Intel's P6 Uses Decoupled Superscalar Design: 2/16/95
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Intel® Architecture Instruction Set Extensions and Future Features Programming Reference
Intel® Architecture Instruction Set Extensions and Future Features Programming Reference 319433-037 MAY 2019 Intel technologies features and benefits depend on system configuration and may require enabled hardware, software, or service activation. Learn more at intel.com, or from the OEM or retailer. No computer system can be absolutely secure. Intel does not assume any liability for lost or stolen data or systems or any damages resulting from such losses. You may not use or facilitate the use of this document in connection with any infringement or other legal analysis concerning Intel products described herein. You agree to grant Intel a non-exclusive, royalty-free license to any patent claim thereafter drafted which includes subject matter disclosed herein. No license (express or implied, by estoppel or otherwise) to any intellectual property rights is granted by this document. The products described may contain design defects or errors known as errata which may cause the product to deviate from published specifica- tions. Current characterized errata are available on request. This document contains information on products, services and/or processes in development. All information provided here is subject to change without notice. Intel does not guarantee the availability of these interfaces in any future product. Contact your Intel representative to obtain the latest Intel product specifications and roadmaps. Copies of documents which have an order number and are referenced in this document, or other Intel literature, may be obtained by calling 1- 800-548-4725, or by visiting http://www.intel.com/design/literature.htm. Intel, the Intel logo, Intel Deep Learning Boost, Intel DL Boost, Intel Atom, Intel Core, Intel SpeedStep, MMX, Pentium, VTune, and Xeon are trademarks of Intel Corporation in the U.S. -

A Superscalar Out-Of-Order X86 Soft Processor for FPGA
A Superscalar Out-of-Order x86 Soft Processor for FPGA Henry Wong University of Toronto, Intel [email protected] June 5, 2019 Stanford University EE380 1 Hi! ● CPU architect, Intel Hillsboro ● Ph.D., University of Toronto ● Today: x86 OoO processor for FPGA (Ph.D. work) – Motivation – High-level design and results – Microarchitecture details and some circuits 2 FPGA: Field-Programmable Gate Array ● Is a digital circuit (logic gates and wires) ● Is field-programmable (at power-on, not in the fab) ● Pre-fab everything you’ll ever need – 20x area, 20x delay cost – Circuit building blocks are somewhat bigger than logic gates 6-LUT6-LUT 6-LUT6-LUT 3 6-LUT 6-LUT FPGA: Field-Programmable Gate Array ● Is a digital circuit (logic gates and wires) ● Is field-programmable (at power-on, not in the fab) ● Pre-fab everything you’ll ever need – 20x area, 20x delay cost – Circuit building blocks are somewhat bigger than logic gates 6-LUT 6-LUT 6-LUT 6-LUT 4 6-LUT 6-LUT FPGA Soft Processors ● FPGA systems often have software components – Often running on a soft processor ● Need more performance? – Parallel code and hardware accelerators need effort – Less effort if soft processors got faster 5 FPGA Soft Processors ● FPGA systems often have software components – Often running on a soft processor ● Need more performance? – Parallel code and hardware accelerators need effort – Less effort if soft processors got faster 6 FPGA Soft Processors ● FPGA systems often have software components – Often running on a soft processor ● Need more performance? – Parallel -

The Microarchitecture of the Pentium 4 Processor
The Microarchitecture of the Pentium 4 Processor Glenn Hinton, Desktop Platforms Group, Intel Corp. Dave Sager, Desktop Platforms Group, Intel Corp. Mike Upton, Desktop Platforms Group, Intel Corp. Darrell Boggs, Desktop Platforms Group, Intel Corp. Doug Carmean, Desktop Platforms Group, Intel Corp. Alan Kyker, Desktop Platforms Group, Intel Corp. Patrice Roussel, Desktop Platforms Group, Intel Corp. Index words: Pentium® 4 processor, NetBurst™ microarchitecture, Trace Cache, double-pumped ALU, deep pipelining provides an in-depth examination of the features and ABSTRACT functions of the Intel NetBurst microarchitecture. This paper describes the Intel® NetBurst™ ® The Pentium 4 processor is designed to deliver microarchitecture of Intel’s new flagship Pentium 4 performance across applications where end users can truly processor. This microarchitecture is the basis of a new appreciate and experience its performance. For example, family of processors from Intel starting with the Pentium it allows a much better user experience in areas such as 4 processor. The Pentium 4 processor provides a Internet audio and streaming video, image processing, substantial performance gain for many key application video content creation, speech recognition, 3D areas where the end user can truly appreciate the applications and games, multi-media, and multi-tasking difference. user environments. The Pentium 4 processor enables real- In this paper we describe the main features and functions time MPEG2 video encoding and near real-time MPEG4 of the NetBurst microarchitecture. We present the front- encoding, allowing efficient video editing and video end of the machine, including its new form of instruction conferencing. It delivers world-class performance on 3D cache called the Execution Trace Cache. -

