Relevance Popularity: a Term Event Model Based Feature Selection Scheme for Text Classification
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Changchun–Harbin Expressway Project
Performance Evaluation Report Project Number: PPE : PRC 30389 Loan Numbers: 1641/1642 December 2006 People’s Republic of China: Changchun–Harbin Expressway Project Operations Evaluation Department CURRENCY EQUIVALENTS Currency Unit – yuan (CNY) At Appraisal At Project Completion At Operations Evaluation (July 1998) (August 2004) (December 2006) CNY1.00 = $0.1208 $0.1232 $0.1277 $1.00 = CNY8.28 CNY8.12 CNY7.83 ABBREVIATIONS AADT – annual average daily traffic ADB – Asian Development Bank CDB – China Development Bank DMF – design and monitoring framework EIA – environmental impact assessment EIRR – economic internal rate of return FIRR – financial internal rate of return GDP – gross domestic product ha – hectare HHEC – Heilongjiang Hashuang Expressway Corporation HPCD – Heilongjiang Provincial Communications Department ICB – international competitive bidding JPCD – Jilin Provincial Communications Department JPEC – Jilin Provincial Expressway Corporation MOC – Ministry of Communications NTHS – national trunk highway system O&M – operations and maintenance OEM – Operations Evaluation Mission PCD – provincial communication department PCR – project completion report PPTA – project preparatory technical assistance PRC – People’s Republic of China RRP – report and recommendation of the President TA – technical assistance VOC – vehicle operating cost NOTE In this report, “$” refers to US dollars. Keywords asian development bank, development effectiveness, expressways, people’s republic of china, performance evaluation, heilongjiang province, jilin province, transport Director Ramesh Adhikari, Operations Evaluation Division 2, OED Team leader Marco Gatti, Senior Evaluation Specialist, OED Team members Vivien Buhat-Ramos, Evaluation Officer, OED Anna Silverio, Operations Evaluation Assistant, OED Irene Garganta, Operations Evaluation Assistant, OED Operations Evaluation Department, PE-696 CONTENTS Page BASIC DATA v EXECUTIVE SUMMARY vii MAPS xi I. INTRODUCTION 1 A. -

Prevalence of Hypertension and Associated Risk Factors in Dehui City of Jilin Province in China
Journal of Human Hypertension (2015) 29,64–68 & 2015 Macmillan Publishers Limited All rights reserved 0950-9240/15 www.nature.com/jhh ORIGINAL ARTICLE Prevalence of hypertension and associated risk factors in Dehui City of Jilin Province in China QWei1,7, J Sun2,7, J Huang3, H-Y Zhou2, Y-M Ding4, Y-C Tao5, S-M He2, Y-L Liu2 and J-Q Niu6 To evaluate the prevalence, awareness, treatment and control of hypertension and its risk factors in Dehui City of Jilin Province in China. The study was performed among 3778 subjects (male ¼ 1787) in Dehui city, Jilin Province of China. The subjects completed a standard questionnaire, biochemical tests and physical examinations. Logistic regression analyses were used to identify risk factors for hypertension. The prevalence of hypertension was 41.00% in this area. The awareness, treatment and the control of hypertension were 21.82, 15.56 and 1.10%, respectively, with city areas being significantly higher than rural areas. Significant risk factors for hypertension included age, sex, central obesity, alcohol consumption, family history of hypertension, dyslipidemia, education level and type of work. Further analysis showed that diabetes for urban participants and cigarette smoking for rural participants were risk factors but were not statistically significant at the multi-variate level. The prevalence of hypertension in Dehui Ctiy of Jilin Province is higher than in other areas of China. In addition, rates of awareness and treatment of the condition are much lower than in other populations, with the control rate only 1.10%. Journal of Human Hypertension (2015) 29, 64–68; doi:10.1038/jhh.2014.32; published online 3 July 2014 INTRODUCTION other areas in Jilin Province. -

