Introduction B16 Operating Systems
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Apple Developer Enterprise Program License Agreement
LEIA ATENTAMENTE OS TERMOS E CONDIÇÕES DO CONTRATO DE LICENÇA ABAIXO ANTES DE BAIXAR OU USAR O SOFTWARE APPLE. ESTES TERMOS E CONDIÇÕES CONSTITUEM UM ACORDO LEGAL ENTRE SUA EMPRESA/ORGANIZAÇÃO E A APPLE. Apple Developer Enterprise Program License Agreement (para aplicativos de uso interno para funcionários) Propósito Sua empresa, organização ou instituição de ensino deseja usar o Software Apple (conforme definido abaixo) para desenvolver um ou mais Aplicativos de Uso Interno (conforme definido abaixo) para produtos da marca Apple com iOS, watchOS, tvOS, iPadOS e/ou macOS e implantar esses Aplicativos somente para uso interno de funcionários de Sua empresa, organização ou instituição de ensino ou para uso limitado conforme expressamente estabelecido neste documento. A Apple está disposta a conceder a Você uma licença limitada para usar o Software Apple a fim de desenvolver e testar Seus Aplicativos de Uso Interno e implantar tais Aplicativos internamente e conforme permitido neste Contrato nos termos e condições aqui estabelecidos. Você também poderá criar Bilhetes (conforme definido abaixo) para uso em produtos da marca Apple com iOS ou watchOS nos termos deste Contrato. Os Aplicativos de Uso Interno desenvolvidos para macOS podem ser distribuídos nos termos deste Contrato usando um Certificado Apple ou poderão ser distribuídos separadamente. Nota: este Programa é destinado a aplicativos personalizados de uso interno que forem desenvolvidos por Você para Suas finalidades comerciais específicas e somente para uso de Seus funcionários e, em casos limitados, outras partes, conforme estabelecido neste documento. Se Você deseja distribuir aplicativos para iOS, watchOS ou tvOS para terceiros ou obter um aplicativo de terceiros, Você deve usar a App Store ou a opção de distribuição personalizada de aplicativos. -

Apple II Versus Apple III Hardware Architecture Comments ______
_______________ Apple /// Computer Historical Information _______________ _____________________________________________________________________________ Apple II versus Apple III Hardware Architecture Comments _____________________________________________________________________________ December 2002 eMail correspondence between Steven Weyhrich Rick Auricchio (Apple) David Craig Compiled by David T Craig on 05 September 2004 __________________________________________________________________________________________ Apple II versus Apple III Hardware Architecture Comments -- December 2002 eMail correspondence between Steven Weyhrich, Rick Auricchio (Apple), David Craig Compiled by David T Craig on 05 September 2004 -- Page 1 of 23 _______________ Apple /// Computer Historical Information _______________ From: Steven Weyhrich Sent: Saturday, December 14, 2002 2:05 PM To: David Craig Subject: CD's I am sorry I didn't e-mail you sooner to let you know that I did receive the package of CD's that you kindly sent to me. What a treasure trove of information you have collected and organized! I have not yet had an opportunity to look at them in detail, but what I have seen looks pretty neat. You seem to be more of a trivia pack rat than even _I_ am! I did notice one item: The Byte magazine "letter from Wozniak" does appear to be a joke by the guy writing the column, rather than a true letter from Wozniak. This may not be news to you, but I thought I'd put my two cents worth. :-) You asked something about whether or not a disassembly of PRODOS had been done anywhere. I had thought that the writers of Beneath Apple ProDOS had published a disassembly listing, but it was only a listing of pertinent parts of the code (what a certain part of the code does, not the disassembly listing of the opcodes). -

