An Integrated Analysis of the Genome-Wide Profiles of DNA Methylation and Mrna Expression Defining the Side Population of a Huma
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

CD29 Identifies IFN-Γ–Producing Human CD8+ T Cells With
+ CD29 identifies IFN-γ–producing human CD8 T cells with an increased cytotoxic potential Benoît P. Nicoleta,b, Aurélie Guislaina,b, Floris P. J. van Alphenc, Raquel Gomez-Eerlandd, Ton N. M. Schumacherd, Maartje van den Biggelaarc,e, and Monika C. Wolkersa,b,1 aDepartment of Hematopoiesis, Sanquin Research, 1066 CX Amsterdam, The Netherlands; bLandsteiner Laboratory, Oncode Institute, Amsterdam University Medical Center, University of Amsterdam, 1105 AZ Amsterdam, The Netherlands; cDepartment of Research Facilities, Sanquin Research, 1066 CX Amsterdam, The Netherlands; dDivision of Molecular Oncology and Immunology, Oncode Institute, The Netherlands Cancer Institute, 1066 CX Amsterdam, The Netherlands; and eDepartment of Molecular and Cellular Haemostasis, Sanquin Research, 1066 CX Amsterdam, The Netherlands Edited by Anjana Rao, La Jolla Institute for Allergy and Immunology, La Jolla, CA, and approved February 12, 2020 (received for review August 12, 2019) Cytotoxic CD8+ T cells can effectively kill target cells by producing therefore developed a protocol that allowed for efficient iso- cytokines, chemokines, and granzymes. Expression of these effector lation of RNA and protein from fluorescence-activated cell molecules is however highly divergent, and tools that identify and sorting (FACS)-sorted fixed T cells after intracellular cytokine + preselect CD8 T cells with a cytotoxic expression profile are lacking. staining. With this top-down approach, we performed an un- + Human CD8 T cells can be divided into IFN-γ– and IL-2–producing biased RNA-sequencing (RNA-seq) and mass spectrometry cells. Unbiased transcriptomics and proteomics analysis on cytokine- γ– – + + (MS) analyses on IFN- and IL-2 producing primary human producing fixed CD8 T cells revealed that IL-2 cells produce helper + + + CD8 Tcells. -

CD29 Identifies IFN-Γ–Producing Human CD8+ T Cells with an Increased Cytotoxic Potential
+ CD29 identifies IFN-γ–producing human CD8 T cells with an increased cytotoxic potential Benoît P. Nicoleta,b, Aurélie Guislaina,b, Floris P. J. van Alphenc, Raquel Gomez-Eerlandd, Ton N. M. Schumacherd, Maartje van den Biggelaarc,e, and Monika C. Wolkersa,b,1 aDepartment of Hematopoiesis, Sanquin Research, 1066 CX Amsterdam, The Netherlands; bLandsteiner Laboratory, Oncode Institute, Amsterdam University Medical Center, University of Amsterdam, 1105 AZ Amsterdam, The Netherlands; cDepartment of Research Facilities, Sanquin Research, 1066 CX Amsterdam, The Netherlands; dDivision of Molecular Oncology and Immunology, Oncode Institute, The Netherlands Cancer Institute, 1066 CX Amsterdam, The Netherlands; and eDepartment of Molecular and Cellular Haemostasis, Sanquin Research, 1066 CX Amsterdam, The Netherlands Edited by Anjana Rao, La Jolla Institute for Allergy and Immunology, La Jolla, CA, and approved February 12, 2020 (received for review August 12, 2019) Cytotoxic CD8+ T cells can effectively kill target cells by producing therefore developed a protocol that allowed for efficient iso- cytokines, chemokines, and granzymes. Expression of these effector lation of RNA and protein from fluorescence-activated cell molecules is however highly divergent, and tools that identify and sorting (FACS)-sorted fixed T cells after intracellular cytokine + preselect CD8 T cells with a cytotoxic expression profile are lacking. staining. With this top-down approach, we performed an un- + Human CD8 T cells can be divided into IFN-γ– and IL-2–producing biased RNA-sequencing (RNA-seq) and mass spectrometry cells. Unbiased transcriptomics and proteomics analysis on cytokine- γ– – + + (MS) analyses on IFN- and IL-2 producing primary human producing fixed CD8 T cells revealed that IL-2 cells produce helper + + + CD8 Tcells. -

