Forecasting Event Attendance with Anonymized Mobile Phone Data
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Katie Holmes Would Grace the Cover of Together Magazine
WWW.TOGETHERMAG.EU OCTOBER 2012 #33 K ATIE HOLMES Style princess BobbI BROWN Cosmetics queen JEAN-POL AUTU M N PIRON Belgium’s bathtub LOOK baron www.scapafashion.com Wow* *The new A-Class has arrived @ Mercedes Europa. Mercedes Europa. Where the star shines on diplomats. Official subsidiary of Mercedes-Benz Belgium Luxembourg • The most beautiful Mercedes-Benz window right in the heart of the European capital • Over 30 years of experience • Easy access • The full range of Mercedes-Benz passenger cars and utility vehicles • smart center • Experience in sales to members of the diplomatic corps and international organisations (Eurocontrol, European School, NATO, EC, EP, etc.) • Special diplomatic rates and promotions • Specialised diplomatic salesteam. A Daimler Brand Mercedes Europa Chaussée de Louvain 1150, 1200 Brussels, 3,8 - 6,4 L/100 KM • 98 -148 gCO 2 /KM Tel. +32 2 730 66 11, Fax. +32 2 705 73 13, [email protected] Environmental Information AR 19/3/2004 : www.mercedes-benz.be – Give priority to safety. ** Depending on the model. Publisher’s letter Inspirational people figure large in this issue roof that dreams can come true: I have long TIME ON YOUR SIDE wished that actress Katie Holmes would grace the cover of Together magazine. PI am by far not alone in my admiration for the actress, as demonstrated in the decision by Bobbi Brown to appoint Holmes as the first celebrity ambassador of her cosmetics brand. Learn about their mutual admiration for each other and discover their beauty tips on page 50. An interview with top jeweller Valerie Messika on page 63 reveals her secret to success, as does our interview with Belgium’s ‘bathtub baron’ Jean-Pol Piron, the man behind bathroom design firm Aquamass. -
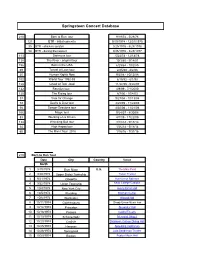
Springsteen Concert Database
Springsteen Concert Database 210 Born to Run tour 9/19/74 - 5/28/76 121 BTR - initial concerts 9/19/1974 - 12/31/1975 35 BTR - chicken scratch 3/25/1976 - 5/28/1976 54 BTR - during the lawsuit 9/26/1976 - 3/25/1977 113 Darkness tour 5/23/78 - 12/18/78 138 The River - original tour 10/3/80 - 9/14/81 156 Born in the USA 6/29/84 - 10/2/85 69 Tunnel of Love tour 2/25/88 - 8/2/88 20 Human Rights Now 9/2/88 - 10/15/88 102 World Tour 1992-93 6/15/92 - 6/1/93 128 Ghost of Tom Joad 11/22/95 - 5/26/97 132 Reunion tour 4/9/99 - 7/1/2000 120 The Rising tour 8/7/00 - 10/4/03 37 Vote for Change 9/27/04 - 10/13/04 72 Devils & Dust tour 4/25/05 - 11/22/05 56 Seeger Sessions tour 4/30/06 - 11/21/06 106 Magic tour 9/24/07 - 8/30/08 83 Working on a Dream 4/1/09 - 11/22/09 134 Wrecking Ball tour 3/18/12 - 9/18/13 34 High Hopes tour 1/26/14 - 5/18/14 65 The River Tour 2016 1/16/16 - 7/31/16 210 Born to Run Tour Date City Country Venue North America 1 9/19/1974 Bryn Mawr U.S. The Main Point 2 9/20/1974 Upper Darby Township Tower Theater 3 9/21/1974 Oneonta Hunt Union Ballroom 4 9/22/1974 Union Township Kean College Campus Grounds 5 10/4/1974 New York City Avery Fisher Hall 6 10/5/1974 Reading Bollman Center 7 10/6/1974 Worcester Atwood Hall 8 10/11/1974 Gaithersburg Shady Grove Music Fair 9 10/12/1974 Princeton Alexander Hall 10 10/18/1974 Passaic Capitol Theatre 11 10/19/1974 Schenectady Memorial Chapel 12 10/20/1974 Carlisle Dickinson College Dining Hall 13 10/25/1974 Hanover Spaulding Auditorium 14 10/26/1974 Springfield Julia Sanderson Theater 15 10/29/1974 Boston Boston Music Hall 16 11/1/1974 Upper Darby Tower Theater 17 11/2/1974 18 11/6/1974 Austin Armadillo World Headquarters 19 11/7/1974 20 11/8/1974 Corpus Christi Ritz Music Hall 21 11/9/1974 Houston Houston Music Hall 22 11/15/1974 Easton Kirby Field House 23 11/16/1974 Washington, D.C. -

