An Application of Pruning in the Design of Neural Networks for Real Time flood Forecasting
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Aziende Sanitarie Della Regione Autonoma Friuli Venezia Giulia
All. 1 Aziende sanitarie della Regione Autonoma Friuli Venezia Giulia ELENCO DEGLI AMBITI TERRITORIALI CARENTI DI MEDICI DI MEDICINA GENERALE DI ASSISTENZA PRIMARIA PER L’ANNO 2019 AZIENDE SANITARIE AMBITI TERRITORIALI CARENTI MEDICI ASUI di Trieste Ambito territoriale del comune di 8* via G. Sai, 1-3 Trieste 34128 TRIESTE *di cui n. 4 incarichi con le seguenti decorrenze: -n.1 incarico dal 1.4.2019 -n.1 incarico dal 4.8.2019 -n.1 incarico dal 1.9.2019 -n.1 incarico dal 29.11.2019 Ai sensi dell’art. 34, comma 2, del vigente, n. 6 degli 8 incarichi sono vincolati all’apertura dell’ambulatorio nei seguenti territori: -n. 1 incarico nel Distretto n. 1- III Circoscrizione, rione di Gretta; - n. 1 incarico nel Distretto n. 1 – II Circoscrizione, rione Villa Opicina; - n. 3 incarichi nel Distretto n. 3 – VII Circoscrizione, rione S.M.M. Inferiore; n. 1 incarico nel Distretto n. 4 – VI Circoscrizione, rione Chiadino. Ambito del Consorzio del Comune di 1* Duino Aurisina * con decorrenza 1.4.2019 AAS n. 2 “Bassa Friulana-Isontina” Ambito territoriale dei comuni di 1 Via Vittorio Veneto, 174 Doberdò del Lago, Fogliano 34170 GORIZIA Redipuglia, Ronchi dei Legionari, San Canzian d’Isonzo, San Pier d’Isonzo e Turriaco Ambito territoriale dei comuni di 1 Aquileia, Fiumicello-Villa Vicentina, (vincolo di ambulatorio nel comune di Aquileia) Terzo d’Aquileia Ambito territoriale del comune di 1 Cervignano del Friuli Ambito territoriale dei comuni di 1 1 All. 1 Carlino, Marano Lagunare, Porpetto, San Giorgio di Nogaro, Torviscosa Ambito territoriale dei comuni di Farra 1* d’Isonzo, Gradisca d’Isonzo, Romans d’Isonzo, Sagrado e Villesse * con decorrenza 2.12.2019 AAS n. -

Inaugurazione Monumento All'emigrante
ANNO 7 - NUMERO 14 - DICEMBRE 2011 WWW.COMUNE.RAGOGNA.UD.IT SEMESTRALE DI INFORMAZIONE DEL COMUNE DI RAGOGNA - DISTRIBUITO GRATUITAMENTE A TUTTE LE FAMIGLIE DEL COMUNE STAMPATO SU CARTA RICICLATA AUTORIZZAZIONE DEL TRIBUNALE DI UDINE NUMERO 9 DEL 12/3/2005 EDITORIALE INAUGURAZIONE MONUMENTO ALL'EMIGRANTE GRANDE FESTA SUL MONTE DI RAGOGNA VENERDÌ 5 AGOSTO QUANDO OLTRE UN MIGLIAIO DI PERSONE HA POTUTO ASSISTERE CON EMOZIONE E COMMOZIONE ALLO SCOPRIMENTO DEL TANTO ATTESO MONUMENTO ALL'EMIGRANTE CHE I FRATELLI ARRIGO E MARIO COLLAVINO HANNO VOLUTO REGALARE ALLA COMUNITÀ DI RAGOGNA Era la folla delle grandi occasioni quella che per sempre l'operosità della nostra gente che ha salito le pendici del nostro monte per ovunque nel mondo si è fatta apprezzare e assistere ad un evento annunciato da tempo benvolere. e che aveva accresciuto settimana dopo E i fratelli Collavino hanno voluto realizzare settimana la frenesia dell'attesa. tutto questo per donarlo al Comune di Rago- Hanno lavorato sodo i volontari del Gruppo gna e quindi a tutta la nostra comunità che ha Alpini di Muris per realizzare il basamento molto apprezzato il gesto e che è accorsa in