Optical Character Recognition (Ocr) for Telugu: Database, Algorithm and Application
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Movie 9 As a Science Fiction and Gothic Horror
International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-8 Issue-7C May 2019 Movie 9 as a Science Fiction and Gothic Horror Sreelakshmi J, Sreenath Muraleedharan Abstract: This paper analyses how Pritviraj portrays the experienced a psychotic break that has dissociative sol entity theme of the movie 9 -How a psychoanalytic person creates disorder by being Ava. Soon he realise Adam is missing and various problem in his life. The Abstract and concrete themes of approaches the monastery for help. There he learns to trace the novel can be categorised under the gothic and scientific back his lost memories and come face to face with Ava elements ;are meticulously analysed to show the novelists again. This time he confuses his true love for his son and acumen in establishing the strong bond between the man and universe. This bond and the subsequent interdependence help to Ava transforms into Annie to show him the way to Adam. In initiate the quiet and deep rooted desires of the individual. the end, Albert finds Adam in the cave unharmed. The film Keywords: Comet, space,omen,astrophysics,scientists, ghost. ends with the reconciliation between the father and the son. The question of whether Ava is real or not is left to the I. INTRODUCTION imagination of the audience. In the scene after the credits, the camera focuses on the painting in the cave where there is The sci-fi Malayalam movie 9, by Jenuse Mohammed a picture that looks the same as Ava. Thus the truth about highlights the genre of horror and thriller parallel to each Ava’s origin remains a mystery. -

3.Ijece-Survey Paper of Script Identification
International Journal of Electronics and Communication Engineering (IJECE) ISSN(P): 2278-9901; ISSN(E): 2278-991X Vol. 8, Issue 3, Apr - May 2019; 15-20 © IASET SURVEY PAPER OF SCRIPT IDENTIFICATION OF TELUGU LANGUAGE USING OCR B. Hari Kumar 1 & P. Chitra 2 1Reserch Scholar, Department of ECE, Sathyabama Institute of Science and Technology, Chennai,India 2 Professor, Department of ECE, Sathyabama Institute of Science and Technology, Chennai, India ABSTRACT This study provides a summary of the ongoing research and the development process of the optical character recognition (OCR) systems for Devanagari text. A file may contain words in more than a language in a multilingual country like India. Multilingual Optical Character Recognition (OCR) system is required for a multilingual environment to read the multilingual documents. The objective of OCR is an automatic reading of the optically sensed document to interpret human-readable fonts into machine-readable code. Reading of Devanagari script is still a challenging task as various approaches are available for Chinese, English, and Japanese for script acknowledgement to get 100 percent accuracy. A survey has been done on Telugu OCR System. Recognition involves character segmentation into the elements of the component and recognizing them. A heuristic method has been selected as the best classifier for the current work based on the identification precisions of multiple classifiers. In this article, a heuristic approach is developed for separation, feature extraction and recognition of Devanagari script. The subsequent portion of this paper would explain the development that has been made in OCR System application for Devanagari Script reorganization and for the future work’s scope in Devanagari OCR systems. -

Ved-Prakash-Sharma-Hindi-Novel-Free-Download.Pdf
1 / 4 Ved Prakash Sharma Hindi Novel Free Download To download HINDI NOVELS VED PRAKASH SHARMA PDF, click on the Download button Content rating: Medium Maturity From Creative Canine LLC: The .... Apr 22, 2018 — Ved Prakash Sharma Hindi Novel Free Download ... All the content presented here are found from various blogs and forums. The owner of this .... Ved Prakash Sharma was an Indian writer of novels and screenplays in Hindi. He was born in Meerut, Uttar Pradesh, where he completed his graduation from .... Marathi Books - Akshardhara. My wishlists · My Account · Sign in .... Jun 7, 2021 — Ved prakash sharma novels free download pdf - PngLine. Ved Prakash Sharma Novel Free In Vijay Vikas In Hindi By comixtream On Feb 23, .... Raj Comics is an Indian comic book publisher. It published a line of Indian comic books through ... Their comics are usually published in Hindi, with only a few titles and special editions in English. ... Media Lab. The resulting research was published as a free PDF on the Sarai website. ... Download as PDF · Printable version .... Free download ek thappad hindustani ved prakash sharma hindi novel pdf format : pdf language : hindi pages : 289 size : 27. Ved prakash sharma' s most popular .... Feb 15, 2021 — Vardi Wala Gunda by Ved Prakash Sharma Free Hindi Book |. ... Free Download Kanoon Ka Pandit Ved Prakash Sharma Hindi Novel Pdf ... Hindi-novels-of-vedprakash-sharma-free-download-pdf - Hindi novels of vedprakash sharma free download pdf. List of ebooks and manuels about Hindi novels .... Ved prakash sharma hindi novel download site. Sagar bhai ye novels to download hi nhi hote ab phle wala system accha tha. -