Le « Soap Opera »
LeMonde Job: WMR2697--0001-0 WAS TMR2697-1 Op.: XX Rev.: 27-06-97 T.: 20:05 S.: 75,06-Cmp.:28,15, Base : LMQPAG 33Fap:99 No:0682 Lcp: 196 CMYK b TELEVISION a RADIO H MULTIMEDIA VUE SUR LES DOCS PORTRAIT Un CD-ROM Le devoir Macha Béranger, de mémoire vingt ans de nuit à la gloire de et la transmission à France-Inter. Charles de Gaulle ont marqué Page 27 Page 36 la programmation du 8e festival marseillais. Page 5 Produits à l’origine par les fabricants de lessive qui y trouvaient le moyen Le « soap opera » de promouvoir leurs produits à l’heure où les ménagères vaquent à leurs occupations domestiques, les « soap operas », interminables feuilletons, connaissent depuis l’après-guerre un succès qui ne se dément pas. Ils fleurissent maintenant hors des Etats-Unis. Arte, la chaîne culturelle, s’est penchée sur ces « opéras de savon » qui répondent aux principes du vieux mélodrame et sont devenus un phénomène de TRANSWORLD société, à l’échelle mondiale. Pages 2, 3 et 4 des origines à nos jours Salles de paris virtuels, cyberpoker, Cybercasinos, armé de sa carte de crédit, l’internaute peut gagner le jackpot, ou se ruiner, ou comment sans sortir de chez lui. Ces sites ont d’abord trouvé refuge aux Caraïbes, se ruiner mais les bookmakers anglais commencent à les concurrencer. sur Internet Pages 32 et 33 SEMAINE DU 30 JUIN AU 6 JUILLET 1997 LeMonde Job: WMR2697--0002-0 WAS TMR2697-2 Op.: XX Rev.: 28-06-97 T.: 08:19 S.: 75,06-Cmp.:28,15, Base : LMQPAG 33Fap:99 No:0683 Lcp: 196 CMYK ENQUÊTE Les recettes Ci-dessous, de haut en bas et de gauche à droite : « Haine et passion » du télé-mélo (« Guiding Light »), une telenovela mexicaine et « Amoureusement vôtre » Arte présente un dossier sur le « soap opera », succédané américain (« Loving ») du mélo de toujours, qui fait désormais recette dans le monde entier En pages 1 et 3 : « Amour, gloire et beauté » (« The Bold and the Beautiful ») L y a fort à parier que, aujourd’hui, Alfred de Musset ne manquerait pas, de jeter au moins un œil sur « Amour, gloire et beauté », tous les matins sur France 2. -

Aalleonso I 3EGIN
NOVEMBER 17, 2001 Music Volume 19, Issue 47 £3.95 Michael Jackson's Invinci- ble (Epic) goes straight in at number one on this week's European Top 100 Media Albums chart . e taller it41010 radio M&M chart toppers this week Radio faces biggest slump for decade Eurochart Hot 100 Singles by Emmanuel Legrand across [the whole of] Europe will be However, Neuville remains cau- KYLIE MINOGUE down by 0.5%, and that's an opti-tiouslyoptimisticfor2002. He Can't Get You Out Of My Head PARIS- The European radio industrymistic estimate," says Main Neu-explains: "For a start, 2002 will (Parlophone) is on course for its worst year since the ville, managing directorof Frenchcompare to a very bad year, 2001, European Top 100 Albums recession at the beginning of the '90s. independentmediaconsultancyso it should not be too difficult to do MICHAEL JACKSON According toestimates,Europe's Anima. better. We also see that consumer Invincible three biggestmarkets-the UK, Neuville says that 2001 wasspending in Europe doesn't seem to France and Germany-will all see neg- (Epic) affected by the slump in dotcombe too affected so far, and this ative growth in advertising revenues and telecoms advertising expendi-should bring back some confidence European Radio Top 50 for 2001. tures. He