Monoid Machines: a O(Log N) Parser for Regular Languages
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Matrix Calculus You Need for Deep Learning
The Matrix Calculus You Need For Deep Learning Terence Parr and Jeremy Howard July 3, 2018 (We teach in University of San Francisco's MS in Data Science program and have other nefarious projects underway. You might know Terence as the creator of the ANTLR parser generator. For more material, see Jeremy's fast.ai courses and University of San Francisco's Data Institute in- person version of the deep learning course.) HTML version (The PDF and HTML were generated from markup using bookish) Abstract This paper is an attempt to explain all the matrix calculus you need in order to understand the training of deep neural networks. We assume no math knowledge beyond what you learned in calculus 1, and provide links to help you refresh the necessary math where needed. Note that you do not need to understand this material before you start learning to train and use deep learning in practice; rather, this material is for those who are already familiar with the basics of neural networks, and wish to deepen their understanding of the underlying math. Don't worry if you get stuck at some point along the way|just go back and reread the previous section, and try writing down and working through some examples. And if you're still stuck, we're happy to answer your questions in the Theory category at forums.fast.ai. Note: There is a reference section at the end of the paper summarizing all the key matrix calculus rules and terminology discussed here. arXiv:1802.01528v3 [cs.LG] 2 Jul 2018 1 Contents 1 Introduction 3 2 Review: Scalar derivative rules4 3 Introduction to vector calculus and partial derivatives5 4 Matrix calculus 6 4.1 Generalization of the Jacobian . -

IVC Factsheet Functions Comp Inverse
Imperial Valley College Math Lab Functions: Composition and Inverse Functions FUNCTION COMPOSITION In order to perform a composition of functions, it is essential to be familiar with function notation. If you see something of the form “푓(푥) = [expression in terms of x]”, this means that whatever you see in the parentheses following f should be substituted for x in the expression. This can include numbers, variables, other expressions, and even other functions. EXAMPLE: 푓(푥) = 4푥2 − 13푥 푓(2) = 4 ∙ 22 − 13(2) 푓(−9) = 4(−9)2 − 13(−9) 푓(푎) = 4푎2 − 13푎 푓(푐3) = 4(푐3)2 − 13푐3 푓(ℎ + 5) = 4(ℎ + 5)2 − 13(ℎ + 5) Etc. A composition of functions occurs when one function is “plugged into” another function. The notation (푓 ○푔)(푥) is pronounced “푓 of 푔 of 푥”, and it literally means 푓(푔(푥)). In other words, you “plug” the 푔(푥) function into the 푓(푥) function. Similarly, (푔 ○푓)(푥) is pronounced “푔 of 푓 of 푥”, and it literally means 푔(푓(푥)). In other words, you “plug” the 푓(푥) function into the 푔(푥) function. WARNING: Be careful not to confuse (푓 ○푔)(푥) with (푓 ∙ 푔)(푥), which means 푓(푥) ∙ 푔(푥) . EXAMPLES: 푓(푥) = 4푥2 − 13푥 푔(푥) = 2푥 + 1 a. (푓 ○푔)(푥) = 푓(푔(푥)) = 4[푔(푥)]2 − 13 ∙ 푔(푥) = 4(2푥 + 1)2 − 13(2푥 + 1) = [푠푚푝푙푓푦] … = 16푥2 − 10푥 − 9 b. (푔 ○푓)(푥) = 푔(푓(푥)) = 2 ∙ 푓(푥) + 1 = 2(4푥2 − 13푥) + 1 = 8푥2 − 26푥 + 1 A function can even be “composed” with itself: c. -