China Russia
1 1 1 1 Acheng 3 Lesozavodsk 3 4 4 0 Didao Jixi 5 0 5 Shuangcheng Shangzhi Link? ou ? ? ? ? Hengshan ? 5 SEA OF 5 4 4 Yushu Wuchang OKHOTSK Dehui Mudanjiang Shulan Dalnegorsk Nongan Hailin Jiutai Jishu CHINA Kavalerovo Jilin Jiaohe Changchun RUSSIA Dunhua Uglekamensk HOKKAIDOO Panshi Huadian Tumen Partizansk Sapporo Hunchun Vladivostok Liaoyuan Chaoyang Longjing Yanji Nahodka Meihekou Helong Hunjiang Najin Badaojiang Tong Hua Hyesan Kanggye Aomori Kimchaek AOMORI ? ? 0 AKITA 0 4 DEMOCRATIC PEOPLE'S 4 REPUBLIC OF KOREA Akita Morioka IWATE SEA O F Pyongyang GULF OF KOREA JAPAN Nampo YAMAJGATAA PAN Yamagata MIYAGI Sendai Haeju Niigata Euijeongbu Chuncheon Bucheon Seoul NIIGATA Weonju Incheon Anyang ISIKAWA ChechonREPUBLIC OF HUKUSIMA Suweon KOREA TOTIGI Cheonan Chungju Toyama Cheongju Kanazawa GUNMA IBARAKI TOYAMA PACIFIC OCEAN Nagano Mito Andong Maebashi Daejeon Fukui NAGANO Kunsan Daegu Pohang HUKUI SAITAMA Taegu YAMANASI TOOKYOO YELLOW Ulsan Tottori GIFU Tokyo Matsue Gifu Kofu Chiba SEA TOTTORI Kawasaki KANAGAWA Kwangju Masan KYOOTO Yokohama Pusan SIMANE Nagoya KANAGAWA TIBA ? HYOOGO Kyoto SIGA SIZUOKA ? 5 Suncheon Chinhae 5 3 Otsu AITI 3 OKAYAMA Kobe Nara Shizuoka Yeosu HIROSIMA Okayama Tsu KAGAWA HYOOGO Hiroshima OOSAKA Osaka MIE YAMAGUTI OOSAKA Yamaguchi Takamatsu WAKAYAMA NARA JAPAN Tokushima Wakayama TOKUSIMA Matsuyama National Capital Fukuoka HUKUOKA WAKAYAMA Jeju EHIME Provincial Capital Cheju Oita Kochi SAGA KOOTI City, town EAST CHINA Saga OOITA Major Airport SEA NAGASAKI Kumamoto Roads Nagasaki KUMAMOTO Railroad Lake MIYAZAKI River, lake JAPAN KAGOSIMA Miyazaki International Boundary Provincial Boundary Kagoshima 0 12.5 25 50 75 100 Kilometers Miles 0 10 20 40 60 80 ? ? ? ? 0 5 0 5 3 3 4 4 1 1 1 1 The boundaries and names show n and t he designations us ed on this map do not imply of ficial endors ement or acceptance by the United N at ions. -

Effect of Finger Pressing on Anti-Inflammatory Effect in Obese Rats with Insulin Resistance
2021 International Conference on Biomedicine, Medical Services & Specialties (BMMSS 2021) Effect of Finger Pressing on Anti-Inflammatory Effect in Obese Rats with Insulin Resistance Shaotao Chen1, Lin JIANG2, Xiaolin Zhang1, Mingjun Liu1,* 1Changchun University of Traditional Chinese Medicine, Changchun, Jilin 130117, China 2Balipu Community Health Service Center, Erdao District, Changchun, Jilin 130117, China *Corresponding Author Keywords: Finger pressure method, Insulin resistance, Obese rats Abstract: Objective: To observe the anti-inflammatory effect of finger pressure method on obese rats with insulin resistance and study its mechanism. Methods: 20 male SD rats aged 5-8 weeks were randomly divided into two groups: general diet plus finger pressure method group and high fat plus finger pressure method group. They were fed with high fat diet for 8 weeks. The success of modeling was judged by fasting blood glucose, fasting insulin level and glucose tolerance test. The model of insulin resistance induced by obesity was induced by high fat diet for 8 weeks in the high fat plus finger pressure method group and the general diet plus finger pressure method group. After the experiment, blood glucose, blood insulin, TG, TCH, LDL and FFA were measured, and the fat- body ratio around testis and kidney was measured by killing animals. Results: The body weight, Lee index and fat coefficient of obese rats were significantly increased by high fat diet. Aerobic exercise and polysaccharide intervention can decrease the above morphological indexes. After 4 weeks of hypoxic exercise, the rats lost weight (P < 0.05), impaired glucose tolerance, insulin resistance and insulin sensitivity. The basic finger pressure method intervention can alleviate the anti-inflammation and improve the insulin resistance of obese rats. -