The Disruption Ofcelf6, a Gene Identified by Translational Profiling
2732 • The Journal of Neuroscience, February 13, 2013 • 33(7):2732–2753 Neurobiology of Disease The Disruption of Celf6, a Gene Identified by Translational Profiling of Serotonergic Neurons, Results in Autism-Related Behaviors Joseph D. Dougherty,1,2 Susan E. Maloney,1,2 David F. Wozniak,2 Michael A. Rieger,1,2 Lisa Sonnenblick,3,4,5 Giovanni Coppola,4 Nathaniel G. Mahieu,1 Juliet Zhang,6 Jinlu Cai,8 Gary J. Patti,1 Brett S. Abrahams,8 Daniel H. Geschwind,3,4,5 and Nathaniel Heintz6,7 Departments of 1Genetics and 2Psychiatry, Washington University School of Medicine, St. Louis, Missouri 63110, 3UCLA Center for Autism Research and Treatment, Semel Institute for Neuroscience and Behavior, 4Program in Neurogenetics, Department of Neurology, and 5Department of Human Genetics, David Geffen School of Medicine at UCLA, Los Angeles, California 90095, 6Laboratory of Molecular Biology, Howard Hughes Medical Institute, and 7The GENSAT Project, Rockefeller University, New York, New York 10065, and 8Departments of Genetics and Neuroscience, Albert Einstein College of Medicine, New York, New York 10461 The immense molecular diversity of neurons challenges our ability to understand the genetic and cellular etiology of neuropsychiatric disorders. Leveraging knowledge from neurobiology may help parse the genetic complexity: identifying genes important for a circuit that mediates a particular symptom of a disease may help identify polymorphisms that contribute to risk for the disease as a whole. The serotonergic system has long been suspected in disorders that have symptoms of repetitive behaviors and resistance to change, including autism. We generated a bacTRAP mouse line to permit translational profiling of serotonergic neurons. -

Supplementary Tables S1-S3
Supplementary Table S1: Real time RT-PCR primers COX-2 Forward 5’- CCACTTCAAGGGAGTCTGGA -3’ Reverse 5’- AAGGGCCCTGGTGTAGTAGG -3’ Wnt5a Forward 5’- TGAATAACCCTGTTCAGATGTCA -3’ Reverse 5’- TGTACTGCATGTGGTCCTGA -3’ Spp1 Forward 5'- GACCCATCTCAGAAGCAGAA -3' Reverse 5'- TTCGTCAGATTCATCCGAGT -3' CUGBP2 Forward 5’- ATGCAACAGCTCAACACTGC -3’ Reverse 5’- CAGCGTTGCCAGATTCTGTA -3’ Supplementary Table S2: Genes synergistically regulated by oncogenic Ras and TGF-β AU-rich probe_id Gene Name Gene Symbol element Fold change RasV12 + TGF-β RasV12 TGF-β 1368519_at serine (or cysteine) peptidase inhibitor, clade E, member 1 Serpine1 ARE 42.22 5.53 75.28 1373000_at sushi-repeat-containing protein, X-linked 2 (predicted) Srpx2 19.24 25.59 73.63 1383486_at Transcribed locus --- ARE 5.93 27.94 52.85 1367581_a_at secreted phosphoprotein 1 Spp1 2.46 19.28 49.76 1368359_a_at VGF nerve growth factor inducible Vgf 3.11 4.61 48.10 1392618_at Transcribed locus --- ARE 3.48 24.30 45.76 1398302_at prolactin-like protein F Prlpf ARE 1.39 3.29 45.23 1392264_s_at serine (or cysteine) peptidase inhibitor, clade E, member 1 Serpine1 ARE 24.92 3.67 40.09 1391022_at laminin, beta 3 Lamb3 2.13 3.31 38.15 1384605_at Transcribed locus --- 2.94 14.57 37.91 1367973_at chemokine (C-C motif) ligand 2 Ccl2 ARE 5.47 17.28 37.90 1369249_at progressive ankylosis homolog (mouse) Ank ARE 3.12 8.33 33.58 1398479_at ryanodine receptor 3 Ryr3 ARE 1.42 9.28 29.65 1371194_at tumor necrosis factor alpha induced protein 6 Tnfaip6 ARE 2.95 7.90 29.24 1386344_at Progressive ankylosis homolog (mouse) -

