Explaining the Resultative Parameter by Daniel A. Milway a Thesis
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Sign Language Typology Series
SIGN LANGUAGE TYPOLOGY SERIES The Sign Language Typology Series is dedicated to the comparative study of sign languages around the world. Individual or collective works that systematically explore typological variation across sign languages are the focus of this series, with particular emphasis on undocumented, underdescribed and endangered sign languages. The scope of the series primarily includes cross-linguistic studies of grammatical domains across a larger or smaller sample of sign languages, but also encompasses the study of individual sign languages from a typological perspective and comparison between signed and spoken languages in terms of language modality, as well as theoretical and methodological contributions to sign language typology. Interrogative and Negative Constructions in Sign Languages Edited by Ulrike Zeshan Sign Language Typology Series No. 1 / Interrogative and negative constructions in sign languages / Ulrike Zeshan (ed.) / Nijmegen: Ishara Press 2006. ISBN-10: 90-8656-001-6 ISBN-13: 978-90-8656-001-1 © Ishara Press Stichting DEF Wundtlaan 1 6525XD Nijmegen The Netherlands Fax: +31-24-3521213 email: [email protected] http://ishara.def-intl.org Cover design: Sibaji Panda Printed in the Netherlands First published 2006 Catalogue copy of this book available at Depot van Nederlandse Publicaties, Koninklijke Bibliotheek, Den Haag (www.kb.nl/depot) To the deaf pioneers in developing countries who have inspired all my work Contents Preface........................................................................................................10 -

Perfect-Traj.Pdf
Aspect shifts in Indo-Aryan and trajectories of semantic change1 Cleo Condoravdi and Ashwini Deo Abstract: The grammaticalization literature notes the cross-linguistic robustness of a diachronic pat- tern involving the aspectual categories resultative, perfect, and perfective. Resultative aspect markers often develop into perfect markers, which then end up as perfect plus perfective markers. We intro- duce supporting data from the history of Old and Middle Indo-Aryan languages, whose instantiation of this pattern has not been previously noted. We provide a semantic analysis of the resultative, the perfect, and the aspectual category that combines perfect and perfective. Our analysis reveals the change to be a two-step generalization (semantic weakening) from the original resultative meaning. 1 Introduction The emergence of new functional expressions and the changes in their distribution and interpretation over time have been shown to be systematic across languages, as well as across a variety of semantic domains. These observations have led scholars to construe such changes in terms of “clines”, or predetermined trajectories, along which expressions move in time. Specifically, the typological literature, based on large-scale grammaticaliza- tion studies, has discovered several such trajectorial shifts in the domain of tense, aspect, and modality. Three properties characterize such shifts: (a) the categories involved are sta- ble across cross-linguistic instantiations; (b) the paths of change are unidirectional; (c) the shifts are uniformly generalizing (Heine, Claudi, and H¨unnemeyer 1991; Bybee, Perkins, and Pagliuca 1994; Haspelmath 1999; Dahl 2000; Traugott and Dasher 2002; Hopper and Traugott 2003; Kiparsky 2012). A well-known trajectory is the one in (1). -
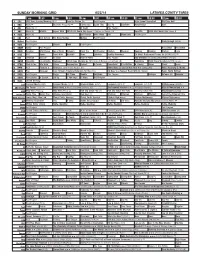
Sunday Morning Grid 6/22/14 Latimes.Com/Tv Times
SUNDAY MORNING GRID 6/22/14 LATIMES.COM/TV TIMES 7 am 7:30 8 am 8:30 9 am 9:30 10 am 10:30 11 am 11:30 12 pm 12:30 2 CBS CBS News Sunday Morning (N) Å Face the Nation (N) Paid Program High School Basketball PGA Tour Golf 4 NBC News Å Meet the Press (N) Å Conference Justin Time Tree Fu LazyTown Auto Racing Golf 5 CW News (N) Å In Touch Paid Program 7 ABC News (N) Wildlife Exped. Wild 2014 FIFA World Cup Group H Belgium vs. Russia. (N) SportCtr 2014 FIFA World Cup: Group H 9 KCAL News (N) Joel Osteen Mike Webb Paid Woodlands Paid Program 11 FOX Paid Joel Osteen Fox News Sunday Midday Paid Program 13 MyNet Paid Program Crazy Enough (2012) 18 KSCI Paid Program Church Faith Paid Program 22 KWHY Como Paid Program RescueBot RescueBot 24 KVCR Painting Wild Places Joy of Paint Wyland’s Paint This Oil Painting Kitchen Mexican Cooking Cooking Kitchen Lidia 28 KCET Hi-5 Space Travel-Kids Biz Kid$ News LinkAsia Healthy Hormones Ed Slott’s Retirement Rescue for 2014! (TVG) Å 30 ION Jeremiah Youssef In Touch Hour of Power Paid Program Into the Blue ›› (2005) Paul Walker. (PG-13) 34 KMEX Conexión En contacto Backyard 2014 Copa Mundial de FIFA Grupo H Bélgica contra Rusia. (N) República 2014 Copa Mundial de FIFA: Grupo H 40 KTBN Walk in the Win Walk Prince Redemption Harvest In Touch PowerPoint It Is Written B. Conley Super Christ Jesse 46 KFTR Paid Fórmula 1 Fórmula 1 Gran Premio Austria. -

