Open-Access for Existing LMIC Demographic Surveillance Data
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

ICT in the Kosovo National Statistical System - Baseline Review and Recommendations for Development
UNDP Kosovo UNKT Technical assistance to the IT department of the Kosovo Agency of Statistics (KAS) Technical analysis of information technology in the national statistical system ICT in the Kosovo National Statistical System - Baseline review and Recommendations for development April 2013 by Arij Dekker, Consultant in statistical data processing and management [email protected] ICT in the Kosovo National Statistical System - Baseline review and Recommendations for development 1 Contents List of Acronyms ...................................................................................................................................... 3 Executive Summary ................................................................................................................................. 5 Chapter 1. Introduction ..................................................................................................................... 7 Chapter 2. Methods of information gathering .................................................................................... 9 2.1 Description of interview partners and question clusters ........................................................... 9 2.2 Other information sources ..................................................................................................... 12 Chapter 3. The present state of ICT in the Kosovo national statistical system ................................... 14 3.1 Summary of information gathered from the interviews ......................................................... -

On New Data Sources for the Production of Official Statistics
On new data sources for the production of official statistics David Salgado1,2 and Bogdan Oancea3 1Dept. Methodology and Development of Statistical Production, Statistics Spain (INE), Spain 2Dept. Statistics and Operations Research, Complutense University of Madrid, Spain 3Dept. Business Administration, University of Bucharest, Romania February 7, 2020 Abstract In the past years we have witnessed the rise of new data sources for the potential production of official statistics, which, by and large, can be classified as survey, administrative, and digital data. Apart from the differences in their generation and collection, we claim that their lack of statistical metadata, their economic value, and their lack of ownership by data holders pose several entangled challenges lurking the incorporation of new data into the routinely production of official statistics. We argue that every challenge must be duly overcome in the international community to bring new statistical products based on these sources. These challenges can be naturally classified into different entangled issues regarding access to data, statistical methodology, quality, information technologies, and management. We identify the most relevant to be necessarily tackled before new data sources can be definitively considered fully incorporated into the production of official statistics. Contents 1 Introduction 2 2 Data: survey, administrative, digital 3 2.1 Somedefinitions ..................................... .... 3 2.2 Statisticalmetadata ................................ ....... 4 2.3 Economicvalue..................................... -

Software Developer
PINKY MONONYANE SOFTWARE DEVELOPER https://www.pinkymononyane.info PROFILE English, Sotho, Tsonga, Tswana, Venda, N. Sotho 33 Years old, Black Female with no disability I have 9 years’ programming experience with professional skills that could fill a South African Citizen, ID Number: 871020 0461 08 1 bucket 10 times over, with few honorable mentions such as HTML, B – Light Vehicles 750kg to 3500kg CSS3, Python (I have more than 5 years Single of Experience in Django framework. I have been developing small to medium projects even before my latest position ADDRESS & CONTACT INFO at BCM), Php and Java Script with keen attention to details, Phone Number: +27 78 968 2362 plus a well dynamic personality that appeals to most that I have had a Home Address Recent / Previous pleasure working/collaborating with. Work Address 684 Lievaart Point to note... Challenges is what I live, Street 145 Second Street breath and seek, for it's in those that's Proclamation Hill Parkmore where personal growth is found. Pretoria, Gauteng Sandton 0183 2052 Furthermore I constantly look for more knowledge related to my field; as such I Email Address: [email protected] have enrolled in Computer Science BSc Degree at UNISA, as they say knowledge CAREER STATUS is like an endless river flow. Can't have 2013-2019 Data Developer: 7 Years’ Experience enough: P. Languages:- So when I'm nowhere to be found rest Python, CSpro, SSRS, SQL Server, R-Statistics, SAS, Server assured you can find me programming a interaction, security and management under various software on my friendly computer or out environments (Linux, Windows and Windows server) on a hunt for further knowledge and if not I’m probably out travelling and 2020-2020 Software Developer: 9 Months Formal Experience spending time with my loved ones. -
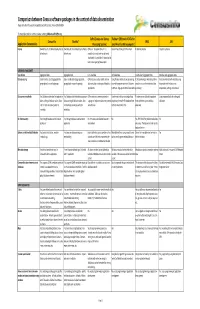
Comparison Between Census Software Packages in the Context of Data Dissemination Prepared by Devinfo Support Group (DSG) and UN Statistics Division (DESA/UNSD)
Comparison between Census software packages in the context of data dissemination Prepared by DevInfo Support Group (DSG) and UN Statistics Division (DESA/UNSD) For more information or comments please contact: [email protected] CsPro (Census and Survey Redatam (REtrieval of DATa for CensusInfo DevInfo* SPSS SAS Application Characteristics Processing System) small Areas by Microcomputer) License Owned by UN, distributed royalty-free to Owned by UN, distributed royalty-free to CSPro is in the public domain. It is Version free of charge for Download Properitery license Properitery license all end-users all end-users available at no cost and may be freely distributed. It is available for download at www.census.gov/ipc/www/cspro DATABASE MANAGEMENT Type of data Aggregated data. Aggregated data. Individual data. Individual data. Individual and aggregated data. Individual and aggregated data. Data processing Easily handles data disaggregated by Easily handles data disaggregated by CSPro lets you create, modify, and run Using Process module allows processing It allows entering primary data, define It lets you interact with your data using geographical area and subgroups. geographical area and subgroups. data entry, batch editing, and tabulation data with programs written in Redatam variables and perform statistical data integrated tools for data entry, applications command language or limited Assisstants processing computation, editing, and retrieval. Data consistency checks Yes, Database administration application Yes, Database administration -

