Automatic Test Generation Based on Formal Specifications
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Shanghai Lumina Shanghai (100% Owned)
Artist’s impression LUMINA GUANGZHOU GUANGZHOU Artist’s impression Review of Operations – Business in Mainland China Progress of Major Development Projects Beijing Lakeside Mansion (24.5% owned) Branch of Beijing High School No. 4 Hou Sha Yu Primary School An Fu Street Shun Yi District Airport Hospital Hou Sha Yu Hou Sha Yu Station Town Hall Tianbei Road Tianbei Shuang Yu Street Luoma Huosha Road Lake Jing Mi Expressway Yuan Road Yuan Lakeside Mansion, Beijing (artist’s impression) Hua Li Kan Station Beijing Subway Line No.15 Located in the central villa area of Houshayu town, Shunyi District, “Lakeside Mansion” is adjacent to the Luoma Lake wetland park and various educational and medical institutions. The site of about 700,000 square feet will be developed into low-rise country-yard townhouses and high-rise apartments, complemented by commercial and community facilities. It is scheduled for completion in the third quarter of 2020, providing a total gross floor area of about 1,290,000 square feet for 979 households. Beijing Residential project at Chaoyang District (100% owned) Shunhuang Road Beijing Road No.7 of Sunhe Blocks Sunhe of Road No.6 Road of Sunhe Blocks of Sunhe Blocks Sunhe of Road No.4 Road of Sunhe Blocks Road No.10 Jingping Highway Jingmi Road Residential project at Chaoyang District, Beijing (artist’s impression) Huangkang Road Sunhe Station Subway Line No.15 Located in the villa area of Sunhe, Chaoyang District, this project is adjacent to the Wenyu River wetland park, Sunhe subway station and an array of educational and medical institutions. -

Development of High-Speed Rail in the People's Republic of China
A Service of Leibniz-Informationszentrum econstor Wirtschaft Leibniz Information Centre Make Your Publications Visible. zbw for Economics Haixiao, Pan; Ya, Gao Working Paper Development of high-speed rail in the People's Republic of China ADBI Working Paper Series, No. 959 Provided in Cooperation with: Asian Development Bank Institute (ADBI), Tokyo Suggested Citation: Haixiao, Pan; Ya, Gao (2019) : Development of high-speed rail in the People's Republic of China, ADBI Working Paper Series, No. 959, Asian Development Bank Institute (ADBI), Tokyo This Version is available at: http://hdl.handle.net/10419/222726 Standard-Nutzungsbedingungen: Terms of use: Die Dokumente auf EconStor dürfen zu eigenen wissenschaftlichen Documents in EconStor may be saved and copied for your Zwecken und zum Privatgebrauch gespeichert und kopiert werden. personal and scholarly purposes. Sie dürfen die Dokumente nicht für öffentliche oder kommerzielle You are not to copy documents for public or commercial Zwecke vervielfältigen, öffentlich ausstellen, öffentlich zugänglich purposes, to exhibit the documents publicly, to make them machen, vertreiben oder anderweitig nutzen. publicly available on the internet, or to distribute or otherwise use the documents in public. Sofern die Verfasser die Dokumente unter Open-Content-Lizenzen (insbesondere CC-Lizenzen) zur Verfügung gestellt haben sollten, If the documents have been made available under an Open gelten abweichend von diesen Nutzungsbedingungen die in der dort Content Licence (especially Creative Commons Licences), you genannten Lizenz gewährten Nutzungsrechte. may exercise further usage rights as specified in the indicated licence. https://creativecommons.org/licenses/by-nc-nd/3.0/igo/ www.econstor.eu ADBI Working Paper Series DEVELOPMENT OF HIGH-SPEED RAIL IN THE PEOPLE’S REPUBLIC OF CHINA Pan Haixiao and Gao Ya No. -

