMEN, IST ER NICHT GELADEN. ENTFERNEN SIE NICHT DEN AKKU, WÄHREND DAS GERÄT GELADEN WIRD. DIE GARANTIE ERLISCHT, WENN SIE DAS AUSSENGEHÄUSE DES GERÄTES ÖFFNEN ODER SONSTWIE BESCHÄDIGEN. DATENSCHUTZBESCHRÄNKUNGEN Einige Länder erfordern die volle Offenlegung von aufgezeichneten Telefongesprächen und schreiben vor, dass Sie Ihren Gesprächspartner darüber informieren müssen, wenn ein Gespräch aufgezeichnet wird. Befolgen Sie immer die entsprechenden Gesetze und Bestimmungen Ihres Landes, wenn Sie die Aufnahmefunktion des PDA-Telefons einsetzen. INFORMATIONEN ZU RECHTEN ÜBER GEISTIGES EIGENTUM Copyright © 008 HTC Corporation. Alle Rechte vorbehalten. HTC, das HTC-Logo, HTC Innovation, ExtUSB, TouchFLO, HTC Touch und HTC Care sind Warenzeichen und/oder Dienstleistungszeichen der HTC Corporation. Microsoft, MS-DOS, Windows, Windows NT, Windows Server, Windows Mobile, Windows XP, Windows Vista, ActiveSync, Windows Mobile-Gerätecenter, Internet Explorer, MSN, Hotmail, Windows Live, Outlook, Excel, PowerPoint, Word, OneNote und Windows Media sind entweder eingetragene oder nicht eingetragene Warenzeichen von Microsoft Corporation in den USA und/oder anderen Ländern. Bluetooth und das Bluetooth-Logo sind Warenzeichen im Besitz von Bluetooth SIG, Inc. Java, JME und alle anderen Java-basierten Zeichen sind Warenzeichen oder eingetragene Warenzeichen von Sun Microsystems, Inc. in den USA und anderen Ländern. Copyright © 008, Adobe Systems Incorporated. Alle Rechte vorbehalten. microSD ist ein Warenzeichen von SD Card Association. Opera® Mobile von Opera Software ASA. Copyright 1995-008 Opera Software ASA. Alle Rechte vorbehalten. Google ist ein eingetragenes Warenzeichen und Google Maps ist ein Warenzeichen von Google, Inc. in den USA und anderen Ländern. YouTube ist ein Warenzeichen von Google, Inc. -

Belkasoft Evidence Center X User Reference Contents About
702 San Conrado Terrace, Unit 1 Sunnyvale CA 94085 USA and Canada: +1 650 272 0384 Europe, other regions: +48 663 247 314 Web: https://belkasoft.com Email: [email protected] Belkasoft Evidence Center X User Reference Contents About ............................................................................................................................................... 7 What is this document about? .................................................................................................... 7 Other resources .......................................................................................................................... 7 Legal notes and disclaimers ........................................................................................................ 7 Introduction .................................................................................................................................... 9 What is Belkasoft Evidence Center (Belkasoft X) and who are its users? ................................... 9 Types of tasks Belkasoft X is used for ........................................................................................ 10 Typical Belkasoft X workflow .................................................................................................... 10 Forensically sound software ..................................................................................................... 11 When Belkasoft X uses the Internet ........................................................................................ -
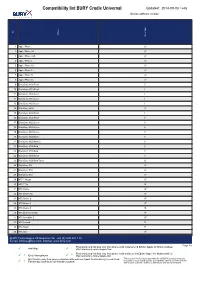
BURY Compatibility List Generator
Compatibility list BURY Cradle Universal Updated: 2014-09-03 / v48 Device software version: No Phone Set of tips 1 Apple iPhone A' 2 Apple iPhone 3G A' 3 Apple iPhone 3GS A' 4 Apple iPhone 4 A' 5 Apple iPhone 4S A' 6 Apple iPhone 5 A' 7 Apple iPhone 5c A' 8 Apple iPhone 5s A' 9 BlackBerry 8100 Pearl F 10 BlackBerry 8110 Pearl F 11 BlackBerry 8300 Curve F 12 BlackBerry 8310 Curve F 13 BlackBerry 8520 Curve F 14 BlackBerry 8800 A' 15 BlackBerry 9100 Pearl E 16 BlackBerry 9105 Pearl E 17 BlackBerry 9320 Curve E 18 BlackBerry 9360 Curve E 19 BlackBerry 9380 Curve E 20 BlackBerry 9500 Storm F 21 BlackBerry 9520 Storm2 F 22 BlackBerry 9700 Bold F 23 BlackBerry 9780 Bold F 24 BlackBerry 9800 Torch F 25 BlackBerry 9900 Bold Touch E 26 BlackBerry Q5 A' 27 BlackBerry Q10 A' 28 BlackBerry Z10 A' 29 HTC 7 Mozart A' 30 HTC 7 Pro B 31 HTC Desire A' 32 HTC Desire HD A' 33 HTC Desire S A' 34 HTC Desire X A' 35 HTC Desire Z B 36 HTC EVO 3D X515m A' 37 HTC Incredible S A' 38 HTC Legend F 39 HTC Magic F 40 HTC One A' BURY Technologies UK Enquiries Tel. +44 (0)1489 881 118 E-mail: [email protected], Internet: www.bury.com Page 1/5 Phonebook and call lists only from phone (with installed 2nd Edition Applet for Nokia mobiles) ✓ working ✓ * http://www.bury.com/en/applet2nd Phonebook and call lists only from phone (with installed 3rd Edition Applet for Nokia mobiles) ✓ 1 Only from phone ✓ ** http://www.bury.com/en/applet3rd Mail function only from phone available with installed Applet for BlackBerry (Email Read The scope of the functions described for all BURY products may vary ✓ 2 according to your mobile phone, your network service provider and the The use of some mobile phones keys could be restricted due to cradle holding mechanism. -