su cui è stata collocata una statua in bronzo massa all'inaugurazione del Monumento. raffigurante un emigrante con la valigia in La cerimonia si è tenuta nel piazzale anti- mano che si incammina verso le strade di stante la baita del Gruppo Alpini ed ha visto tutto il mondo. La statua è collocata giust'ap- la grande e prestigiosa partecipazione di punto su un globo in cemento raffigurante la numerosi emigranti provenienti dai tanti “Fo- Terra con delinetati tutti e 5 i continenti dove golars furlans” nel mondo intervenuti anche i nostri emigranti friulani hanno lavorato ed per la concomitanza dell'annuale raduno che operato con capacità, onestà e laboriosità. -

SMALL Tour in Friuli Venezia Giulia
SMALL tour in friuli venezia giulia Day 1 | Venezia 10.30am - 5.30pm Short and intense tour starting from St. Erasmus (the garden of Venice), as readable model of the formation process of agricultural and of settlement land, where you can see the formation of the settlement (rural and urban) and of the territory: the island, full of linear watery basins (fish ponds, dug up to obtain fill soil, where the fish is bred or kept alive), lined with banks and lapped by waterways. Moving then to Murano (the island of glass) which has Sant’Erasmo both mature settlement forms, extremely dense (compact textures with the characteristic bipolar amphibious water-land system, developed in depth, even up to more than one hundred meters, for the production needs of the rolling of glass cane beads), and recent low density settlement forms and even soils of more recent, controversial, colonization. Un unusual visit to understand the essence itself of the lagoonal city and to bring back home an unforgettable memory. Unique chaperon: Guido Masè, architect Murano and former professor at IUAV of Venice, expert of the ecomuseum world and member of the Technical Committee of Friuli Venezia Giulia ecomuseums. Hour of freedom for lunch and shopping city transport costs € 30.00 per person 6.00pm departure for Maniago Venezia Santa Lucia - Sacile | regionale veloce 2462 departure 6.04pm | arrival in Sacile 7.06pm Sacile - Maniago | Autobus TS414 cdoespta orftu trhee 7tr.1a4ipnm jo u| ranrreivya €l 9in,5 0 Maniago 8.17pm San Marco Day 1 | Ecomuseo Lis Aganis 8.30pm arrival in Maniago Overnight stay in one of the city hotels http://www.albergomontenegro.net http://www.leondoromaniago.com ahvttepr:a/g/we cwoswts. -
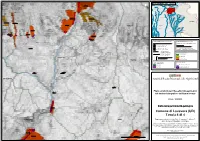
Comune Di Lusevera (UD) Tavola 4 Di 4
!< !< !< !< !< !< !< !< !< !< !< .! INAmQpezUzo ADRAM.!ENTO DEL.!LA TA.!VOLA Tolmezzo Moggio UdineseChiusaforte 0300510300A .! 0302041600 Cavazzo Carnico !< ± 1 2 0300510600 !< .! .!Gemona del Friuli !< Trasaghis .! 3 Lusevera 0302042500 !< 4 0302042400 .! !< Travesio .! Attimis 0302041300 .! !< !< .! Pulfero 0300510500 San Daniele del Friuli !<0300510500-CR 0300512300-CR .! .! 0302041500 Spilimbergo !< Povoletto .! !< 0302121700 Cividale del Friuli SLOVENIA 0302040000 !< !< .! 0302042400-CR !< UDINE 0302042500-CR 0302040100 0302039800 0302041200 !< !< 0300510200 !< 0300512300 .! !