Midterm Study Sheet for CS3719 Regular Languages and Finite
Midterm study sheet for CS3719 Regular languages and finite automata: • An alphabet is a finite set of symbols. Set of all finite strings over an alphabet Σ is denoted Σ∗.A language is a subset of Σ∗. Empty string is called (epsilon). • Regular expressions are built recursively starting from ∅, and symbols from Σ and closing under ∗ Union (R1 ∪ R2), Concatenation (R1 ◦ R2) and Kleene Star (R denoting 0 or more repetitions of R) operations. These three operations are called regular operations. • A Deterministic Finite Automaton (DFA) D is a 5-tuple (Q, Σ, δ, q0,F ), where Q is a finite set of states, Σ is the alphabet, δ : Q × Σ → Q is the transition function, q0 is the start state, and F is the set of accept states. A DFA accepts a string if there exists a sequence of states starting with r0 = q0 and ending with rn ∈ F such that ∀i, 0 ≤ i < n, δ(ri, wi) = ri+1. The language of a DFA, denoted L(D) is the set of all and only strings that D accepts. • Deterministic finite automata are used in string matching algorithms such as Knuth-Morris-Pratt algorithm. • A language is called regular if it is recognized by some DFA. • ‘Theorem: The class of regular languages is closed under union, concatenation and Kleene star operations. • A non-deterministic finite automaton (NFA) is a 5-tuple (Q, Σ, δ, q0,F ), where Q, Σ, q0 and F are as in the case of DFA, but the transition function δ is δ : Q × (Σ ∪ {}) → P(Q). -

Chapter 6 Formal Language Theory
Chapter 6 Formal Language Theory In this chapter, we introduce formal language theory, the computational theories of languages and grammars. The models are actually inspired by formal logic, enriched with insights from the theory of computation. We begin with the definition of a language and then proceed to a rough characterization of the basic Chomsky hierarchy. We then turn to a more de- tailed consideration of the types of languages in the hierarchy and automata theory. 6.1 Languages What is a language? Formally, a language L is defined as as set (possibly infinite) of strings over some finite alphabet. Definition 7 (Language) A language L is a possibly infinite set of strings over a finite alphabet Σ. We define Σ∗ as the set of all possible strings over some alphabet Σ. Thus L ⊆ Σ∗. The set of all possible languages over some alphabet Σ is the set of ∗ all possible subsets of Σ∗, i.e. 2Σ or ℘(Σ∗). This may seem rather simple, but is actually perfectly adequate for our purposes. 6.2 Grammars A grammar is a way to characterize a language L, a way to list out which strings of Σ∗ are in L and which are not. If L is finite, we could simply list 94 CHAPTER 6. FORMAL LANGUAGE THEORY 95 the strings, but languages by definition need not be finite. In fact, all of the languages we are interested in are infinite. This is, as we showed in chapter 2, also true of human language. Relating the material of this chapter to that of the preceding two, we can view a grammar as a logical system by which we can prove things. -