Emacs MIME Manual
Emacs MIME Manual by Lars Magne Ingebrigtsen This file documents the Emacs MIME interface functionality. Copyright (C) 1998, 1999, 2000, 2001, 2002, 2003 Free Software Foundation, Inc. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.1 or any later version published by the Free Software Foundation; with no Invariant Sections, with the Front-Cover texts being “A GNU Manual”, and with the Back-Cover Texts as in (a) below. A copy of the license is included in the section entitled “GNU Free Documentation License” in the Emacs manual. (a) The FSF’s Back-Cover Text is: “You have freedom to copy and modify this GNU Manual, like GNU software. Copies published by the Free Software Foundation raise funds for GNU development.” This document is part of a collection distributed under the GNU Free Documentation License. If you want to distribute this document separately from the collection, you can do so by adding a copy of the license to the document, as described in section 6 of the license. 1 Emacs MIME This manual documents the libraries used to compose and display MIME messages. This manual is directed at users who want to modify the behaviour of the MIME encod- ing/decoding process or want a more detailed picture of how the Emacs MIME library works, and people who want to write functions and commands that manipulate MIME elements. MIME is short for Multipurpose Internet Mail Extensions. This standard is documented in a number of RFCs; mainly RFC2045 (Format of Internet Message Bodies), RFC2046 (Me- dia Types), RFC2047 (Message Header Extensions for Non-ASCII Text), RFC2048 (Regis- tration Procedures), RFC2049 (Conformance Criteria and Examples). -

EMFS: Repurposing SMTP and IMAP for Data Storage and Synchronization
EMFS: Repurposing SMTP and IMAP for Data Storage and Synchronization William Woodruff william@tuffbizz.com September 20, 2018 v1.0 Abstract Cloud storage has become a massive and lucrative business, with com- panies like Apple, Microsoft, Google, and Dropbox providing hun- dreds of millions of clients with synchronized and redundant stor- age. These services often command price-to-storage ratios significantly higher than the market rate for physical storage, as well as increase the surface area for data leakage. In place of this consumer-unfriendly status quo, I propose using widely available, well standardized email protocols like SMTP and IMAP in conjunction with free email service providers to store, synchronize, and share files across discrete systems. arXiv:1602.00615v1 [cs.NI] 29 Jan 2016 1 Contents 1 Introduction 3 2 Email as a General-Purpose Storage Service 4 2.1 Usenet as a Precedent . .4 2.1.1 Protocol and Topological Similarities . .4 2.1.2 Usage Similarities . .5 2.2 Advantages over NNTP . .5 2.3 Advantages over CSPs . .6 2.3.1 Security . .6 2.3.2 Extensibility and Transparency . .6 3 Architecture 6 3.1 Filesystem Primitives . .7 3.1.1 Types . .7 3.1.1.1 Files . .7 3.1.1.2 Directories . .8 3.1.2 Operations . .9 3.1.2.1 Filesystem Creation . .9 3.1.2.2 Directory Creation . .9 3.1.2.3 Directory Deletion . 10 3.1.2.4 File Creation . 10 3.1.2.5 File Deletion . 11 3.1.2.6 Indexing . 11 4 Applying EMFS to Common ESPs 12 4.1 ESP Statistics . -