also says that the badto advertisers. And last but not MICHAEL JACKSON In its most recent Status Report,economic situation in the US hasleast, there are a few major events You Rock My World pan-European sales house IP antici-affected European media in thatsuch as the Winter Olympic Games (Epic) pates that radio's advertising revenuesUS companies facing tough marketand the football World Cup that for 2001 as a whole will be down 6% in conditions at home have cut downare likely to be supported by mas- European Dance Traxx the UK, 9% in France and 5% in Ger-on all expenditures, including thatsive advertising and sponsorship KYLIE MINOGUE many, while Spain and Italy are alsoof theiraffiliatesin Europe, ainvestments." Can't Get You Out Of My Head expected to report negative figures. -

Interview Music Hall Group Nv
Recensie: Interview Music Hall Group nv foto © Concertnews.be Recensie: De Music Hall Group werd in 1988 opgericht door Geert Allaert. Momenteel beheren ze vier eigen zalen waarvoor ze een samenwerking zijn aangegaan met de Jannen van het Sportpaleis. Ook als promotor en producent maken ze het waar. Producties zoals Peter Pan en Cinderella komen van hun hand. Eigenlijk worden de meeste grote musicals die in Vlaanderen te zien zijn, georganiseerd door Music Hall. Hoe is de groep uitgegroeid tot wat ze nu is? En hoe gaan ze om met de rode cijfers die vaak opduiken? Een gesprek met de CEO van Music Hall Group: Geert Allaert. Als concessiehouder en eigenaar In 1988 richtte u de Music Hall Group op (toen Flanders Eventhall, sinds 1999 onder de naam Music Hall). Daarna werd u eigenaar van Vorst Nationaal en de Capitole in Gent en concessiehouder van de Antwerpse Stadsschouwburg. Waarom net die zalen? Het gebouw van de Antwerpse Stadsschouwburg is van de stad en ik heb die in concessie gekregen. De andere zalen zijn eigendom. Ik heb van kleins af aan muziekschool gevolgd in Menen, daarna het stedelijk conservatorium in Kortrijk en daarna het conservatorium in Gent. Muzikaal had ik dus wel de bagage. Parallel heb ik in Gent Germaanse Filologie gestudeerd. Tekst en taal enerzijds en muziek anderzijds. Vandaar kwam dan de goesting voor musicals. Er wordt gedanst en geacteerd en de basis is tekst en muziek. Tijdens de opleidingsmaand van mijn legerdienst (Turnhout) had ik al het idee om de ‘afzwaai'  te organiseren met onder andere Carl Huybrechts, Erik Geboers en Willem Vermandere en nog een paar mensen. -

Table of Contents US Participants Enjoy Local Sport Staff Sgt
Thursday, Feb. 11, 2016 Volume 9, Issue 6 Published for members of the SHAPE/Chièvres, Brussels and Schinnen communities Benelux news briefs SHF plans for reduced staffi ng for holiday SHAPE Healthcare Facility will operate with reduced staff- ing Feb. 15 from 8 a.m. to 5 p.m. During those times: • Acute Care Walk-In Clinic will operate with Medical Of- ficer of the Day, or MOD, cov- erage only. • Physical Therapy and Re- ferral Management services will be available. • All other services will be closed. Housing Offi ce closes for training The SHAPE Housing Services Office will be closed for train- ing Feb. 16 from 1 to 3 p.m. and Feb. 17 from 9 to 11 a.m. Vendors wanted The second annual Chièvres American Festival will be held June 3 and 4. On both days, Chièvres will have a market with both food and non-food booths. Booths will be related to Texas Satur- day, June 3, and booths will be related to the United States in general Sunday, June 4. If you want to sell your wares, call the USAG Benelux Public Affairs Office at DSN 361-5694 or civilian 068-275694. Table of Contents US participants