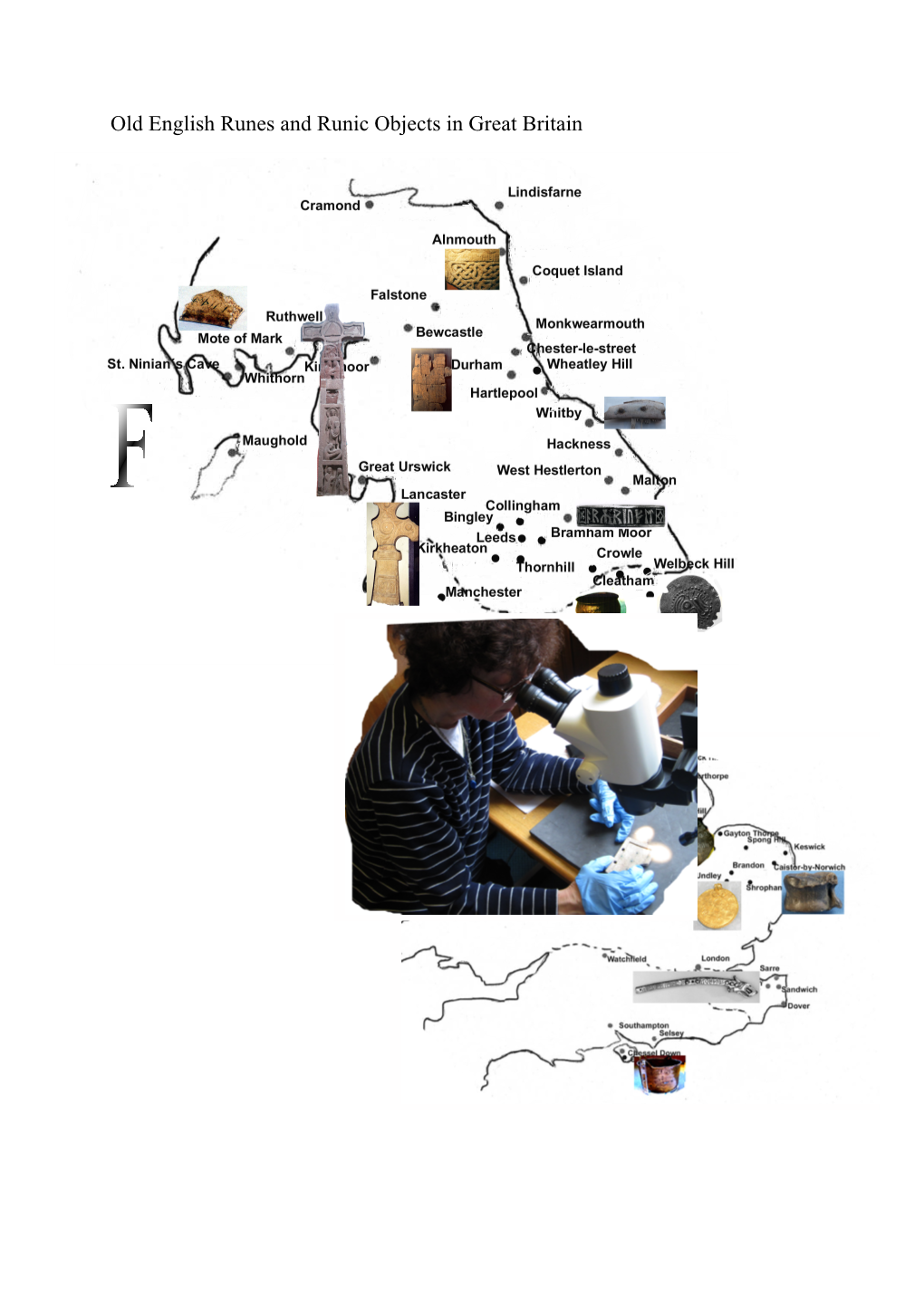
Old English Runes and Runic Objects in Great Britain
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

