Genome-Wide Genetic Structure and Differentially Selected Regions
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Genome-Wide Association Study of Bisphosphonate-Associated
Calcifed Tissue International (2019) 105:51–67 https://doi.org/10.1007/s00223-019-00546-9 ORIGINAL RESEARCH A Genome‑Wide Association Study of Bisphosphonate‑Associated Atypical Femoral Fracture Mohammad Kharazmi1 · Karl Michaëlsson1 · Jörg Schilcher2 · Niclas Eriksson3,4 · Håkan Melhus3 · Mia Wadelius3 · Pär Hallberg3 Received: 8 January 2019 / Accepted: 8 April 2019 / Published online: 20 April 2019 © The Author(s) 2019 Abstract Atypical femoral fracture is a well-documented adverse reaction to bisphosphonates. It is strongly related to duration of bisphosphonate use, and the risk declines rapidly after drug withdrawal. The mechanism behind bisphosphonate-associated atypical femoral fracture is unclear, but a genetic predisposition has been suggested. With the aim to identify common genetic variants that could be used for preemptive genetic testing, we performed a genome-wide association study. Cases were recruited mainly through reports of adverse drug reactions sent to the Swedish Medical Products Agency on a nation- wide basis. We compared atypical femoral fracture cases (n = 51) with population-based controls (n = 4891), and to reduce the possibility of confounding by indication, we also compared with bisphosphonate-treated controls without a current diagnosis of cancer (n = 324). The total number of single-nucleotide polymorphisms after imputation was 7,585,874. A genome-wide signifcance threshold of p < 5 × 10−8 was used to correct for multiple testing. In addition, we performed candidate gene analyses for a panel of 29 genes previously implicated in atypical femoral fractures (signifcance threshold of p < 5.7 × 10−6). Compared with population controls, bisphosphonate-associated atypical femoral fracture was associated with four isolated, uncommon single-nucleotide polymorphisms. -

Diseasespecific and Inflammationindependent Stromal
Full Length Arthritis & Rheumatism DOI 10.1002/art.37704 Disease-specific and inflammation-independent stromal alterations in spondyloarthritis synovitis Nataliya Yeremenko1,2, Troy Noordenbos1,2, Tineke Cantaert1,3, Melissa van Tok1,2, Marleen van de Sande1, Juan D. Cañete4, Paul P. Tak1,5*, Dominique Baeten1,2 1Department of Clinical Immunology and Rheumatology and 2Department of Experimental Immunology, Academic Medical Center/University of Amsterdam, the Netherlands. 3Department of Immunobiology, Yale University School of Medicine, New Haven, CT, USA. 4Department of Rheumatology, Hospital Clinic de Barcelona and IDIBAPS, Spain. 5Arthrogen B.V., Amsterdam, the Netherlands. *Currently also: GlaxoSmithKline, Stevenage, U.K. Corresponding author: Dominique Baeten, MD, PhD, Department of Clinical Immunology and Rheumatology, F4-105, Academic Medical Center/University of Amsterdam, Meibergdreef 9, 1105 AZ Amsterdam, The Netherlands. E-mail: [email protected] This article has been accepted for publication and undergone full peer review but has not been through the copyediting, typesetting, pagination and proofreading process which may lead to differences between this version and the Version of Record. Please cite this article as an ‘Accepted Article’, doi: 10.1002/art.37704 © 2012 American College of Rheumatology Received: Apr 11, 2012; Revised: Jul 25, 2012; Accepted: Sep 06, 2012 Arthritis & Rheumatism Page 2 of 36 Abstract Objective: The molecular processes driving the distinct patterns of synovial inflammation and tissue remodelling in spondyloarthritis (SpA) versus rheumatoid arthritis (RA) remain largely unknown. Therefore, we aimed to identify novel and unsuspected disease- specific pathways in SpA by a systematic and unbiased synovial gene expression analysis. Methods: Differentially expressed genes were identified by pan-genomic microarray and confirmed by quantitative PCR and immunohistochemistry using synovial tissue biopsies of SpA (n=63), RA (n=28) and gout (n=9) patients. -

