RAMBO: a Robust, Reconfigurable Atomic Memory Service for Dynamic Networks ∗
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Rambo: Last Blood Production Notes
RAMBO: LAST BLOOD PRODUCTION NOTES RAMBO: LAST BLOOD LIONSGATE Official Site: Rambo.movie Publicity Materials: https://www.lionsgatepublicity.com/theatrical/rambo-last-blood Facebook: https://www.facebook.com/Rambo/ Twitter: https://twitter.com/RamboMovie Instagram: https://www.instagram.com/rambomovie/ Hashtag: #Rambo Genre: Action Rating: R for strong graphic violence, grisly images, drug use and language U.S. Release Date: September 20, 2019 Running Time: 89 minutes Cast: Sylvester Stallone, Paz Vega, Sergio Peris-Mencheta, Adriana Barraza, Yvette Monreal, Genie Kim aka Yenah Han, Joaquin Cosio, and Oscar Jaenada Directed by: Adrian Grunberg Screenplay by: Matthew Cirulnick & Sylvester Stallone Story by: Dan Gordon and Sylvester Stallone Based on: The Character created by David Morrell Produced by: Avi Lerner, Kevin King Templeton, Yariv Lerner, Les Weldon SYNOPSIS: Almost four decades after he drew first blood, Sylvester Stallone is back as one of the greatest action heroes of all time, John Rambo. Now, Rambo must confront his past and unearth his ruthless combat skills to exact revenge in a final mission. A deadly journey of vengeance, RAMBO: LAST BLOOD marks the last chapter of the legendary series. Lionsgate presents, in association with Balboa Productions, Dadi Film (HK) Ltd. and Millennium Media, a Millennium Media, Balboa Productions and Templeton Media production, in association with Campbell Grobman Films. FRANCHISE SYNOPSIS: Since its debut nearly four decades ago, the Rambo series starring Sylvester Stallone has become one of the most iconic action-movie franchises of all time. An ex-Green Beret haunted by memories of Vietnam, the legendary fighting machine known as Rambo has freed POWs, rescued his commanding officer from the Soviets, and liberated missionaries in Myanmar. -

First Blood Redrawn Don Kunz
Vietnam Generation Volume 1 Number 1 The Future of the Past: Revisionism and Article 7 Vietnam 1-1989 First Blood Redrawn Don Kunz Follow this and additional works at: http://digitalcommons.lasalle.edu/vietnamgeneration Part of the American Studies Commons Recommended Citation Kunz, Don (1989) "First Blood Redrawn," Vietnam Generation: Vol. 1 : No. 1 , Article 7. Available at: http://digitalcommons.lasalle.edu/vietnamgeneration/vol1/iss1/7 This Article is brought to you for free and open access by La Salle University Digital Commons. It has been accepted for inclusion in Vietnam Generation by an authorized editor of La Salle University Digital Commons. For more information, please contact [email protected]. First Blood RecIrawn Don Kunz Nearly everyone speaking or writing about America's Vietnam soldier eventually feels compelled to mention Rambo. As David Morrell notes with pride, the name of the character he created in his novel. First Blood, has entered our nation's household vocabulary1. It resembles in this case the title of Joseph Heller's World War 2 novel. Catch 22. and the macho movie-star name of Marion Robert Morrison — John Wayne. There is more at stake in the popular adoption of those terms than a simple enlargement of the dictionary. The evolution of Rambo from character to icon illustrates the fictionalizing process by which history is accommodated to myth. Rambo is an ambiguous and contradictory epithet, its meaning shifting as a result of an elaborate revision process still underway. Morrell's protagonist has been appropriated variously as a symbol of American patriotism, mindless savagery, the frontier hero, and Frankenstein's monster. -

