Advanced Packet Classification Jonathan Turner
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Disability Classification System
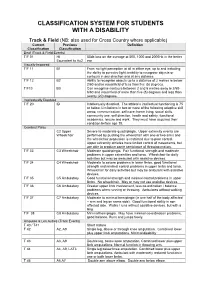
CLASSIFICATION SYSTEM FOR STUDENTS WITH A DISABILITY Track & Field (NB: also used for Cross Country where applicable) Current Previous Definition Classification Classification Deaf (Track & Field Events) T/F 01 HI 55db loss on the average at 500, 1000 and 2000Hz in the better Equivalent to Au2 ear Visually Impaired T/F 11 B1 From no light perception at all in either eye, up to and including the ability to perceive light; inability to recognise objects or contours in any direction and at any distance. T/F 12 B2 Ability to recognise objects up to a distance of 2 metres ie below 2/60 and/or visual field of less than five (5) degrees. T/F13 B3 Can recognise contours between 2 and 6 metres away ie 2/60- 6/60 and visual field of more than five (5) degrees and less than twenty (20) degrees. Intellectually Disabled T/F 20 ID Intellectually disabled. The athlete’s intellectual functioning is 75 or below. Limitations in two or more of the following adaptive skill areas; communication, self-care; home living, social skills, community use, self direction, health and safety, functional academics, leisure and work. They must have acquired their condition before age 18. Cerebral Palsy C2 Upper Severe to moderate quadriplegia. Upper extremity events are Wheelchair performed by pushing the wheelchair with one or two arms and the wheelchair propulsion is restricted due to poor control. Upper extremity athletes have limited control of movements, but are able to produce some semblance of throwing motion. T/F 33 C3 Wheelchair Moderate quadriplegia. Fair functional strength and moderate problems in upper extremities and torso. -

Reframing Sport Contexts: Labeling, Identities, and Social Justice
Reframing Sport Contexts: Labeling, Identities, and Social Justice Dr. Ted Fay and Eli Wolff Sport in Society Disability in Sport Initiative Northeastern University Critical Context • Marginalization (Current Status Quo) vs. • Legitimatization (New Inclusive Paradigm) Critical Context Naturalism vs. Trans-Humanism (Wolbring, G. (2009) How Do We Handle Our Differences related to Labeling Language and Cultural Identities? • Stereotyping? • Prejudice? • Discrimination? (Carr-Ruffino, 2003, p. 1) Ten Major Cultural Differences 1) Source of Control 2) Collectivism or Individualism 3) Homogeneous or Heterogeneous 4) Feminine or Masculine 5) Rank Status 6) Risk orientation 7) Time use 8) Space use 9) Communication Style 10) Economic System (Carr – Ruffino, 2003, p.27) Rationale for Inclusion • Divisioning by classification relative to “fair play” and equity principles • Sport model rather than “ism” segregated model (e.g., by race, gender, disability, socio-economic class, sexual orientation, look (body image), sect (religion), age) • Legitimacy • Human rights and equality Social Dynamics of Inequality Reinforce and reproduce Social Institutions Ideology Political (Patriarchy) Economic Educational Perpetuates Religious Prejudice & Are institutionalized by Discrimination Cultural Practices (ISM) Sport Music Art (Sage, 1998) Five Interlinking Conceptual Frameworks • Critical Change Factors Model (CCFM) • Organizational Continuum in Sport Governance (OCSG) • Criteria for Inclusion in Sport Organizations (CISO) • Individual Multiple Identity Sport Classifications Index (IMISCI) • Sport Opportunity Spectrum (SOS) Critical Change Factors Model (CCFM) F1) Change/occurrence of major societal event (s) affecting public opinion toward ID group. F2) Change in laws, government and court action in changing public policies toward ID group. F3) Change in level of influence of high profile ID group role models on public opinion. -

International Triathlon Union • ITU Competition Rules
ITU Competition Rules Approved by the ITU Executive Board, in November 2015 Green highlight – added as of November 2015 Red highlight – deleted as of November 2015 International Triathlon Union ITU Competition Rules 06-12-2015 1 The ITU Competition Rules is the master source document, found on ITU’s website at www.triathlon.org. The web based document acts as the official (authorised) reference document and is maintained based on authorised amendments in accordance with recommendations by the ITU Technical Committee and accepted by the ITU Executive Board. Contact International Triathlon Union (ITU) Maison du Sport International Av. de Rhodanie 54 Lausanne CH -1007, Switzerland Tel +41 21 614 60 30 Fax +41 21 614 60 39 Email: [email protected] For general information about ITU visit www.triathlon.org International Triathlon Union ITU Competition Rules 06-12-2015 2 TABLE OF CONTENTS 1. INTRODUCTION: _________________________________________________________________________ 4 2. CONDUCT OF ATHLETES: ___________________________________________________________________ 6 3. PENALTIES: _____________________________________________________________________________ 16 4. SWIMMING CONDUCT: ___________________________________________________________________ 20 5. CYCLING CONDUCT:______________________________________________________________________ 25 6. RUNNING CONDUCT: ____________________________________________________________________ 33 7. TRANSITION AREA CONDUCT: _____________________________________________________________ 34 8. COMPETITION -