An Introduction to Hinduism
A guide to various aspects of Indian religious thought and inter-religious understanding and religious tolerance. "Its chief mark consists in concentration on the spiritual aspect, belief in the intimate relationship of philosophy and life, the inseparability of theory and practice and the insistence on intuition coexisting with the acceptance of authority." I have summarised and rearranged the material so that some of them could more easily and logically fit into the sub-headings I have created for the western readers of my Web-site. Otherwise the contents of the original text remains unchanged except a few amendments and correction I have made. Your suggestion, comments and criticisms are greatly appreciated. Giessen, 17 November 1999 Prakash Arumugam - AN INTRODUCTION TO HINDUISM by Dr C.P.Ramaswami Aiyar, Dr Nalinaksha Dutt, Prof. A.R.Wadia, Prof. M.Mujeeb, Dr Dharm Pal and Fr. Jerome D'Souza, S.J. · * * * * Source: The Gazetteer of India, Volume 1: Country and people. Delhi, Publications Division, Government of India, 1965. "CHAPTER Vlll - Religion " An introduction to Hinduism - 1 - copy right © 1999-2000 Prakash Arumugam An Introduction It has been pointed out by Dr. Arnold J. Toynbee1, in A Study of History, that the principal civilisations of the world lay different degrees of emphasis on specific lines of activity. Hellenic civilisation, for instance, displays a manifest tendency towards a prominently aesthetic outlook on life as a whole. Indian civilisation, on the other hand, shows an equally manifest tendency towards a predominantly religious outlook. Dr. Toynbee's remark sums up what has been observed by many other scholars. -

Directorate of Film Festivals Announces Winners for the 67Th Edition of the National Film Awards for 2019
Directorate of Film Festivals announces winners for the 67th edition of the National Film Awards for 2019 The Directorate of Film Festival of India has announced the 67th National Film Awards at a press conference by the eminent panel of Shri N. Chandra, Chairman, Central Panel for Feature Films Jury, Shri Arun Chaddha, Chairman, Non-Feature Films Jury, Shri Shaji N Karun, Chairman, Most Film Friendly State Jury and Shri Saibal Chatterjee, Chairman Best Writing on Cinema Jury. The Chairpersons and other Jury Members, ahead of the press meet, submitted a report on the 67th National Film Awards to Union Minister of Information and Broadcasting, Government of India, Shri Prakash Javadekar. A complete list of the awards is given below. 67th National Film Awards, 2019 Most Film Friendly State Award Sr. No. State Medal Rajat Kamal & Certificate 1 Sikkim 67th National Film Awards, 2019 Best Writing on Cinema Award for Best Book on Cinema: Name of the Medal and Cash Sr. No. Title of the Book Language Name of the Author Publisher prize A GANDHIAN AFFAIR: INDIA’S CURIOS PORTRAYAL OF HarperCollins Swarna Kamal and LOVE IN Publishers Rs. 75,000/- 1 CINEMA English Sanjay Suri India Special Mention: Sr. No. Title of the Book Language Name of the Author Award CINEMA PAHANARA 1 MANUS Marathi Ashok Rane Certificate KANNADA CINEMA: JAGATHIKA CINEMA VIKASA-PRERANE- Certificate 2 PRABHAVA Kannada P R Ramadasa Naidu Award for Best Film Critic: Sr. No. Name of Critic Language Medal and Cash Prize Swarna Kamal and Rs. 75,000/- 1 Sohini Chattopadhyay English 67th National Film Awards, 2019 Non-Feature Films Section Medal & S.No. -