The Logic of Recursive Equations Author(S): A
The Logic of Recursive Equations Author(s): A. J. C. Hurkens, Monica McArthur, Yiannis N. Moschovakis, Lawrence S. Moss, Glen T. Whitney Source: The Journal of Symbolic Logic, Vol. 63, No. 2 (Jun., 1998), pp. 451-478 Published by: Association for Symbolic Logic Stable URL: http://www.jstor.org/stable/2586843 . Accessed: 19/09/2011 22:53 Your use of the JSTOR archive indicates your acceptance of the Terms & Conditions of Use, available at . http://www.jstor.org/page/info/about/policies/terms.jsp JSTOR is a not-for-profit service that helps scholars, researchers, and students discover, use, and build upon a wide range of content in a trusted digital archive. We use information technology and tools to increase productivity and facilitate new forms of scholarship. For more information about JSTOR, please contact [email protected]. Association for Symbolic Logic is collaborating with JSTOR to digitize, preserve and extend access to The Journal of Symbolic Logic. http://www.jstor.org THE JOURNAL OF SYMBOLIC LOGIC Volume 63, Number 2, June 1998 THE LOGIC OF RECURSIVE EQUATIONS A. J. C. HURKENS, MONICA McARTHUR, YIANNIS N. MOSCHOVAKIS, LAWRENCE S. MOSS, AND GLEN T. WHITNEY Abstract. We study logical systems for reasoning about equations involving recursive definitions. In particular, we are interested in "propositional" fragments of the functional language of recursion FLR [18, 17], i.e., without the value passing or abstraction allowed in FLR. The 'pure," propositional fragment FLRo turns out to coincide with the iteration theories of [1]. Our main focus here concerns the sharp contrast between the simple class of valid identities and the very complex consequence relation over several natural classes of models. -
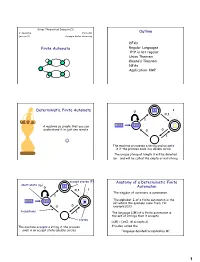
Deterministic Finite Automata 0 0,1 1
Great Theoretical Ideas in CS V. Adamchik CS 15-251 Outline Lecture 21 Carnegie Mellon University DFAs Finite Automata Regular Languages 0n1n is not regular Union Theorem Kleene’s Theorem NFAs Application: KMP 11 1 Deterministic Finite Automata 0 0,1 1 A machine so simple that you can 0111 111 1 ϵ understand it in just one minute 0 0 1 The machine processes a string and accepts it if the process ends in a double circle The unique string of length 0 will be denoted by ε and will be called the empty or null string accept states (F) Anatomy of a Deterministic Finite start state (q0) 11 0 Automaton 0,1 1 The singular of automata is automaton. 1 The alphabet Σ of a finite automaton is the 0111 111 1 ϵ set where the symbols come from, for 0 0 example {0,1} transitions 1 The language L(M) of a finite automaton is the set of strings that it accepts states L(M) = {x∈Σ: M accepts x} The machine accepts a string if the process It’s also called the ends in an accept state (double circle) “language decided/accepted by M”. 1 The Language L(M) of Machine M The Language L(M) of Machine M 0 0 0 0,1 1 q 0 q1 q0 1 1 What language does this DFA decide/accept? L(M) = All strings of 0s and 1s The language of a finite automaton is the set of strings that it accepts L(M) = { w | w has an even number of 1s} M = (Q, Σ, , q0, F) Q = {q0, q1, q2, q3} Formal definition of DFAs where Σ = {0,1} A finite automaton is a 5-tuple M = (Q, Σ, , q0, F) q0 Q is start state Q is the finite set of states F = {q1, q2} Q accept states : Q Σ → Q transition function Σ is the alphabet : Q Σ → Q is the transition function q 1 0 1 0 1 0,1 q0 Q is the start state q0 q0 q1 1 q q1 q2 q2 F Q is the set of accept states 0 M q2 0 0 q2 q3 q2 q q q 1 3 0 2 L(M) = the language of machine M q3 = set of all strings machine M accepts EXAMPLE Determine the language An automaton that accepts all recognized by and only those strings that contain 001 1 0,1 0,1 0 1 0 0 0 1 {0} {00} {001} 1 L(M)={1,11,111, …} 2 Membership problem Determine the language decided by Determine whether some word belongs to the language. -
6.045 Final Exam Name
6.045J/18.400J: Automata, Computability and Complexity Prof. Nancy Lynch 6.045 Final Exam May 20, 2005 Name: • Please write your name on each page. • This exam is open book, open notes. • There are two sheets of scratch paper at the end of this exam. • Questions vary substantially in difficulty. Use your time accordingly. • If you cannot produce a full proof, clearly state partial results for partial credit. • Good luck! Part Problem Points Grade Part I 1–10 50 1 20 2 15 3 25 Part II 4 15 5 15 6 10 Total 150 final-1 Name: Part I Multiple Choice Questions. (50 points, 5 points for each question) For each question, any number of the listed answersClearly may place be correct. an “X” in the box next to each of the answers that you are selecting. Problem 1: Which of the following are true statements about regular and nonregular languages? (All lan guages are over the alphabet{0, 1}) IfL1 ⊆ L2 andL2 is regular, thenL1 must be regular. IfL1 andL2 are nonregular, thenL1 ∪ L2 must be nonregular. IfL1 is nonregular, then the complementL 1 must of also be nonregular. IfL1 is regular,L2 is nonregular, andL1 ∩ L2 is nonregular, thenL1 ∪ L2 must be nonregular. IfL1 is regular,L2 is nonregular, andL1 ∩ L2 is regular, thenL1 ∪ L2 must be nonregular. Problem 2: Which of the following are guaranteed to be regular languages ? ∗ L2 = {ww : w ∈{0, 1}}. L2 = {ww : w ∈ L1}, whereL1 is a regular language. L2 = {w : ww ∈ L1}, whereL1 is a regular language. L2 = {w : for somex,| w| = |x| andwx ∈ L1}, whereL1 is a regular language. -