< 0300510600 !< Sedegliano 0302041400 0302039900 0302066800 0302121603 !< !< !< !< 0302040300 .! !< .! Codroipo San Giovanni al Natisone 0302040400 !< 0302040500 0302041000 0302058900 !< .! 0302040700 GORIZIA 0300510200 !< !< !<0300510400 0302127100 0302042900 !< .! 03020409000302041100 03020!<40200 !< !< !< !< 2 Palmanova .! 0302039600 Gradisca d'Isonzo !< 0302040800 !< 0302040600 0302039600 0302042900 !< !< 0302042600 !< !< 0300510400A .! .!Latisana San Canzian d'Isonzo 0302127300 0302121601 !< !< !< 0300510400 !< 0302127200 PIANO ASSETTO IDROGEOLOGICO P.A.I. ZONE DI ATTENZIONE GEOLOGICA !< !< Perimetrazione e classi di pericolosità geologica QUADRO CONOSCITIVO COMPLEMENTARE AL P.A.I. P1 - Pericolosità geologica moderata Banca dati I.F.F.I. - P2 - Pericolosità geologica media Inventario dei fenomeni franosi in Italia 0302350700 0302!<350700 P3 - Pericolosità geologica elevata !< Localizzazione dissesto franoso non delimitato P4 - Pericolosità geologica molto -

A.S. 2020/2021 - INIZIO DELLE ATTIVITÀ DIDATTICHE LUNEDÍ 14 SETTEMBRE 2020
ISTITUTO COMPRENSIVO “Linussio - Matiz” Via Roma n. 42 33026 PALUZZA (UD) e mail [email protected] pec: [email protected] Sito web: http://www.icpaluzza.gov.it Ai Sigg Genitori degli alunni Scuole dell’Infanzia, Primarie, Secondarie di I grado Istituto Comprensivo “Linussio - Matiz”di Paluzza Ai Sigg. Sindaci dei Comuni di Arta Terme - Cercivento – Paluzza – Paularo Ravascletto - Sutrio - TreppoLigosullo Al personale Docente e A.T.A. Loro Sedi OGGETTO: CALENDARIO SCOLASTICO 2020/2021 Per opportuna conoscenza e per gli atti di competenza, si riporta il calendario scolastico per l’anno 2020/2021, come deliberato dal Consiglio di Istituto nelle sedute del 31.07.2020 e del 25.08.2020, in applicazione della delibera di Giunta regionale FVG n. 469 del 27 marzo 2020. a.s. 2020/2021 - INIZIO DELLE ATTIVITÀ DIDATTICHE LUNEDÍ 14 SETTEMBRE 2020 LUNEDÍ INIZIO delle attività didattiche 14 SETTEMBRE 2020 scuole dell’infanzia, primarie e secondaria di I grado orario antimeridiano senza servizio mensa DELIBERA GIUNTA REG. FVG GIOVEDÍ FINE delle attività didattiche scuole primarie integrata dalla delibera del 10 GIUGNO 2021 orario antimeridiano senza servizio mensa C.d.I nr. 6 del 31.07.2020 e dalla delibera del C.d.I nr. 1 del 25.08.2020 GIOVEDÍ FINE delle attività didattiche scuole secondarie 10 GIUGNO 2021 orario antimeridiano senza servizio mensa VENERDÍ FINE delle attività didattiche scuole dell’Infanzia 30 GIUGNO 2021 orario antimeridiano senza servizio mensa Il Consiglio di Istituto ha inoltre deliberato: SCUOLE DELL’INFANZIA dal 14 al 16 settembre 2020 Lezioni antimeridiane senza servizio mensa 23.12.2020 11.02.2021 31.03.2021 28-29-30 giugno dal 17 al 18 settembre 2020 Lezioni antimeridiane con servizio mensa Giornata giochi Infanzia (pranzo al sacco Escluso il plesso di Ravascletto confezionato dalle cuoche della scuola) Per il plesso di Piano d’Arta 23.12.2020 11.02.2021 31.03.2021 28-29-30 giugno dal 21 settembre 2020 Orario completo Esclusi i plessi di TreppoLigosullo/Cercivento – Ravascletto* Codice Mecc. -