P6 Underscores Intel's Lead: 2/16/95
MICROPROCESSOR REPORT MICROPROCESSOR REPORT THE INSIDERS’ GUIDE TO MICROPROCESSOR HARDWARE VOLUME 9 NUMBER 2 FEBRUARY 16, 1995 P6 Underscores Intel’s Lead Sets New x86 Performance Standard, Thrusts into Server Market by Linley Gwennap Accelerating the Generational Pace While its competitors struggle to complete their The P6 is the first fruit of Intel’s effort to double its Pentium-class chips, Intel is well on the way to deliver- pace of processor generations. In the past, new x86 pro- ing its next-generation P6 processor. Looking under the cessor cores have rolled out every four years or so from hood (see page 9), we see that the microarchitecture of what was essentially a single design team at Intel’s main the P6 is not that different from the design of AMD’s K5 facility in Santa Clara (California). The P6 is the first or even NexGen’s 586. From the user’s perspective, x86 processor core from the company’s Hillsboro (Ore- though, the difference is clear: the first P6 should out- gon) team, which had previously focused on i960 chips. perform its competitors by about 50% on typical applica- The P6 project began in late 1991, several months before tions, based on initial performance estimates. the first tape out of the Pentium processor. Intel estimates that the P6 will deliver 200 SPEC- The decision to start a second x86 design center int92 at 133 MHz, the target frequency of the initial im- shows excellent foresight. Without the P6, Intel’s high plementation, although it has not yet announced any end throughout 1996 would have been limited to 150- specific P6 products. -

Multiprocessing Contents
Multiprocessing Contents 1 Multiprocessing 1 1.1 Pre-history .............................................. 1 1.2 Key topics ............................................... 1 1.2.1 Processor symmetry ...................................... 1 1.2.2 Instruction and data streams ................................. 1 1.2.3 Processor coupling ...................................... 2 1.2.4 Multiprocessor Communication Architecture ......................... 2 1.3 Flynn’s taxonomy ........................................... 2 1.3.1 SISD multiprocessing ..................................... 2 1.3.2 SIMD multiprocessing .................................... 2 1.3.3 MISD multiprocessing .................................... 3 1.3.4 MIMD multiprocessing .................................... 3 1.4 See also ................................................ 3 1.5 References ............................................... 3 2 Computer multitasking 5 2.1 Multiprogramming .......................................... 5 2.2 Cooperative multitasking ....................................... 6 2.3 Preemptive multitasking ....................................... 6 2.4 Real time ............................................... 7 2.5 Multithreading ............................................ 7 2.6 Memory protection .......................................... 7 2.7 Memory swapping .......................................... 7 2.8 Programming ............................................. 7 2.9 See also ................................................ 8 2.10 References ............................................. -