Apple Developer Enterprise Program License Agreement
LEIA CUIDADOSAMENTE OS SEGUINTES TERMOS E CONDIÇÕES DO CONTRATO DE LICENÇA ANTES DE DESCARREGAR OU DE UTILIZAR O SOFTWARE APPLE. OS PRESENTES TERMOS E CONDIÇÕES CONSTITUEM UM CONTRATO LEGAL ENTRE A EMPRESA/ORGANIZAÇÃO DO UTILIZADOR E A APPLE. Contrato de Licença do Apple Developer Enterprise Program (para aplicações internas e de utilização interna para os funcionários) Objetivo A empresa, a organização ou a instituição de ensino do Utilizador gostaria de utilizar o Software Apple (conforme definido abaixo) para desenvolver uma ou mais Aplicações de utilização interna (conforme definido abaixo) para produtos da marca Apple com o iOS, watchOS, tvOS, iPadOS e/ou macOS, e para implementar as referidas Aplicações apenas para utilização interna pelos funcionários na empresa, organização ou instituição de ensino do Utilizador, ou para utilização limitada conforme expressamente aqui previsto. A Apple está disposta a conceder ao Utilizador uma licença limitada para utilizar o Software Apple para desenvolver e testar as respetivas Aplicações de utilização interna e para implementar as referidas Aplicações internamente e de outra forma permitida pelo presente em conformidade com os termos e condições estabelecidos no presente Contrato. O Utilizador também pode criar Passes (como definido abaixo) para utilização em produtos da marca Apple com o iOS ou watchOS ao abrigo do presente Contrato. As Aplicações de utilização interna desenvolvidas para macOS podem ser distribuídas ao abrigo do presente Contrato através de um Certificado Apple ou podem ser distribuídas em separado. Nota: O presente Programa destina-se a aplicações personalizadas de utilização interna, desenvolvidas pelo Utilizador para os respetivos fins empresariais específicos e apenas para utilização dos respetivos funcionários e, em casos limitados, por outras entidades específicas, conforme aqui previsto. -

The Big Tip Book for the Apple II Series 1986.Pdf
for the Apple®II Series ~ THE BIG TIP BOOK FOR THE APPLE II SERIES Bantam Computer Books Ask your bookseller for the books you have missed AMIGA DOS USER'S MANUAL by Commodore-Amiga, Inc. THE APPLE /le BOOK by Bill O'Brien THE COMMODORE 64 SURVIVAL MANUAL by Winn L. Rosch COMMODORE 128 PROGRAMMER'S REFERENCE GUIDE by Commodore Business Machines, Inc. EXPLORING ARTIFICIAL INTELLIGENCE ON YOUR APPLE II by Tim Hartnell EXPLORING ARTIFICIAL INTELLIGENCE ON YOUR COMMODORE 64 by Tim Hartnell EXPLORING ARTIFICIAL INTELLIGENCE ON YOUR IBM PC by Tim Hartnell EXPLORING THE UNIX ENVIRONMENT by The Waite Group/Irene Pasternack FRAMEWORK FROM THE GROUND UP by The Waite Group/Cynthia Spoor and Robert Warren HOW TO GET THE MOST OUT OF COMPUSERVE, 2d ed. by Charles Bowen and David Peyton HOW TO GET THE MOST OUT OF THE SOURCE by Charles Bowen and David Peyton MACINTOSH C PRIMER PLUS by The Waite Group/Stephen W. Prata THE MACINTOSH by Bill O'Brien THE NEW jr: A GUIDE TO IBM'S PCjr by Winn L. Rosch ORCHESTRATING SYMPHONY by The Waite Group/Dan Schafer PC-DOS/MS-DOS User's Guide to the Most Popular Operating System for Personal Computers by Alan M. Boyd POWER PAINTING: COMPUTER GRAPHICS ON THE MACINTOSH by Verne Bauman and Ronald Kidd/illustrated by Gasper Vaccaro SMARTER TELECOMMUNICATIONS Hands-On Guide to On-Line Computer Services by Charles Bowen and Stewart Schneider SWING WITH JAZZ: LOTUS JAZZ ON THE MACINTOSH by Datatech Publications Corp./Michael McCarty TEACH YOUR BABY TO USE A COMPUTER Birth Through Preschool by Victoria Williams, Ph.D. -