ISO Basic Latin Alphabet
ISO basic Latin alphabet The ISO basic Latin alphabet is a Latin-script alphabet and consists of two sets of 26 letters, codified in[1] various national and international standards and used widely in international communication. The two sets contain the following 26 letters each:[1][2] ISO basic Latin alphabet Uppercase Latin A B C D E F G H I J K L M N O P Q R S T U V W X Y Z alphabet Lowercase Latin a b c d e f g h i j k l m n o p q r s t u v w x y z alphabet Contents History Terminology Name for Unicode block that contains all letters Names for the two subsets Names for the letters Timeline for encoding standards Timeline for widely used computer codes supporting the alphabet Representation Usage Alphabets containing the same set of letters Column numbering See also References History By the 1960s it became apparent to thecomputer and telecommunications industries in the First World that a non-proprietary method of encoding characters was needed. The International Organization for Standardization (ISO) encapsulated the Latin script in their (ISO/IEC 646) 7-bit character-encoding standard. To achieve widespread acceptance, this encapsulation was based on popular usage. The standard was based on the already published American Standard Code for Information Interchange, better known as ASCII, which included in the character set the 26 × 2 letters of the English alphabet. Later standards issued by the ISO, for example ISO/IEC 8859 (8-bit character encoding) and ISO/IEC 10646 (Unicode Latin), have continued to define the 26 × 2 letters of the English alphabet as the basic Latin script with extensions to handle other letters in other languages.[1] Terminology Name for Unicode block that contains all letters The Unicode block that contains the alphabet is called "C0 Controls and Basic Latin". -

Proposal for Generation Panel for Latin Script Label Generation Ruleset for the Root Zone
Generation Panel for Latin Script Label Generation Ruleset for the Root Zone Proposal for Generation Panel for Latin Script Label Generation Ruleset for the Root Zone Table of Contents 1. General Information 2 1.1 Use of Latin Script characters in domain names 3 1.2 Target Script for the Proposed Generation Panel 4 1.2.1 Diacritics 5 1.3 Countries with significant user communities using Latin script 6 2. Proposed Initial Composition of the Panel and Relationship with Past Work or Working Groups 7 3. Work Plan 13 3.1 Suggested Timeline with Significant Milestones 13 3.2 Sources for funding travel and logistics 16 3.3 Need for ICANN provided advisors 17 4. References 17 1 Generation Panel for Latin Script Label Generation Ruleset for the Root Zone 1. General Information The Latin script1 or Roman script is a major writing system of the world today, and the most widely used in terms of number of languages and number of speakers, with circa 70% of the world’s readers and writers making use of this script2 (Wikipedia). Historically, it is derived from the Greek alphabet, as is the Cyrillic script. The Greek alphabet is in turn derived from the Phoenician alphabet which dates to the mid-11th century BC and is itself based on older scripts. This explains why Latin, Cyrillic and Greek share some letters, which may become relevant to the ruleset in the form of cross-script variants. The Latin alphabet itself originated in Italy in the 7th Century BC. The original alphabet contained 21 upper case only letters: A, B, C, D, E, F, Z, H, I, K, L, M, N, O, P, Q, R, S, T, V and X. -

Processing South Asian Languages Written in the Latin Script: the Dakshina Dataset
Processing South Asian Languages Written in the Latin Script: the Dakshina Dataset Brian Roarky, Lawrence Wolf-Sonkiny, Christo Kirovy, Sabrina J. Mielkez, Cibu Johnyy, Işın Demirşahiny and Keith Hally yGoogle Research zJohns Hopkins University {roark,wolfsonkin,ckirov,cibu,isin,kbhall}@google.com [email protected] Abstract This paper describes the Dakshina dataset, a new resource consisting of text in both the Latin and native scripts for 12 South Asian languages. The dataset includes, for each language: 1) native script Wikipedia text; 2) a romanization lexicon; and 3) full sentence parallel data in both a native script of the language and the basic Latin alphabet. We document the methods used for preparation and selection of the Wikipedia text in each language; collection of attested romanizations for sampled lexicons; and manual romanization of held-out sentences from the native script collections. We additionally provide baseline results on several tasks made possible by the dataset, including single word transliteration, full sentence transliteration, and language modeling of native script and romanized text. Keywords: romanization, transliteration, South Asian languages 1. Introduction lingua franca, the prevalence of loanwords and code switch- Languages in South Asia – a region covering India, Pak- ing (largely but not exclusively with English) is high. istan, Bangladesh and neighboring countries – are generally Unlike translations, human generated parallel versions of written with Brahmic or Perso-Arabic scripts, but are also text in the native scripts of these languages and romanized often written in the Latin script, most notably for informal versions do not spontaneously occur in any meaningful vol- communication such as within SMS messages, WhatsApp, ume. -