CALENDARIO LA1/1A Carnico / Prima Categoria
CALENDARIO LA1/1A Carnico / Prima Categoria Giornata n. 1 Davar - A.S.D. Ter.Ca.L. Ven 03/05/19 21:00 Comunale Ovaro (UD) Loc. Spin ASD Preone Becs - A.C. Calgaretto Sab 04/05/19 18:00 Comunale Preone (UD) ASD Sclapeciocs - ASD Socchieve Sab 04/05/19 18:00 P. Picco Bordano (UD) ASD Ibligine - Tilly`s Pub Sutrio Sab 04/05/19 18:00 Campo Dei Pini Villa Santina (UD) - Via Piave, 65 ASD AC Ampezzo - Nolas e Lops Sab 04/05/19 20:00 Campo Sportivo Ampezzo (UD) Riposa: ASD Mueç Giornata n. 2 A.C. Calgaretto - ASD Mueç Sab 11/05/19 18:00 Mario De Antoni Comeglians (UD) Loc. Passarean ASD Ibligine - ASD Preone Becs Sab 11/05/19 18:00 Campo Dei Pini Villa Santina (UD) - Via Piave, 65 Nolas e Lops - ASD Sclapeciocs Sab 11/05/19 18:00 Prater P. Morassi Cercivento (UD) - Via Dal Flum A.S.D. Ter.Ca.L. - Tilly`s Pub Sutrio Sab 11/05/19 18:00 Campo Sportivo Tolmezzo (UD) Terzo ASD AC Ampezzo - ASD Socchieve Sab 11/05/19 20:00 Campo Sportivo Ampezzo (UD) Riposa: Davar Giornata n. 3 A.C. Calgaretto - ASD Socchieve Sab 18/05/19 18:00 Mario De Antoni Comeglians (UD) Loc. Passarean ASD Preone Becs - Davar Sab 18/05/19 18:00 Comunale Preone (UD) A.S.D. Ter.Ca.L. - ASD Ibligine Sab 18/05/19 18:00 Campo Sportivo Tolmezzo (UD) Terzo Tilly`s Pub Sutrio - Nolas e Lops Sab 18/05/19 18:00 Comunale Sutrio (UD) - Via Peschiera, 1 ASD Mueç - ASD AC Ampezzo Sab 18/05/19 18:30 Campo Sportivo Comunale Moggio Udinese (UD) - via Ermolli Riposa: ASD Sclapeciocs Giornata n. -

Second Report Submitted by Italy Pursuant to Article 25, Paragraph 1 of the Framework Convention for the Protection of National Minorities
Strasbourg, 14 May 2004 ACFC/SR/II(2004)006 SECOND REPORT SUBMITTED BY ITALY PURSUANT TO ARTICLE 25, PARAGRAPH 1 OF THE FRAMEWORK CONVENTION FOR THE PROTECTION OF NATIONAL MINORITIES (received on 14 May 2004) MINISTRY OF THE INTERIOR DEPARTMENT FOR CIVIL LIBERTIES AND IMMIGRATION CENTRAL DIRECTORATE FOR CIVIL RIGHTS, CITIZENSHIP AND MINORITIES HISTORICAL AND NEW MINORITIES UNIT FRAMEWORK CONVENTION FOR THE PROTECTION OF NATIONAL MINORITIES II IMPLEMENTATION REPORT - Rome, February 2004 – 2 Table of contents Foreword p.4 Introduction – Part I p.6 Sections referring to the specific requests p.8 - Part II p.9 - Questionnaire - Part III p.10 Projects originating from Law No. 482/99 p.12 Monitoring p.14 Appropriately identified territorial areas p.16 List of conferences and seminars p.18 The communities of Roma, Sinti and Travellers p.20 Publications and promotional activities p.28 European Charter for Regional or Minority Languages p.30 Regional laws p.32 Initiatives in the education sector p.34 Law No. 38/2001 on the Slovenian minority p.40 Judicial procedures and minorities p.42 Database p.44 Appendix I p.49 - Appropriately identified territorial areas p.49 3 FOREWORD 4 Foreword Data and information set out in this second Report testify to the considerable effort made by Italy as regards the protection of minorities. The text is supplemented with fuller and greater details in the Appendix. The Report has been prepared by the Ministry of the Interior – Department for Civil Liberties and Immigration - Central Directorate for Civil Rights, Citizenship and Minorities – Historical and new minorities Unit When the Report was drawn up it was also considered appropriate to seek the opinion of CONFEMILI (National Federative Committee of Linguistic Minorities in Italy). -