The Proximal Signaling Network of the BCR-ABL1 Oncogene Shows a Modular Organization
Oncogene (2010) 29, 5895–5910 & 2010 Macmillan Publishers Limited All rights reserved 0950-9232/10 www.nature.com/onc ORIGINAL ARTICLE The proximal signaling network of the BCR-ABL1 oncogene shows a modular organization B Titz, T Low, E Komisopoulou, SS Chen, L Rubbi and TG Graeber Crump Institute for Molecular Imaging, Institute for Molecular Medicine, Jonsson Comprehensive Cancer Center, California NanoSystems Institute, Department of Molecular and Medical Pharmacology, University of California, Los Angeles, CA, USA BCR-ABL1 is a fusion tyrosine kinase, which causes signaling effects of BCR-ABL1 toward leukemic multiple types of leukemia. We used an integrated transformation. proteomic approach that includes label-free quantitative Oncogene (2010) 29, 5895–5910; doi:10.1038/onc.2010.331; protein complex and phosphorylation profiling by mass published online 9 August 2010 spectrometry to systematically characterize the proximal signaling network of this oncogenic kinase. The proximal Keywords: adaptor protein; BCR-ABL1; phospho- BCR-ABL1 signaling network shows a modular and complex; quantitative mass spectrometry; signaling layered organization with an inner core of three leukemia network; systems biology transformation-relevant adaptor protein complexes (Grb2/Gab2/Shc1 complex, CrkI complex and Dok1/ Dok2 complex). We introduced an ‘interaction direction- ality’ analysis, which annotates static protein networks Introduction with information on the directionality of phosphorylation- dependent interactions. In this analysis, the observed BCR-ABL1 is a constitutively active oncogenic fusion network structure was consistent with a step-wise kinase that arises through a chromosomal translocation phosphorylation-dependent assembly of the Grb2/Gab2/ and causes multiple types of leukemia. It is found in Shc1 and the Dok1/Dok2 complexes on the BCR-ABL1 many cases (B25%) of adult acute lymphoblastic core. -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -

Molecular Cytogenetics Biomed Central
Molecular Cytogenetics BioMed Central Research Open Access FISH mapping of Philadelphia negative BCR/ABL1 positive CML Anna Virgili1, Diana Brazma1, Alistair G Reid2, Julie Howard-Reeves1, Mikel Valgañón1, Anastasios Chanalaris1, Valeria AS De Melo2, David Marin2, Jane F Apperley2, Colin Grace1 and Ellie P Nacheva*1 Address: 1Molecular Cytogenetics, Academic Haematology, Royal Free and UCL Medical School, Rowland Hill Street, London, NW3 2PF, UK and 2Imperial College, Faculty Medicine, Hammersmith Hospital, Dept of Haematology, Du Cane Road, London, W12 ONN, UK Email: Anna Virgili - [email protected]; Diana Brazma - [email protected]; Alistair G Reid - [email protected]; Julie Howard-Reeves - [email protected]; Mikel Valgañón - [email protected]; Anastasios Chanalaris - [email protected]; Valeria AS De Melo - [email protected]; David Marin - [email protected]; Jane F Apperley - [email protected]; Colin Grace - [email protected]; Ellie P Nacheva* - [email protected] * Corresponding author Published: 18 July 2008 Received: 21 May 2008 Accepted: 18 July 2008 Molecular Cytogenetics 2008, 1:14 doi:10.1186/1755-8166-1-14 This article is available from: http://www.molecularcytogenetics.org/content/1/1/14 © 2008 Virgili et al; licensee BioMed Central Ltd. This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. Abstract Background: Chronic myeloid leukaemia (CML) is a haematopoietic stem cell disorder, almost always characterized by the presence of the Philadelphia chromosome (Ph), usually due to t(9;22)(q34;q11) or its variants. -
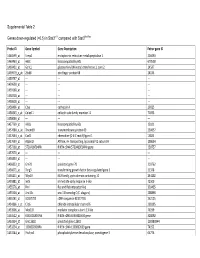
0.5) in Stat3∆/∆ Compared with Stat3flox/Flox
Supplemental Table 2 Genes down-regulated (<0.5) in Stat3∆/∆ compared with Stat3flox/flox Probe ID Gene Symbol Gene Description Entrez gene ID 1460599_at Ermp1 endoplasmic reticulum metallopeptidase 1 226090 1460463_at H60c histocompatibility 60c 670558 1460431_at Gcnt1 glucosaminyl (N-acetyl) transferase 1, core 2 14537 1459979_x_at Zfp68 zinc finger protein 68 24135 1459747_at --- --- --- 1459608_at --- --- --- 1459168_at --- --- --- 1458718_at --- --- --- 1458618_at --- --- --- 1458466_at Ctsa cathepsin A 19025 1458345_s_at Colec11 collectin sub-family member 11 71693 1458046_at --- --- --- 1457769_at H60a histocompatibility 60a 15101 1457680_a_at Tmem69 transmembrane protein 69 230657 1457644_s_at Cxcl1 chemokine (C-X-C motif) ligand 1 14825 1457639_at Atp6v1h ATPase, H+ transporting, lysosomal V1 subunit H 108664 1457260_at 5730409E04Rik RIKEN cDNA 5730409E04Rik gene 230757 1457070_at --- --- --- 1456893_at --- --- --- 1456823_at Gm70 predicted gene 70 210762 1456671_at Tbrg3 transforming growth factor beta regulated gene 3 21378 1456211_at Nlrp10 NLR family, pyrin domain containing 10 244202 1455881_at Ier5l immediate early response 5-like 72500 1455576_at Rinl Ras and Rab interactor-like 320435 1455304_at Unc13c unc-13 homolog C (C. elegans) 208898 1455241_at BC037703 cDNA sequence BC037703 242125 1454866_s_at Clic6 chloride intracellular channel 6 209195 1453906_at Med13l mediator complex subunit 13-like 76199 1453522_at 6530401N04Rik RIKEN cDNA 6530401N04 gene 328092 1453354_at Gm11602 predicted gene 11602 100380944 1453234_at -