Chromosome 18 Gene Dosage Map 2.0
Human Genetics (2018) 137:961–970 https://doi.org/10.1007/s00439-018-1960-6 ORIGINAL INVESTIGATION Chromosome 18 gene dosage map 2.0 Jannine D. Cody1,2 · Patricia Heard1 · David Rupert1 · Minire Hasi‑Zogaj1 · Annice Hill1 · Courtney Sebold1 · Daniel E. Hale1,3 Received: 9 August 2018 / Accepted: 14 November 2018 / Published online: 17 November 2018 © Springer-Verlag GmbH Germany, part of Springer Nature 2018 Abstract In 2009, we described the first generation of the chromosome 18 gene dosage maps. This tool included the annotation of each gene as well as each phenotype associated region. The goal of these annotated genetic maps is to provide clinicians with a tool to appreciate the potential clinical impact of a chromosome 18 deletion or duplication. These maps are continually updated with the most recent and relevant data regarding chromosome 18. Over the course of the past decade, there have also been advances in our understanding of the molecular mechanisms underpinning genetic disease. Therefore, we have updated the maps to more accurately reflect this knowledge. Our Gene Dosage Map 2.0 has expanded from the gene and phenotype maps to also include a pair of maps specific to hemizygosity and suprazygosity. Moreover, we have revamped our classification from mechanistic definitions (e.g., haplosufficient, haploinsufficient) to clinically oriented classifications (e.g., risk factor, conditional, low penetrance, causal). This creates a map with gradient of classifications that more accurately represents the spectrum between the two poles of pathogenic and benign. While the data included in this manuscript are specific to chro- mosome 18, they may serve as a clinically relevant model that can be applied to the rest of the genome. -
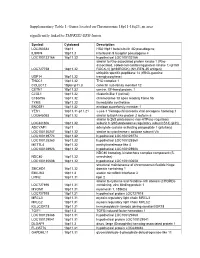
Supplementary Table 1: Genes Located on Chromosome 18P11-18Q23, an Area Significantly Linked to TMPRSS2-ERG Fusion
Supplementary Table 1: Genes located on Chromosome 18p11-18q23, an area significantly linked to TMPRSS2-ERG fusion Symbol Cytoband Description LOC260334 18p11 HSA18p11 beta-tubulin 4Q pseudogene IL9RP4 18p11.3 interleukin 9 receptor pseudogene 4 LOC100132166 18p11.32 hypothetical LOC100132166 similar to Rho-associated protein kinase 1 (Rho- associated, coiled-coil-containing protein kinase 1) (p160 LOC727758 18p11.32 ROCK-1) (p160ROCK) (NY-REN-35 antigen) ubiquitin specific peptidase 14 (tRNA-guanine USP14 18p11.32 transglycosylase) THOC1 18p11.32 THO complex 1 COLEC12 18pter-p11.3 collectin sub-family member 12 CETN1 18p11.32 centrin, EF-hand protein, 1 CLUL1 18p11.32 clusterin-like 1 (retinal) C18orf56 18p11.32 chromosome 18 open reading frame 56 TYMS 18p11.32 thymidylate synthetase ENOSF1 18p11.32 enolase superfamily member 1 YES1 18p11.31-p11.21 v-yes-1 Yamaguchi sarcoma viral oncogene homolog 1 LOC645053 18p11.32 similar to BolA-like protein 2 isoform a similar to 26S proteasome non-ATPase regulatory LOC441806 18p11.32 subunit 8 (26S proteasome regulatory subunit S14) (p31) ADCYAP1 18p11 adenylate cyclase activating polypeptide 1 (pituitary) LOC100130247 18p11.32 similar to cytochrome c oxidase subunit VIc LOC100129774 18p11.32 hypothetical LOC100129774 LOC100128360 18p11.32 hypothetical LOC100128360 METTL4 18p11.32 methyltransferase like 4 LOC100128926 18p11.32 hypothetical LOC100128926 NDC80 homolog, kinetochore complex component (S. NDC80 18p11.32 cerevisiae) LOC100130608 18p11.32 hypothetical LOC100130608 structural maintenance -

Network-Based Method for Drug Target Discovery at the Isoform Level
www.nature.com/scientificreports OPEN Network-based method for drug target discovery at the isoform level Received: 20 November 2018 Jun Ma1,2, Jenny Wang2, Laleh Soltan Ghoraie2, Xin Men3, Linna Liu4 & Penggao Dai 1 Accepted: 6 September 2019 Identifcation of primary targets associated with phenotypes can facilitate exploration of the underlying Published: xx xx xxxx molecular mechanisms of compounds and optimization of the structures of promising drugs. However, the literature reports limited efort to identify the target major isoform of a single known target gene. The majority of genes generate multiple transcripts that are translated into proteins that may carry out distinct and even opposing biological functions through alternative splicing. In addition, isoform expression is dynamic and varies depending on the developmental stage and cell type. To identify target major isoforms, we integrated a breast cancer type-specifc isoform coexpression network with gene perturbation signatures in the MCF7 cell line in the Connectivity Map database using the ‘shortest path’ drug target prioritization method. We used a leukemia cancer network and diferential expression data for drugs in the HL-60 cell line to test the robustness of the detection algorithm for target major isoforms. We further analyzed the properties of target major isoforms for each multi-isoform gene using pharmacogenomic datasets, proteomic data and the principal isoforms defned by the APPRIS and STRING datasets. Then, we tested our predictions for the most promising target major protein isoforms of DNMT1, MGEA5 and P4HB4 based on expression data and topological features in the coexpression network. Interestingly, these isoforms are not annotated as principal isoforms in APPRIS. -

