The Role of the First Five Formants in Three Vowels of Mandarin for Forensic Voice Analysis
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
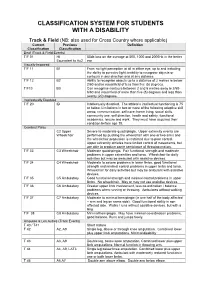
Disability Classification System
CLASSIFICATION SYSTEM FOR STUDENTS WITH A DISABILITY Track & Field (NB: also used for Cross Country where applicable) Current Previous Definition Classification Classification Deaf (Track & Field Events) T/F 01 HI 55db loss on the average at 500, 1000 and 2000Hz in the better Equivalent to Au2 ear Visually Impaired T/F 11 B1 From no light perception at all in either eye, up to and including the ability to perceive light; inability to recognise objects or contours in any direction and at any distance. T/F 12 B2 Ability to recognise objects up to a distance of 2 metres ie below 2/60 and/or visual field of less than five (5) degrees. T/F13 B3 Can recognise contours between 2 and 6 metres away ie 2/60- 6/60 and visual field of more than five (5) degrees and less than twenty (20) degrees. Intellectually Disabled T/F 20 ID Intellectually disabled. The athlete’s intellectual functioning is 75 or below. Limitations in two or more of the following adaptive skill areas; communication, self-care; home living, social skills, community use, self direction, health and safety, functional academics, leisure and work. They must have acquired their condition before age 18. Cerebral Palsy C2 Upper Severe to moderate quadriplegia. Upper extremity events are Wheelchair performed by pushing the wheelchair with one or two arms and the wheelchair propulsion is restricted due to poor control. Upper extremity athletes have limited control of movements, but are able to produce some semblance of throwing motion. T/F 33 C3 Wheelchair Moderate quadriplegia. Fair functional strength and moderate problems in upper extremities and torso. -

Reframing Sport Contexts: Labeling, Identities, and Social Justice
Reframing Sport Contexts: Labeling, Identities, and Social Justice Dr. Ted Fay and Eli Wolff Sport in Society Disability in Sport Initiative Northeastern University Critical Context • Marginalization (Current Status Quo) vs. • Legitimatization (New Inclusive Paradigm) Critical Context Naturalism vs. Trans-Humanism (Wolbring, G. (2009) How Do We Handle Our Differences related to Labeling Language and Cultural Identities? • Stereotyping? • Prejudice? • Discrimination? (Carr-Ruffino, 2003, p. 1) Ten Major Cultural Differences 1) Source of Control 2) Collectivism or Individualism 3) Homogeneous or Heterogeneous 4) Feminine or Masculine 5) Rank Status 6) Risk orientation 7) Time use 8) Space use 9) Communication Style 10) Economic System (Carr – Ruffino, 2003, p.27) Rationale for Inclusion • Divisioning by classification relative to “fair play” and equity principles • Sport model rather than “ism” segregated model (e.g., by race, gender, disability, socio-economic class, sexual orientation, look (body image), sect (religion), age) • Legitimacy • Human rights and equality Social Dynamics of Inequality Reinforce and reproduce Social Institutions Ideology Political (Patriarchy) Economic Educational Perpetuates Religious Prejudice & Are institutionalized by Discrimination Cultural Practices (ISM) Sport Music Art (Sage, 1998) Five Interlinking Conceptual Frameworks • Critical Change Factors Model (CCFM) • Organizational Continuum in Sport Governance (OCSG) • Criteria for Inclusion in Sport Organizations (CISO) • Individual Multiple Identity Sport Classifications Index (IMISCI) • Sport Opportunity Spectrum (SOS) Critical Change Factors Model (CCFM) F1) Change/occurrence of major societal event (s) affecting public opinion toward ID group. F2) Change in laws, government and court action in changing public policies toward ID group. F3) Change in level of influence of high profile ID group role models on public opinion. -