enjoy local sport Staff Sgt. John Darnell II (right) tries to draw everyone's attention while Staff Sgt. Paul Lamb gets ready to hit the News.............................1-5 chôlette at the yearly crossage game in Chièvres Wednesday, Feb. 10, 2016. Crossage is played in the streets of Inside the gate.................6-7 Chièvres on Ash Wednesday and could be described as a cross between golf and croquet, but, in crossage, teams Outside the gate............8-11 play with a wooden oblong ball (chôlette) and a wooden mallet (rabot). -

Ignace Vandewalle De Illegale Ghelamco Arena Als Politici Zich Met Voetbal Bemoeien…
DE ILLEGALE GHELAMCO ARENA IGNACE VANDEWALLE DE ILLEGALE GHELAMCO ARENA ALS POLITICI ZICH MET VOETBAL BEMOEIEN… Inhoud 1 De politieke ontvoogding van professionele sportclubs 7 2 KAA Gent: de afwending van het faillissement 11 3 Een multifunctioneel voetbalstadion 31 4 Alternatieve financiering via verkaveling Houtdok 73 5 Het interbellum Optima – Ghelamco 95 6 De commissie Optima/Termont: “Het surrealisme voorbij” 133 7 De Ghelamco Arena 167 Nawoord 231 Dankwoord 233 Bronnenlijst 235 1 De politieke ontvoogding van professionele sportclubs e nieuwe voetbaltempel van KAA Gent, de Ghelamco Arena, is Dhoofdzakelijk gebouwd met financiële steun van de stad Gent. Op Gentse gemeenteraden werden beslissingen omtrent de finan- ciering van het voetbalstadion vaak genomen in een wat hitserige supporterssfeer eigen aan een voetbalmatch. Zo liet schepen Christophe Peeters op de gemeenteraad van 25 oktober 2010, na tussenkomsten van de fracties sp.a, CD&V, N-VA, Open Vld en Groen, volgende uitspraak noteren in het verslag van de gemeente- raad: “Collega’s, ik had op bepaalde momenten bij sommige tussenkomsten het gevoel dat de gemeenteraad spontaan zou overgaan naar ‘Al wie dat niet stemt is FCB’.1 Maar het leek er bij wijlen wel op. Het enthou siasme is dan ook bijzonder groot en het doet mij bijzonder veel ge noegen – dat zal het ook wel zijn voor de club – dat er zoveel trouwe AA Gent supporters in deze gemeenteraad zitten. Ik denk dat het ook een voorwaarde moet zijn om in deze gemeenteraad te kunnen zijn: dat je minstens onze club daarin kunt steunen.” Ook Ivan De Witte deed in Het Laatste Nieuws van 15 mei 1999 als kersvers voorzitter van KAA Gent een opvallende uitspraak over de politieke inmenging bij KAA Gent: “Ik maak mij sterk dat, over alle partijgrenzen heen, een consensus groeit, dat de vierde stad van België zich nadrukkelijk moet integreren in de belangrijkste sportclub van de 1 FCB: Football Club Brugeois-Club Brugge K.V. -

POPMUZIEK OPMUZIEK Kan Je Dagelijks Beleven in Vlaanderen Langs De Media, Cies
CULTUUR/HET AANBOD POPMUZIEK OPMUZIEK kan je dagelijks beleven in Vlaanderen langs de media, cies. De grote zalen als de Ancienne Belgique in Brussel ontvangen dan de langs de cd-winkels, maar ook en vooral door er naartoe te gaan. Elke wat grotere groepen, net als in Gent de Vooruit en in Antwerpen de Pweek kan je in Vlaanderen tientallen popconcerten bijwonen. Elisabethzaal. Ten slotte heb je de mega-zalen: Flanders Expo in Gent, Vorst Tegenwoordig staat er een circuit op de kaart dat het mogelijk maakt dat Nationaal in Brussel en het Sportpaleis in Antwerpen. zowel jonge amateurs tot supersterren hier passeren. De amateurs krijgen En dan zijn er nog de festivals, die gespreid zitten over het hele jaar, maar kansen in de jeugdhuizen. Een meer volwassen en professioneel aanbod vooral in de zomer voluit gaan. De bekendste zijn Rock Werchter (T/W), tref je aan in de zowat 70 culturele centra. Voor de fans van veeleer gespe- Beach