Zuban-E Urdu-E Mu'alla and the Idol of Linguistic Origins1
Zuban-e Urdu-e Mu‘alla and the Idol of Linguistic Origins1 I as a bounded entity to be located in dic- tionaries, grammar books, a literary canon and, most important, a “community” of human beings who can be counted and located on a map—all these are developments that emerged in nineteenth-century India and distort our understanding of earlier times. Naming one such language “Urdu” was itself an historical event in this process. It is a name that took some time to enter common usage and in certain quarters has remained problematic. What counts as Urdu as opposed to Hindi, Hindi- Urdu, Hirdu, Hindustani, Hindusthani and a number of so-called lan- guages, dialects and speech varieties has been a matter of highly charged controversy for a long time. The Turkish word urd∑, as a military encampment, appears in Indo- Muslim texts from the middle of the twelfth century. Babar in the sixteenth century refers to his own urd∑-e mu‘all≥, the exalted camp. But the word is not explicitly associated with language until the middle of the eighteenth century. It was then that Arzu, Mir and others began to use phrases like zub≥n-e urd∑-e sh≥hµ,2 zub≥n-e urd∑-e mu‘all≥, or, more modestly, mu√≥vara-e urd∑-e mu‘all≥—the idiom of the exalted camp. And only at the end of the century do scholars begin to find scattered references to the word urd∑ alone as a metonym for a language, which is 1An earlier version of this paper was presented at the South Asia Conference, University of Wisconsin, November , . -

GC Kids 13, Reaching Hindus.Pub
GREAT COMMISSION KIDS “Hey Kids, Let’s Talk !” Do you have a comment or question about missions or about something you read in this G KIDS issue? Email [email protected] Or send a letter to: By Linda Dingeldein C Issue 13: Reaching Hindus GC Kids - Let’s Talk 1431 Stuckert Rd Telling about the Warrington, PA 18976-2851 U.S.A. one true God Reaching Hindus Some religions, like the For Jesus Hindu religion, think Remember—Pray that many Hindus will there are many gods. become Christians! We must tell them the truth about the one true God! That is what this issue of “GC Kids” is GC KIDS is for children ages about 9 to 13. It aims to nurture a passion for about. As you read the missions that will encourage children to be active in the Great Commis- stories, think about sion throughout their lives. what the disciple John This quarterly publication is mailed free to individual children or adult said was the reason he leaders of children. (For multiple copies see the information below.) wrote about Jesus: For suggestions, ideas or submissions , send postal mail via the ad- John said, dress below or email [email protected]. “Jesus did many other miraculous To subscribe , email [email protected], subject line: “GC EE Pioneer Missionaries ——— FR Kids subscription” or fill in this form and mail it to GC Kids c/o signs in the presence John and Jessie Whipple World Team, 1431 Stuckert Rd., Warrington, PA 18976. of his disciples, which are not Name _____________________________________________________________ n 1912, only two weeks after they heard recorded in this I Address _____________________________________________________________ book. -

