Analysis of E-Mail Attachment Signatures for Potential Use by Intrusion Detection Systems
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Securing Your Email in 13 Steps: the Email Security Checklist Handbook Securing Your Email in 13 Steps
HANDBOOK Securing Your Email in 13 Steps: The Email Security Checklist handbook Securing Your Email in 13 Steps overview You’ve hardened your servers, locked down your website and are ready to take on the internet. But all your hard work was in vain, because someone fell for a phishing email and wired money to a scammer, while another user inadvertently downloaded and installed malware from an email link that opened a backdoor into the network. Email is as important as the website when it comes to security. As a channel for social engineering, malware delivery and resource exploitation, a combination of best practices and user education should be enacted to reduce the risk of an email-related compromise. By following this 13 step checklist, you can make your email configuration resilient to the most common attacks and make sure it stays that way. 2 @UpGuard | UpGuard.com handbook Securing Your Email in 13 Steps 1. Enable SPF How do you know if an email is really from who it says it’s from? There are a couple of ways to answer this question, and Sender Policy Framework (SPF) is one. SPF works by publishing a DNS record of which servers are allowed to send email from a specific domain. 1. An SPF enabled email server receives an email from [email protected] 2. The email server looks up example.com and reads the SPF TXT record in DNS. 3. If the originating server of the email matches one of the allowed servers in the SPF record, the message is accepted. -

Imail V12 Web Client Help
Ipswitch, Inc. Web: www.imailserver.com 753 Broad Street Phone: 706-312-3535 Suite 200 Fax: 706-868-8655 Augusta, GA 30901-5518 Copyrights ©2011 Ipswitch, Inc. All rights reserved. IMail Server – Web Client Help This manual, as well as the software described in it, is furnished under license and may be used or copied only in accordance with the terms of such license. Except as permitted by such license, no part of this publication may be reproduced, photocopied, stored on a retrieval system, or transmitted, in any form or by any means, electronic, mechanical, recording, or otherwise, without the expressed prior written consent of Ipswitch, Inc. The content of this manual is furnished for informational use only, is subject to change without notice, and should not be construed as a commitment by Ipswitch, Inc. While every effort has been made to assure the accuracy of the information contained herein, Ipswitch, Inc. assumes no responsibility for errors or omissions. Ipswitch, Inc. also assumes no liability for damages resulting from the use of the information contained in this document. Ipswitch Collaboration Suite (ICS), the Ipswitch Collaboration Suite (ICS) logo, IMail, the IMail logo, WhatsUp, the WhatsUp logo, WS_FTP, the WS_FTP logos, Ipswitch Instant Messaging (IM), the Ipswitch Instant Messaging (IM) logo, Ipswitch, and the Ipswitch logo are trademarks of Ipswitch, Inc. Other products and their brands or company names are or may be trademarks or registered trademarks, and are the property of their respective companies. Update History December 2011 v12 April 2011 v11.5 October 2010 v11.03 May 2010 v11.02 Contents CHAPTER 1 Introduction to IMail Web Client About Ipswitch Web Messaging Help .................................................................................................................. -

Introduction to Email
Introduction to Email gcflearnfree.org/print/email101/introduction-to-email Introduction Do you ever feel like the only person who doesn't use email? You don't have to feel left out. If you're just getting started, you'll see that with a little bit of practice, email is easy to understand and use. In this lesson, you will learn what email is, how it compares to traditional mail, and how email addresses are written. We'll also discuss various types of email providers and the features and tools they include with an email account. Getting to know email Email (electronic mail) is a way to send and receive messages across the Internet. It's similar to traditional mail, but it also has some key differences. To get a better idea of what email is all about, take a look at the infographic below and consider how you might benefit from its use. Email advantages Productivity tools: Email is usually packaged with a calendar, address book, instant messaging, and more for convenience and productivity. Access to web services: If you want to sign up for an account like Facebook or order products from services like Amazon, you will need an email address so you can be safely identified and contacted. Easy mail management: Email service providers have tools that allow you to file, label, prioritize, find, group, and filter your emails for easy management. You can even easily control spam, or junk email. Privacy: Your email is delivered to your own personal and private account with a password required to access and view emails. -
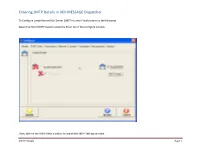
Entering SMTP Details in REV MESSAGE Dispatcher
Entering SMTP Details in REV MESSAGE Dispatcher. To Configure using Internet Mail Server (SMTP) to send Emails please do the following. Select the Email (SMTP) option under the Email tab in the Configure window. Then, click on the SMTP Details button to launch the SMTP Settings window. SMTP details Page 1 Entering SMTP Details in REV MESSAGE Dispatcher. In the User Information enter the Sender Name and the Sender E-mail Address. This is what will appear in the ‘From:’ field when the email is received. For example, we use Message Dispatcher for the Name and [email protected] as the E-mail Address SMTP details Page 2 Entering SMTP Details in REV MESSAGE Dispatcher. Example of what it looks like when the email is viewed. SMTP details Page 3 Entering SMTP Details in REV MESSAGE Dispatcher. The next step is to enter the Outgoing Mail Server SMTP (Simple Mail Transport Protocol) address. You can also use an IP address instead, i.e. 118.208.34.220 SMTP details Page 4 Entering SMTP Details in REV MESSAGE Dispatcher. The final step is to enter your outgoing email account and password information that provided to you by your ISP or Network Administrator. SMTP details Page 5 Entering SMTP Details in REV MESSAGE Dispatcher. There’re also Options for Email Attachment Encoding (MIME and UUEncode) and Email Message Format (HTML Mail Format). To send out long URL link in the email (like we have with the Web Interface link) we recommend you to select the HTML Mail Format option. Now, we just need to click on the Accept button to save these settings SMTP details Page 6 . -