Taf7l Cooperates with Trf2 to Regulate Spermiogenesis
Taf7l cooperates with Trf2 to regulate spermiogenesis Haiying Zhoua,b, Ivan Grubisicb,c, Ke Zhengd,e, Ying Heb, P. Jeremy Wangd, Tommy Kaplanf, and Robert Tjiana,b,1 aHoward Hughes Medical Institute and bDepartment of Molecular and Cell Biology, Li Ka Shing Center for Biomedical and Health Sciences, California Institute for Regenerative Medicine Center of Excellence, University of California, Berkeley, CA 94720; cUniversity of California Berkeley–University of California San Francisco Graduate Program in Bioengineering, University of California, Berkeley, CA 94720; dDepartment of Animal Biology, University of Pennsylvania School of Veterinary Medicine, Philadelphia, PA 19104; eState Key Laboratory of Reproductive Medicine, Nanjing Medical University, Nanjing 210029, People’s Republic of China; and fSchool of Computer Science and Engineering, The Hebrew University of Jerusalem, Jerusalem 91904, Israel Contributed by Robert Tjian, September 11, 2013 (sent for review August 20, 2013) TATA-binding protein (TBP)-associated factor 7l (Taf7l; a paralogue (Taf4b; a homolog of Taf4) (9), TBP-related factor 2 (Trf2) (10, of Taf7) and TBP-related factor 2 (Trf2) are components of the core 11), and Taf7l (12, 13). For example, mice bearing mutant or promoter complex required for gene/tissue-specific transcription deficient CREM showed decreased postmeiotic gene expression of protein-coding genes by RNA polymerase II. Previous studies and defective spermiogenesis (14). Mice deficient in Taf4b, reported that Taf7l knockout (KO) mice exhibit structurally abnor- a testis-specific homolog of Taf4, are initially normal but undergo mal sperm, reduced sperm count, weakened motility, and compro- progressive germ-cell loss and become infertile by 3 mo of age −/Y mised fertility. -