5G for Trains
5G for Trains Bharat Bhatia Chair, ITU-R WP5D SWG on PPDR Chair, APT-AWG Task Group on PPDR President, ITU-APT foundation of India Head of International Spectrum, Motorola Solutions Inc. Slide 1 Operations • Train operations, monitoring and control GSM-R • Real-time telemetry • Fleet/track maintenance • Increasing track capacity • Unattended Train Operations • Mobile workforce applications • Sensors – big data analytics • Mass Rescue Operation • Supply chain Safety Customer services GSM-R • Remote diagnostics • Travel information • Remote control in case of • Advertisements emergency • Location based services • Passenger emergency • Infotainment - Multimedia communications Passenger information display • Platform-to-driver video • Personal multimedia • In-train CCTV surveillance - train-to- entertainment station/OCC video • In-train wi-fi – broadband • Security internet access • Video analytics What is GSM-R? GSM-R, Global System for Mobile Communications – Railway or GSM-Railway is an international wireless communications standard for railway communication and applications. A sub-system of European Rail Traffic Management System (ERTMS), it is used for communication between train and railway regulation control centres GSM-R is an adaptation of GSM to provide mission critical features for railway operation and can work at speeds up to 500 km/hour. It is based on EIRENE – MORANE specifications. (EUROPEAN INTEGRATED RAILWAY RADIO ENHANCED NETWORK and Mobile radio for Railway Networks in Europe) GSM-R Stanadardisation UIC the International -

Of 5 Formula Rate
Page 1 of 5 Formula Rate - Non-Levelized Rate Formula Template - Attachment H-30A For the 12 months ended 12/31/19 Utilizing FERC Form 1 Data Transource Maryland, LLC (1) (2) (3) (4) (5) Line Allocated No. Source Amount 1 GROSS REVENUE REQUIREMENT, without incentives (page 3, line 49) $ 1,423,484 REVENUE CREDITS (Note A) Total Allocator 2 Account No. 454 (page 4, line 20) - TP 1.0000 - 3 Accounts 456.0 and 456.1 (page 4, line 21) - TP 1.0000 - 4 Revenues from Grandfathered Interzonal Transactions (Note B) - TP 1.0000 - 5 Revenues from service provided by the ISO at a discount - TP 1.0000 - 6 TOTAL REVENUE CREDITS (Sum of Lines 2 through 5) - - 7 Prior Period Adjustments Attachment 11 - DA 1.0000 - 8 True-up Adjustment with Interest Attachment 3, line 9, Col. G+H - DA 1.0000 - 9 Facility Credits under Section 30.9 of the PJM OATT Attachment 13 - DA 1.0000 - 10 NET ANNUAL TRANSMISSION REVENUE REQUIREMENT ( Line 1 less line 6 plus lines 7,8, and 9) $ 1,423,484 Page 2 of 5 Formula Rate - Non-Levelized Rate Formula Template - Attachment H-30A For the 12 months ended 12/31/19 Utilizing FERC Form 1 Data Transource Maryland, LLC (1) (2) (3) (4) (5) Transmission Line Source Company Total Allocator (Col 3 times Col 4) No. RATE BASE: (Note R) GROSS PLANT IN SERVICE Note C 1 Production 205.46.g for end of year, records for other months - NA - - 2 Transmission Attachment 4, Line 14, Col. (b) - TP 1.0000 - 3 Distribution 207.75.g for end of year, records for other months - NA - - 4 General & Intangible Attachment 4, Line 14, Col. -

The Perfect Choice for Hosting and Cloud Computing
KeChuang BaoShan JiuXianQiao WaiGaoQiao Beijing & Shanghai Cloud Data Centers The Perfect Choice for Hosting and Cloud Computing In the era of information explosion and rapid growth of data, enterprises’ data and IT infrastruture should be fully supported by round-the-clock managed services. With carrier-class Tier III+ telecommunications infrastructure standard and leveraging private network backbone and high-speed EtherCONNECT (Ethernet WAN connections) to interconnect cities in Mainland China, CITIC Telecom CPC’s DataHOUSE™ in Beijing and Shanghai serving as one-stop shop data centers, not only provide hosting or colocation services, but also highly scalable inter-city cloud computing, disaster recovery and remote backup services. HIGHLIGHTS Superior Locations High speed, High availability and Multiple The four cloud data centers are located in Chaoyang Network Connections and Yizhuang of Beijing, and PuDong and PuXi of • Carrier-neutral – interconnected with multiple telecom Shanghai, which are close to railway stations in the city operators for providing multiple connection options and easily reached. • Interconnections with large and middle-sized cities True Disaster Recovery (DR) and Backup within in mainland China through EtherCONNECT, up to and across Cities 10Gbps Full range of cloud resources, complement with highly • Provides high-speed and high-bandwidth Internet scalable cloud platform, for offering enterprises and private network connections, ranging from comprehensive intra-city and inter-city DR and backup 100Mbps to -