Water Resource Carrying Capacity Based on Water Demand Prediction in Chang-Ji Economic Circle
water Article Water Resource Carrying Capacity Based on Water Demand Prediction in Chang-Ji Economic Circle Ge Wang 1,2,3,4, Changlai Xiao 1,2,3,4, Zhiwei Qi 1,2,3,4, Xiujuan Liang 1,2,3,4,*, Fanao Meng 1,2,3,4 and Ying Sun 1,2,3,4 1 Key Laboratory of Groundwater Resources and Environment, Jilin University, Ministry of Education, No 2519, Jiefang Road, Changchun 130021, China; [email protected] (G.W.); [email protected] (C.X.); [email protected] (Z.Q.); [email protected] (F.M.); [email protected] (Y.S.) 2 Jilin Provincial Key Laboratory of Water Resources and Environment, Jilin University, Changchun 130021, China 3 National-Local Joint Engineering Laboratory of In-Situ Conversion, Drilling and Exploitation Technology for Oil Shale, Changchun 130021, China 4 College of New Energy and Environment, Jilin University, No 2519, Jiefang Road, Changchun 130021, China * Correspondence: [email protected] Abstract: In view of the large spatial difference in water resources, the water shortage and deteriora- tion of water quality in the Chang-Ji Economic Circle located in northeast China, the water resource carrying capacity (WRCC) from the perspective of time and space is evaluated. We combine the gray correlation analysis and multiple linear regression models to quantitatively predict water supply and demand in different planning years, which provide the basis for quantitative analysis of the WRCC. The selection of research indicators also considers the interaction of social economy, water resources, and water environment. Combined with the fuzzy comprehensive evaluation method, the gray corre- lation analysis and multiple linear regression models to quantitatively and qualitatively evaluate the WRCC under different social development plans. -

Printmgr File
DEFINITIONS AND GLOSSARY In this prospectus, unless the context otherwise requires, the following terms shall have the meanings set out below: “Anci District Huimin Village and Huimin Village Bank Company Limited of Anci, Langfang Township Bank” ( ), a joint stock company with limited liability incorporated in the PRC on December 6, 2011, in which the Bank holds a 51% equity interest. The remaining nine shareholders hold 49% equity interest in Anci District Huimin Village and Township Bank “Anping Huimin Village and Township Anping Huimin Village Bank Co., Ltd. Bank” ( ), a joint stock company with limited liability incorporated in the PRC on December 24, 2013, in which the Bank holds a 36% equity interest. The remaining 30 shareholders hold 64% equity interest in Anping Huimin Village and Township Bank. The Bank and five other shareholders (holding an aggregate of 39.16% equity interest in Anping Huimin Village and Township Bank) entered into agreements to act in concert with respect to their voting rights to be exercised at board meetings and shareholders’ general meetings of Anping Huimin Village and Township Bank. Anping Huimin Village and Township Bank is deemed to be under the Bank’s control and to be the Group’s subsidiary “Application Form(s)” WHITE, YELLOW and GREEN application forms or, where the context so requires, any of them, relating to the Hong Kong Public Offering “Baicheng Taobei Huimin Village and Baicheng Taobei Huimin Village Bank Co., Ltd. Township Bank” ( ), a joint stock company with limited liability incorporated in the PRC on November 23, 2015, in which the Bank holds a 49% equity interest. -