Long, Noncoding RNA Dysregulation in Glioblastoma
cancers Review Long, Noncoding RNA Dysregulation in Glioblastoma Patrick A. DeSouza 1,2 , Xuan Qu 1, Hao Chen 1,3, Bhuvic Patel 1 , Christopher A. Maher 2,4,5,6 and Albert H. Kim 1,6,* 1 Department of Neurological Surgery, Washington University School of Medicine in St. Louis, St. Louis, MO 63110, USA; [email protected] (P.A.D.); [email protected] (X.Q.); [email protected] (H.C.); [email protected] (B.P.) 2 Department of Internal Medicine, Washington University School of Medicine in St. Louis, St. Louis, MO 63110, USA; [email protected] 3 Department of Neuroscience, Washington University School of Medicine in St. Louis, St. Louis, MO 63110, USA 4 Department of Biomedical Engineering, Washington University School of Medicine in St. Louis, St. Louis, MO 63110, USA 5 McDonnell Genome Institute, Washington University School of Medicine in St. Louis, St. Louis, MO 63110, USA 6 Siteman Cancer Center, Washington University School of Medicine in St. Louis, St. Louis, MO 63110, USA * Correspondence: [email protected] Simple Summary: Developing effective therapies for glioblastoma (GBM), the most common primary brain cancer, remains challenging due to the heterogeneity within tumors and therapeutic resistance that drives recurrence. Noncoding RNAs are transcribed from a large proportion of the genome and remain largely unexplored in their contribution to the evolution of GBM tumors. Here, we will review the general mechanisms of long, noncoding RNAs and the current knowledge of how these impact heterogeneity and therapeutic resistance in GBM. A better understanding of the molecular drivers required for these aggressive tumors is necessary to improve the management and outcomes Citation: DeSouza, P.A.; Qu, X.; of this challenging disease. -

Building the Vertebrate Codex Using the Gene Breaking Protein Trap Library
Genetics, Development and Cell Biology Publications Genetics, Development and Cell Biology 2020 Building the vertebrate codex using the gene breaking protein trap library Noriko Ichino Mayo Clinic Gaurav K. Varshney National Institutes of Health Ying Wang Iowa State University Hsin-kai Liao Iowa State University Maura McGrail Iowa State University, [email protected] See next page for additional authors Follow this and additional works at: https://lib.dr.iastate.edu/gdcb_las_pubs Part of the Molecular Genetics Commons, and the Research Methods in Life Sciences Commons The complete bibliographic information for this item can be found at https://lib.dr.iastate.edu/ gdcb_las_pubs/261. For information on how to cite this item, please visit http://lib.dr.iastate.edu/howtocite.html. This Article is brought to you for free and open access by the Genetics, Development and Cell Biology at Iowa State University Digital Repository. It has been accepted for inclusion in Genetics, Development and Cell Biology Publications by an authorized administrator of Iowa State University Digital Repository. For more information, please contact [email protected]. Building the vertebrate codex using the gene breaking protein trap library Abstract One key bottleneck in understanding the human genome is the relative under-characterization of 90% of protein coding regions. We report a collection of 1200 transgenic zebrafish strains made with the gene- break transposon (GBT) protein trap to simultaneously report and reversibly knockdown the tagged genes. Protein trap-associated mRFP expression shows previously undocumented expression of 35% and 90% of cloned genes at 2 and 4 days post-fertilization, respectively. Further, investigated alleles regularly show 99% gene-specific mRNA knockdown. -

Genome-Wide Copy Number Variant Analysis For
An et al. BMC Medical Genomics (2016) 9:2 DOI 10.1186/s12920-015-0163-4 RESEARCH ARTICLE Open Access Genome-wide copy number variant analysis for congenital ventricular septal defects in Chinese Han population Yu An1,2,4, Wenyuan Duan3, Guoying Huang4, Xiaoli Chen5,LiLi5, Chenxia Nie6, Jia Hou4, Yonghao Gui4, Yiming Wu1, Feng Zhang2, Yiping Shen7, Bailin Wu1,4,7* and Hongyan Wang8* Abstract Background: Ventricular septal defects (VSDs) constitute the most prevalent congenital heart disease (CHD), occurs either in isolation (isolated VSD) or in combination with other cardiac defects (complex VSD). Copy number variation (CNV) has been highlighted as a possible contributing factor to the etiology of many congenital diseases. However, little is known concerning the involvement of CNVs in either isolated or complex VSDs. Methods: We analyzed 154 unrelated Chinese individuals with VSD by chromosomal microarray analysis. The subjects were recruited from four hospitals across China. Each case underwent clinical assessment to define the type of VSD, either isolated or complex VSD. CNVs detected were categorized into syndrom related CNVs, recurrent CNVs and rare CNVs. Genes encompassed by the CNVs were analyzed using enrichment and pathway analysis. Results: Among 154 probands, we identified 29 rare CNVs in 26 VSD patients (16.9 %, 26/154) and 8 syndrome-related CNVs in 8 VSD patients (5.2 %, 8/154). 12 of the detected 29 rare CNVs (41.3 %) were recurrently reported in DECIPHER or ISCA database as associated with either VSD or general heart disease. Fifteen genes (5 %, 15/285) within CNVs were associated with a broad spectrum of complicated CHD. -