Monoids: Theme and Variations (Functional Pearl)
University of Pennsylvania ScholarlyCommons Departmental Papers (CIS) Department of Computer & Information Science 7-2012 Monoids: Theme and Variations (Functional Pearl) Brent A. Yorgey University of Pennsylvania, [email protected] Follow this and additional works at: https://repository.upenn.edu/cis_papers Part of the Programming Languages and Compilers Commons, Software Engineering Commons, and the Theory and Algorithms Commons Recommended Citation Brent A. Yorgey, "Monoids: Theme and Variations (Functional Pearl)", . July 2012. This paper is posted at ScholarlyCommons. https://repository.upenn.edu/cis_papers/762 For more information, please contact [email protected]. Monoids: Theme and Variations (Functional Pearl) Abstract The monoid is a humble algebraic structure, at first glance ve en downright boring. However, there’s much more to monoids than meets the eye. Using examples taken from the diagrams vector graphics framework as a case study, I demonstrate the power and beauty of monoids for library design. The paper begins with an extremely simple model of diagrams and proceeds through a series of incremental variations, all related somehow to the central theme of monoids. Along the way, I illustrate the power of compositional semantics; why you should also pay attention to the monoid’s even humbler cousin, the semigroup; monoid homomorphisms; and monoid actions. Keywords monoid, homomorphism, monoid action, EDSL Disciplines Programming Languages and Compilers | Software Engineering | Theory and Algorithms This conference paper is available at ScholarlyCommons: https://repository.upenn.edu/cis_papers/762 Monoids: Theme and Variations (Functional Pearl) Brent A. Yorgey University of Pennsylvania [email protected] Abstract The monoid is a humble algebraic structure, at first glance even downright boring. -

Contents 3 Homomorphisms, Ideals, and Quotients
Ring Theory (part 3): Homomorphisms, Ideals, and Quotients (by Evan Dummit, 2018, v. 1.01) Contents 3 Homomorphisms, Ideals, and Quotients 1 3.1 Ring Isomorphisms and Homomorphisms . 1 3.1.1 Ring Isomorphisms . 1 3.1.2 Ring Homomorphisms . 4 3.2 Ideals and Quotient Rings . 7 3.2.1 Ideals . 8 3.2.2 Quotient Rings . 9 3.2.3 Homomorphisms and Quotient Rings . 11 3.3 Properties of Ideals . 13 3.3.1 The Isomorphism Theorems . 13 3.3.2 Generation of Ideals . 14 3.3.3 Maximal and Prime Ideals . 17 3.3.4 The Chinese Remainder Theorem . 20 3.4 Rings of Fractions . 21 3 Homomorphisms, Ideals, and Quotients In this chapter, we will examine some more intricate properties of general rings. We begin with a discussion of isomorphisms, which provide a way of identifying two rings whose structures are identical, and then examine the broader class of ring homomorphisms, which are the structure-preserving functions from one ring to another. Next, we study ideals and quotient rings, which provide the most general version of modular arithmetic in a ring, and which are fundamentally connected with ring homomorphisms. We close with a detailed study of the structure of ideals and quotients in commutative rings with 1. 3.1 Ring Isomorphisms and Homomorphisms • We begin our study with a discussion of structure-preserving maps between rings. 3.1.1 Ring Isomorphisms • We have encountered several examples of rings with very similar structures. • For example, consider the two rings R = Z=6Z and S = (Z=2Z) × (Z=3Z). -