MARATHON WILD ENDURANCE M-PESA Changing Lives
SeptemberSeptember - NovemberNovember 20092009 WIN a beach holiday for two SAFARICOM MARATHON WILD ENDURANCE M-PESA changing lives THIS MONTH SeptemberSeptembetbr --N Novemberovember 2009 WIN a beach holiday for two SAFARICOM MARATHON WILD ENDURANCE Inside 2 Message from Michael M-PESA changing lives 4 What’s news? 6 Matchless marathon WIN a MANAGING EDITOR: Chris Muthama 12 Passion for youth holiday 23 EDITOR: Maryann Michuki CONTRIBUTORS: Craig Bishop, John Kabubu, for two! Kimani Kamakiru, Chebet Karago, 14 Uplifting Kenyans Candice Miranda PHOTOGRAPHY: Craig Bishop, 17 High value trees Gina Din Corporate Communications, Charlie Grieves-Cook, Alex Kamweru, 18 Camphone seduction Chebet Karago, Candice Miranda, Neil Thomas, Duncan Willetts 20 Lions of Lewa PUBLISHERS: East African Magazines Ltd, Nairobi PRINTING: Colourprint, Nairobi 23 Feeling lucky? ALL CORRESPONDENCE TO: The Option Magazine 24 Techno teasers Safaricom Limited P.O. Box 46350- 00100 Nairobi, Kenya 26 Are cellphones risky? [email protected] www.safaricom.co.ke 28 Mobile manners To advertise in The Option Magazine, contact: Helen Kiarie Tel: 020 605991/2 29 Meet Torome Tirike [email protected] 30 Dial 24/7 Techno 34 Going global The editorial content and individual opinions expressed bytes herein are solely those of the authors and do not necessarily represent those of Safaricom Ltd. Neither 35 Always in touch Safaricom nor the Publishers accept any responsibility for the content. All rights reserved. No part of this work 36 What’s hot! may be reproduced or transmitted in any form or by 24 any means, electronic or mechanical, without prior permission in writing from Safaricom. 40 Safaricom shops Ed’s letter It’s amazing how time flies: it is 10 years since the first Safaricom Marathon in Lewa. -

Dynamic Converter Administration Guide 10G Release 3 (10.1.3.3.1)
Cover Page Dynamic Converter Administration Guide 10g Release 3 (10.1.3.3.1) May 2007 Dynamic Converter Administration Guide, 10g Release 3 (10.1.3.3.1) Copyright © 2007, Oracle. All rights reserved. Contributing author: Ron van de Crommert The Programs (which include both the software and documentation) contain proprietary information; they are provided under a license agreement containing restrictions on use and disclosure and are also protected by copyright, patent, and other intellectual and industrial property laws. Reverse engineering, disassembly, or decompilation of the Programs, except to the extent required to obtain interoperability with other independently created software or as specified by law, is prohibited. The information contained in this document is subject to change without notice. If you find any problems in the documentation, please report them to us in writing. This document is not warranted to be error-free. Except as may be expressly permitted in your license agreement for these Programs, no part of these Programs may be reproduced or transmitted in any form or by any means, electronic or mechanical, for any purpose. If the Programs are delivered to the United States Government or anyone licensing or using the Programs on behalf of the United States Government, the following notice is applicable: U.S. GOVERNMENT RIGHTS Programs, software, databases, and related documentation and technical data delivered to U.S. Government customers are "commercial computer software" or "commercial technical data" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, use, duplication, disclosure, modification, and adaptation of the Programs, including documentation and technical data, shall be subject to the licensing restrictions set forth in the applicable Oracle license agreement, and, to the extent applicable, the additional rights set forth in FAR 52.227-19, Commercial Computer Software--Restricted Rights (June 1987). -