Field Indicators of Hydric Soils
United States Department of Field Indicators of Agriculture Natural Resources Hydric Soils in the Conservation Service United States In cooperation with A Guide for Identifying and Delineating the National Technical Committee for Hydric Soils Hydric Soils, Version 8.2, 2018 Field Indicators of Hydric Soils in the United States A Guide for Identifying and Delineating Hydric Soils Version 8.2, 2018 (Including revisions to versions 8.0 and 8.1) United States Department of Agriculture, Natural Resources Conservation Service, in cooperation with the National Technical Committee for Hydric Soils Edited by L.M. Vasilas, Soil Scientist, NRCS, Washington, DC; G.W. Hurt, Soil Scientist, University of Florida, Gainesville, FL; and J.F. Berkowitz, Soil Scientist, USACE, Vicksburg, MS ii In accordance with Federal civil rights law and U.S. Department of Agriculture (USDA) civil rights regulations and policies, the USDA, its Agencies, offices, and employees, and institutions participating in or administering USDA programs are prohibited from discriminating based on race, color, national origin, religion, sex, gender identity (including gender expression), sexual orientation, disability, age, marital status, family/parental status, income derived from a public assistance program, political beliefs, or reprisal or retaliation for prior civil rights activity, in any program or activity conducted or funded by USDA (not all bases apply to all programs). Remedies and complaint filing deadlines vary by program or incident. Persons with disabilities who require alternative means of communication for program information (e.g., Braille, large print, audiotape, American Sign Language, etc.) should contact the responsible Agency or USDA’s TARGET Center at (202) 720-2600 (voice and TTY) or contact USDA through the Federal Relay Service at (800) 877-8339. -

Connexion Client Cataloging Quick Reference
OCLC Connexion Client Cataloging Quick Reference Introduction Keystroke shortcuts The Connexion client is a Windows-based interface to OCLC • Use default keystroke shortcuts or assign your own to activate Connexion® used to access WorldCat for cataloging. commands, insert characters, run macros, and insert text strings. This quick reference provides brief instructions for editing, saving, • View key assignments in View > Assigned Keys.To print or copy exporting, and printing labels for bibliographic records; using local files; the list, click Print or Copy to Clipboard. creating and adding records to WorldCat; replacing WorldCat records; Tip: Before printing, click a column heading to sort the list by data batch processing; and cataloging with non-Latin scripts. in the column. • Assign your own keystrokes in Tools > Keymaps. Multiscript support: The client supports the following non-Latin scripts: • Print a function key template to put at the top of your keyboard: Arabic, Armenian, Bengali, Chinese, Cyrillic, Devanagari, Ethiopic, Greek, Hebrew, Japanese, Korean, Syriac, Tamil, and Thai. www.oclc.org/support/documentation/connexion/client/ gettingstarted/keyboardtemplate.pdf. This quick reference does not cover instructions for authorities work or instructions already available in: Toolbar • Getting Started with Connexion Client • The client installs with three toolbars displayed by default: • Connexion Client Setup Worksheet o Main client toolbar (with command-equivalent buttons) • Connexion: Searching WorldCat Quick Reference o WorldCat quick search tool Quick tools for text strings and user tools Connexion client documentation assumes knowledge of MARC o cataloging. • Customize the main client toolbar: In Tools > Toolbar Editor, drag and drop buttons to add or remove, or reset to the default. -
![F6-13 202 (Ibc [F] 202)](https://docslib.b-cdn.net/cover/4091/f6-13-202-ibc-f-202-1014091.webp)
F6-13 202 (Ibc [F] 202)
F6-13 202 (IBC [F] 202) Proposed Change as Submitted Proponent: Elley Klausbruckner representing Klausbruckner & Associates Inc ([email protected]) Revise as follows: SECTION 202 (IBC [F] 202) GENERAL DEFINITIONS FLAMMABLE SOLID. A solid, other than a blasting agent or explosive, that is capable of causing fire through friction, absorption of moisture, spontaneous chemical change or retained heat from manufacturing or processing, or which has an ignition temperature below 212°F (100°C) or which burns so vigorously and persistently when ignited as to create a serious hazard. A chemical shall be considered a flammable solid as determined in accordance with the test method of CPSC 16 CFR Part 1500.44, if it ignites and burns with a self-sustained flame at a rate greater than 0.1 0.0866 inch (2.5 mm 2.2 mm) per second along its major axis. Reason: The definition proposed is in line with GHS [Globally Harmonized System] which is now adopted by OSHA. When an MSDS is prepared today, a material classified as “Flammable Solids” is typically based on this definition and not the previous definition [existing language in the Fire Code]. For additional details please see http://www.osha.gov/dsg/hazcom/ghs.html. Cost Impact: The code change proposal will not increase the cost of construction. 202-FLAMMABLE SOLID-F-KLAUSBRUCKNER Committee Action Hearing Results Committee Action: Disapproved Committee Reason: The disapproval was based on the committee’s judgment that the code change could be the beginning of a trend toward acceptance of OSHA definitions which are much different than IFC definitions and are focused on worker and work- place safety only. -