Rock, Folk Dranouter, Sfinks (wereldmuziek) en Pukkelpop. Elk van die cialiseerde genres zijn er negen muziekclubs, verspreid over de vijf provin- festivals lokt tienduizenden mensen om naar muziek te luisteren. INFO GRAFIEK 7 BELGISCHE PLATENVERKOOP ROCKCONCERTEN In de loop van het jaar 30.000 x 1.000 Dé rocktempel in Vlaanderen is de - De Nachten www.denachten.be Ancienne Belgique in Brussel, die zo- - Nekka www.nekka.be Singels wel een kleine clubzaal heeft als een - Night of the Proms www.notp.com 25.000 Albums grote concertzaal. Andere zalen in Totaal INFORMATIE Vlaanderen waar rock en ook de meer Voor concertnieuws kun je de kalen- actuele elektronische muziek een be- 20.000 ders raadplegen van de culturele cen- langrijke plaats innemen, zijn de tra, de organisatoren, de zalen, en de Muziek-O-Droom (Hasselt), Flanders promotoren. -

Als PDF Downloaden
Deine U2-Konzert-Statistik Konzert-Statistik: http://www.u2tour.de/statistic.php?id=vevv3a Besuchte Konzerte von spiritualcowboy 31.01.1985 Köln, Sporthalle 25.05.1985 Nürburg, Nürburgring 17.06.1987 Köln, Müngersdorfer Stadion 21.07.1987 München, Olympiahalle 22.07.1987 München, Olympiahalle 14.12.1989 Dortmund, Westfalenhalle 15.12.1989 Dortmund, Westfalenhalle 16.12.1989 Dortmund, Westfalenhalle 18.12.1989 Amsterdam, RAI Europahal 09.05.1992 Gent, Flanders Expo Hal 24.05.1992 Wien, Donauinsel 25.05.1992 München, Olympiahalle 29.05.1992 Frankfurt, Festhalle 04.06.1992 Dortmund, Westfalenhalle 05.06.1992 Dortmund, Westfalenhalle 13.06.1992 Kiel, Ostseehalle 15.06.1992 Rotterdam, Sportpaleis Ahoy 29.05.1993 Werchter, Festival Grounds 02.06.1993 Frankfurt, Waldstadion 04.06.1993 München, Olympiastadion 06.06.1993 Stuttgart, Cannstatter Wasen 09.06.1993 Bremen, Weserstadion 12.06.1993 Köln, Müngersdorfer Stadion 15.06.1993 Berlin, Olympiastadion 03.08.1993 Nijmegen, Goffertpark 27.08.1993 Dublin, RDS Arena 28.08.1993 Dublin, RDS Arena 19.07.1997 Rotterdam, Feyenoord Stadium (De Kuip) 27.07.1997 Köln, Butzweilerhof 29.07.1997 Leipzig, Festwiese 31.07.1997 Mannheim, Maimarkt 09.09.1997 Madrid, Estadio Vicente Calderón 12.07.2001 Köln, Kölnarena 13.07.2001 Köln, Kölnarena 29.07.2001 Berlin, Waldbühne 05.08.2001 Antwerpen, Sportpaleis 12.06.2005 Gelsenkirchen, Arena Auf Schalke Seite 1/11 Deine U2-Konzert-Statistik 07.07.2005 Berlin, Olympiastadion 13.07.2005 Amsterdam, Amsterdam Arena 15.07.2005 Amsterdam, Amsterdam Arena 16.07.2005 Amsterdam, -

For Cultural Diversity City of Ghent
Point Persons G l o b a l Wim Vandendriessche a l l i a n c e Head of Departement Unesco Kaat Heirbrant Executive Officer for cultural Diversity City of Ghent creative cities network Music Department of City Promotion & Sports Sint-Pietersplein 10 9000 Gent T +32 (0)9 243 77 40 F +32 (0)9 243 77 49 [email protected] [email protected] www.gent.be Table of Contents 1 Executive Summary 3 Classical 6 Jazz 8 Dance and Techno 9 Avant-garde 9 G l o b a l a l l i a n c e Musical 10 Unesco for What about Rock and World music? 10 cultural Diversity creative cities network Music 2 Ghent in Context 13 Succinct general survey 15 Animated city of culture 17 3 Extended Description of Cultural Assests 21 3.1 Facts and Figures 23 3.1.1 Subsidies and investments 25 3.1.2 Economic return 28 3.2 History and Tradition 29 3.3.1 Halls/Theatres 37 3.3.3 Rehearsal rooms 44 3.3.4 café circuit 44 3.3.5 Recording studios 45 3.3.6 Public space 45 3.3.7 Bandstands 46 3.4 Festivals 47 3.4.1 The Federation of Music Festivals in Flanders (FMiV) 49 3.4.2 The European Festivals Association (EFA) 49 3.4.3 The Ghent Festival 50 3.4.4 10 days off 51 3.4.5 Blue Note Records Festival 52 3.4.6 Boomtown 53 3.4.7 Polé Polé 54 3.4.8 Festival of Flanders 54 3.4.9 OdeGand 55 3.4.10 Film Festival 56 3.4.11 Jazz in the Park 57 3.4.12 November Music 58 3.4.13 Kozzmozz 59 3.4.14 11 July Celebrations 60 3.4.16 Festivals… Festivals! 61 3.5 Contempary Creation and Environment 63 3.5.1 Contemporary classics 65 3.5.2 Rock & pop 66 3.5.3 Jazz 67 3.5.4 Folk 68 3.5.5 Dance/Techno -