Avviso Appalto Aggiudicato
C O M U N E DI A M P E Z Z O PROVINCIA DI UDINE ------------- _________________________________________________________________________________________________________________________________________________________ Ampezzo, lì 28 settembre 2016 Referente: Moreno De Candido tel 0433/80310 [email protected] Avviso di appalto aggiudicato RESTAURO CONSERVATIVO PER L’ADEGUAMENTO ALLE NORME DI SICUREZZA DELLA PALESTRA COMUNALE A SERVIZIO DELL’ISTITUTO COMPRENSIVO DEL CAPOLUOGO: OPERE STRUTTURALI. OO.PP. 122 CUP E24H15000070005 – CIG 6788015F2B 1. STAZIONE APPALTANTE: Comune di Ampezzo, Piazza Zona Libera 1944 n° 28 – 33021 – Ampezzo (UD) – NUTS: ITH42 - tel 0433/80310 – fax 0433/80639 – Posta Elettronica Certificata (PEC): [email protected] sito www.comune.ampezzo.ud.it 2. TIPO DI AMMINISTRAZIONE AGGIUDICATRICE: ente territoriale. 3. CODICI CPV: 45454100-5; 4. CODICE NUTS DEL LUOGO DI PRESTAZIONE: ITH42; 5. DESCRIZIONE DELL’APPALTO: demolizioni, consolidamento parti strutturali in legno, consolidamento travi a volta lamellari, pulizia e consolidamento di elementi strutturali in calcestruzzo, fornitura e posa di pannelli di tamponamento esteri in legno, esecuzione di carpenteria metallica in acciaio, fornitura e posa di elementi lamellari in legno. 6. TIPO DI PROCEDURA DI AGGIUDICAZIONE: procedura negoziata, ai sensi dell’art. 36 comma 2 lettera b) del D.Lgs. 50/2016 e s.m.i. , perché importo a base d’asta < 150.000,00 euro, preceduta da avviso indagine di mercato; 7. CRITERIO DI AGGIUDICAZIONE: criterio del Minor prezzo rispetto a quello posta a base di gara, ai sensi dell’art. 95 comma 4 del D.Lgs. 50/2016; con esclusione automatica delle offerte che presentano una percentuale di ribasso superiore alla soglia di anomalia individuata ai sensi dell’art. -

Glacial and Proglacial Deposits of the Resia Valley (Ne Italy): New Insights on the Onset and Decay of the Last Alpine Glacial Maximum in the Julian Alps
Available online http://amq.aiqua.it ISSN (print): 2279-7327, ISSN (online): 2279-7335 Alpine and Mediterranean Quaternary, 27 (2), 2014, 85 - 104 GLACIAL AND PROGLACIAL DEPOSITS OF THE RESIA VALLEY (NE ITALY): NEW INSIGHTS ON THE ONSET AND DECAY OF THE LAST ALPINE GLACIAL MAXIMUM IN THE JULIAN ALPS. Renato R. Colucci1, Giovanni Monegato2, Manja Žebre1,3 1 C.N.R. - Institute of Marine Sciences, Trieste, Italy 2 C.N.R. - Institute of Geosciences and Earth Resources, Torino, Italy 3 Department of Geography, Faculty of Arts, University of Ljubljana, Ljubljana, Slovenia Corresponding author: G. Monegato <[email protected]> ABSTRACT: The Resia Valley is located in the south-eastern sector of the Alps, where small glacial remnants are still preserved despite