The ICD-10 Classification of Mental and Behavioural Disorders Diagnostic Criteria for Research
The ICD-10 Classification of Mental and Behavioural Disorders Diagnostic criteria for research World Health Organization Geneva The World Health Organization is a specialized agency of the United Nations with primary responsibility for international health matters and public health. Through this organization, which was created in 1948, the health professions of some 180 countries exchange their knowledge and experience with the aim of making possible the attainment by all citizens of the world by the year 2000 of a level of health that will permit them to lead a socially and economically productive life. By means of direct technical cooperation with its Member States, and by stimulating such cooperation among them, WHO promotes the development of comprehensive health services, the prevention and control of diseases, the improvement of environmental conditions, the development of human resources for health, the coordination and development of biomedical and health services research, and the planning and implementation of health programmes. These broad fields of endeavour encompass a wide variety of activities, such as developing systems of primary health care that reach the whole population of Member countries; promoting the health of mothers and children; combating malnutrition; controlling malaria and other communicable diseases including tuberculosis and leprosy; coordinating the global strategy for the prevention and control of AIDS; having achieved the eradication of smallpox, promoting mass immunization against a number of other -
Modifier Chart
Modifier Chart 22 Increased procedural services 23 Unusual anesthesia Unrelated Evaluation & Management (E/M) services by the same 24 provider during postoperative period Significant, separately identifiable E/M service by the same physician 25 on the same day of the procedure or other service 26 Professional component 32 Mandated Services When primary purpose is the delivery of an evidence-based service in accord with US Preventive Services Task Force A or B rating in effect 33 and other preventive services identified in preventive services mandates (legislative or regulatory) 47 Anesthesia by surgeon 50 Bilateral procedure 51 Multiple procedures 52 Reduced services 53 Discontinued procedure 54 Surgical care only 55 Postoperative management only 57 Decision for surgery Staged or related procedure or service by the same physician during 58 the postoperative period 59 Distinct procedural service Separate encounter, distinct because it occurred during a separate XE * encounter Separate structure, distinct because it was performed on a separate XS * organ/structure Separate practitioner, distinct because it was performed by a XP * different practitioner Unusual non-overlapping service, distinct because it does not XL * overlap usual components of the main service 62 Two surgeons 63 Procedure performed on infants less than 4 kgs. 66 Surgical team Repeat procedure or service by the same physician or other qualified 76 health care professional Repeat procedure or service by another physician or other qualified 77 health care professional Unplanned -

Legislative Council Minutes 2010-2011
LEGISLATIVE COUNCIL MINUTES 2010-2011 (Formerly BOARD OF CONTROL) Colorado High School Activities Association 14855 E. 2nd Avenue Aurora, CO 80011 303-344-5050 Fax: 303-367-4101 TABLE OF CONTENTS CONSTITUTIONAL PROPSOALS APPROVED ........................................................................... 1-2 ADMINISTRATIVE PROPOSALS APPROVED ........................................................................... 3-5 SPORT PROPOSALS APPROVED ...............................................................................................52 ACTIVITY PROPOSALS APPROVED ...................................................................................... None POLICY PROPOSALS APPROVED ......................................................................................... None COMMITTEE REPORTS BASEBALL ................................................................................................................. 6-24 BASKETBALL ........................................................................................................... 25-45 BUDGET/PROPERTY ADMINISTRATION ................................................................ 46-50 CLASSIFICATION AND LEAGUE ORGANIZATION ................................................... 51-61 COACHING EDUCATION ................................................................................................62 CROSS COUNTRY .................................................................................................... 63-68 EQUITY .........................................................................................................................69 -