Characters for Classical Latin
Characters for Classical Latin David J. Perry version 13, 2 July 2020 Introduction The purpose of this document is to identify all characters of interest to those who work with Classical Latin, no matter how rare. Epigraphers will want many of these, but I want to collect any character that is needed in any context. Those that are already available in Unicode will be so identified; those that may be available can be debated; and those that are clearly absent and should be proposed can be proposed; and those that are so rare as to be unencodable will be known. If you have any suggestions for additional characters or reactions to the suggestions made here, please email me at [email protected] . No matter how rare, let’s get all possible characters on this list. Version 6 of this document has been updated to reflect the many characters of interest to Latinists encoded as of Unicode version 13.0. Characters are indicated by their Unicode value, a hexadecimal number, and their name printed IN SMALL CAPITALS. Unicode values may be preceded by U+ to set them off from surrounding text. Combining diacritics are printed over a dotted cir- cle ◌ to show that they are intended to be used over a base character. For more basic information about Unicode, see the website of The Unicode Consortium, http://www.unicode.org/ or my book cited below. Please note that abbreviations constructed with lines above or through existing let- ters are not considered separate characters except in unusual circumstances, nor are the space-saving ligatures found in Latin inscriptions unless they have a unique grammatical or phonemic function (which they normally don’t). -

Greek Type Design Introduction
A primer on Greek type design by Gerry Leonidas T the 1997 ATypI Conference at Reading I gave a talk Awith the title ‘Typography & the Greek language: designing typefaces in a cultural context.’ The inspiration for that talk was a discussion with Christopher Burke on designing typefaces for a script one is not linguistically familiar with. My position was that knowledge and use of a language is not a prerequisite for understanding the script to a very high, if not conclusive, degree. In other words, although a ‘typographically attuned’ native user should test a design in real circumstances, any designer could, with the right preparation and monitoring, produce competent typefaces. This position was based on my understanding of the decisions a designer must make in designing a Greek typeface. I should add that this argument had two weak points: one, it was based on a small amount of personal experience in type design and a lot of intuition, rather than research; and, two, it was quite possible that, as a Greek, I was making the ‘right’ choices by default. Since 1997, my own work proved me right on the first point, and that of other designers – both Greeks and non- Greeks – on the second. The last few years saw multilingual typography literally explode. An obvious arena was the broader European region: the Amsterdam Treaty of 1997 which, at the same time as bringing the European Union closer to integration on a number of fields, marked a heightening of awareness in cultural characteristics, down to an explicit statement of support for dialects and local script variations. -

Nemeth Code Uses Some Parts of Textbook Format but Has Some Idiosyncrasies of Its Own
This book is a compilation of research, in “Understanding and Tracing the Problem faced by the Visually Impaired while doing Mathematics” as a Diploma project by Aarti Vashisht at the Srishti School of Art, Design and Technology, Bangalore. 6 DOTS 64 COMBINATIONS A Braille character is formed out of a combination of six dots. Including the blank space, sixty four combinations are possible using one or more of these six dots. CONTENTS Introduction 2 About Braille 32 Mathematics for the Visually Impaired 120 Learning Mathematics 168 C o n c l u s i o n 172 P e o p l e a n d P l a c e s 190 Acknowledgements INTRODUCTION This project tries to understand the nature of the problems that are faced by the visually impaired within the realm of mathematics. It is a summary of my understanding of the problems in this field that may be taken forward to guide those individuals who are concerned about this subject. My education in design has encouraged interest in this field. As a designer I have learnt to be aware of my community and its needs, to detect areas where design can reach out and assist, if not resolve, a problem. Thus began, my search, where I sought to grasp a fuller understanding of the situation by looking at the various mediums that would help better communication. During the project I realized that more often than not work happened in individual pockets which in turn would lead to regionalization of many ideas and opportunities. Data collection got repetitive, which would delay or sometimes even hinder the process. -

Encoding Diversity for All the World's Languages
Encoding Diversity for All the World’s Languages The Script Encoding Initiative (Universal Scripts Project) Michael Everson, Evertype Westport, Co. Mayo, Ireland Bamako, Mali • 6 May 2005 1. Current State of the Unicode Standard • Unicode 4.1 defines over 97,000 characters 1. Current State of the Unicode Standard: New Script Additions Unicode 4.1 (31 March 2005): For Unicode 5.0 (2006): Buginese N’Ko Coptic Balinese Glagolitic Phags-pa New Tai Lue Phoenician Nuskhuri (extends Georgian) Syloti Nagri Cuneiform Tifinagh Kharoshthi Old Persian Cuneiform 1. Current State of the Unicode Standard • Unicode 4.1 defines over 97,000 characters • Unicode covers over 50 scripts (many of which are used for languages with over 5 million speakers) 1. Current State of the Unicode Standard • Unicode 4.1 defines over 97,000 characters • Unicode covers over 50 scripts (often used for languages with over 5 million speakers) • Unicode enables millions of users worldwide to view web pages, send e-mails, converse in chat-rooms, and share text documents in their native script 1. Current State of the Unicode Standard • Unicode 4.1 defines over 97,000 characters • Unicode covers over 50 scripts (often used for languages with over 5 million speakers) • Unicode enables millions of users worldwide to view web pages, send e-mails, converse in chat- rooms, and share text documents in their native script • Unicode is widely supported by current fonts and operating systems, but… Over 80 scripts are missing! Missing Modern Minority Scripts India, Nepal, Southeast Asia China: -