Content Based Search in Gene Expression Databases and a Meta-Analysis of Host Responses to Infection
Content Based Search in Gene Expression Databases and a Meta-analysis of Host Responses to Infection A Thesis Submitted to the Faculty of Drexel University by Francis X. Bell in partial fulfillment of the requirements for the degree of Doctor of Philosophy November 2015 c Copyright 2015 Francis X. Bell. All Rights Reserved. ii Acknowledgments I would like to acknowledge and thank my advisor, Dr. Ahmet Sacan. Without his advice, support, and patience I would not have been able to accomplish all that I have. I would also like to thank my committee members and the Biomed Faculty that have guided me. I would like to give a special thanks for the members of the bioinformatics lab, in particular the members of the Sacan lab: Rehman Qureshi, Daisy Heng Yang, April Chunyu Zhao, and Yiqian Zhou. Thank you for creating a pleasant and friendly environment in the lab. I give the members of my family my sincerest gratitude for all that they have done for me. I cannot begin to repay my parents for their sacrifices. I am eternally grateful for everything they have done. The support of my sisters and their encouragement gave me the strength to persevere to the end. iii Table of Contents LIST OF TABLES.......................................................................... vii LIST OF FIGURES ........................................................................ xiv ABSTRACT ................................................................................ xvii 1. A BRIEF INTRODUCTION TO GENE EXPRESSION............................. 1 1.1 Central Dogma of Molecular Biology........................................... 1 1.1.1 Basic Transfers .......................................................... 1 1.1.2 Uncommon Transfers ................................................... 3 1.2 Gene Expression ................................................................. 4 1.2.1 Estimating Gene Expression ............................................ 4 1.2.2 DNA Microarrays ...................................................... -

Huntley Thesis 6-13-19 Final Revision
The Regulation and Function of BMPs in Osteoclastogenesis A Dissertation SUBMITTED TO THE FACULTY OF THE UNIVERSITY OF MINNESOTA BY Raphael Edward Huntley IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF DOCTOR OF PHILOSOPHY Raj Gopalakrishnan DMD, PhD, Adviser Kim Mansky PhD, Co Adviser June 2019 Raphael Huntley 2019 ã Acknowledgements Thank you to my committee members, Dr. Rajaram Gopalakrishnan, Dr. Kim Mansky, Dr. Paul Jardine, and Dr. Michael O’Connor. Without your input, guidance, and dedication this thesis would not be possible. Thank you to Dr. Mark Herzberg and Ann Hagen, whose efforts have created and sustained the MinnCReST training program, which provided me financial and developmental support as well as career guidance and training. i Dedication To my parents, who tried their best to raise me like a mensch. It almost worked. To my loving wife, who may be the only person to read it cover to cover. To my siblings, who have always referred to me as ‘genius boy, Rafi’. To my dog; he really is a good boy. ii Table of Contents: Acknowledgements .......................................................................................................................... i Dedication .......................................................................................................................................... ii Table of Contents: .......................................................................................................................... iii Table to Figures: ............................................................................................................................ -

A Network Inference Approach to Understanding Musculoskeletal
A NETWORK INFERENCE APPROACH TO UNDERSTANDING MUSCULOSKELETAL DISORDERS by NIL TURAN A thesis submitted to The University of Birmingham for the degree of Doctor of Philosophy College of Life and Environmental Sciences School of Biosciences The University of Birmingham June 2013 University of Birmingham Research Archive e-theses repository This unpublished thesis/dissertation is copyright of the author and/or third parties. The intellectual property rights of the author or third parties in respect of this work are as defined by The Copyright Designs and Patents Act 1988 or as modified by any successor legislation. Any use made of information contained in this thesis/dissertation must be in accordance with that legislation and must be properly acknowledged. Further distribution or reproduction in any format is prohibited without the permission of the copyright holder. ABSTRACT Musculoskeletal disorders are among the most important health problem affecting the quality of life and contributing to a high burden on healthcare systems worldwide. Understanding the molecular mechanisms underlying these disorders is crucial for the development of efficient treatments. In this thesis, musculoskeletal disorders including muscle wasting, bone loss and cartilage deformation have been studied using systems biology approaches. Muscle wasting occurring as a systemic effect in COPD patients has been investigated with an integrative network inference approach. This work has lead to a model describing the relationship between muscle molecular and physiological response to training and systemic inflammatory mediators. This model has shown for the first time that oxygen dependent changes in the expression of epigenetic modifiers and not chronic inflammation may be causally linked to muscle dysfunction. -