International Triathlon Union • ITU Competition Rules
ITU Competition Rules Approved by the ITU Executive Board, in November 2015 Green highlight – added as of November 2015 Red highlight – deleted as of November 2015 International Triathlon Union ITU Competition Rules 06-12-2015 1 The ITU Competition Rules is the master source document, found on ITU’s website at www.triathlon.org. The web based document acts as the official (authorised) reference document and is maintained based on authorised amendments in accordance with recommendations by the ITU Technical Committee and accepted by the ITU Executive Board. Contact International Triathlon Union (ITU) Maison du Sport International Av. de Rhodanie 54 Lausanne CH -1007, Switzerland Tel +41 21 614 60 30 Fax +41 21 614 60 39 Email: [email protected] For general information about ITU visit www.triathlon.org International Triathlon Union ITU Competition Rules 06-12-2015 2 TABLE OF CONTENTS 1. INTRODUCTION: _________________________________________________________________________ 4 2. CONDUCT OF ATHLETES: ___________________________________________________________________ 6 3. PENALTIES: _____________________________________________________________________________ 16 4. SWIMMING CONDUCT: ___________________________________________________________________ 20 5. CYCLING CONDUCT:______________________________________________________________________ 25 6. RUNNING CONDUCT: ____________________________________________________________________ 33 7. TRANSITION AREA CONDUCT: _____________________________________________________________ 34 8. COMPETITION -

Connexion Client Cataloging Quick Reference
OCLC Connexion Client Cataloging Quick Reference Introduction Keystroke shortcuts The Connexion client is a Windows-based interface to OCLC • Use default keystroke shortcuts or assign your own to activate Connexion® used to access WorldCat for cataloging. commands, insert characters, run macros, and insert text strings. This quick reference provides brief instructions for editing, saving, • View key assignments in View > Assigned Keys.To print or copy exporting, and printing labels for bibliographic records; using local files; the list, click Print or Copy to Clipboard. creating and adding records to WorldCat; replacing WorldCat records; Tip: Before printing, click a column heading to sort the list by data batch processing; and cataloging with non-Latin scripts. in the column. • Assign your own keystrokes in Tools > Keymaps. Multiscript support: The client supports the following non-Latin scripts: • Print a function key template to put at the top of your keyboard: Arabic, Armenian, Bengali, Chinese, Cyrillic, Devanagari, Ethiopic, Greek, Hebrew, Japanese, Korean, Syriac, Tamil, and Thai. www.oclc.org/support/documentation/connexion/client/ gettingstarted/keyboardtemplate.pdf. This quick reference does not cover instructions for authorities work or instructions already available in: Toolbar • Getting Started with Connexion Client • The client installs with three toolbars displayed by default: • Connexion Client Setup Worksheet o Main client toolbar (with command-equivalent buttons) • Connexion: Searching WorldCat Quick Reference o WorldCat quick search tool Quick tools for text strings and user tools Connexion client documentation assumes knowledge of MARC o cataloging. • Customize the main client toolbar: In Tools > Toolbar Editor, drag and drop buttons to add or remove, or reset to the default. -

Legislative Council Minutes 2010-2011
LEGISLATIVE COUNCIL MINUTES 2010-2011 (Formerly BOARD OF CONTROL) Colorado High School Activities Association 14855 E. 2nd Avenue Aurora, CO 80011 303-344-5050 Fax: 303-367-4101 TABLE OF CONTENTS CONSTITUTIONAL PROPSOALS APPROVED ........................................................................... 1-2 ADMINISTRATIVE PROPOSALS APPROVED ........................................................................... 3-5 SPORT PROPOSALS APPROVED ...............................................................................................52 ACTIVITY PROPOSALS APPROVED ...................................................................................... None POLICY PROPOSALS APPROVED ......................................................................................... None COMMITTEE REPORTS BASEBALL ................................................................................................................. 6-24 BASKETBALL ........................................................................................................... 25-45 BUDGET/PROPERTY ADMINISTRATION ................................................................ 46-50 CLASSIFICATION AND LEAGUE ORGANIZATION ................................................... 51-61 COACHING EDUCATION ................................................................................................62 CROSS COUNTRY .................................................................................................... 63-68 EQUITY .........................................................................................................................69 -