Using a Large Capacity Disk
ON THREE Presents ... The Universal Sider Drive For The Apple/// User's Guide Apple /// Universal Sider Drive User's ·Gulde Notice =========--------------------------------------------------------------------------------------------------------------- ON THREE reserves the right to make improvements in the product described in this · ··· · · guide at any time and without notice. Customer Satisfaction =================================------------------------------------------------------------------------------------------ If you discover physical defects in the media on which a software product is distributed, ON THREE will replace the media at no charge to you during the 90-day period after which you purchased the product. In addition, if ON THREE releases a corrective update to the software described· in this guide during the 90-day period after you purchased this package, ON THREE will replace the applicable diskette and documentation with the revised version at no cost to you during the six months after the date of purchase. A nominal charge will apply towards product enhancements. Limitations on Warranties and Liability ==============================-------------------------------------------------------------------- Even though ON THREE has tested the software and hardware described in this guide and reviewed its contents, neither ON THREE nor its software suppliers make any : f I warranty or representation, either express or implied, with respect to this guide or to the I . software described in this guide, their quality, performance, merchantability, or fitness for any particular purpose. As a result, this software and guide are sold "as is", and you the purchaser are assuming the entire risk as to their quality and performance. In no event will ON THREE or its software suppliers be liable for direct, indirect, incidental, or consequential damages resulting from any defect in the software or guide, even if they have been advised of the possibility of such damages. -

Apple Redl"Scovers the Apple II the Connector in the Previous Apple Iic-Apple's Own /Lc Memory
l'Iovember 1988 Vol. 4. 1'10. 10 ISSN 0885-40 I 7 newstand price: $2.50 Releasing the power.to everyone. photocopy charge per page: $0.15 .-.-.-.-.-.-.-.-.-.-.-.-.-.-.-.-.-.-.-.-.-.-.-.-.-.-.~ ---- "scovers the Apple II the connector in the previous Apple IIc-Apple's own /lc memory Apple redl . expansion cards will not worl< in this computer. Furthermore. Apple It.s been a long. lonesome four yea.,; for Apple II enthuslasl5. Dut does nol intend to produce a memory card. a modem. or anal-panel now that Apple has succeeded in business with il5 Macintosh line. it is display lor the IIc-Plus. bur will leave development of these producl5 . to the third-party community. readmitting to and recommitting to the Apple II. Apple demonstrated Up to three additional drives can be connecled to the IIc-Plus il5 born-again Apple II attitude at Septembers Applefest in San fran- cisco with major new producl announcemenl5; with a confession. SmartPort connector. These can be a mix of Apple 3.5. UniDisk 3.5. from Apple's president. John Sculley. about Apple's treatment of the - or (one or two) 5.25'[lrives. A smartPort-compatible hard disk for the Apple II; and with a commitment to continue investing major research IIc was also introduced at Applefest by Chinook Technology. and development dollars in the Apple II family. .. The IIc-Plus weighs in at 7 pounds (3.2 kg). New product introductions included GS/OS, the 16-bit operating I thought tbere were serious tones of rapprochement in John system written specificaily the Apple IIgs that we've been waiting for. -

Apple Confidential 2.0 the Definitive History of the World's Most Colorful
vi Reviewers love Apple Confidential “The Apple story itself is here in all its drama.” New York Times Book Review “An excellent textbook for Apple historians.” San Francisco Chronicle “Written with humor, respect, and care, it absolutely is a must-read for every Apple fan.” InfoWorld “Pretty much irresistible is the only way to describe this quirky, highly detailed and illustrated look at the computer maker’s history.” The Business Reader Review “The book is full of basic facts anyone will appreciate. But it’s also full of interesting extras that Apple fanatics should love.” Arizona Republic “I must warn you. This 268-page book is hard to put down for a MacHead like me, and probably you too.” MacNEWS “You’ll love this book. It’s a wealth of information.” AppleInsider “Rife with gems that will appeal to Apple fanatics and followers of the computer industry.” Amazon.com “Mr. Linzmayer has managed to deliver, within the confines of a single book, just about every juicy little tidbit that was ever leaked from the company.” MacTimes “The most entertaining book about Apple yet to be published.” Booklist i …and readers love it too! “Congratulations! You should be very proud. I picked up Apple Confidential and had a hard time putting it down. Obviously, you invested a ton of time in this. I hope it zooms off the shelves.” David Lubar, Nazareth, PA “I just read Apple Confidentialfrom cover to cover…you have written a great book!” Jason Whong, Rochester, NY “There are few books out there that reveal so much about Apple and in such a fun and entertaining manner. -