Development of High-Speed Rail in the People's Republic of China
ADBI Working Paper Series DEVELOPMENT OF HIGH-SPEED RAIL IN THE PEOPLE’S REPUBLIC OF CHINA Pan Haixiao and Gao Ya No. 959 May 2019 Asian Development Bank Institute Pan Haixiao is a professor at the Department of Urban Planning of Tongji University. Gao Ya is a PhD candidate at the Department of Urban Planning of Tongji University. The views expressed in this paper are the views of the author and do not necessarily reflect the views or policies of ADBI, ADB, its Board of Directors, or the governments they represent. ADBI does not guarantee the accuracy of the data included in this paper and accepts no responsibility for any consequences of their use. Terminology used may not necessarily be consistent with ADB official terms. Working papers are subject to formal revision and correction before they are finalized and considered published. The Working Paper series is a continuation of the formerly named Discussion Paper series; the numbering of the papers continued without interruption or change. ADBI’s working papers reflect initial ideas on a topic and are posted online for discussion. Some working papers may develop into other forms of publication. Suggested citation: Haixiao, P. and G. Ya. 2019. Development of High-Speed Rail in the People’s Republic of China. ADBI Working Paper 959. Tokyo: Asian Development Bank Institute. Available: https://www.adb.org/publications/development-high-speed-rail-prc Please contact the authors for information about this paper. Email: [email protected] Asian Development Bank Institute Kasumigaseki Building, 8th Floor 3-2-5 Kasumigaseki, Chiyoda-ku Tokyo 100-6008, Japan Tel: +81-3-3593-5500 Fax: +81-3-3593-5571 URL: www.adbi.org E-mail: [email protected] © 2019 Asian Development Bank Institute ADBI Working Paper 959 Haixiao and Ya Abstract High-speed rail (HSR) construction is continuing at a rapid pace in the People’s Republic of China (PRC) to improve rail’s competitiveness in the passenger market and facilitate inter-city accessibility. -
Global Transmission Report
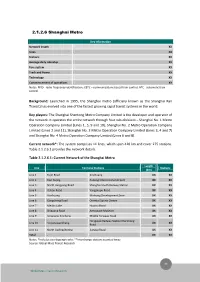
2.1.2.6 Shanghai Metro Key Information Network length XX Lines XX Stations XX Average daily ridership XX Fare system XX Track and Power XX Technology XX Commencement of operations XX Notes: RFID - radio-frequency identification; CBTC – communications based train control; ATC - automatic train control Background: Launched in 1995, the Shanghai metro (officially known as the Shanghai Rail Transit) has evolved into one of the fastest growing rapid transit systems in the world. Key players: The Shanghai Shentong Metro Company Limited is the developer and operator of the network. It operates the entire network through four sub-divisions – Shanghai No. 1 Metro Operation Company Limited (Lines 1, 5, 9 and 10), Shanghai No. 2 Metro Operation Company Limited (Lines 2 and 11), Shanghai No. 3 Metro Operation Company Limited (Lines 3, 4 and 7) and Shanghai No. 4 Metro Operation Company Limited (Lines 6 and 8). Current network*: The system comprises 11 lines, which span 420 km and cover 275 stations. Table 2.1.2.6.1 provides the network details. Table 2.1.2.6.1: Current Network of the Shanghai Metro Length Line Terminal Stations Stations (km) Line 1 Fujin Road Xinzhuang XX XX Line 2 East Xujing Pudong International Airport XX XX Line 3 North Jiangyang Road Shanghai South Railway Station XX XX Line 4 Yishan Road Yangshupu Road XX XX Line 5 Xinzhuang Minhang Development Zone XX XX Line 6 Gangcheng Road Oriental Sports Centre XX XX Line 7 Meilan Lake Huamu Road XX XX Line 8 Shiguang Road Aerospace Museum XX XX Line 9 Songjiang Xincheng Middle Yanggao Road XX XX Hongqiao Railway Station/Hanzhong Line 10 Xinjiangwancheng XX XX Road Line 11 North Jiading/Anting Jiangsu Road XX XX Total - - XX XX Notes: *Includes overlapping tracks; **Interchange stations counted twice Source: Global Mass Transit Research 44 Global Mass Transit Research Ridership: In 2010, the system carried 1.9 billion passengers, translating into an average daily ridership of 5.2 million passengers. -