Expression of Odontogenic Ameloblast-Associated Protein (ODAM) in Dental and Other Epithelial Neoplasms
Expression of Odontogenic Ameloblast-Associated Protein (ODAM) in Dental and Other Epithelial Neoplasms Daniel P Kestler, James S Foster, Sallie D Macy, Charles L Murphy, Deborah T Weiss, and Alan Solomon Human Immunology and Cancer Program, Department of Medicine, University of Tennessee Graduate School of Medicine, Knoxville, Tennessee, United States of America We previously have communicated our discovery that the amyloid associated with calcifying epithelial odontogenic tumors is composed of N-terminal fragments of the structurally novel odontogenic ameloblast-associated protein designated ODAM. Sub- sequently, it was shown by other investigators that ODAM is expressed in rodent enamel organ and is likely involved in dental de- velopment. We now report that this molecule also is found in certain human tissues, principally the salivary gland and trachea, as evidenced by RNA array analysis and immunohistochemistry-utilizing antibodies prepared against synthetic ODAM-related peptides and recombinant protein. Notably, these reagents immunostained normal and malignant ameloblasts and other types of human neoplastic cells, including those of gastric, lung, and breast origin where the presence in the latter was confirmed by in situ hybridization using gene-specific molecular probes. Moreover, significant titers of anti-ODAM IgG antibodies were detected in the sera of patients with these malignancies. Our studies have provided the first evidence in humans for the cellular expression of ODAM in normal and diseased states. Based on our findings, we posit that ODAM is a developmental antigen that has an es- sential role in tooth maturation and in the pathogenesis of certain odontogenic and other epithelial neoplasms; further, we sug- gest that ODAM may serve as a novel prognostic biomarker, as well as a potential diagnostic and therapeutic target for patients with breast and other epithelial forms of cancer. -

DYRK1A Protein Kinase Promotes Quiescence and Senescence Through DREAM Complex Assembly
Downloaded from genesdev.cshlp.org on September 28, 2021 - Published by Cold Spring Harbor Laboratory Press DYRK1A protein kinase promotes quiescence and senescence through DREAM complex assembly Larisa Litovchick,1,2 Laurence A. Florens,3 Selene K. Swanson,3 Michael P. Washburn,3,4 and James A. DeCaprio1,2,5,6 1Department of Medical Oncology, Dana-Farber Cancer Institute, Boston, Massachusetts 02215, USA; 2Department of Medicine, Brigham and Women’s Hospital, Harvard Medical School, Boston, Massachusetts 02115, USA; 3Stowers Institute for Biomedical Research, Kansas City, Missouri 64110, USA; 4Department of Pathology and Laboratory Medicine, The University of Kansas Medical Center, Kansas City, Kansas 66160, USA; 5Belfer Institute for Applied Cancer Science, Dana-Farber Cancer Institute, Boston, Massachusetts 02215, USA In the absence of growth signals, cells exit the cell cycle and enter into G0 or quiescence. Alternatively, cells enter senescence in response to inappropriate growth signals such as oncogene expression. The molecular mechanisms required for cell cycle exit into quiescence or senescence are poorly understood. The DREAM (DP, RB [retinoblastoma] , E2F, and MuvB) complex represses cell cycle-dependent genes during quiescence. DREAM contains p130, E2F4, DP1, and a stable core complex of five MuvB-like proteins: LIN9, LIN37, LIN52, LIN54, and RBBP4. In mammalian cells, the MuvB core dissociates from p130 upon entry into the cell cycle and binds to BMYB during S phase to activate the transcription of genes expressed late in the cell cycle. We used mass spectroscopic analysis to identify phosphorylation sites that regulate the switch of the MuvB core from BMYB to DREAM. Here we report that DYRK1A can specifically phosphorylate LIN52 on serine residue 28, and that this phosphorylation is required for DREAM assembly.