Master Thesis
MASTER THESIS TITLE: Software support for video streaming from smartphone on small airship MASTER DEGREE: Master in Science in Telecommunication Engineering & Management AUTHOR: Miguel Carretero Rodríguez SUPERVISOR: Zbynek Soban DIRECTOR: Lukas Kencl DATE: February, 9th 2009 Overview This project has been created to study and to solve two goals. The main goal has been streaming real video from a smartphone to a laptop and the second goal has been to control the airship electronics from the smartphone. To achieve the main goal of the project, firstly has been necessary realize a technologies study to select the better choice. The chosen technology has been to use of wi-fi, mainly due to the high transmission speed. Once the technology has been chosen, an ad-hoc wi-fi network has been created to be able to transmit wirelessly. After that, it has been necessary to study how to do the sending of the information. The first idea was using the User Datagram Protocol or Transport Control Protocol, at the beginning it seemed a good choice, because of was possible to achieve a communication between the smartphone and the laptop and a camera in record mode application was created. However, when the real video was to be sent to the laptop, it was not possible because it was not way to open the file while it was been created and there was not any temporal file. Then, another possibility had to be studied and it was the use of streamers. The Live555 Streaming Media is a set of C++ libraries which allows to stream real time from a device to a computer. -

Acer Airis Alcatel Alltel Amoi Amoisonic Anextek Apple Arima
Acer 1 n10 1 1 n311 1 1 S100 Liquid 1 1 X960 1 Airis 1 T480 1 Alcatel 1 ELLE No 1 1 1 ELLE No 3 1 1 One Touch 355 1 1 One Touch 556 1 1 One Touch 557 1 1 One Touch 565 1 1 One Touch 708 1 1 One Touch 735i 1 1 One Touch 756 1 1 One Touch 757 1 1 One Touch 800 1 1 One Touch C551 1 1 One Touch C552 1 1 One Touch C635 1 1 One Touch C651 1 1 One Touch C652 1 1 One Touch C750 1 1 One Touch S853 1 1 One Touch V670 1 Alltel 1 PPC-6800 1 Amoi 1 A310 1 1 D85 1 1 D89 1 1 E72 1 1 F8 1 1 F90 1 1 H9 1 1 M636 1 1 N810 1 1 WP-S1 Skypephone 1 Amoisonic 1 9201 1 AnexTek 1 SP230 1 Apple 1 iPad 1 1 iPhone 1 1 iPod Touch 1 Arima 1 2850 1 Asus 1 1210 1 1 Galaxy II 1 1 Galaxy Mini 1 1 J100 1 1 J101 1 1 J102 1 1 M303 1 1 M530w 1 1 M930 1 1 P320 1 1 P505 1 1 P525 1 1 P526 1 1 P527 1 1 P550 1 1 P552 1 1 P735 1 1 P750 1 1 V80 1 AT&T 1 8900 Tilt 1 1 8925 Tilt 1 Audiovox 1 CDM-8450 1 1 CDM-8450SP 1 1 CDM-8455 1 1 CDM-8615 1 1 CDM-8900 1 1 CDM-8910 1 1 CDM-8912 1 1 CDM-8915 1 1 CDM-8920 1 1 CDM-8930 1 1 PM-8912 1 1 PM-8920 1 1 PPC-6600 / PPC-6601 1 1 PPC-6700 1 1 SMT-5600 1 1 VI600 1 BenQ 1 A500 1 1 A5001 1 1 A520 1 1 CL71 1 1 E72 1 1 E81 1 1 M315 1 1 M350 1 1 M580A 1 1 Morpheus 1 1 P30 1 1 P50 1 1 S660C 1 1 S668C 1 1 S670C 1 1 S680C 1 1 S700 1 1 S7001 1 1 S82 1 1 S830C 1 1 U700 1 1 Z2 1 BenQ-Siemens 1 C81 1 1 C81F 1 1 E71 1 1 EF51 1 1 EF81 1 1 EF91 1 1 EL71 1 1 M81 1 1 P51 1 1 S68 1 1 S80 1 1 S81 1 Bird 1 D660 1 1 E810 1 1 S689 1 1 SC01 1 1 SC24 1 1 V007 1 BlackBerry 1 7100g 1 1 7100i 1 1 7100r 1 1 7100t 1 1 7100v 1 1 7100x 1 1 7105t 1 1 7130c 1 1 7130e 1 1 7130g