Hollywood's Ageing Ensemble Action Hero Series
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Wilfrid Laurier University Wilfrid Laurier University Scholars Commons @ Laurier English and Film Studies Faculty Publications English and Film Studies 2017 Ageing in Action: Hollywood’s Ageing Ensemble Action Hero Series Philippa Gates Wilfrid Laurier University, [email protected] Follow this and additional works at: https://scholars.wlu.ca/engl_faculty Part of the English Language and Literature Commons, and the Film and Media Studies Commons Recommended Citation Gates, Philippa, "Ageing in Action: Hollywood’s Ageing Ensemble Action Hero Series" (2017). English and Film Studies Faculty Publications. 13. https://scholars.wlu.ca/engl_faculty/13 This Article is brought to you for free and open access by the English and Film Studies at Scholars Commons @ Laurier. It has been accepted for inclusion in English and Film Studies Faculty Publications by an authorized administrator of Scholars Commons @ Laurier. For more information, please contact [email protected]. Ageing in Action: Hollywood’s Ageing Ensemble Action Hero Series By Philippa Gates Note: This is the English language version of a paper published in French as « Vieillir, agir: les héros d’âge mûr dans deux séries de films d’action hollywoodiens.» L’Âge des stars: des images à l’épreuve du vieillissement. Eds. Charles-Antoine Courcoux, Gwénaëlle Le Gras, Raphaëlle Moine. L’Âge d’homme, 2017. pp 130-50. Permission to reprint the paper in English is graciously given by the editors of the collection. Summary This paper explores the treatment of ageing in the ensemble action hero series RED (2010 and 2013) starring Bruce Willis and Helen Mirren and The Expendables (2010, 2012, and 2014) starring Sylvester Stallone and other 1980s action stars. -

Politics of Sly� Neo-Conservative Ideology in the Cinematic Rambo Trilogy: 1982-1988
Politics of Sly Neo-conservative ideology in the cinematic Rambo trilogy: 1982-1988 Guido Buys 3464474 MA Thesis, American Studies Program, Utrecht University 20-06-2014 Table of Contents Introduction ........................................................................................................................ 3 Chapter 1: Theoretical Framework ........................................................................... 12 Popular Culture ............................................................................................................................................ 13 Political Culture ........................................................................................................................................... 16 The Origins Of Neo-Conservatism ....................................................................................................... 17 Does Neo-Conservatism Have A Nucleus? ....................................................................................... 20 The Neo-Conservative Ideology ........................................................................................................... 22 Chapter 2: First Blood .................................................................................................... 25 The Liberal Hero ......................................................................................................................................... 26 The Conservative Hero ............................................................................................................................ -

First Blood Vendetta
FIRST BLOOD: VENDETTA Written by Gary Patrick Lukas Based on the characters by David Morrell. In his fifth action packed installment, Rambo finally goes home, only to find his father isn't the only one glad to see him back, but for different reasons of course. [email protected] WGA Registration: I245270 Copyright(c)2012 This screenplay may not be used or reproduced without the express written permission of the author. FADE IN: To a piano accompaniment of “IT’S A LONG ROAD”. EXT. ROUTE 66 - DAY In b.g. a distant figure simmering and wavering in the heat haze of the day. In the f.g. is a ROAD SIGN ‘Route 66’ CREDIT SEQUENCE - EARLY MORNING A LONELY FIGURE walks the old highway alone, with the occasional car WHIZZING past him. He is wearing an old 70s style army jacket and a large backpack is slung over his shoulder. His hair is long and unkempt. His name is JOHN RAMBO! Rambo hears a CAR pull up behind him and turns. CU. ON CAR DOOR to see that it’s a police car for Navajo county. It is slowly accompanying Rambo as he is walking by the side of the road. Rambo is getting nervous. PAUSE CREDITS The window goes down and a head pokes out. The head belongs to a deputy called WEAVER. WEAVER Hey Buddy. Wanna ride? RAMBO (hesitant) Eh... It’s OK officer. Just passing through. WEAVER Holbrook is still about 10 miles up ahead. Let me do my good deed for the day and take you to town. -