Screening Experiments with Maximally Balanced Projections Tim Kramer and Shankar Vaidyaraman October 2019 Overview
Screening Experiments with Maximally Balanced Projections Tim Kramer and Shankar Vaidyaraman October 2019 Overview • Design focus – screening and robustness studies • Orthogonality, near-orthogonality and balanced projections • Some examples • Outline of design optimization strategies • Benefits and drawbacks • Summary Box Centenary, October 2019 Company Confidential (c) 2019 Eli Lilly and Company 2 Screening Designs • Many potential factors • Few factors will likely have large impact • Experimental setup may impose balance constraints (e.g. plates with fixed wells per plate) • Some factors will necessarily have more than two levels (solvents, HPLC column types, equipment types,…) • Prediction confidence increases if design projects into full-factorial experiment for active factors Box Centenary, October 2019 Company Confidential (c) 2019 Eli Lilly and Company 3 Robustness Designs • Goal is not to identify impact of any specific factor • Identify whether quality attribute is acceptable when an individual factor or combination of factors are at their extreme values – Want worst case combination of 1, 2, 3,… factors Box Centenary, October 2019 Company Confidential (c) 2019 Eli Lilly and Company 4 Special Case Designs • Calibration Designs: one key factor (e.g. concentration) in the presence of many noise factors • Split Plot and Blocked Designs: Multiple factors applied to a set of plots or blocks Box Centenary, October 2019 Company Confidential (c) 2019 Eli Lilly and Company 5 2-Dimensional Projections of Standard 2^3 Half- Fraction Design -

Research Article KINEMATIC ANALYSIS of JAVELIN THROW
©Journal of Sports Science and Medicine (2003) 2, 36-46 http://www.jssm.org Research article KINEMATIC ANALYSIS OF JAVELIN THROW PERFORMED BY WHEELCHAIR ATHLETES OF DIFFERENT FUNCTIONAL CLASSES John W. Chow 1 *, Ann F. Kuenster 2 and Young-tae Lim 3 1Department of Exercise and Sport Sciences, University of Florida, Gainesville, USA 2Department of Kinesiology, University of Illinois at Urbana-Champaign, USA 3Division of Sport Science, Konkuk University, Chungju, Korea Received: 10 December 2002 / Accepted: 07 February 2003 / Published (online): 01 June 2003 ABSTRACT The purpose of this study was to identify those kinematic characteristics that are most closely related to the functional classification of a wheelchair athlete and measured distance of a javelin throw. Two S- VHS camcorders (60 field· s-1) were used to record the performance of 15 males of different classes. Each subject performed 6 - 10 throws and the best two legal throws from each subject were selected for analysis. Three-dimensional kinematics of the javelin and upper body segments at the instant of release and during the throw (delivery) were determined. The selection of kinematic parameters that were analyzed in this study was based on a javelin throw model showing the factors that determine the measured distance of a throw. The average of two throws for each subject was used to compute Spearman rank correlation coefficients between selected parameters and measured distance, and between selected parameters and the functional classification. The speeds and angles of the javelin at release, ranged from 9.1 to 14.7 m· s-1 and 29.6 to 35.8º, respectively, were smaller than those exhibited by elite male able-bodied throwers. -

(Thompson, 1956) That the Frequency of Dis- the Genotype. One
GENOTYPIC CONTROL OF CHROMOSOME BEHAVIOUR. IN RYE VI. SELECTION FOR DISJUNCTION FREQUENCY C. W. LAWRENCE Deportment of Genetics, University of Birmingham Received20.vi.57 I.INTRODUCTION IThas been shown (Thompson, 1956) that the frequency of dis- junctional separation of the chromosomes in rings and chains formed at meiosis in an interchange heterozygote is subject to the control of the genotype. One would expect, therefore, that the disjunction frequency could be changed by selection, and indeed if the differences found between characteristic disjunction frequencies of closely related species (e.g.inEnot1,era,Clcland,1926 ; Kulkarni, 1929) are genetic, they suggest that selection may in fact bring about such a change. The following account offers direct evidence of the effect on this character of selection among genotypes within a species. F1 231 F., 3 2 1 107 F,3 106 / \ IN108 F4 9394 95 96 97 98 47 F 45 46 /1 F,, 1 2 3 4 5 6 Fin. —Pedigree of material. l' and P0 are inbred lines. The parents and each number in F1 and F2 represent a single plant. In F3 and subsequent generations each number rcl)resents a family which arose from a single plant self-pollinated in the preceding generation. 2.MATERIAL AND METHOD Thematerial used is that described by Thompson (l.c.). Two independent interchanges are involved, and these can be distinguished at diplotene in hetero- zygotes, though not at metaphase. Interchange A includes the nucleolar chromo- some. and interchange B contains slightly unequal chromosomes. The interchanges were found in an F1 plant from a cross between two inbred hues of rye.