In the United States District Court for the Eastern District of Virginia Richmond Division
Case 3:13-cv-00808-JRS Document 12 Filed 12/24/13 Page 1 of 46 PageID# 176 IN THE UNITED STATES DISTRICT COURT FOR THE EASTERN DISTRICT OF VIRGINIA RICHMOND DIVISION THE TRUSTEES OF COLUMBIA Civil Action No. 3:13-cv-00808-JRS UNIVERSITY IN THE CITY OF NEW YORK, Plaintiff JURY TRIAL DEMANDED vs. SYMANTEC CORPORATION, Defendant. FIRST AMENDED COMPLAINT Plaintiff The Trustees of Columbia University in the City of New York (“Columbia”) files this First Amended Complaint against Defendant Symantec Corporation (“Symantec”) for patent infringement, correction of inventorship, and other claims for relief, and alleges as follows: INTRODUCTION 1. Columbia brings this action to remedy Symantec’s violations of Columbia’s intellectual property rights in important computer security innovations. Protecting data exchanged in email and over networks from viruses and other malicious intrusions into our computers presents ever-increasing challenges. The creativity and hard work of Columbia professors and researchers has resulted in next generation techniques for detecting intrusions even for attacks that have never been seen before. Symantec is infringing several Columbia patents on computer security and intrusion detection, including United States Patent Nos. 7,487,544; 7,979,907; 7,448,084; 7,913,306; 8,074,115; and 8,601,322, as set forth in more detail in this First Amended Complaint. When Columbia alerted Symantec to Columbia’s patent rights and invited a licensing negotiation, Symantec ignored Columbia. Columbia brings this 2937734.1 01 Case 3:13-cv-00808-JRS Document 12 Filed 12/24/13 Page 2 of 46 PageID# 177 action to redress Symantec’s infringement of Columbia’s patents and the innovations of its researchers. -

An Email Worm Vaccine Architecture
An Email Worm Vaccine Architecture Stelios Sidiroglou, John Ioannidis, Angelos D. Keromytis, and Salvatore J. Stolfo Department of Computer Science, Columbia University {stelios,ji,angelos,sal}@cs.columbia.edu Abstract. We present an architecture for detecting “zero-day” worms and viruses in incoming email. Our main idea is to intercept every incoming message, pre- scan it for potentially dangerous attachments, and only deliver messages that are deemed safe. Unlike traditional scanning techniques that rely on some form of pattern matching (signatures), we use behavior-based anomaly detection. Under our approach, we “open” all suspicious attachments inside an instrumented vir- tual machine looking for dangerous actions, such as writing to the Windows reg- istry, and flag suspicious messages. The attachment processing can be offloaded to a cluster of ancillary machines (as many as are needed to keep up with a site's email load), thus not imposing any computational load on the mail server. Mes- sages flagged are put in a “quarantine” area for further, more labor-intensive pro- cessing. Our implementation shows that we can use a large number of malware- checking VMs operating in parallel to cope with high loads. Finally, we show that we are able to detect the actions of all malicious software we tested, while keeping the false positive rate to under 5%. 1 Introduction Recent incidents have demonstrated the ability of email-based worms and viruses (“mal- ware”) to infect large numbers of hosts very rapidly [1, 2]. Email malware propagates as executable attachments that users are tricked into opening, thus causing the malig- nant code to run and propagate, usually by sending copies of itself to all the entries in the user's address file. -