Screening Experiments with Maximally Balanced Projections Tim Kramer and Shankar Vaidyaraman October 2019 Overview
Screening Experiments with Maximally Balanced Projections Tim Kramer and Shankar Vaidyaraman October 2019 Overview • Design focus – screening and robustness studies • Orthogonality, near-orthogonality and balanced projections • Some examples • Outline of design optimization strategies • Benefits and drawbacks • Summary Box Centenary, October 2019 Company Confidential (c) 2019 Eli Lilly and Company 2 Screening Designs • Many potential factors • Few factors will likely have large impact • Experimental setup may impose balance constraints (e.g. plates with fixed wells per plate) • Some factors will necessarily have more than two levels (solvents, HPLC column types, equipment types,…) • Prediction confidence increases if design projects into full-factorial experiment for active factors Box Centenary, October 2019 Company Confidential (c) 2019 Eli Lilly and Company 3 Robustness Designs • Goal is not to identify impact of any specific factor • Identify whether quality attribute is acceptable when an individual factor or combination of factors are at their extreme values – Want worst case combination of 1, 2, 3,… factors Box Centenary, October 2019 Company Confidential (c) 2019 Eli Lilly and Company 4 Special Case Designs • Calibration Designs: one key factor (e.g. concentration) in the presence of many noise factors • Split Plot and Blocked Designs: Multiple factors applied to a set of plots or blocks Box Centenary, October 2019 Company Confidential (c) 2019 Eli Lilly and Company 5 2-Dimensional Projections of Standard 2^3 Half- Fraction Design -

Research Article KINEMATIC ANALYSIS of JAVELIN THROW
©Journal of Sports Science and Medicine (2003) 2, 36-46 http://www.jssm.org Research article KINEMATIC ANALYSIS OF JAVELIN THROW PERFORMED BY WHEELCHAIR ATHLETES OF DIFFERENT FUNCTIONAL CLASSES John W. Chow 1 *, Ann F. Kuenster 2 and Young-tae Lim 3 1Department of Exercise and Sport Sciences, University of Florida, Gainesville, USA 2Department of Kinesiology, University of Illinois at Urbana-Champaign, USA 3Division of Sport Science, Konkuk University, Chungju, Korea Received: 10 December 2002 / Accepted: 07 February 2003 / Published (online): 01 June 2003 ABSTRACT The purpose of this study was to identify those kinematic characteristics that are most closely related to the functional classification of a wheelchair athlete and measured distance of a javelin throw. Two S- VHS camcorders (60 field· s-1) were used to record the performance of 15 males of different classes. Each subject performed 6 - 10 throws and the best two legal throws from each subject were selected for analysis. Three-dimensional kinematics of the javelin and upper body segments at the instant of release and during the throw (delivery) were determined. The selection of kinematic parameters that were analyzed in this study was based on a javelin throw model showing the factors that determine the measured distance of a throw. The average of two throws for each subject was used to compute Spearman rank correlation coefficients between selected parameters and measured distance, and between selected parameters and the functional classification. The speeds and angles of the javelin at release, ranged from 9.1 to 14.7 m· s-1 and 29.6 to 35.8º, respectively, were smaller than those exhibited by elite male able-bodied throwers. -

Letters to Assessors 2006-010
STATE OF CALIFORNIA BETTY T. YEE STATE BOARD OF EQUALIZATION Acting Member PROPERTY AND SPECIAL TAXES DEPARTMENT First District, San Francisco 450 N STREET, SACRAMENTO, CALIFORNIA PO BOX 942879, SACRAMENTO, CALIFORNIA 94279-0064 BILL LEONARD Second District, Sacramento/Ontario 916 445-4982 FAX 916 323-8765 www.boe.ca.gov CLAUDE PARRISH Third District, Long Beach February 6, 2006 JOHN CHIANG Fourth District, Los Angeles STEVE WESTLY State Controller, Sacramento RAMON J. HIRSIG Executive Director No. 2006/010 CORRECTION TO COUNTY ASSESSORS: REVENUE AND TAXATION CODE SECTION 69.5: PROPOSITIONS 60, 90, AND 110 Section 69.5 was added to the Revenue and Taxation Code1 in 1987 to implement Proposition 60, which amended section 2 of article XIII A of the California Constitution to authorize the Legislature to provide for the transfer of a base year value from a principal residence2 to a replacement dwelling within the same county by a homeowner age 55 and over. Subsequently, section 69.5 was amended to implement Proposition 90, which authorized county boards of supervisors to adopt ordinances allowing base year value transfers between different counties, and Proposition 110, which extended these provisions to severely and permanently disabled persons of any age. After summarizing the key elements of section 69.5, this letter provides answers to frequently asked questions about its application. This letter supersedes Letters To Assessors No. 87/71 (dated September 11, 1987) and No. 88/10 (dated February 11, 1988). SUMMARY OF SECTION 69.5 Section 69.5 allows a homeowner to transfer the existing base year value to a replacement dwelling provided that: • If the replacement property is located in a different county than the original property, then the county in which the replacement dwelling is located must have a current ordinance allowing base year value transfers from other counties. -