2.15 Jilin Province Jilin Province Jixin Group Co. Ltd., Affiliated to the Jilin Provincial Prison Administration Bureau, Has 22
2.15 Jilin Province Jilin Province Jixin Group Co. Ltd., affiliated to the Jilin Provincial Prison Administration Bureau, has 22 prison enterprises Legal representative of the prison company: Feng Gang, Chairman of Jilin Jixin Group Co., Ltd. His official positions in the prison system: Party Committee Member of Jilin Provincial Justice Department, Party Committee Secretary and Director of Jilin Provincial Prison Administration Bureau1 According to the “Notice on Issuing ‘Jilin Province People’s Government Institutional Reform Program’ from the General Office of the CCP Central Committee and the General Office of the State Council” (Ting Zi [2008] No. 25), the Jilin Provincial Prison Administration Bureau (Deputy-department level) was set up as a management agency under the Provincial Justice Department.2 Business areas: The company manages state-owned operating assets of the enterprises within province’s prison system; production, processing and sale of electromechanical equipment (excluding cars), chemical products, apparels, cement, construction materials; production and sale of agricultural and sideline products; labor processing No. Company Name of the Legal Person Legal Registered Business Scope Company Notes on the Prison Name Prison, to which and representative Capital Address the Company Shareholder(s) / Title Belongs 1 Jilin Jixin Jilin Provincial State-owned Feng Gang 70.67 The company manages state-owned 1000 Xinfa According to the “Notice on Issuing Group Co., Prison Asset Chairman of Jilin million operating assets of the -

Jilin Province Chuncheng Heating Company Limited* 吉林省春城
THIS CIRCULAR IS IMPORTANT AND REQUIRES YOUR IMMEDIATE ATTENTION If you are in any doubt as to any aspect of this circular or as to the action to be taken, you should consult your securities broker or other registered securities dealer, bank manager, solicitor, professional accountant or other professional adviser. If you have sold or transferred all your shares in Jilin Province Chuncheng Heating Company Limited*, you should at once hand this circular and the accompanying form of proxy to the purchaser or transferee or to the bank, securities broker or other agent through whom the sale or transfer was effected for transmission to the purchaser or transferee. Hong Kong Exchanges and Clearing Limited and The Stock Exchange of Hong Kong Limited take no responsibility for the contents of this circular, make no representation as to its accuracy or completeness and expressly disclaim any liability whatsoever for any loss howsoever arising from or in reliance upon the whole or any part of the contents of this circular. Jilin Province Chuncheng Heating Company Limited* 吉林省春城熱力股份有限公司 (A joint stock limited liability company incorporated in the People’s Republic of China) (Stock code: 1853) REPORT OF THE DIRECTORS FOR THE YEAR 2020, REPORT OF THE SUPERVISORY COMMITTEE FOR THE YEAR 2020, ANNUAL REPORT FOR THE YEAR 2020, AUDITED FINANCIAL STATEMENTS FOR THE YEAR 2020, PROFIT DISTRIBUTION PLAN FOR THE YEAR 2020, REMUNERATION PLAN FOR DIRECTORS FOR THE YEAR 2021, REMUNERATION PLAN FOR SUPERVISORS FOR THE YEAR 2021, RE-APPOINTMENT OF THE COMPANY’S AUDITORS FOR THE YEAR 2021, PROPOSED ELECTION OF NEW SESSION OF THE BOARD OF DIRECTORS AND THE SUPERVISORY COMMITTEE, NON-EXEMPT CONTINUING CONNECTED TRANSACTIONS, GENERAL MANDATE TO ISSUE SHARES AND NOTICE OF 2020 ANNUAL GENERAL MEETING Independent Financial Adviser to the Independent Board Committee and the Independent Shareholders Giraffe Capital Limited The letter from the Board is set out on pages 5 to 28 of this circular. -