~Inted Circuit Board Computer Aided Design on the Apple Ii Plus;
3 ~INTED CIRCUIT BOARD COMPUTER AIDED DESIGN ON THE APPLE II PLUS; A Thesis Presented to The Faculty of the College of Engineering and Technology Ohio University In Partial Fulfillment of the Requirements for the Degree Master of Science by Yi Chia Tang Vorhis June, 1984 iii ACKNOWLEDGEMENTS I would like to thank Dr. James C. Gilfert for his advice and help throughout the development of this thesis. I found this an enjoyable project, and am glad to have had this opportunity. I am also indebted to Dr. Harold F. Klock for his informative lectures and personal assistance during my graduate study. Last, I would like to thank my family. I am especially grateful to my aunt and uncle, Dr. and Dr. C. T. Eyron Kao, for supporting my advanced study in the United States. COPYRIGHT ACKNOWLEDGEMENT Apple, Apple II Plus, Applesoft, DOS 3.3 are copyrighted by the Apple Computer Company. VAX 11-730 is a registered trademark of the Digital Equipment Corporation. iv Contents Chapter 1 Introduction••••••••••••••••••••••••••••••••••••1 Chapter 2 System Characteristics / Set Up •••••••••••••••••5 Section 1 Memory ••••••••••••••••••••••••••••••••5 Section 2 Solder Side and Component Side Array.10 Section 3 Fundamentals of Applesoft BASIC ••••••21 Section 4 Files••••••••••••••••••••••••••••••••24 Chapter 3 Program Organization•••••••••••••••••••••••••••28 Section 1 PART 1 •••••••••••••••••••••••••••••••28 Section 2 PART 11 ••••••••••••••••••••••••••••••33 Section 3 PART 111 •••••••••••••••••••••••••••••36 Chapter 4 Program Features•••••••••••••••••••••••••••••••45 -

Apple2info.Net: Apple II Information
apple2info.net: Apple II Information This page contains links to other Apple II related web sites. If you have any information on sites listed in the Not Currently Available section, let me know. Please email me at if something needs changed, or better yet, register and edit it yourself. :) News & Information Sites These sites have Apple II news, information, links, message boards, classified ads, etc. Some of them have files to download. 1MHz (Carrington Vanston) - http://monsterfeet.com/1mhz [1] A free Apple II podcast originating from Toronto, Canada. Also available on iTunes [2]. 1000BiT - http://www.1000bit.net [3] This site has a large collection of manuals, advertisements, brochures, and other information on 8-bit computers, including the Apple II. Available in English and Italian. 8-Bit Sound and Fury (Simon Williams) - http://eightbitsoundandfury.ld8.org/ [4] Possibly the only place on the internet devoted exclusively creating music on the 8-bit Apple II computers. Lots of information and downloads for making music on 8-bit Apple II's including sofware, hardware, documentation, and audio files. A2 Central (Sean Fahey) - http://www.a2central.com/ [5] A2Central is an online Apple II User Group with news related to the Apple II, a directory of developers working on Apple II hardware and software projects, links to other sites, and more. Efforts are underway to make significant additions to the services and content offered. A2-Web - http://www.a2-web.com/ [6] Billing itself as "The Mother of All Apple II Web Sites," this large site is loaded with links to and information on Apple II hardware, software, and vendor sites, emulators, message boards, classified ads, faqs, and more. -