2Nd Generation Intel® Core™ Processor Family Mobile with ECC
2nd Generation Intel® Core™ Processor Family Mobile with ECC Datasheet Addendum May 2012 Revision 002 Document Number: 324855-002 INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROPERTY RIGHTS IS GRANTED BY THIS DOCUMENT. EXCEPT AS PROVIDED IN INTEL'S TERMS AND CONDITIONS OF SALE FOR SUCH PRODUCTS, INTEL ASSUMES NO LIABILITY WHATSOEVER AND INTEL DISCLAIMS ANY EXPRESS OR IMPLIED WARRANTY, RELATING TO SALE AND/OR USE OF INTEL PRODUCTS INCLUDING LIABILITY OR WARRANTIES RELATING TO FITNESS FOR A PARTICULAR PURPOSE, MERCHANTABILITY, OR INFRINGEMENT OF ANY PATENT, COPYRIGHT OR OTHER INTELLECTUAL PROPERTY RIGHT. UNLESS OTHERWISE AGREED IN WRITING BY INTEL, THE INTEL PRODUCTS ARE NOT DESIGNED NOR INTENDED FOR ANY APPLICATION IN WHICH THE FAILURE OF THE INTEL PRODUCT COULD CREATE A SITUATION WHERE PERSONAL INJURY OR DEATH MAY OCCUR. A "Mission Critical Application" is any application in which failure of the Intel Product could result, directly or indirectly, in personal injury or death. SHOULD YOU PURCHASE OR USE INTEL'S PRODUCTS FOR ANY SUCH MISSION CRITICAL APPLICATION, YOU SHALL INDEMNIFY AND HOLD INTEL AND ITS SUBSIDIARIES, SUBCONTRACTORS AND AFFILIATES, AND THE DIRECTORS, OFFICERS, AND EMPLOYEES OF EACH, HARMLESS AGAINST ALL CLAIMS COSTS, DAMAGES, AND EXPENSES AND REASONABLE ATTORNEYS' FEES ARISING OUT OF, DIRECTLY OR INDIRECTLY, ANY CLAIM OF PRODUCT LIABILITY, PERSONAL INJURY, OR DEATH ARISING IN ANY WAY OUT OF SUCH MISSION CRITICAL APPLICATION, WHETHER OR NOT INTEL OR ITS SUBCONTRACTOR WAS NEGLIGENT IN THE DESIGN, MANUFACTURE, OR WARNING OF THE INTEL PRODUCT OR ANY OF ITS PARTS. -
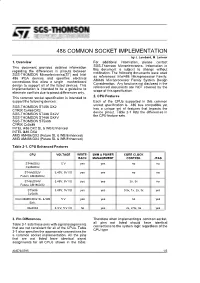
486 COMMON SOCKET IMPLEMENTATION by J
486 COMMON SOCKET IMPLEMENTATION by J. Lombard, M. Lerman 1. Overview For additional information, please contact This document provides detailed information SGS-Thomson Microelectronics. Information in this document is subject to change without regarding the differences in pinouts between notification. The following documents were used SGS-THOMSON Microelectronics(ST) and Intel as references: Intel486 Microprocessor Family, 486 PGA devices and specifies electrical connections that allow a single motherboard AM486 Microprocessor Family System Design Consideration. Any functions not disclosed in the design to support all of the listed devices. This referenced documents are NOT covered by the implementation is intended to be a guideline to scope of this specification. eliminate conflicts due to pinout differences only. 2. CPU Features This common socket specification is intended to support the following devices: Each of the CPUs supported in this common socket specification is 486 bus compatible yet SGS-THOMSON ST486 DX2 CYRIX Cx486 DX2 has a unique set of features that impacts the device pinout. Table 2-1 lists the differences in SGS-THOMSON ST486 DX2V the CPU feature sets. SGS-THOMSON ST486 DX4V SGS-THOMSON ST5x86 CYRIX Cx5x86 INTEL i486 DX2 SL & WB Enhanced INTEL i486 DX4 AMD AM486 DX2 (Future SL & WB Enhanced) AMD AM486 DX4 (Future SL & WB Enhanced) Table 2-1. CPU Enhanced Features CPU VOLTAGE WRITE- SMM & POWER CORE CLOCK BACK MANAGEMENT CONTROL JTAG ST486DX2 5 V yes yes no no Cx486DX2 ST486DX2V 3.45V, 5V I/O yes yes no no Future AM486DX2 ST486DX4V 3.45V, 5V I/O yes yes 2x, 3x no Future AM486DX2 ST5x86 3.45V, 5V I/O yes yes 0.5x, 1x, 2x, 3x yes Cx5x86 Intel i486DX/DX2 SL & WB 5 V yes yes no yes Enh. -