(A) for Any Regular Expression R, the Set L(R) of Strings
Kleene’s Theorem Definition. Alanguageisregular iff it is equal to L(M), the set of strings accepted by some deterministic finite automaton M. Theorem. (a) For any regular expression r,thesetL(r) of strings matching r is a regular language. (b) Conversely, every regular language is the form L(r) for some regular expression r. L6 79 Example of a regular language Recall the example DFA we used earlier: b a a a a M ! q0 q1 q2 q3 b b b In this case it’s not hard to see that L(M)=L(r) for r =(a|b)∗ aaa(a|b)∗ L6 80 Example M ! a 1 b 0 b a a 2 L(M)=L(r) for which regular expression r? Guess: r = a∗|a∗b(ab)∗ aaa∗ L6 81 Example M ! a 1 b 0 b a a 2 L(M)=L(r) for which regular expression r? Guess: r = a∗|a∗b(ab)∗ aaa∗ since baabaa ∈ L(M) WRONG! but baabaa ̸∈ L(a∗|a∗b(ab)∗ aaa∗ ) We need an algorithm for constructing a suitable r for each M (plus a proof that it is correct). L6 81 Lemma. Given an NFA M =(Q, Σ, δ, s, F),foreach subset S ⊆ Q and each pair of states q, q′ ∈ Q,thereisa S regular expression rq,q′ satisfying S Σ∗ u ∗ ′ L(rq,q′ )={u ∈ | q −→ q in M with all inter- mediate states of the sequence of transitions in S}. Hence if the subset F of accepting states has k distinct elements, q1,...,qk say, then L(M)=L(r) with r ! r1|···|rk where Q ri = rs,qi (i = 1, . -

Math 311 - Introduction to Proof and Abstract Mathematics Group Assignment # 15 Name: Due: at the End of Class on Tuesday, March 26Th
Math 311 - Introduction to Proof and Abstract Mathematics Group Assignment # 15 Name: Due: At the end of class on Tuesday, March 26th More on Functions: Definition 5.1.7: Let A, B, C, and D be sets. Let f : A B and g : C D be functions. Then f = g if: → → A = C and B = D • For all x A, f(x)= g(x). • ∈ Intuitively speaking, this definition tells us that a function is determined by its underlying correspondence, not its specific formula or rule. Another way to think of this is that a function is determined by the set of points that occur on its graph. 1. Give a specific example of two functions that are defined by different rules (or formulas) but that are equal as functions. 2. Consider the functions f(x)= x and g(x)= √x2. Find: (a) A domain for which these functions are equal. (b) A domain for which these functions are not equal. Definition 5.1.9 Let X be a set. The identity function on X is the function IX : X X defined by, for all x X, → ∈ IX (x)= x. 3. Let f(x)= x cos(2πx). Prove that f(x) is the identity function when X = Z but not when X = R. Definition 5.1.10 Let n Z with n 0, and let a0,a1, ,an R such that an = 0. The function p : R R is a ∈ ≥ ··· ∈ 6 n n−1 → polynomial of degree n with real coefficients a0,a1, ,an if for all x R, p(x)= anx +an−1x + +a1x+a0. -

1 Monoids and Groups
1 Monoids and groups 1.1 Definition. A monoid is a set M together with a map M × M ! M; (x; y) 7! x · y such that (i) (x · y) · z = x · (y · z) 8x; y; z 2 M (associativity); (ii) 9e 2 M such that x · e = e · x = x for all x 2 M (e = the identity element of M). 1.2 Examples. 1) Z with addition of integers (e = 0) 2) Z with multiplication of integers (e = 1) 3) Mn(R) = fthe set of all n × n matrices with coefficients in Rg with ma- trix multiplication (e = I = the identity matrix) 4) U = any set P (U) := fthe set of all subsets of Ug P (U) is a monoid with A · B := A [ B and e = ?. 5) Let U = any set F (U) := fthe set of all functions f : U ! Ug F (U) is a monoid with multiplication given by composition of functions (e = idU = the identity function). 1.3 Definition. A monoid is commutative if x · y = y · x for all x; y 2 M. 1.4 Example. Monoids 1), 2), 4) in 1.2 are commutative; 3), 5) are not. 1 1.5 Note. Associativity implies that for x1; : : : ; xk 2 M the expression x1 · x2 ····· xk has the same value regardless how we place parentheses within it; e.g.: (x1 · x2) · (x3 · x4) = ((x1 · x2) · x3) · x4 = x1 · ((x2 · x3) · x4) etc. 1.6 Note. A monoid has only one identity element: if e; e0 2 M are identity elements then e = e · e0 = e0 1.7 Definition.