Archiving E-Mail
DIGITAL DILEMMAS: ARCHIVING E-MAIL PRE-CONFERENCE WORKSHOP ASSOCIATION OF CANADIAN ARCHIVISTS JUNE 10, 2008 Presented By: COLLABORATIVE ELECTRONIC RECORDS PROJECT TEAM Nancy Adgent, Steve Burbeck, Ricc Ferrante, Lynda Schmitz Fuhrig, Darwin Stapleton DIGITAL DILEMMAS: ARCHIVING E-MAIL WORKSHOP June 10, 2008 9:00 – 10:30 CERP Inception, funding, goals (Darwin Stapleton) Need for e-mail preservation, why an issue (Ricc Ferrante) Identifying the issues, developing guidelines (Nancy Adgent) Results of testing (Nancy Adgent, Lynda Schmitz Fuhrig) Review workflow and tools (Lynda Schmitz Fuhrig) Questions 10:30 – 10:45 Break 10:45 - 12:00 Exercise 1: Complete accession and processing forms (Nancy Adgent) Exercise 2: Convert msg to mbox via Aid4Mail (Nancy Adgent) Exercise 3: Convert pst to mbox via MessageSave (Lynda Schmitz Fuhrig) Exercise 4: Start AIP (Lynda Schmitz Fuhrig) 12:00 – 12:15 Questions 12:15 – 1:30 Lunch on your own (McConnell Hall cafeteria is a short walk from the class location) 1:30 – 3:00 Overview of technical issues (Ricc Ferrante) AIP post parsing (Ricc Ferrante) Why xml (Ricc Ferrante) Overview of parser (Steve Burbeck) How testbed message oddities contributed to development Collaboration with NC Demonstration of parser (Steve Burbeck) Questions 3:00 - 3:15 Break 3:15 - 4:15 Exercise 5: Convert mbox via parser (Steve Burbeck) Exercise 6: Complete AIP (Lynda Schmitz Fuhrig) DSpace Introduction (Ricc Ferrante) Exercise 7: Parse attendee’s messages Summary (Ricc Ferrante) 4:15 - 4:30 Questions 2 TABLE OF CONTENTS Page Exercise 1: Complete accession and processing forms . 25 Exercise 2: Convert msg to mbox via Aid4Mail . 39 Exercise 3: Convert pst to mbox via MessageSave . -

Code Injection Vulnerabilities in Web Applications - Exemplified at Cross-Site Scripting Martin Johns
Dissertation zur Erlangung des akademischen Grades eines Doktors der Naturwissenschaften Code Injection Vulnerabilities in Web Applications - Exemplified at Cross-site Scripting Martin Johns Eingereicht an der Fakult¨atf¨urInformatik und Mathematik der Universit¨atPassau Gutachter: Prof. Dr. Joachim Posegga Prof. Dr. Dieter Gollmann Submitted April 14th 2009, defended July 22nd 2009 2 Abstract The majority of all security problems in today’s Web applications is caused by string- based code injection, with Cross-site Scripting (XSS) being the dominant representative of this vulnerability class. This thesis discusses XSS and suggests defense mechanisms. We do so in three stages: First, we conduct a thorough analysis of JavaScript’s capabilities and explain how these capabilities are utilized in XSS attacks. We subsequently design a systematic, hierarchical classification of XSS payloads. In addition, we present a comprehensive sur- vey of publicly documented XSS payloads which is structured according to our proposed classification scheme. Secondly, we explore defensive mechanisms which dynamically prevent the execution of some payload types without eliminating the actual vulnerability. More specifically, we discuss the design and implementation of countermeasures against the XSS payloads “Session Hijacking”, “Cross-site Request Forgery”, and attacks that target intranet re- sources. We build upon this and introduce a general methodology for developing such countermeasures: We determine a necessary set of basic capabilities an adversary needs for successfully executing an attack through an analysis of the targeted payload type. The resulting countermeasure relies on revoking one of these capabilities, which in turn renders the payload infeasible. Finally, we present two language-based approaches that prevent XSS and related vul- nerabilities: We identify the implicit mixing of data and code during string-based syn- tax assembly as the root cause of string-based code injection attacks. -