A Technical History of Apple's Operating Systems
A Technical History of Apple’s Operating Systems Amit Singh A Supplementary Document for Chapter 1 from the book Mac OS X Internals: A Systems Approach. Copyright © Amit Singh. All Rights Reserved. Portions Copyright © Pearson Education. Document Version 2.0.1 (July 28, 2006) Latest version available at http://osxbook.com/book/bonus/chapter1/ This page intentionally left blank. Dear Reader This is a supplementary document for Chapter 1 from my book Mac OS X In- ternals: A Systems Approach. A subset (about 30%) of this document ap- pears in the book as the first chapter with the title Origins of Mac OS X. This document is titled A Technical History of Apple’s Operating Systems. Whereas the book’s abridged version covers the history of Mac OS X, this document’s coverage is considerably broader. It encompasses not only Mac OS X and its relevant ancestors, but the various operating systems that Apple has dabbled with since the company’s inception, and many other systems that were direct or indirect sources of inspiration. This was the first chapter I wrote for the book. It was particularly difficult to write in terms of the time and other resources required in researching the mate- rial. I often had to find and scavenge ancient documentation, software, and hardware (all actual screenshots shown in this document were captured first hand.) However, I couldn’t include the chapter in its original form in the book. The book grew in size beyond everybody’s expectations—1680 pages! There- fore, it was hard to justify the inclusion of this much history, even if it is inter- esting history. -

The ADIOS-81 Apple Disk Interface and Operating System Reference Manual-1981.Pdf
Ih e 4 / 10 5 - 81 := Apple Disk Interface nna Operating Mystem R ef e r on n> M n n u n ; N ov emb e r 1981 Copyright (C ) - 1981 A ll R tgh ts R eserved W o rldw id e Th e s0F T W AQ ERO U S E P . 0 . B ox 1117 4 nonolulu r Hawa ii 96 82 8 U . S . A . X M TO G C E C opy righ t (C), 19 81 by Th e Soft W areh ouse. A ll R iqhts R ese rv ed W o rldw id e . No Pa rt of th is m anual n ay be r e p r o d u c e d , t r a n s m i t t e d , t r a n s c r i b e d , s t o r e d i n a re tr iev al sy stem , oz trans lated into a ny hum œ n or com p u ter l an g u aq e : in any f o rm o r by a ny m e a n s , e l e c t ro n ic , m echan icalz m açneticr op tica l, chen icalr m anual , o: oth er- w ise , w ith ou t khe exp ress w ritken p e rm zss ion o f The Sof t W areh ouse , P.O . Box 1117 4 , Eon o lulu , Eaw ai i 96 82 8 , D.S .N TQ A D FA A P K M T N c A D IO S is a tr ad en a rk o f T h e S o f t W a r eh o u s e . -
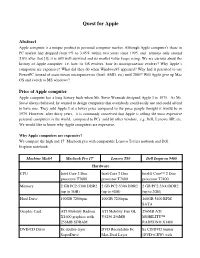
Quest for Apple
Quest for Apple Abstract Apple computer is a unique product in personal computer market. Although Apple computer©s share in PC market had dropped from 9% to 3.45% within two years since 1995, and remains only around 2.0% after that [1], it is still well survived and its market value keeps rising. We are curious about the history of Apple computer, i.e. how its OS evolves, how its microprocessor evolves? Why Apple's computers are expensive? What did they do when Windows95 appeared? Why had it persisted to use PowerPC instead of mainstream microprocessor (Intel, AMD, etc) until 2005? Will Apple give up Mac OS and switch to MS windows? Price of Apple computer Apple computer has a long history back when Mr. Steve Wozniak designed Apple I in 1975. As Mr. Steve always believed, he wanted to design computers that everybody could easily use and could afford to have one. They sold Apple I at a lower price compared to the price people thought it would be in 1975. However, after thirty years, it is commonly conceived that Apple is selling the most expensive personal computers in the world, compared to PCs sold by other vendors, e.g. Dell, Lenovo, HP, etc. We would like to know why Apple computers are expensive. Why Apple computers are expensive? We compare the high end 17' Macbook pro with comparable Lenovo Tseries notbook and Dell Inspiron notebook. Machine Model Macbook Pro 17' Lenovo T60 Dell Inspiron 9400 Hardware CPU Intel Core 2 Duo Intel Core 2 Duo Intel® Core™ 2 Duo processor T7600 processor T7600 processor T7400 Memory 2 GB PC2-5300 DDR2