MICROPROCESSOR REPORT the INSIDERS’ GUIDE to MICROPROCESSOR HARDWARE Slot Vs
VOLUME 12, NUMBER 1 JANUARY 26, 1998 MICROPROCESSOR REPORT THE INSIDERS’ GUIDE TO MICROPROCESSOR HARDWARE Slot vs. Socket Battle Heats Up Intel Prepares for Transition as Competitors Boost Socket 7 A A look Look by Michael Slater ship as many parts as they hoped, especially at the highest backBack clock speeds where profits are much greater. The past year has brought a great deal The shift to 0.25-micron technology will be central to of change to the x86 microprocessor 1998’s CPU developments. Intel began shipping 0.25-micron A market, with Intel, AMD, and Cyrix processors in 3Q97; AMD followed late in 1997, IDT plans to LookA look replacing virtually their entire product join in by mid-98, and Cyrix expects to catch up in 3Q98. Ahead ahead lines with new devices. But despite high The more advanced process technology will cut power con- hopes, AMD and Cyrix struggled in vain for profits. The sumption, allowing sixth-generation CPUs to be used in financial contrast is stark: in 1997, Intel earned a record notebook systems. The smaller die sizes will enable higher $6.9 billion in net profit, while AMD lost $21 million for the production volumes and make it possible to integrate an L2 year and Cyrix lost $6 million in the six months before it was cache on the CPU chip. acquired by National. New entrant IDT added another com- The processors from Intel’s challengers have lagged in petitor to the mix but hasn’t shipped enough products to floating-point and MMX performance, which the vendors become a significant force. -

Extensions to Instruction Sets
Extensions to Instruction Sets Ricardo Manuel Meira Ferrão Luis Departamento de Informática, Universidade do Minho 4710 - 057 Braga, Portugal [email protected] Abstract. This communication analyses extensions to instruction sets in general purpose processors, together with their evolution and significant innovation. It begins with an overview of specific multimedia and digital signal processing requirements and then it focuses on feature detection to properly identify the adequate extension. A brief performance evaluation on two competitive processors closes the communication. 1 Introduction The purpose of this communication is to analyse extensions to instruction sets, describe the specific multimedia and digital signal processing (DSP) requirements of a processor, detail how to detect these extensions and verify if the processor supports them. To achieve this functionality an IA32 architecture example code will be demonstrated. To study the instruction sets supported by each processor, an analysis is performed to compare and distinguish each technology in terms of new extensions to instruction sets and architecture evolution, mapping a table that lists the instruction sets supported by each processor. To clearly identify these differences between architectures, tests are performed with an application example, determining comparable results of two competitive processors. In this communication, Section 2 gives an overview of multimedia and digital signal processing requirements, Section 3 explains the feature detection of these instructions, Section 4 details some of the extensions supported by IA32 based processors, Section 5 tests and describes the performance of each technology and analyses the results. Section 6 concludes this communication. 2 Multimedia and DSP Requirements Computer industries needed a way to improve their multimedia capabilities because of the demand for 3D graphics, video and other multimedia applications such as games. -

Travelmate P6 Series Product Sheet
Acer recommends Windows 10 Pro. TravelMate P6 Wi-Fi 6 Microsoft Teams SPECIFICATIONS TravelMate P6 P614-51-G2_51G-G2 2 1 3 12 13 14 15 16 4 5 6 7 8 9 10 11 17 Product views 1. Infrared LED 5. HDMI® port 9. Smart Card reader slot (optional) 14. microCD card reader (optional) 6. USB port 10. Keyboard 15. USB port 2. Webcam 7. USB Type-C /Thunderbolt 11. Touchpad 16. Ethernet port 3. 14" display 3 port 12. Power button with fingerprint 17. Kensington lock slot 4. DC-in jack 8. Headset/speaker jack reader 13. SIM card slot (optional) Operating system1, Windows 10 Pro 64-bit (Acer recommends Windows 10 Pro for business.) Windows 10 Home 64-bit 2 CPU and chipset1 Intel® CoreTM i7-10510U processor Intel® CoreTM i5-10210U processor Memory1, 3, 4, 5 Dual-channel DDR4 SDRAM support up to 24 GB of DDR4 system memory, 8 GB / 4 GB of onboard DDR4 system memory Display6 14.0" display with IPS (In-Plane Switching) technology, Full HD 1920 x 1080, high-brightness (300nits) Acer ComfyViewTM LED-backlit TFT LCD 16:9 aspect ratio, 100% sRGB color gamut Wide viewing angle up to 170 degrees Stylish and Slim design Mercury free, environment friendly Graphics Intel® UHD Graphics 620 (P614-51-G2 only) NVIDIA® GeForce® MX250 (P614-51G-G2 only) Audio Four built-in microphones Built-in discrete smart amplifiers to deliver powerful sound Compatible with Cortana with Voice for up to 4 meters Acer TrueHarmony technology for lower distortion, wider frequency range, headphone-like audio and powerful sound Certified for Microsoft Teams Storage1, 7, Solid state -