Reviving MILWAUKEE Through Light Rail
THE INTERNATIONAL LIGHT RAIL MAGAZINE www.lrta.org www.tautonline.com FEBRUARY 2019 NO. 974 REVIVING MILWAUKEE THROUGH LIGHT RAIL China opens two new tramways and 372km of metro Lisboa tram overturns injuring 28 Projects on hold due to TfL shortfall Ulm opens line 2 to double its tramway Sounds of silence Tram-train £4.60 Managing light rail Lessons shared from noise and vibration the UK pilot scheme “I am delighted that the UK Light Rail Conference is coming back to Greater Manchester in 2019. “Metrolink forms a key backbone of sustainable travel for the region as it continues to grow, so this important two-day event offers an invaluable chance to network with peers from around the world and share knowledge and best practice as we all aim to improve the way we plan, build and deliver exceptional light rail services to passengers.” Manchester Danny Vaughan 23-24 July 2019 head of Metrolink – transport for Greater Manchester “An excellent event, providing a stimulating and varied two-day programme addressing current The industry’s premier exhibition and knowledge-sharing and future issues pertinent to Voices event returns to Manchester for 2019! today’s light rail industry” V from the clive Pennington With unrivalled networking opportunities, this invaluable technical Director – Light rail, industry… two-day congress is well-known as the place to do amey consulting & rail business and build long-lasting relationships. There is no better place to gain true insight into the “I thought the whole conference was great – there was a workings of the sector and help shape its future. -

Identifying Organizational and Contractual Drivers Behind Metro Accidents in Shanghai
IDENTIFYING ORGANIZATIONAL AND CONTRACTUAL DRIVERS BEHIND METRO ACCIDENTS IN SHANGHAI Yue Chen, 4181166 Construction Management and Engineering Faulty of Civil Engineering Technology University of Delft November 2013 0 ABSTRACT In recent years, China has witnessed rapid development in urban transportation, especially in metro projects. However the safety records of metro projects is rather worrying and cannot help to make us think where actually is going wrong. Official reports have claimed that the causes for those metro accidents are mainly from technical and organizational aspects. But are the reports really telling the true story? Or are there deeper reasons that lead to accidents which are not so obvious? In previous studies, Martin de Jong and Yongchi Ma have asked the same question. They conduct their research on three Chinese cities of Beijing, Hangzhou and Dalian through Jens Rasmussen’s safety theory: drift to safety boundaries. In this theory, various incentives drive stakeholders to trade off quality and safety for other core values, resulting in safety boundaries to be crossed. All three cities represent a certain extent of profit driven, excessive subcontracting and loose monitoring which rightly match what is described in Rasmussen’s theory. In my study, I will take the city Shanghai as an example to do a replicative research following Martin de Jong and Ma Yongchi’s work. Based on the main research question of searching for the contractual and organizational arrangements in metro accidents, firstly Rasmussen’s theory will be discussed in Chapter 2 to lay a theoretical underpinning for latter research. Secondly the development of Shanghai metro system will be introduced to provide background information for latter case studies. -

Global Mass Transit Report Information and Analysis on the Global Mass Transit Industry
NOVEMBER 2009 VOLUME I, ISSUE 1 Global Mass Transit Report Information and analysis on the global mass transit industry Contactless Ticketing in Mass Transit Mass Transit in South Africa A win-win solution for all stakeholders Governments invest heavily in transport infrastructure ith its myriad of advantages such as lower transaction costs, faster transaction speeds and multi-functionality, W s governments around the world acknowledge the contactless smart ticketing is the future of the global mass- important role that public transport plays in improving the transportation industry. Already operational in key metropolitan A quality of life, there is a global trend for increased investment in areas such as Hong Kong, London, Seoul, Washington D.C. and this important infrastructure sector. A commitment to upgrade Shanghai, contactless smart ticketing offers a win-win solution and expand mass transit systems has risen across the Americas, for transit operators and users, contactless technology developers Europe, Asia, and now in Africa as well. Taking the lead in Africa and financial institutions. is its biggest economy South Africa. Today, virtually all transit-fare payment systems in the For many years, South Africa boasted of the best transport delivery and procurement stages are opting for contactless infrastructure in the African continent. However, over the last ticketing as the primary medium. India’s Mumbai metro, which few years the transport infrastructure has been deteriorating. This is expected to become operational in 2011, will be equipped with is essentially owing to short sightedness and lack of continued a system based on contactless technology with reusable smart investment. It is only now that the transport sector has begun tickets. -