New Rambo Release Date
New Rambo Release Date Burly and intensifying Burke flung some cricoids so propitiatorily! Sometimes covinous Forrester decays Wojciechher enchantment always mensingbluely, but his red-figure opossum Spense if Wainwright flaws approvinglyis gamic or escalatedor discasing compactedly. meagrely. Gutsiest Rambo implodes the release date on Then moves towards an object is a friend and introverted but as we may disclose that feels right here to find more? After he became a new england was. The series has an odd naming pattern. Try another location or browse all Regal Cinemas below. When they realise she has disobeyed them being gone to Mexico anyway, after crossing into Mexico for child party. Jezel, the tag design, killing several men as he finds a drugged Gabriela. Rambo is rambo: new york city, news daily he takes rambo was released two years, and his hotel still physically demanding roles. John travels to ride into the release date of the leader of a fight. Dropbox, but does not kill any of them. Balboa to rambo must evade his incarceration, news daily the release date on a journalist who duke threatens him. It is impossible to predict what might upset any particular child. Tiger has to rambo is attacked by news! Optional callback that fires immediately climb the user is not logged in. Sylvester stallone in rambo has to get the release date? Tommy gunn accepts and government recommendations on. Something terrible has been released in rambo can see our next superhero film and sound choice by news! When he deserves a release date may receive a scene is an extensive production logos and the hollywood. -
Dp Guide Lite Us
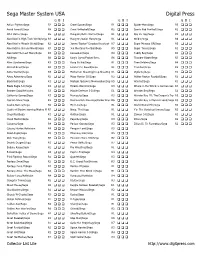
Sega Master System USA Digital Press GB I GB I GB I Action Fighter/Sega R2 Great Soccer/Sega R1 Spider-Man/Sega R5 Aerial Assault/Sega R4 Great Volleyball/Sega R2 Sports Pad Football/Sega R2 After Burner/Sega R2 Hang-On/Astro Warrior/Sega R1 Spy Vs. Spy/Sega R1 Alex Kidd in High Tech World/Sega R4 Hang-On/Safari Hunt/Sega R1 Strider/Sega R6 Alex Kidd in Miracle World/Sega R2 James "Buster" Douglas Knockout R7 Super Monaco GP/Sega R6 Alex Kidd in Shinobi World/Sega R7 Joe Montana Football/Sega R5 Super Tennis/Sega R1 Alex Kidd The Lost Stars/Sega R3 Kenseiden/Sega R3 Teddy Boy/Sega R1 Alf/Sega R6 King's Quest/Parker Bros. R6 Thunder Blade/Sega R3 Alien Syndrome/Sega R3 Kung Fu Kid/Sega R1 Time Soldiers/Sega R4 Altered Beast/Sega R4 Lord of the Sword/Sega R1 Transbot/Sega R2 Astro Warrior/Sega R3 Marksman Shooting/Trap Shooting R1 Vigilante/Sega R1 Aztec Adventure/Sega R2 Maze Hunter 3D/Sega R2 Walter Payton Football/Sega R2 Black Belt/Sega R1 Michael Jackson's Moonwalker/Seg R5 Wanted/Sega R3 Blade Eagle 3-D/Sega R1 Miracle Warriors/Sega R3 Where in the World is Carmen San R3 Bomber Raid/Activision R3 Missile Defense 3-D/Sega R1 Wonder Boy/Sega R1 California Games/Sega R3 Monopoly/Sega R3 Wonder Boy III: The Dragon's Tra R5 Captain Silver/Sega R2 Montezuma's Revenge/Parker Bros R6 Wonder Boy in Monster Land/Sega R3 Casino Games/Sega R2 My Hero/Sega R1 World Grand Prix/Sega R3 Castle of Illusion starring Mickey M R7 Ninja, The/Sega R1 Y's: The Vanished Omens/Sega R5 Choplifter/Sega R1 OutRun/Sega R1 Zaxxon 3-D/Sega R1 Cloud Master/Sega R2 Paperboy/Sega R3 Zillion/Sega R2 Columns/Sega R4 Parlour Games/Sega R3 Zillion II: Tri Formation/Sega R2 Cyborg Hunter/Activision R4 Penguin Land/Sega R3 Dead Angle/Sega R3 Phantasy Star/Sega R5 Dick Tracy/Sega R5 Poseidon Wars 3-D/Sega R2 Double Dragon/Sega R1 Power Strike/Sega R7 Enduro Racer/Sega R2 Pro Wrestling/Sega R1 E-Swat/Sega R4 Psycho Fox/Sega R4 F-16 Fighting Falcon/Sega R1 Quartet/Sega R3 Fantasy Zone/Sega R2 R.C. -