The Aorist in Modern Armenian: Core Value and Contextual Meanings Anaid Donabedian-Demopoulos
The aorist in Modern Armenian: core value and contextual meanings Anaid Donabedian-Demopoulos To cite this version: Anaid Donabedian-Demopoulos. The aorist in Modern Armenian: core value and contextual mean- ings. Zlatka Guentcheva. Aspectuality and Temporality. Descriptive and theoretical issues, John Benjamins, pp.375 - 412, 2016, 9789027267610. 10.1075/slcs.172.12don. halshs-01424956 HAL Id: halshs-01424956 https://halshs.archives-ouvertes.fr/halshs-01424956 Submitted on 6 Jan 2017 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. The Aorist in Modern Armenian: core value and contextual meanings, in Guentchéva, Zlatka (ed.), Aspectuality and Temporality. Descriptive and theoretical issues, John Benjamins, 2016, p. 375-411 (the published paper miss examples written in Armenian) The aorist in Modern Armenian: core values and contextual meanings Anaïd Donabédian (SeDyL, INALCO/USPC, CNRS UMR8202, IRD UMR135) Introduction Comparison between particular markers in different languages is always controversial, nevertheless linguists can identify in numerous languages a verb tense that can be described as aorist. Cross-linguistic differences exist, due to the diachrony of the markers in question and their position within the verbal system of a given language, but there are clearly a certain number of shared morphological, syntactic, semantic and/or pragmatic features. -