I Trade DVD-DL on a 3:1 Base, Blu-Rays Only for Blu
I trade DVD-DL on a 3:1 Base, Blu-Rays only for Blu-Rays and RT (rare shows) only for other RTs in return, if you see a RT show on other lists as common, trade it with this guy and not with me Grey = Authored by me Red = Filmed by me Blue = Blu-Ray (BD) I DON’T SELL ANY BOOTLEGS , I'M JUST MAKING TRADES!!! __________________________________________________________________________________________________________ 12.05.1981 Palais de Beaulieu - Lausanne, Switzerland 26.09.1981 Rockfestival - Solothurn, Switzerland (Crownkocher;Thumraider) xx.12.1982 Solingen, Germany 01.03.1985 Johanneshovs Isstadion - Stockholm, Sweden 27.04.1986 Forest National - Brussels, Belgium 27.06.1986 IMA Sports Arena - Flint, MI, USA (Damage Inc.) 23.06.1989 Fat Jak's Night Club - Council Bluffs, IA, USA 30.04.1993 Halle Gartlage - Osnabrück, Germany 03.05.1993 Mejeriet - Lund, Sweden (Havrefras) 18.05.1993 Zimba - Milan, Italy 15.10.1993 L'Amours - Brooklyn, NY, USA 23.10.1993 The Ritz - Roseville, MI, USA 26.11.1994 Tavastia Club - Helsinki, Finland 02.05.1996 Pumpenhurst - Copenhagen, Denmark 31.05.1996 Buenos Aires, Argentina (PRO) 27.04.2005 Luzhniki Sports Arena - Moscow, Russia 08.07.2005 Rockwave Festival - Terravibe, Greece (Left Angle;Incl. Slayer) 11.08.2005 Sziget Festival - Budapest, Hungary 26.06.2010 Besiktas Inönü Stadium(Sonisphere) - Istanbul, Turkey (Efooo;Nikky Syxx) 27.09.2010 B.B. King Blues Club & Grill - New York, NY, USA (YT shit) 04.02.2011 Klub Studio - Krakau, Poland (1DVD-DL)( Damian Kaplita) 10.02.2011 Live Music Hall – Cologne, -

La Takes Light Rail to the Next Level
THE INTERNATIONAL LIGHT RAIL MAGAZINE www.lrta.org www.tautonline.com AUGUST 2016 NO. 944 LA TAKES LIGHT RAIL TO THE NEXT LEVEL Intermodal: Urban rail’s part in the bigger picture Dubai signs Metro expansion deal Could ‘Brexit’ jeopardise UK funding? Seattle brings forward LRT growth ISSN 1460-8324 £4.25 Prague Systems Factfile 08 Tram/metro growth High-floor to meet in the Czech capital low-floor in Utrecht 9 771460 832043 LRT MONITOR TheLRT MONITOR series from Mainspring is an essential reference work for anyone who operates in the world’s light and urban rail sectors. Featuring regular updates in both digital and print form, the LRT Monitor includes an overview of every established line and network as well as details of planned schemes and those under construction. Each entry includes: An overview A high-quality of the system’s image for ease development, of future recent major reference projects and known plans for the future Contact names The vital and numbers operational for the key statistics decision-makers The European edition covers 425 tramway, light rail and metro systems across the continent – from Armenia to the United Kingdom. Our data is derived from first-person research, so you can be assured that it is the most up-to-date possible, with regular updates to ensure you stay on top of this thriving market. Other editions: For more details contact +44 1733 367607 or email [email protected] www.mainspring.co.uk/monitor CONTENTS The official journal of the Light Rail Transit Association AUGUST 2016 Vol.