Shengjing Bank Co., Ltd.* (A Joint Stock Company Incorporated in the People's Republic of China with Limited Liability) Stock Code: 02066 Annual Report Contents
Shengjing Bank Co., Ltd.* (A joint stock company incorporated in the People's Republic of China with limited liability) Stock Code: 02066 Annual Report Contents 1. Company Information 2 8. Directors, Supervisors, Senior 68 2. Financial Highlights 4 Management and Employees 3. Chairman’s Statement 7 9. Corporate Governance Report 86 4. Honours and Awards 8 10. Report of the Board of Directors 113 5. Management Discussion and 9 11. Report of the Board of Supervisors 121 Analysis 12. Social Responsibility Report 124 5.1 Environment and Prospects 9 13. Internal Control 126 5.2 Development Strategies 10 14. Independent Auditor’s Report 128 5.3 Business Review 11 15. Financial Statements 139 5.4 Financial Review 13 16. Notes to the Financial Statements 147 5.5 Business Overview 43 17. Unaudited Supplementary 301 5.6 Risk Management 50 Financial Information 6. Significant Events 58 18. Organisational Chart 305 7. Change in Share Capital and 60 19. The Statistical Statements of All 306 Shareholders Operating Institution of Shengjing Bank 20. Definition 319 * Shengjing Bank Co., Ltd. is not an authorised institution within the meaning of the Banking Ordinance (Chapter 155 of the Laws of Hong Kong), not subject to the supervision of the Hong Kong Monetary Authority, and not authorised to carry on banking and/or deposit-taking business in Hong Kong. COMPANY INFORMATION Legal Name in Chinese 盛京銀行股份有限公司 Abbreviation in Chinese 盛京銀行 Legal Name in English Shengjing Bank Co., Ltd. Abbreviation in English SHENGJING BANK Legal Representative ZHANG Qiyang Authorised Representatives ZHANG Qiyang and ZHOU Zhi Secretary to the Board of Directors ZHOU Zhi Joint Company Secretaries ZHOU Zhi and KWONG Yin Ping, Yvonne Registered and Business Address No. -
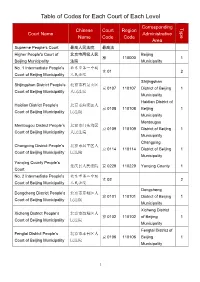
Table of Codes for Each Court of Each Level
Table of Codes for Each Court of Each Level Corresponding Type Chinese Court Region Court Name Administrative Name Code Code Area Supreme People’s Court 最高人民法院 最高法 Higher People's Court of 北京市高级人民 Beijing 京 110000 1 Beijing Municipality 法院 Municipality No. 1 Intermediate People's 北京市第一中级 京 01 2 Court of Beijing Municipality 人民法院 Shijingshan Shijingshan District People’s 北京市石景山区 京 0107 110107 District of Beijing 1 Court of Beijing Municipality 人民法院 Municipality Haidian District of Haidian District People’s 北京市海淀区人 京 0108 110108 Beijing 1 Court of Beijing Municipality 民法院 Municipality Mentougou Mentougou District People’s 北京市门头沟区 京 0109 110109 District of Beijing 1 Court of Beijing Municipality 人民法院 Municipality Changping Changping District People’s 北京市昌平区人 京 0114 110114 District of Beijing 1 Court of Beijing Municipality 民法院 Municipality Yanqing County People’s 延庆县人民法院 京 0229 110229 Yanqing County 1 Court No. 2 Intermediate People's 北京市第二中级 京 02 2 Court of Beijing Municipality 人民法院 Dongcheng Dongcheng District People’s 北京市东城区人 京 0101 110101 District of Beijing 1 Court of Beijing Municipality 民法院 Municipality Xicheng District Xicheng District People’s 北京市西城区人 京 0102 110102 of Beijing 1 Court of Beijing Municipality 民法院 Municipality Fengtai District of Fengtai District People’s 北京市丰台区人 京 0106 110106 Beijing 1 Court of Beijing Municipality 民法院 Municipality 1 Fangshan District Fangshan District People’s 北京市房山区人 京 0111 110111 of Beijing 1 Court of Beijing Municipality 民法院 Municipality Daxing District of Daxing District People’s 北京市大兴区人 京 0115 -