The Intel X86 Microarchitectures Map Version 2.0
The Intel x86 Microarchitectures Map Version 2.0 P6 (1995, 0.50 to 0.35 μm) 8086 (1978, 3 µm) 80386 (1985, 1.5 to 1 µm) P5 (1993, 0.80 to 0.35 μm) NetBurst (2000 , 180 to 130 nm) Skylake (2015, 14 nm) Alternative Names: i686 Series: Alternative Names: iAPX 386, 386, i386 Alternative Names: Pentium, 80586, 586, i586 Alternative Names: Pentium 4, Pentium IV, P4 Alternative Names: SKL (Desktop and Mobile), SKX (Server) Series: Pentium Pro (used in desktops and servers) • 16-bit data bus: 8086 (iAPX Series: Series: Series: Series: • Variant: Klamath (1997, 0.35 μm) 86) • Desktop/Server: i386DX Desktop/Server: P5, P54C • Desktop: Willamette (180 nm) • Desktop: Desktop 6th Generation Core i5 (Skylake-S and Skylake-H) • Alternative Names: Pentium II, PII • 8-bit data bus: 8088 (iAPX • Desktop lower-performance: i386SX Desktop/Server higher-performance: P54CQS, P54CS • Desktop higher-performance: Northwood Pentium 4 (130 nm), Northwood B Pentium 4 HT (130 nm), • Desktop higher-performance: Desktop 6th Generation Core i7 (Skylake-S and Skylake-H), Desktop 7th Generation Core i7 X (Skylake-X), • Series: Klamath (used in desktops) 88) • Mobile: i386SL, 80376, i386EX, Mobile: P54C, P54LM Northwood C Pentium 4 HT (130 nm), Gallatin (Pentium 4 Extreme Edition 130 nm) Desktop 7th Generation Core i9 X (Skylake-X), Desktop 9th Generation Core i7 X (Skylake-X), Desktop 9th Generation Core i9 X (Skylake-X) • Variant: Deschutes (1998, 0.25 to 0.18 μm) i386CXSA, i386SXSA, i386CXSB Compatibility: Pentium OverDrive • Desktop lower-performance: Willamette-128 -

A Performance Analysis Tool for Intel SGX Enclaves
sgx-perf: A Performance Analysis Tool for Intel SGX Enclaves Nico Weichbrodt Pierre-Louis Aublin Rüdiger Kapitza IBR, TU Braunschweig LSDS, Imperial College London IBR, TU Braunschweig Germany United Kingdom Germany [email protected] [email protected] [email protected] ABSTRACT the provider or need to refrain from offloading their workloads Novel trusted execution technologies such as Intel’s Software Guard to the cloud. With the advent of Intel’s Software Guard Exten- Extensions (SGX) are considered a cure to many security risks in sions (SGX)[14, 28], the situation is about to change as this novel clouds. This is achieved by offering trusted execution contexts, so trusted execution technology enables confidentiality and integrity called enclaves, that enable confidentiality and integrity protection protection of code and data – even from privileged software and of code and data even from privileged software and physical attacks. physical attacks. Accordingly, researchers from academia and in- To utilise this new abstraction, Intel offers a dedicated Software dustry alike recently published research works in rapid succession Development Kit (SDK). While it is already used to build numerous to secure applications in clouds [2, 5, 33], enable secure network- applications, understanding the performance implications of SGX ing [9, 11, 34, 39] and fortify local applications [22, 23, 35]. and the offered programming support is still in its infancy. This Core to all these works is the use of SGX provided enclaves, inevitably leads to time-consuming trial-and-error testing and poses which build small, isolated application compartments designed to the risk of poor performance.