the average low-elevation of the reliefs. The abundance of glacigenic deposits related to the Last Glacial Maximum allowed to discuss and reconstruct the onset and decay of the glaciation. The initial glacier expansion from the Canin-Toudule and the Barman cirques led to the infilling of the former valley with fluvioglacial and glaciolacustrine successions. Then, the spread of the Resia Glacier during the LGM cli- max covered and over-consolidated these units. On the valley flanks, the interaction of the base of the trunk glacier with the sharp pre- glacial topography caused the formation of subglacial deposits containing large-size sub-angular boulders and glaciolacustrine fines. Dur- ing the LGM the Resia Glacier reached the maximum thickness of about 550 m, and was tributary of the Fella Glacier at Resiutta. During the Late Glacial, two main stadial phases are characterised by frontal moraines and ice-dammed deposits. -

Comune Di AMARO (UD) Comune Di
DIVISIONE ESERCIZIO Friuli Venezia Giulia Strade S.p.A. Sede Legale: Scala dei Cappuccini, 1 - 34131 Trieste Tel. +39 040 5604200 - Fax +39 040 5604281 [email protected] www.fvgstrade.it Società soggetta alla attività di direzione e coordinamento Dell’unico socio Regione Autonoma FVG Cod. Fisc. e p. I.V.A. 01133800324 - Cap. Soc. € 10.300.000,00 i.v. Reg. Imp. di TS n . 01133800324 - REA 127257 Documento trasmesso esclusivamente Alla Prefettura di Udine via posta elettronica o telefax Alla Prefettura di Pordenone Alla Prefettura di Trieste Alla Questura di Udine Alla Questura di Pordenone Alla Questura di Trieste Al Compartimento Polizia Stradale del Friuli Venezia Giulia Alla Sezione Polizia Stradale di Udine Alla Sezione Polizia Stradale di Pordenone Alla Sezione Polizia Stradale di Trieste Al Comando Regionale Guardia di Finanza del Friuli Venezia Giulia Al Comando Provinciale Guardia di Finanza di Udine Al Comando Provinciale Guardia di Finanza di Pordenone Al Comando Provinciale Guardia di Finanza di Trieste Al Comando Provinciale Carabinieri di Udine Al Comando Provinciale Carabinieri di Pordenone Al Comando Provinciale Carabinieri di Trieste Al Comando Provinciale Vigili del Fuoco di Udine Al Comando Provinciale Vigili del Fuoco di Pordenone Al Comando Provinciale Vigili del Fuoco di Trieste Alla Croce Rossa Italiana di Udine Alla Croce Rossa Italiana di Pordenone Alla Croce Rossa Italiana di Trieste Alla SORES Alla SOGIT Al CCISS Al Servizio viabilità di interesse locale e regionale per il tramite della segreteria del Direttore Generale Alla Direzione Regionale Infrastrutture e Trasporti Alla Direzione Regionale della Protezione Civile All’ ANSA – Agenzia di Stampa Alla RAI del Friuli Venezia Giulia All’ ANAS S.p.A. -

33027 Paularo (UD) Tel: 043370046 E-Mail: [email protected]