Email Threats 2017
Internet Security Threat Report ISTR Email Threats 2017 An ISTR Special Report Analyst: Ben Nahorney October 2017 Contents Executive summary and key findings Malware Spambots BEC scams Spam User email behavior Protection and best practices Internet Security Threat Report Contents 3 Executive summary and key findings 5 Big numbers 7 Malware 8 Impact 9 Malware distribution 11 Spambots 12 Necurs 12 BlankSlate 12 Fioesrat 13 Silentbrute 13 Pandex 13 Oliner 13 Sarvdap 13 Emotet 13 Waledac 14 BEC scams 15 Latest trends 16 Beyond wire transfers 16 Typosquatting 16 Phishing Figures and Tables 16 Phishing scams of note 8 Email users targeted by malware per month 17 Spam 8 Percent of email users targeted by malware by industry 18 Advertising spam 9 Top three malicious email themes 19 Other distribution methods 10 Downloader detections by month 19 The cost of spam 10 URL malware rate 12 Necurs botnet activity 21 User email behavior 13 Waledac (Kelihos) botnet activity 23 Protection and best practices 15 BEC emails received per organization 24 Email security 15 Top subject lines in BEC scam emails 24 CloudSOC 16 Phishing rate 24 Download Insight 18 Spam rate by half year 24 Advanced antivirus engine 18 Spam campaign advertising pharmaceuticals 24 SONAR behavior engine 19 Bitcoin scam email 24 Ongoing development 19 Example Tofsee email 25 Best practices 19 The website Tofsee email links to 26 About Symantec 22 Broadly shared emails with sensitive information 26 More Information 22 Number of registered TLS email domains Internet Security Threat Report Executive summary and key findings Section 00 00 Executive summary and key findings Page 4 Email Threats 2017 Executive summary Key findings Email is everywhere. -

Internet Security (An Article from the Internet)
First National Bank Internet Security (An Article from the Internet) If terms such as 'phishing', 'zombies' and 'DoS' have you thrashing around in the dark, this article will help you get acquainted – and get the upper hand – with these and other online perils. Table of Contents 1. Introduction .............................................................................................................................................. 3 2. What Your Up Against ............................................................................................................................... 3 Viruses and worms .................................................................................................................................... 3 Adware, spyware and key loggers ............................................................................................................ 4 Phishing ..................................................................................................................................................... 5 Spam ......................................................................................................................................................... 5 Browser hijacking ...................................................................................................................................... 6 Family, friends and colleagues .................................................................................................................. 6 Zombies and DoS ..................................................................................................................................... -
Python-Receive-Email-Attachment
Python-receive-email-attachment Python-receive-email-attachment 1 / 2 Nov 27, 2019 — We'll be using the Python base64 module to read our file and encode it as a base64 string. I have used the fictional attachment.pdf file, so make .... Oct 14, 2020 — import win32com.client #pip install pypiwin32 to work with windows operating sysytm import datetime import os # To get today's date in .... Sep 14, 2017 — Sending and receiving emails automatically in Python ... for attachment in mail.attachments: f = open("attachments/" + attachment[0], "wb") .... 15 hours ago — AWS Boto3 Python Crash Course with AWS SES Tutorial ... I have shared the email screenshot that I have received via SES at the end of the .... Python receive email attachment. Parser import Parser as EmailParser from email. com' detach_dir = '. Sep 21, 2009 · #!/usr/local/bin/python ... ... fp.read() msg.add_attachment(img_data, maintype='image', subtype=imghdr.what(None, img_data)) # Send the email via our own SMTP server. with smtplib. python receive email attachment python receive email attachment, python read email attachment outlook, python get email attachment name 13 hours ago — In this video we share the script, with step by step explanation, for fetching the data from Outlook Application by python. Required ... 1 year ago.. Send and receive e-mails with Gmail's intuitive and efficient platform. ... allow less secure app Here. install python decouple pipenv install python-decouple. ... the standard email sending options such as to, from, subject, body, attachment, etc.. Feb 21, 2020 — The official dedicated python forum. ... Read today's all the email from a dedicated folder in outlook. -

Administrator's Guide
Trend Micro Incorporated reserves the right to make changes to this document and to the service described herein without notice. Before installing and using the service, review the readme files, release notes, and/or the latest version of the applicable documentation, which are available from the Trend Micro website at: https://docs.trendmicro.com/en-us/enterprise/email-security.aspx Trend Micro, the Trend Micro t-ball logo, Remote Manager, Apex Central, Cloud App Security, and Hosted Email Security are trademarks or registered trademarks of Trend Micro Incorporated. All other product or company names may be trademarks or registered trademarks of their owners. Copyright © 2021. Trend Micro Incorporated. All rights reserved. Document Part No.: APEM09182/210104 Release Date: September 9, 2021 Protected by U.S. Patent No.: Patents pending. This documentation introduces the main features of the service and/or provides installation instructions for a production environment. Read through the documentation before installing or using the service. Detailed information about how to use specific features within the service may be available at the Trend Micro Online Help Center and/or the Trend Micro Knowledge Base. Trend Micro always seeks to improve its documentation. If you have questions, comments, or suggestions about this or any Trend Micro document, please contact us at [email protected]. Evaluate this documentation on the following site: https://www.trendmicro.com/download/documentation/rating.asp Privacy and Personal Data Collection Disclosure Certain features available in Trend Micro products collect and send feedback regarding product usage and detection information to Trend Micro. Some of this data is considered personal in certain jurisdictions and under certain regulations.