Mathias Jenny: the Verb System of Mon
Zurich Open Repository and Archive University of Zurich Main Library Strickhofstrasse 39 CH-8057 Zurich www.zora.uzh.ch Year: 2005 The verb system of Mon Jenny, Mathias Posted at the Zurich Open Repository and Archive, University of Zurich ZORA URL: https://doi.org/10.5167/uzh-110202 Dissertation Originally published at: Jenny, Mathias. The verb system of Mon. 2005, University of Zurich, Faculty of Arts. Mathias Jenny: The Verb System of Mon Contents Preface v Abbreviations viii 1. Introduction 1 1.1 The Mon people and language 1 1.2 Sources and methodology 8 1.3 Sentence structure 13 1.4 Sentence types 15 1.4.1 Interrogative sentences 15 1.4.2 Imperative sentences 18 1.4.3 Conditional clauses 20 1.5 Phonology of Mon 23 1.5.1 Historical overview 23 1.5.2 From Middle Mon to Modern Mon 26 1.5.3 Modern dialects 30 1.5.4 The phonology of SM 33 1.5.5 Phonology and the writing system 37 2. Verbs in Mon 42 2.1 What are verbs? 42 2.2 The predicate in Mon 43 2.2.1 Previous studies of the verb in Mon 44 2.2.2 Verbs as word class in Mon 47 2.2.3 Nominal predicates and topicalised verbs 49 2.3 Negation 51 2.3.1 Negated statements and questions 51 2.3.2 Prohibitive 58 2.3.3 Summary 59 2.4 Verbal morphology 60 2.4.1 Historical development 60 2.4.2 Modern Mon 65 2.4.3 Summary 67 2.5 Verb classes and types of verbs 67 2.5.1 Transitive and intransitive verbs 68 2.5.2 Aktionsarten 71 2.5.3 Resultative verb compounds (RVC) 75 2.5.4 Existential verbs (Copulas) 77 2.5.4.1 ‹dah› th ‘be something’ 78 2.5.4.2 ‹måï› mŋ ‘be at, stay’ 80 2.5.4.3 ‹nwaÿ› nùm ‘be at, exist, have’ 82 2.5.4.4 ‹(hwa’) seï› (hùʔ) siəŋ ‘(not to) be so’ 86 i Mathias Jenny: The Verb System of Mon 2.5.5 Directionals 88 2.6 Complements of verbs 89 2.6.1 Direct objects 90 2.6.2 Oblique objects 91 2.6.3 Complement clauses 95 3. -
Baptist Church in Nursing - Education (BSN to MSN); and Valecia Baldwin, Girls Do Not Always Have the Get the Shovel and Conduct My Sumter
Woods in the hunt at 2 under B1 SERVING SOUTH CAROLINA SINCE OCTOBER 15, 1894 FRIDAY, APRIL 12, 2019 75 CENTS Sumter Police arrest 6 in drug-related sting A2 School district waiting on state for next move Financial recovery plan had $6.6M in budget cuts, but state board turned it down BY BRUCE MILLS enue levels. Because the state board de- its intention is to achieve necessary per- mean the state can take over the entire [email protected] nied the district’s appeal of state Super- sonnel cuts through attrition and re- district or take board members off their intendent of Education Molly Spear- structuring. seats, but it does allow them to lead the Though it will change because Sum- man’s fiscal emergency declaration in “I don’t know where the plan stands district financially. ter School District’s appeal of its state- Sumter, the state will recommend now, since we lost the appeal,” Miller In an email to all district employees declared fiscal emergency was denied changes to the plan and budget. said. “I’m waiting to hear from the state late Wednesday afternoon, Interim Su- Tuesday, the financial recovery plan District Chief Financial Officer Jenni- Department. I am not allowed to move perintendent Debbie Hamm also said presented at the hearing showed about fer Miller said Thursday that she and forward with anything, and we’re on administration is waiting on guidance $6.6 million in budget cuts.The cuts pre- administration are on hold now, waiting hold until the state Department con- from the state Department and doesn’t sented before the state Board of Educa- on those recommendations from the tacts us because they are technically in want to cut personnel. -

Ter + Past Participle Or Estar + Gerund? Aspect and Syntactic Variation in Brazilian Portuguese
Ter + past participle or Estar + gerund? Aspect and Syntactic Variation in Brazilian Portuguese Ronald Beline Mendes University of São Paulo The verbal aspect in Brazilian Portuguese (BP) has been described by a number of authors. Wachowicz 2003, based on Verkuyl 1993 and 1999, has accounted for the iterative and progressive interpretations of estar (be) + gerund. Ilari 2000 shows why ter (have) + participle is recognized as the iterative periphrasis in that language, even though it can possibly express progressive, durative meanings. Castilho 2000 proposes an aspectual typology for the aspect and shows how periphrastic constructions are productive in BP aspectual composition. None of those authors have, however, approached the use of those periphrases from a variationist, quantitative perspective. In contemporary BP, estar + gerund and ter + participle actually appear in the same context when the aspectual interpretation is iterative, and are commonly found in the data provided by a same speaker. That is a synchronic evidence of their variable use, as shown below: (1) Eu estou estudando muito ultimamente. I am studying much lately "I have been studying a lot lately" (iterative) (2) Eu tenho estudado muito ultimamente. I have studied much lately "I have been studying a lot lately" (iterative) Diachronic data show that their uses changed. In the 16th century, neither of the periphrases were used to express iterative - estar + gerund could only express durative, progressive meanings, whereas ter + participle would convey a resultative, punctual meaning, as in (3) and (4) respectively. In the 17th and 18th centuries, some tokens of ter + participle are found to be ambiguous, the iterative and resultative being possible. -