ISTITUTO COMPRENSIVO DI ARTA e PAULARO via Roma, 37 – 33027 Paularo (UD) Tel: 043370046 E-mail: [email protected] www.icartapaularo.gov.it Sintesi per le famiglie a.s. 2017/2018 Dirigente scolastico reggente: prof. Rossella Rizzatto LE SEDI La presidenza si trova presso la sede Presidenza principale di Paularo. Il Dirigente scolastico reggente, prof. Rossella Rizzatto, riceve su via Roma, 37 appuntamento. 33027 Paularo (UD) Gli uffici di segreteria si trovano presso la tel. 043370046 Uffici di sede principale di Paularo e sono aperti al email: [email protected] segreteria pubblico tutti i giorni, dal lunedì al venerdì, dalle ore 10.30 alle 12.30. Formeaso lunedì – venerdì 8.00 -16.00 via Madussi, 3 40 ore settimanali. 33020 Formeaso di Zuglio (UD) Scuole L’Amministrazione Comunale fornisce alle tel. 0433929504 dell’Infanzia famiglie un servizio gratuito di pre e post email: [email protected] accoglienza con proprio personale (ore 7.30 - 8.00 e 16.00 -17.30) Piano d’Arta via Peresson, 21 lunedì – venerdì 8.00 -16.00 33022 Piano d'Arta (UD) 40 ore settimanali tel. 043392040 email: [email protected] Arta Terme via Roma, 14 lunedì: 8.10 -16.10 con servizio mensa 33022 Arta Terme (UD) martedì - venerdì 8.10 -13.10 tel. 043392196 27 ore settimanali fax 0433929663 email: [email protected] Scuole Paularo via Roma 37 Primarie lunedì – venerdì 8.00 - 16.00 con servizio 33027 Paularo (UD) mensa tel. 043370046 email: [email protected] Arta Terme via Roma, 14 lunedì e giovedì 8.10 - 16.30 con servizio 33022 Arta Terme (UD) mensa tel. -

COMUNE DI MOGGIO UDINESE Provincia Di Udine Medaglia D'oro Al Valore Civile
COMUNE DI MOGGIO UDINESE Provincia di Udine medaglia d'oro al valore civile P.ZZA UFFICI, 1 C.A.P. 33015 C.F. 8400 1550 304 P. I.V.A. 01 134 980 307 TEL. 0433 / 51177-51877-51888 FAX 0433 / 51371 www.comune.moggioudinese.ud.it [email protected] VERBALE DI DELIBERAZIONE DEL CONSIGLIO COMUNALE ORIGINALE ANNO 2014 N. 52 del Reg. Delibere OGGETTO: APPROVAZIONE CONVENZIONE FRA I COMUNI DI PAULARO, LIGOSULLO E MOGGIO UDINESE PER L©ESERCIZIO ASSOCIATO DELLA FUNZIONE DI SEGRETERIA COMUNALE. L©anno 2014, il giorno 26 del mese di Settembre, alle ore 18:00, nella sala consiliare, in seguito a convocazione disposta con avvisi recapitati ai singoli Consiglieri, si è riunito il Consiglio Comunale. Intervennero i signori: Presente/Assente Filaferro Giorgio Sindaco Presente Di Lenardo Annalisa Consigliere Presente Linossi Paola Consigliere Presente Saveri Matteo Consigliere Presente Callegarin Maurizio Consigliere Presente Tassinari Luigino Consigliere Presente Biancolino Ilenia Consigliere Presente Monai Ingrid Consigliere Presente Zearo Enrico Consigliere Presente Musi Ezio Consigliere Presente De Colle Elena Consigliere Presente Goi Elsa Consigliere Presente Gardel Bruno Consigliere Presente È presente l'Assessore esterno dott. Flavio Missoni. Assiste il Segretario Comunale dott.ssa Paola Bulfon. Constatato il numero degli intervenuti, assume la presidenza l'ing. Giorgio Filaferro nella sua qualità di Sindaco ed espone gli oggetti inscritti all©ordine del giorno, su questi il Consiglio Comunale adotta la seguente deliberazione: Comune di Moggio Udinese ± Deliberazione n. 52 del 26/09/2014 1 OGGETTO: Approvazione convenzione fra i Comuni di Paularo, Ligosullo e Moggio Udinese per l'esercizio associato della funzione di Segreteria Comunale.