Unpaid Dividend Data-2016-17 Final As at 31.3.2019
HEIDELBERGCEMENT INDIA LIMITED UNCLAIMED / UNPAID FINAL DIVIDEND FOR 2016-17 (FINAL) AS AT 31.3.2019 DIV_YEAR FOLIO / DPID_CLID NAME_1 ADDRESS SHARES DIVIDEND WAR_NO MICR_NO DIVIDEND_DATE PROPOSED DATE OF AMOUNT (RS) TRANSFER IEPF 2016-17 (FINAL) IN30096610090890 CAPITAL MERCHANTS PRIVATE LIMITED 2778/21 HAMILTON ROAD MORI GATE DELHI 110006 1000 2000.00 11 567 26-SEP-2017 28-OCT-2024 2016-17 (FINAL) A003410 MANOJ AGARWAL C/O K L AGARWALA & SONS 4124 NAYA BAZAR DELHI NEW DELHI 110006 1400 2800.00 12 568 26-SEP-2017 28-OCT-2024 2016-17 (FINAL) A003747 MANOJ KUMAR AGARWALA K L AGARWALA AND SONS 4124 NAYA BAZAR DELHI NEW DELHI 110006 1100 2200.00 13 569 26-SEP-2017 28-OCT-2024 2016-17 (FINAL) B000066 BHAGIRATHMAL MERCHANT C/O M/S RAMJI LAL RAMSAROOP HAUZ QAZI DELHI NEW DELHI 110006 865 1730.00 15 571 26-SEP-2017 28-OCT-2024 2016-17 (FINAL) S002835 SWARCH MAHAJAN 610-A POCKET A SARITA VIHAR NEW DELHI NEW DELHI 110044 757 1514.00 22 578 26-SEP-2017 28-OCT-2024 2016-17 (FINAL) IN30096610270678 VANITA JAIN B-227 (FIRST FLOOR) ASHOK VIHAR PHASE-I DELHI 110052 1000 2000.00 24 580 26-SEP-2017 28-OCT-2024 2016-17 (FINAL) K001842 ROSHAN LAL KOHLI C/O VEENA EAGLETON (IAS) 16 SECTOR 7-A CHANDIGARH (UT) CHANDIGARH 160019 2120 4240.00 35 591 26-SEP-2017 28-OCT-2024 2016-17 (FINAL) V003451 VISHNU PRASAD DUBEY C/O JAIPRAKASH ASSOCIATES LTD 618 KRISHNA TOWER CIVIL LINES KANPUR 208001 1000 2000.00 38 594 26-SEP-2017 28-OCT-2024 2016-17 (FINAL) IN30169610637942 INDIRA AGARWAL NO 7/20/D TILAK NAGAR PARWATI BALLA ROAD KANPUR 208002 2450 4900.00 39 595 26-SEP-2017 28-OCT-2024 2016-17 (FINAL) IN30155720484683 MEENA RASTOGI 228/85 CHANDRA LOK BULIDING RAZA BAZAR LUCKNOW 226003 1000 2000.00 46 602 26-SEP-2017 28-OCT-2024 2016-17 (FINAL) IN30055610268974 MOHD. -
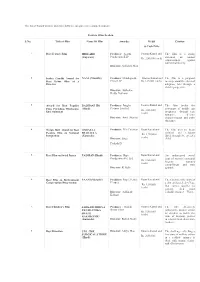
The List of Award Winners Under the Different Categories Is Mentioned As Under
The list of Award winners under the different categories is mentioned as under: Feature Films Section S.No. Title of Film Name Of Film Awardee Medal Citation & Cash Prize 1. Best Feature Film HELLARO Producer: Saarthi Swarna Kamal and The film is a strong (Gujarati) Productions LLP statement on women Rs. 2,50,000 (each) empowerment against patriarchal Society. Director: Abhishek Shah 2. Indira Gandhi Award for NAAL (Marathi) Producer: Mrudhgandh Swarna Kamal and The film is a poignant Films LLP Rs.1,25,000 (each) message about the ethics of Best Debut Film of a Director adoption, told through a child‟s perspective. Director: Sudhakar Reddy Yakkanti 3. Award for Best Popular BADHAAI HO Producer: Junglee Swarna Kamal and The film breaks the (Hindi) Pictures Limited stereotype of middle age Film Providing Wholesome Rs. 2,00,000/- Entertainment pregnancy through easy (each) narrative, effective Director: Amit Sharma characterization and pithy dialogues. 4. Nargis Dutt Award for Best ONDALLA Producer: D N Cinemas Rajat Kamal and The film tries to break Feature Film on National ERADALLA political and religious Rs. 1,50,000/- Integration (Kannada) divide through the eye of a (each) Director: Satya child. Prakash D 5. Best Film on Social Issues PADMAN (Hindi) Producer: Hope Rajat Kamal and An undiscussed social Productions Pvt. Ltd. issue of women‟s personal Rs. 1,50,000/- hygiene narrated (each) compellingly and with Director: R. Balki aplomb. 6. Best Film on Environment PAANI (Marathi) Producer: Purple Pebble Rajat Kamal and The film traces the story of Conservation/Preservation Pictures a dry and parched village Rs. -