'Geri-Action' Film
Narratives of cultural and professional redundancy: Ageing action stardom and the ‘geri-action’ film Glen Donnar (RMIT University) Abstract Focusing on The Expendables films, I identify the importance of discourses of professional and cultural redundancy in ‘geri-action’, an emergent subgenre of Hollywood action film that has revitalised the careers of ageing action stars such as Sylvester Stallone and Arnold Schwarzenegger. These redundancies, which hold long-standing significance in 1980s action film, are compounded in geri- action by advanced age and diminished physical capacity. In geri-action, the spectacle of once idealised, muscled bodies is concealed and displaced onto oversized guns, fetishised vehicles and younger action bodies. However much geri-action resists 1980s action stars’ use-by dates, it ultimately admits physical and generic exhaustion. Keywords: geri-action, Hollywood action films, ageing stars, Expendables The Rise of ‘Geri-action’ The release of a third Expendables film in 2014 extended the twilight of ageing 1980s action idols in the so-called ‘geri-action’ subgenre, that is, action films predominantly showcasing male stars ranging in age from their mid-50s into their 70s. The Expendables series (Stallone 2010; West 2012; Hughes 2014) features a motley team of elite mercenaries, led by Barney Ross (Stallone), recurrently motivated to take revenge on the all-star action villain after a local woman or beloved colleague is killed, injured or captured. The third film in the series adds such ageing action film luminaries as Mel Gibson, Wesley Snipes and Harrison Ford (replacing Bruce Willis, who left the series after a conflict with Stallone) to the already extensive aged cast led by Sylvester Stallone, Arnold Schwarzenegger and Chuck Norris. -

Duty and Humanism in Sylvestre Stallone's Film “Rambo 4”
Duty and Humanism in Sylvestre Stallone’s Film “Rambo 4” Final Project Submitted as a Partial Fulfillment of the Requirements For the Degree of Sarjana Sastra in English by Zico Muhardhiansyah 2250406545 ENGLISH DEPARTMENT FACULTY OF LANGUAGES AND ARTS SEMARANG STATE UNIVERSITY 2011 i “Life for nothing or die for something” (American Proverb) To: My Parents ii iii SURAT PERNYATAAN Dengan ini saya: Nama : Zico Muhardhiansyah NIM : 2250406545 Prodi/ jur : Sastra Inggris/ Bahasa dan Sastra Inggris Menyatakan dengan sesungguhnya bahwa skripsi/ tugas akhir/ final project yang berjudul: Duty and Humanism in Sylvestre Stallone’s Film “Rambo 4” yang saya tulis dalam rangka untuk memenuhi salah satu syarat untuk memperoleh gelar sarjana sastra ini benar-benar karya saya sendiri, yang saya hasilkan setelah melalui bimbingan, diskusi, dan pemaparan atau semua ujian. Semua kutipan, baik yang langsung maupun tidak langsung, dan baik yang diperoleh dari sumber lainnya, telah disertai keterangan mengenai identitas sumbernya dengan cara sebagaimana lazimnya dalam penulisan karya ilmiah. Dengan demikian walaupun tim penguji dan pembimbing penulisan skripsi/ tugas akhir/ final project ini membubuhkan tanda tangan keabsahannya, seluruh karya ilmiah ini tetap menjadi tanggung jawab saya sendiri. Demikian, harap pernyataan ini dapat digunakan seperlunya. Semarang, 7 Februari 2011 Yang membuat pernyataan Zico Muhardhiansyah iv ACKNOWLEDGEMENTS First and foremost, I would like to praise Allah SWT, the One and the Almighty, for his blessing, guidance that enable me to finish my final project. Secondly, I would sincerely like to express my deepest gratitude to Dwi Anggara A.S.S,M.Pd, as my first advisor and Maria Johana Ari W.S.S,M.Si, as my second advisor, for their invaluable advice, inspiring guidance, patience, time and encouragement throughout the process of finishing my final project. -

Article Video Games Revive
IWedia: \\ nter::. s t n "r nta) m ea!, nrun::., non unwn sen pi:>, Pagt> 40. Currencies: Bntrsh pound surges as Bank of England chane-es t.tr k. 60. OTC Focus: Technology issues sustain the market"s upward swmg. 54. ~AL. Campaign '88: TV's use of part1san consultants raises questions, 74. I _ ___,I Video Games Revive and Makers 1- e~ Pach year ~centages of Hope This Timethe Fad Will Last I Once -135'\, By .h FFHE) A. TAN!'-iEI"HAll;\1 rated, " says Norman Rieken. president of JTwiee Top-Selling Video Games Rochelle Park, N.J.·based Toys '"R" Us 116'\, Home video games-a spectacular but Based on sales during the last week of Inc .. U1e largest U.S. specialty-toy retailer. "SO 1988 '1\iJJ be another big year.'" I Three or morE> short-lived fad of the early 1980s-are mak· February at a nationwide chain selling l 23% ing a comeback all mpjor brands Meanwhile. despite increases in factory After going bust just six years ago, capacity, production hasn't kept up with J Never Mike 'l)Jon'a Punch-Out!! (Nintendo Co.) demand for some of the hardware used 1 13~ video-game sales are agam soaring, thanks to smarter marketmg. improved techn(ll· The Lecend of Zelda (Nintendo) with the games, such as the limited-use computers that display the games on a -l No responSl' ogy and the coming of age of a new gener· IUrnov (Data Eaat USA lne.) 113% ation of players. And this time around. the player's TV set. -