Interim Report 2020 Contents
INTERIM REPORT 2020 CONTENTS Corporate Information 2 Financial Highlights 4 Consolidated Statement of Profit or Loss 5 Consolidated Statement of Profit or Loss and Other Comprehensive Income 6 Consolidated Statement of Financial Position 7 Consolidated Statement of Changes in Equity 9 Condensed Consolidated Cash Flow Statement 11 Notes to the Unaudited Interim Financial Report 12 Independent Review Report 27 Management Discussion and Analysis 28 Other Information 37 CORPORATE INFORMATION BOARD OF DIRECTORS REGISTERED OFFICE Executive Directors Cricket Square, Hutchins Drive Mr. Zhao Jinmin (Chairman) PO Box 2681, Grand Cayman KY1-1111 Mr. Liu Yingwu Cayman Islands Mr. Xu Huilin (Chief Executive Officer) Mr. Yuan Limin PRINCIPAL PLACE OF BUSINESS IN Mr. Ma Haidong THE PRC No. 2101, Unit 1 Independent Non-Executive Directors Block 23, Zone G Ms. Su Dan Solana 2, Erdao District Mr. Zhang Zhifeng Changchun Mr. Lau Ying Kit Jilin Province, the PRC COMPANY SECRETARY PRINCIPAL PLACE OF BUSINESS IN Mr. Lo Wai Kit, ACCA, FCPA, CFA HONG KONG Suite 4310, 43/F AUTHORIZED REPRESENTATIVES China Resources Building Mr. Xu Huilin 26 Harbour Road Mr. Lo Wai Kit Wanchai Hong Kong MEMBERS OF AUDIT COMMITTEE Mr. Lau Ying Kit (Chairman) PRINCIPAL SHARE REGISTRAR AND Ms. Su Dan TRANSFER OFFICE Mr. Zhang Zhifeng Conyers Trust Company (Cayman) Limited Cricket Square MEMBERS OF REMUNERATION COMMITTEE Hutchins Drive, P.O. Box 2681 Mr. Zhang Zhifeng (Chairman) Grand Cayman KY1-1111 Mr. Liu Yingwu Cayman Islands Ms. Su Dan HONG KONG BRANCH SHARE REGISTRAR MEMBERS OF NOMINATION COMMITTEE AND TRANSFER OFFICE Ms. Su Dan (Chairman) Tricor Investor Services Limited Mr. Xu Huilin Level 54, Hopewell Centre Mr. -

Jilin Jiutai Rural Commercial Bank Corporation Limited* 吉
Hong Kong Exchanges and Clearing Limited and The Stock Exchange of Hong Kong Limited take no responsibility for the contents of this announcement, make no representation as to its accuracy or completeness and expressly disclaim any liability whatsoever for any loss howsoever arising from or in reliance upon the whole or any part of the contents of this announcement. JILIN JIUTAI RURAL COMMERCIAL BANK CORPORATION LIMITED* 吉林九台農村商業銀行股份有限公司* (A joint stock company incorporated in the People’s Republic of China with limited liability) (Stock code: 6122) 1. NOMINATION OF CANDIDATES FOR THE DIRECTORS OF THE FIFTH SESSION OF THE BOARD OF DIRECTORS 2. NOMINATION OF CANDIDATES FOR THE NON-EMPLOYEE SUPERVISORS OF THE FIFTH SESSION OF THE BOARD OF SUPERVISORS 3. REMUNERATION FOR THE RELEVANT DIRECTORS OF THE FIFTH SESSION OF THE BOARD OF DIRECTORS DURING THEIR TERMS OF OFFICE 4. REMUNERATION FOR THE RELEVANT SUPERVISORS OF THE FIFTH SESSION OF THE BOARD OF SUPERVISORS DURING THEIR TERMS OF OFFICE The board of directors (the “Board”) of Jilin Jiutai Rural Commercial Bank Corporation Limited (the “Bank”) hereby announces that in view of the requirements of the articles of association of the Bank (the “Articles”), the Board and the board of supervisors of the Bank (the “Board of Supervisors”) proposed to carry out the re-election. On March 30, 2021, the 16th meeting of the fourth session of the Board (the “Board Meeting”) approved the resolutions regarding the nomination of Mr. Gao Bing, Mr. Liang Xiangmin, Mr. Yuan Chunyu, Mr. Cui Qiang, Mr. Zhang Yusheng, Mr. Wu Shujun, Mr. Zhang Lixin, Ms.