SYLLABUS Class – B.A. (HONS.) MASS COMMUNICATION VI Semester Subject – Film Journalism UNIT – I the Birth of Cinema Lumie
B.A. (HONS.) Mass Communication VI Semester Subject – Film Journalism SYLLABUS Class – B.A. (HONS.) MASS COMMUNICATION VI Semester Subject – Film Journalism UNIT – I The birth of cinema Lumier brother’s package The Grand father of Indian cinema: Dada Saheb Phalke The silent era (1896-1930) The talkie era and decade wise trend up to 1990 The new trends in Indian cinema (1991-2007) UNIT – II The brief study and analysis of trend setter film directors V ShantaramSohrab ModiMehboob KhanVijay BhattWadia brothersRaj KapoorGuruduttBimal RoySatyajit RayB. R. Chopra Yash ChopraHrishikesh Mukherjee Chetan Anand Basu Chaterjee Sai ParanjapeGuljarBasu BhattacharyaMahesh Bhatt Ramesh SippyShyam BenegalKetan MehtaGovind Nihlani Suraj BarjatyaVidhu Vinod ChopraJ P DuttaSanjay Leela Bhansali Ramgopal VermaKaran JojarAditya Chopra Raj kumar santoshi Rakesh Mehra Rj kumar Hirani UNIT – III Film as an art Film and painting Film and theatre Film and literature Film and music UNIT – IV Film language and grammar (A)Shot, scene & cut, (B)Camera Distance, (C) Camera Angles, (D)Camera movements (E) Lighting (F) Sound in films (G) Film Editing devices Film institutions in India Film festivals (National and International) Film awards Film censorships 45, Anurag Nagar, Behind Press Complex, Indore (M.P.) Ph.: 4262100, www.rccmindore.com 1 B.A. (HONS.) Mass Communication VI Semester Subject – Film Journalism UNIT I THE BIRTH OF CINEMA The Lumiere brothers were born in Besancon, France, in 1862 and 1864, and moved to Lyon in 1870. This is where they spent most of their lives and where their father ran a photographic firm. The brothers worked there starting at a young age but never started experimenting with moving film until after their father had died in 1892.The brothers worked on their new film projects for years, Auguste making the first experiments. -

A View from Afar (South Asia)— an Interview with Gyan Prakash
A VIEW FROM AFAR (SOUTH ASIA)— AN INTERVIEW WITH GYAN PRAKASH • Robert Borofsky: One of the key questions regarding the colonial period is how to write about it. Both Sahlins and Kituai use colonial documentation to discuss the complex ways various parties were en- tangled. To what extent do you think it is possible to write about the colonial period without staying within the silences and framings of the data collected by the colonial regimes—without getting entangled, that is to say, in the colonial entanglements themselves? • Gyan Prakash: To begin with, one cannot simply use colonial documents as repositories of information. One needs to take into account not only the purposes for which they were produced but also how and why they were preserved. Secondly, one must read them for the kind of knowledge they authorize, a point Sahlins and Kituai are both concerned with. One needs to pay attention to the ruling con- cepts of the documents, to what they render thinkable as well as to what they imply is unthinkable. If I were to put it in Foucaultian terms, one needs to consider the type of truth regime the documents establish. Rather than claiming an all-seeing eye—that allows one to grasp what colonial officials could not—the intent would be to make the documents confront their own contradictions, their own silences. I do not mean the object should be to fill in the silences as a sort of com- pensatory history, to give the colonized a voice denied them by colo- nialism. Instead I would make the silences, contradictions, and am- biguities essential elements in the colonial story. -
Aryas Unbound: Print Hinduism and the Cultural Regulation of Religious Offense
TSPACE RESEARCH REPOSITORY tspace.library.utoronto.ca Version: Postprint (Accepted Manuscript) 2015 Aryas Unbound: Print Hinduism and the Cultural Regulation of Religious Offense J. Barton Scott The Accepted Manuscript (AM), the final draft of this author manuscript, is licensed under Attribution-NonCommercial-NoDerivatives 4.0 International (CC BY-NC-ND 4.0). To view the details of this license, visit https://creativecommons.org/licenses/by-nc-nd/4.0/ Permanent link of this paper: http://hdl.handle.net/1807/95440 Important Notes Always cite the Version of Record (VoR: final publisher’s version)so that the author(s) will receive recognition through services that track citation counts, e.g., Scopus. When you are unable to access the VoR, the citation needs to include the word, Postprint (Accepted Manuscript). Visit Publisher’s Site for the VoR: https://doi.org/10.1215/1089201x-3139072 This is an Accepted Manuscript of an article published by Duke University Press in Comparative Studies of South Asia, Africa, and the Middle East in August 2015, available online: https://doi.org/10.1215/1089201x-3139072 Aryas Unbound: Print Hinduism and the Cultural Regulation of Religious Offense J. Barton Scott1 1 Department of Historical Studies and Department for the Study of Religion, University of Toronto, Toronto, ON, Canada ABSTRACT This article analyzes a controversial book ban from the 1940s to trace the mutual determinations of print media, the legal regulation of communal sentiment, and the discourse of religious tolerance in late colonial India. Claimed as the Bible of the Arya Samaj, the Satyarth Prakash (The Light of Truth) was banned in the Muslim-majority province of Sindh due to its defamatory remarks about the Prophet Muhammad.