The Role of the First Five Formants in Three Vowels of Mandarin for Forensic Voice Analysis
Zurich Open Repository and Archive University of Zurich Main Library Strickhofstrasse 39 CH-8057 Zurich www.zora.uzh.ch Year: 2019 The role of the first five formants in three vowels of mandarin for forensic voice analysis Cao, Honglin ; Dellwo, Volker Abstract: Formant characteristics are most commonly part of forensic speaker comparison (FSC). How- ever, only formants F1 to F3 typically occur in evidence material because it is mostly recorded via telephone. Given recent technological advances in telephony (e.g. WeChat or WhatsApp) higher for- mants (F4-F5) are becoming increasingly part of evidence material. The present study investigated the speaker- distinguishing properties of F1 to F5 of three sustained vowels /i/, /y/ and // in Mandarin produced by 20 young male speakers. Based on discriminant analysis, for each single formant, the best predictors were F5 for /i/ and F4 for /y/ and //. Classification performance varied between vowels. Inclusion of two and three formants yielded higher classification rates of 30−80%. The best value was provided by the combination of F2, F4 and F5 of //. The value and limitations of F4 and F5 for FSC are discussed. Posted at the Zurich Open Repository and Archive, University of Zurich ZORA URL: https://doi.org/10.5167/uzh-177494 Conference or Workshop Item Published Version Originally published at: Cao, Honglin; Dellwo, Volker (2019). The role of the first five formants in three vowels of mandarin for forensic voice analysis. In: International Congress of Phonetic Sciences, Melbourne, 5 August 2019 - 9 August 2019, 617-621. THE ROLE OF THE FIRST FIVE FORMANTS IN THREE VOWELS OF MANDARIN FOR FORENSIC VOICE ANALYSIS Honglin Caoa,b,c &Volker Dellwoc a Key Laboratory of Evidence Science (China University of Political Science and Law), Ministry of Education, China. -

Library of Congress Classification
G GEOGRAPHY (GENERAL) G Geography (General) For geography and description of individual countries, see D-F For mathematical geography and cartography see GA For physical geography see GB 1 Periodicals. Serials Societies 2 International 3 United States 4 Canada 5 Mexico. Central America. West Indies 6 South America 7 Great Britain 8 Czechoslovakia 9 Austria 10 Hungary 11 France 13 Germany Including West Germany 14 East Germany 15 Greece 17 Italy 19 Belgium 21 Netherlands (Holland) 23 Russia 23.5 Poland 24 Finland 25 Scandinavia 27 Spain 28 Portugal 29 Switzerland 31 Balkan States 32 Turkey 32.2 Jordan 32.5 Israel 32.7 Saudi Arabia 33 China 34 Korea 35 India 36 Pakistan 36.5 Bangladesh 37 Indochina 38 Indonesia 39 Japan 41 South Africa 43 Egypt 45 Algeria 47 Tanzania 49 Other African (not A-Z) 51 Australia 53 New Zealand 55 Pacific islands 56 Congresses Collected works (nonserial) Cf. G159+ Collections of voyages 58 Several authors 59 Individual authors 62 Addresses, essays, lectures 1 G GEOGRAPHY (GENERAL) G 63 Dictionaries. Encyclopedias 64 Directories Geographers 65 Geography as a profession Biography Cf. D-F, History Cf. GA198, GA407, GA473, etc., Cartographers Cf. G200 Explorers 67 Collective 69.A-Z Individual, A-Z e.g. 69.A2 Adamus Bremensis 69.B35 Barkov, Aleksandr Sergeevich 69.B4 Behaim, Martin 69.H2 Hakluyt, Richard 69.K44 Kemmerikh, Aleksandr (Aleksandr Oskarovich), 1912- 69.P4 Petermann, August 69.R4 Rennell, James 69.R6 Ritter, Karl 69.T55 Tillo, Aleksei Andreevich Philosophy. Relation to other topics. Methodology For relation to parapsychology see BF1045.G46 For relation to religion see BL65.G4 For relation to civilization see CB450 For relation to history. -