Ancient and Other Scripts
The Unicode® Standard Version 13.0 – Core Specification To learn about the latest version of the Unicode Standard, see http://www.unicode.org/versions/latest/. Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and the publisher was aware of a trade- mark claim, the designations have been printed with initial capital letters or in all capitals. Unicode and the Unicode Logo are registered trademarks of Unicode, Inc., in the United States and other countries. The authors and publisher have taken care in the preparation of this specification, but make no expressed or implied warranty of any kind and assume no responsibility for errors or omissions. No liability is assumed for incidental or consequential damages in connection with or arising out of the use of the information or programs contained herein. The Unicode Character Database and other files are provided as-is by Unicode, Inc. No claims are made as to fitness for any particular purpose. No warranties of any kind are expressed or implied. The recipient agrees to determine applicability of information provided. © 2020 Unicode, Inc. All rights reserved. This publication is protected by copyright, and permission must be obtained from the publisher prior to any prohibited reproduction. For information regarding permissions, inquire at http://www.unicode.org/reporting.html. For information about the Unicode terms of use, please see http://www.unicode.org/copyright.html. The Unicode Standard / the Unicode Consortium; edited by the Unicode Consortium. — Version 13.0. Includes index. ISBN 978-1-936213-26-9 (http://www.unicode.org/versions/Unicode13.0.0/) 1. -

Fonts for Latin Paleography
FONTS FOR LATIN PALEOGRAPHY Capitalis elegans, capitalis rustica, uncialis, semiuncialis, antiqua cursiva romana, merovingia, insularis majuscula, insularis minuscula, visigothica, beneventana, carolina minuscula, gothica rotunda, gothica textura prescissa, gothica textura quadrata, gothica cursiva, gothica bastarda, humanistica. User's manual 5th edition 2 January 2017 Juan-José Marcos [email protected] Professor of Classics. Plasencia. (Cáceres). Spain. Designer of fonts for ancient scripts and linguistics ALPHABETUM Unicode font http://guindo.pntic.mec.es/jmag0042/alphabet.html PALEOGRAPHIC fonts http://guindo.pntic.mec.es/jmag0042/palefont.html TABLE OF CONTENTS CHAPTER Page Table of contents 2 Introduction 3 Epigraphy and Paleography 3 The Roman majuscule book-hand 4 Square Capitals ( capitalis elegans ) 5 Rustic Capitals ( capitalis rustica ) 8 Uncial script ( uncialis ) 10 Old Roman cursive ( antiqua cursiva romana ) 13 New Roman cursive ( nova cursiva romana ) 16 Half-uncial or Semi-uncial (semiuncialis ) 19 Post-Roman scripts or national hands 22 Germanic script ( scriptura germanica ) 23 Merovingian minuscule ( merovingia , luxoviensis minuscula ) 24 Visigothic minuscule ( visigothica ) 27 Lombardic and Beneventan scripts ( beneventana ) 30 Insular scripts 33 Insular Half-uncial or Insular majuscule ( insularis majuscula ) 33 Insular minuscule or pointed hand ( insularis minuscula ) 38 Caroline minuscule ( carolingia minuscula ) 45 Gothic script ( gothica prescissa , quadrata , rotunda , cursiva , bastarda ) 51 Humanist writing ( humanistica antiqua ) 77 Epilogue 80 Bibliography and resources in the internet 81 Price of the paleographic set of fonts 82 Paleographic fonts for Latin script 2 Juan-José Marcos: [email protected] INTRODUCTION The following pages will give you short descriptions and visual examples of Latin lettering which can be imitated through my package of "Paleographic fonts", closely based on historical models, and specifically designed to reproduce digitally the main Latin handwritings used from the 3 rd to the 15 th century. -