Signalling Pathways and Mechanistic Cues Highlighted by Transcriptomic
www.nature.com/scientificreports OPEN Signalling pathways and mechanistic cues highlighted by transcriptomic analysis of primordial, primary, and secondary ovarian follicles in domestic cat Shauna Kehoe1*, Katarina Jewgenow1, Paul R. Johnston2,3,4, Susan Mbedi2,5 & Beate C. Braun1 In vitro growth (IVG) of dormant primordial ovarian follicles aims to produce mature competent oocytes for assisted reproduction. Success is dependent on optimal in vitro conditions complemented with an understanding of oocyte and ovarian follicle development in vivo. Complete IVG has not been achieved in any other mammalian species besides mice. Furthermore, ovarian folliculogenesis remains sparsely understood overall. Here, gene expression patterns were characterised by RNA-sequencing in primordial (PrF), primary (PF), and secondary (SF) ovarian follicles from Felis catus (domestic cat) ovaries. Two major transitions were investigated: PrF-PF and PF-SF. Transcriptional analysis revealed a higher proportion in gene expression changes during the PrF-PF transition. Key infuencing factors during this transition included the interaction between the extracellular matrix (ECM) and matrix metalloproteinase (MMPs) along with nuclear components such as, histone HIST1H1T (H1.6). Conserved signalling factors and expression patterns previously described during mammalian ovarian folliculogenesis were observed. Species-specifc features during domestic cat ovarian folliculogenesis were also found. The signalling pathway terms “PI3K-Akt”, “transforming growth factor-β receptor”, “ErbB”, and “HIF-1” from the functional annotation analysis were studied. Some results highlighted mechanistic cues potentially involved in PrF development in the domestic cat. Overall, this study provides an insight into regulatory factors and pathways during preantral ovarian folliculogenesis in domestic cat. Artifcial reproductive technology (ART) such as, germ cell cryopreservation and in vitro embryo production can potentially contribute to species conservation when populations decline to a critically small size1. -
Sheet1 Page 1 Gene Symbol Gene Description Entrez Gene ID
Sheet1 RefSeq ID ProbeSets Gene Symbol Gene Description Entrez Gene ID Sequence annotation Seed matches location(s) Ago-2 binding specific enrichment (replicate 1) Ago-2 binding specific enrichment (replicate 2) OE lysate log2 fold change (replicate 1) OE lysate log2 fold change (replicate 2) Probability Pulled down in Karginov? NM_005646 202813_at TARBP1 Homo sapiens TAR (HIV-1) RNA binding protein 1 (TARBP1), mRNA. 6894 TR(1..5130)CDS(1..4866) 4868..4874,5006..5013 3.73 2.53 -1.54 -0.44 1 Yes NM_001665 203175_at RHOG Homo sapiens ras homolog gene family, member G (rho G) (RHOG), mRNA. 391 TR(1..1332)CDS(159..734) 810..817,782..788,790..796,873..879 3.56 2.78 -1.62 -1 1 Yes NM_002742 205880_at PRKD1 Homo sapiens protein kinase D1 (PRKD1), mRNA. 5587 TR(1..3679)CDS(182..2920) 3538..3544,3202..3208 4.15 1.83 -2.55 -0.42 1 Yes NM_003068 213139_at SNAI2 Homo sapiens snail homolog 2 (Drosophila) (SNAI2), mRNA. 6591 TR(1..2101)CDS(165..971) 1410..1417,1814..1820,1610..1616 3.5 2.79 -1.38 -0.31 1 Yes NM_006270 212647_at RRAS Homo sapiens related RAS viral (r-ras) oncogene homolog (RRAS), mRNA. 6237 TR(1..1013)CDS(46..702) 871..877 3.82 2.27 -1.54 -0.55 1 Yes NM_025188 219923_at,242056_at TRIM45 Homo sapiens tripartite motif-containing 45 (TRIM45), mRNA. 80263 TR(1..3584)CDS(589..2331) 3408..3414,2437..2444,3425..3431,2781..2787 3.87 1.89 -0.62 -0.09 1 Yes NM_024684 221600_s_at,221599_at C11orf67 Homo sapiens chromosome 11 open reading frame 67 (C11orf67), mRNA.