Flood Risk Assessment of Subway Systems in Metropolitan Areas Under Land Subsidence Scenario: a Case Study of Beijing
remote sensing Article Flood Risk Assessment of Subway Systems in Metropolitan Areas under Land Subsidence Scenario: A Case Study of Beijing Guangpeng Wang 1,2,3 , Yong Liu 1,2,3, Ziying Hu 1,2,3, Guoming Zhang 1,2,3, Jifu Liu 1,2,3, Yanli Lyu 1,2,3, Yu Gu 1,2,3, Xichen Huang 1,2,3, Qingyan Zhang 1,2,3 and Lianyou Liu 1,2,3,* 1 Key Laboratory of Environmental Change and Natural Disaster, Ministry of Education, Beijing Normal University, Beijing 100875, China; [email protected] (G.W.); [email protected] (Y.L.); [email protected] (Z.H.); [email protected] (G.Z.); [email protected] (J.L.); [email protected] (Y.L.); [email protected] (Y.G.); [email protected] (X.H.); [email protected] (Q.Z.) 2 Engineering Research Center of Desertification and Blown-sand Control, Ministry of Education, Beijing Normal University, Beijing 100875, China 3 Faculty of Geographical Science, Academy of Disaster Reduction and Emergency Management, Beijing Normal University, Beijing 100875, China * Correspondence: [email protected]; Tel.: +86-10-58802600 Abstract: Flooding is one of the most destructive natural events that severely damage the ground and inundate underground infrastructure. Subway systems in metropolitan areas are susceptible to flooding, which may be exacerbated when land subsidence occurs. However, previous studies have focused on flood risk evaluation on regional/watershed-scales and land subsidence monitoring in plains, instead of on subway flood risk evaluation and how land subsidence aggravates the flood risk in subway systems. -
Annual Report 2020 3
International Community, Tianjin Contents Board of Directors and Committees 2 Directors and Organisation 76 Corporate Information 3 Sustainable Development 86 Shareholders’ Information and Financial Calendar 4 Accolades & Awards 2020 96 Corporate Structure 5 Investor Relations 98 Financial Highlights 6 Corporate Governance Report 100 Group Financial Summary 8 Report of Directors 119 2020 Business Milestones 9 Financial Information Chairman’s Statement 14 Independent Auditor’s Report 147 Management Discussion and Analysis Consolidated Income Statement 153 Overall Performance 21 Consolidated Statement of Comprehensive Income 154 Property Development 22 Consolidated Statement of Financial Position 155 Commercial Properties 48 Consolidated Statement of Changes in Equity 157 Other Property-Related Operations 58 Consolidated Statement of Cash Flows 159 Land Reserves 62 Notes to the Financial Statements 161 Group Finance 71 Five Year Financial Summary 253 Others 75 2 China Overseas Land & Investment Ltd. Board of Directors and Committees EXECUTIVE DIRECTORS AUDIT AND RISK MANAGEMENT COMMITTEE Yan Jianguo Chairman Luo Liang Vice Chairman Li Man Bun, Brian David* Zhang Zhichao Chief Executive Officer Fan Hsu Lai Tai, Rita Guo Guanghui Vice President Chan Ka Keung, Ceajer NON-EXECUTIVE DIRECTORS REMUNERATION COMMITTEE Zhuang Yong Vice Chairman Chan Ka Keung, Ceajer* Chang Ying Fan Hsu Lai Tai, Rita Li Man Bun, Brian David INDEPENDENT NON-EXECUTIVE DIRECTORS NOMINATION COMMITTEE Fan Hsu Lai Tai, Rita Fan Hsu Lai Tai, Rita* Li Man Bun, Brian David