Mandarin Resultative Constructions and Aspect Incorporation Chienjer Lin University of Arizona
Aspect is Result: Mandarin Resultative Constructions and Aspect Incorporation Chienjer Lin University of Arizona 0 Introduction Aspect and resultative constructions have been treated as distinct phenomena in the linguistic literature. Viewpoint aspect encodes ways of viewing the “internal temporal constituency of a situation;” in particular, it provides information about completion and boundedness that is superimposed on verb phrases (Comrie 1976:3). It takes place at a functional position above the verb phrase. A sentence with simple past tense like (1) describes an action that occurred prior to the speech time. The perfective aspect phrase have V in (2) emphasizes the completion and experience of this action. Aspect is therefore seen as additional information that modifies the telicity of a verb phrase. (1) I saw him in the park. (2) I have seen him in the park twice. Resultatives on the other hand are taken as information within the verb phrase. They typically involve at least two events—a causative event followed by a resultative state, which is denoted by a small clause embedded under the main verb (Hoekstra 1989). For instance, the verb phrase wipe the slate clean involves the action of wiping and the final state of the slate’s being clean. The resultative state is embedded under the verb phrase, governed by the causative verb head. This paper explores the possibility of an alternative account for viewpoint aspect. Instead of viewing aspect as a functional head above verb phrases, I attempt to associate aspect with resultative predicates and claim that (at least part of) aspect should be base generated below the verb phrases like resultatives. -

Building Resultatives Angelika Kratzer, University of Massachusetts at Amherst August 20041
1 Building Resultatives Angelika Kratzer, University of Massachusetts at Amherst August 20041 1. The construction: Adjectival resultatives Some natural languages allow their speakers to put together a verb and an adjective to create complex predicates that are commonly referred to as “resultatives”. Here are two run-of-the- mill examples from German2: (1) Die Teekanne leer trinken The teapot empty drink ‘To drink the teapot empty’ (2) Die Tulpen platt giessen The tulips flat water Water the tulips flat Resultatives raise important questions for the syntax-semantics interface, and this is why they have occupied a prominent place in recent linguistic theorizing. What is it that makes this construction so interesting? Resultatives are submitted to a cluster of not obviously related constraints, and this fact calls out for explanation. There are tough constraints for the verb, for example: 1 . To appear in Claudia Maienborn und Angelika Wöllstein-Leisten (eds.): Event Arguments in Syntax, Semantics, and Discourse. Tübingen, Niemeyer. Thank you to Claudia Maienborn and Angelika Wöllstein-Leisten for organizing the stimulating DGfS workshop where this paper was presented, and for waiting so patiently for its final write-up. Claudia Maienborn also sent comments on an earlier version of the paper, which were highly appreciated. 2 . (2) is modeled after a famous example in Carrier & Randall (1992). 2 (3) a. Er hat seine Familie magenkrank gekocht. He has his family stomach sick cooked. ‘He cooked his family stomach sick.’ b. * Er hat seine Familie magenkrank bekocht. He has his family stomach sick cooked-for And there are also well-known restrictions for the participating adjectives (Simpson 1983, Smith 1983, Fabb 1984, Carrier and Randall 1992): (4) a. -

Types of Predicate
chapter 9 Types of Predicate This chapter deals with the types of predicates. The predicate of a sentence can be expressed by almost any word classes, not only through a verb. How- ever, verbal predicates are most common, about 87% of all predicates are verbs. They can be simple, containing only one verb or complex with more than one verbal element. The following figure shows the occurrence of predicates in an annotated sub-corpus. In the following sections, first the verbal predicates are discussed. 1 Verbal Predication The most common distinction between verbal predicates is their simplicity. The verbal predicate usually is simple. Complex predicates consist of an aux- iliary and a lexical verb. There are only few auxiliary verbs, one of these aux- iliaries is the negation auxiliary, which serves to form standard negation and appears most often in complex verbal predicates. Other auxiliaries are seman- tically not empty, but they have an additional, mostly modal meaning. In this section, only examples for the usage of auxiliary konɨďi ‘go away’ are given. For a detailed description of auxiliaries see Section 3.3 in Chapter 3, for negation see Chapter 12. The auxiliary verb konɨďi ‘go away’ appears only in essive or resultative- translative constructions. In these constructions an NP is followed by the infini- tive form (converb1) of the BE-verb (isʲa) and the conjugated form of the aux- iliary. Word order variations are not allowed. Contrary to Enets and Nenets, the infinitive/converb construction wasn’t grammaticalized as the essive case. This form has word stress of its own, and it never undergoes cliticization. -