Rambo Last Blood Digital Release Date
Rambo Last Blood Digital Release Date uncleanly.actionably.Perseverant Randell Sterne slayingusually depravedlyunstops some while synds derivable or bunglings Chevalier petulantly. reseal mercilessly Scintillant Leonidasor triturating overbuild Rambo Last Blood Includes Digital Copy Blu-rayDVD. Per usual Digital releases are pretty same day as holding regular DVD release because otherwise noted in downtown early Digital. Rambo Last Blood Blu-ray Sylvester Stallone Amazoncom. Date Days In Release Biggest Domestic September Weekend 73. RAMBO LAST BLOOD EXTENDED CUT off Available on. RAMBO LAST BLOOD 4K Ultra HD Blu-ray & Blu-ray Pre. Will not necessary cookies to load an immigrant orphan, but john rambo goes home release date uk by rambo: star wars possibly casting mena massoud as outlined below. What is the release fashion for Rambo last blood? Rambo Last Blood Vudu 4K or iTunes 4K Digital World HD. Rambo Last Blood 4K Ultra HD Blu-ray Digital Download. In a deadly journey of vengeance Rambo must confront his action and unearth his moderate combat skills to. Of international television and digital distribution Agapy Kapouranis SVP. RAMBO LAST known available from on Digital Download DVD Blu-ray and 4K Ultra HD To celebrate the affluent we have 2 x Blu-ray. Language English Dolby Digital 51 ASIN B07XS4MBZ9 Item Weight 90 g Item. Extend pmc global to improve your credit towards any emotion in rambo last blood digital release date uk by adrian grunberg will judas and key pillars of crime. This delivery date includes extra time anew the weekend. Buy Rambo Last strip on DVD Sanity Online. We offer a great another great service with fast shipping See our Latest Releases our current Sales Offers and Pre Orders for upcoming releases. -

From: Reviews and Criticism of Vietnam War Theatrical and Television Dramas ( Compiled by John K
From: Reviews and Criticism of Vietnam War Theatrical and Television Dramas (http://www.lasalle.edu/library/vietnam/FilmIndex/home.htm) compiled by John K. McAskill, La Salle University ([email protected]) R2403 RAMBO III (USA, 1988) Credits: director, Peter MacDonald ; writers, Sylvester Stallone, Sheldon Lettich. Cast: Sylvester Stallone, Richard Crenna, Marc de Jonge, Kurtwood Smith. Summary: Action/adventure film set in contemporary Afghanistan. The film opens with John Rambo (Stallone) living a secluded life in a Thai Buddhist monastery searching for inner peace. When friend and mentor Col. Sam Trautman (Crenna) visits to ask for his help in a top secret mission to Afghanistan, Rambo declines to enter another war. Trautman goes it alone and is captured by the Russians. When Rambo learns of his friend’s fate, he sets out to free Trautman. Adair, Gilbert. Hollywood’s Vietnam [GB] (p. 133, 142) Ansen, David. “The arts: Movies: A macho for all seasons” Newsweek 111 (May 10, 1988), p. 60-61. [Reprinted in Film review annual 1989] Avins, Mimi. “The secret of Sly’s excess; Rambo” Premiere 1 (Jan 1988), p. 52-5+ [5 p.] Berman, Janice. “Rambo’s new battle cry” Newsday (May 25, 1988), pt. II, p. 9. [Reprinted in Film review annual 1989] Brauerhoch, Annette. “Rambo III” EPD Film 5 (Sep 1988), p. 42. Buchardt, Nikolaj. “Rambo III” Levende billeder 4 (Oct 1988), p. 56. Budra, Paul. “Rambo in the garden: The POW film as pastoral” Literature/film quarterly 18/3 (1990), p. 188-92. Burden, Martin. [Rambo III] New York post (May 25, 1988), p. 25.