Blindness and Runes
1 "...blindr er betri en brenndr séi..." Runes as a Tactile Writing System1 Frederick W. Schwink University of Illinois at Urbana-Champaign "Attempts to devise characters which could be understood by the blind through their sense of touch reach far back in the epoch of human progress, perhaps to the time when letters or figures were inscribed on some substance to be read by another, and certainly to the earliest period when efforts were made to give instruction to the sightless. The first recorded attempt to find such a means was made shortly after the beginning of the sixteenth century (ca. 1517), when Francisco Lucas of Saragossa, Spain, contrived a set of letters carved on thin tablets of wood." Best 1919:396 Haltr ríðr hrossi, hjörð rekr handar vanr, daufr vegr ok dugir; blindr er betri en brenndr séi, nýtr manngi nás. Hávamál 71 0.0 Introduction In the spring semester of 2010, I was faced with a didactic dilemna. In a graduate overview of the "History of the German Language," my students were to 1 I would like to thank Brad Blair for his willingness to share his time and expertise with me during the gestation of this project. My colleagues in the Department of Germanic Languages at UIUC provided helpful suggestions and encouragement when I presented a preliminary version of this project at a research workshop in Fall of 2009. Sharon Polomé gave me many of the reference works from her late husband's library that made this project feasible. Finally, heartfelt and sincere thanks to Marianne Kalinke, whose generous support has made it possible for me to attend this symposium. -

Proposed ALA-LC Romanization Table for the Deseret Alphabet October 27, 2015
Proposed ALA-LC Romanization Table for the Deseret Alphabet October 27, 2015 Background The Deseret alphabet is a phonetic alphabet developed in Utah Territory in the 19th century, under the direction of Brigham Young. Only four books were published in the Deseret alphabet in Brigham Young’s lifetime. After his death, the alphabet fell into obscurity. In the last few years, there has been a renewed interest in the alphabet as a historical curiosity, following the alphabet’s 2001 addition to the Unicode standard, filling blocks 10400 through 1044F. Due to advances in self-publishing, it has become possible for hobbyists to publish new works in the Deseret alphabet. To date we are aware of 34 recently published volumes, as well as some ephemera such as newsletters. Because the Deseret alphabet has ties to the Mormon movement and to Utah history, it is of interest to the special collections department at Brigham Young University’s Harold B. Lee Library, which collects extensively in areas related to Mormonism and Western history. Methodology After creating and then refining several versions of the romanization standard on my own, I reached out to Dirk Elzinga, a linguistics professor at Brigham Young University who recently co-authored a book on the history of the Deseret alphabet. Dr. Elzinga offered helpful feedback in approaching the romanization project, particularly in the case of how to best romanize the Deseret alphabet vowels. In creating the romanization standard, we have tried to follow the Procedural Guidelines for Proposed New or Revised Romanization Tables as closely as possible, although it has sometimes been challenging to apply them to an alphabet of this type. -

Reading Runes in Late Medieval Manuscripts
Runrön Runologiska bidrag utgivna av Institutionen för nordiska språk vid Uppsala universitet 24 Beck, Wolfgang, 2021: Reading Runes in Late Medieval Manuscripts. In: Read ing Runes. Proceedings of the Eighth International Symposium on Runes and Runic Inscriptions, Nyköping, Sweden, 2–6 September 2014. Ed. by MacLeod, Mindy, Marco Bianchi and Henrik Williams. Uppsala. (Run rön 24.) Pp. 225–232. DOI: 10.33063/diva-438880 © 2021 Wolfgang Beck (CC BY) WOLFGANG BECK Reading Runes in Late Medieval Manuscripts Abstract Whilst the runica manuscripta of English tradition, the Scandinavian rune poems, and the occasional use of runes as writers’ signatures and in the Old High German glosses have been comparatively well-researched, this does not apply to the same extent to the use of runes in late medieval (German) manuscripts. Runes and runic alphabets are found far less frequently in these, for example in the foreign alphabets in the Voyages by Sir John Mandeville or in a manuscript with medical remedies and an invocation of the devil; finally also in a magical treatise relating to the hermetic tradition. However, the use of runes in late medieval manuscripts cannot properly be explained by the functions usually attributed to the runica manuscripta. On the understanding that discussion of runica manuscripta is not just a runic problem in the narrow sense, but can also contribute to an understanding of medieval culture, the specific implications of the use and pragmatics of the late medieval runica manuscripta will be explored. The func- tion of runes in late medieval manuscripts should be determined at the same time with reference to secret written forms, readability and illegibility.