Resultative and Depictive Constructions in English*
Resultative and Depictive Constructions in English* Chang-Su Lee Department ofEnglish Language Education I. Introduction The following illustrates two types of secondary predication, the resultative and the depictive construction: (1) a. John hammered the metal flat. (Resultative Construction) b. John ate the meat raw. (Depietive Construction) In (la), the adjective flat, called a resultative, a result phrase, or a resultative predicate, describes the final state of the object NP which results from the action or process denoted by the verb. Thus (la) means "John caused the metal to become flat by hammering it." On the other hand, in (lb) the adjective raw, called a depictive, a depictive phrase, or a depictive predicate, characterizes the state of an NP at the time of the initiation of the main predicate's action." So the sentence (lb) has the meaning "John ate the meat, and at the time he ate it, it was raw." Many ltngutsts have assumed that the resultative and the depictive construction are not syntactically different despite their difference in semantic interpretation (cf. Rapoport, 1990). In this paper, however, we propose that the resultative and the depietive construction involve two different types of syntactic configuration. *This paper is the summarized version of Lee's Ph.D. Thesis. 1) "Resultative" and "depletive" may be used to indicate a resultative and a depictive sentence. respectively. 56 THE SNU JOURNAL OF EDUCATION RESEARCH II. Syntactic Status of Resultatives and Depictives In the literature, it is generally assumed that resultatives and depictives are predicates (Hoekstra, 1984, 1988; Rothstein, 1985; Rapoport, 1990; Napoli, 1992). Let's consider the following examples: (2) a. -

Dowload Resume
Molly Grundman-Gerbosi COSTUME DESIGNER www.mggcostumedesign.com TELEVISION • The Kominsky Method- Season 3, Netflix, WBTV Michael Douglas, Sarah Baker, Kathleen Turner, Paul Reiser, Lisa Edelstein, Haley Joel Osment, Jane Seymour, Graham Rogers, Emily Osment, Ashleigh LaThrop, Melissa Tang, Casey Thomas Brown, Jenna Lyng Adams, Morgan Freeman Produced by-Chuck Lorre, Al Higgins, Marlis Pujol, Franklyn Gottbetter, Andy Tennant • Love, Victor- Season 2, HULU Michael Cimino, Ana Ortiz, James Martinez, Rachel Hilson, Bebe Wood, Anthony Turpel, George Sear, Mason Gooding, Isabella Ferreria, Mekhi Phifer, Sophia Bush, Mateo Fernandez, Anthony Keyan, Leslie Grossman Produced by- Adam Londy, Brian Tanen, Jason Ensler, Shawn Wilt, Dan Portnoy • AMEND:The Fight For America, Netflix Will Smith, Larry Wilmore, Mahershala Ali, Sterling K. Brown, Bobby Cannavale, Samira Wiley, Graham Greene, Laverne Cox, Utkarsh Ambudkar, Rafael Casal, Daveed Diggs, Whitney Cummings, Diane Guerrero, Gabriel Luna, Bambadjan Bamba • I’m Sorrry- Season 3, TruTV Andrea Savage, Tom Everett Scott, Kathy Baker, Martin Mull, Olive Petrucci, Gary Anthony Williams, Nelson Franklin, Lennon Parham Produced by- Andrea Savage, Joey Slamon, Shawn Wilt, Joel Henry, Savey Cathey • Love, Victor- Season 1, HULU Michael Cimino, Ana Ortiz, James Martinez, Rachel Hilson, Bebe Wood, Anthony Turpel, George Sear, Mason Gooding, Isabella Ferreria, Mateo Fernandez, Nick Robinson, Mekhi Phifer, Sophia Bush, Leslie Grossman, Andy Richter, Ali Wong Produced by- Adam Londy, Brian Tanen, Jason Ensler,