Women in the 2000, 2004 and 2008 Olympic and Paralympic Games an Analysis of Participation, Leadership and Media Opportunities
September 2009 Women in the 2000, 2004 and 2008 Olympic and Paralympic Games An Analysis of Participation, Leadership and Media Opportunities A Women’s Sports Foundation Research Report Authorship and Acknowledgments TThis report was authored by Maureen Smith, Ph.D., California State University, Sacramento, and Alison M. Wrynn, Ph.D., California State University, Long Beach. The report was reviewed by Donna A. Lopiano, Ph.D.; Don Sabo, Ph.D.; Marjorie A. Snyder, Ph.D.; Linda Mastandrea; Terri Lakowski; Carly Adams, Ph.D., University of Lethbridge; Ellen Carlton, Ph.D., Sonoma State University; Kerrie Kauer, Ph.D., California State University, Long Beach; Cheryl Cooky, Ph.D., California State University, Fullerton; Matthew Llewellyn, Pennsylvania State University; and Jennifer Piatt, Ph.D., California State University, Sacramento. The initial data collection was assisted by graduate students at California State University, Sacramento: Brandon Babcock, Kristi Jouett, Fred Kelley, Louis Lopez, Lindsey McEuen, Rusty Price, K.V. Vigil and Kelli White as well as graduate students from California State University, Long Beach. All data that was obtained from the Internet was accurate as of April 2009. Every attempt was made to obtain the most accurate and up-to-date data for this report. Special thanks to Deana Monahan for her editorial and graphic design expertise. Published September 2009, by the Women’s Sports Foundation® Eisenhower Park, 1899 Hempstead Turnpike, Suite 400 East Meadow, NY 11554 [email protected] www.WomensSportsFoundation.org © 2009, Women’s Sports Foundation, All Rights Reserved This report may be downloaded from www.WomensSportsFoundation.org. This report may be reproduced and distributed only in its entirety. -

An Examination of the Deliberate Practice Framework in Quad Rugby
University of Tennessee, Knoxville TRACE: Tennessee Research and Creative Exchange Masters Theses Graduate School 8-2009 An Examination of the Deliberate Practice Framework in Quad Rugby Rachel Lynn Boxell University of Tennessee - Knoxville Follow this and additional works at: https://trace.tennessee.edu/utk_gradthes Part of the Sports Sciences Commons Recommended Citation Boxell, Rachel Lynn, "An Examination of the Deliberate Practice Framework in Quad Rugby. " Master's Thesis, University of Tennessee, 2009. https://trace.tennessee.edu/utk_gradthes/23 This Thesis is brought to you for free and open access by the Graduate School at TRACE: Tennessee Research and Creative Exchange. It has been accepted for inclusion in Masters Theses by an authorized administrator of TRACE: Tennessee Research and Creative Exchange. For more information, please contact [email protected]. To the Graduate Council: I am submitting herewith a thesis written by Rachel Lynn Boxell entitled "An Examination of the Deliberate Practice Framework in Quad Rugby." I have examined the final electronic copy of this thesis for form and content and recommend that it be accepted in partial fulfillment of the requirements for the degree of Master of Science, with a major in Sport Studies. Jeffrey T. Fairbrother, Major Professor We have read this thesis and recommend its acceptance: Gene Hayes, Lars Dzikus Accepted for the Council: Carolyn R. Hodges Vice Provost and Dean of the Graduate School (Original signatures are on file with official studentecor r ds.) To the Graduate Council: I am submitting herewith a thesis written by Rachel Lynn Boxell entitled “An examination of the deliberate practice framework in quad rugby.” I have examined the final electronic copy of this thesis for form and content and recommend that it be accepted in partial fulfillment of the requirements for the degree of Master of Science, with a major in Sport Studies.