Saidou Hamadou
SAIDOU HAMADOU Contact address: P.O.Box : 707 Yaoundé (Cameroon) Telephone: Cameroon : (237) 677 71 94 98 / 697 42 42 32 Email: [email protected] [email protected] Summary Over 11 years of experience in managing data, conducting health and/or demographic surveys in many countries in Central and West Africa Over 08 years of experiences in implementing and evaluating result-based financing in Cameroon, Burkina-Faso, Liberia, Republic of Congo, Democratic Republic of Congo, Chad, Djibouti and Haïti ; 03 years of experiences with Service Delivery Indicators (SDI) surveys Member of many research projects in Africa and in the World Fluent in French and speaks enough English Education University of Paris-Dauphine (FRANCE) 2018 PhD dissertation : „Poverty, Malaria and Health System Reforms in Africa: Three Studies Applied in Cameroon’ Doctoral advisors: Pr. Sandrine MESPLE-SOMPS and Dr. Anne-Sophie ROBILLIARD Institute for Training and Demographic Research (IFORD)(CAMEROUN) 2007-2009 Professional master in Demography, Master‟s Thesis: Dynamics of the relationship between standard of living of households and diarrhea- related morbidity in children of less than three years in Cameroon University of YAOUNDÉ I (CAMEROUN) 2005-2006 Master's degree in computer science - Option: Calculation scientific, Master‟s degree thesis: The securing of data circulation in a local network of enterprise by the CRYPTOGRAPHY University of NGAOUNDÉRÉ (CAMEROUN) 2004-2005 Bachelor of science and technical information (STI) - Option: Calculation scientific, -

Objectives Overview of Data Management Tools
Data Management: Collecting, Protecting and Managing Data Presented by Andre Hackman Johns Hopkins Bloomberg School of Public Health Department of Biostatistics July 17, 2014 Objectives • Review of available database and data management tools and their capabilities • Demonstrate examples of good data management • Discuss strategies and good practice for data security and backup • Discuss data conversion and transfer options Overview of Data Management Tools Types of data management tools to consider Type of tool Examples Spreadsheet Microsoft Excel Google Docs Spreadsheet Open Office Calc Desktop database Microsoft Access Filemaker Pro Specialized databases Epi Info, CSPro, EpiData Web database REDCap OpenClinica Mobile data collection Open Data Kit, CommCare, Magpi, iFormBuilder, 1 Choosing a data management tool… Pick the tool that is appropriate for the data needs of the project • What will be the challenges you face with each tool? – Complexity and scale of the data being collected • Is it longitudinal data with many time points? • What is the expected number of records? Choosing a data management tool… Pick the tool that is appropriate for the data needs of the project • What will be the challenges you face with each tool? – Complexity and scale of the data being collected – Mixture of collection modes: mobile, kiosk, and computer entry. • How will data flow between them? Choosing a data management tool… Pick the tool that is appropriate for the data needs of the project • What will be the challenges you face with each tool? – Complexity and scale of the data being collected – Mixture of collection modes: mobile, kiosk, and computer entry. – Complexity of the data entry forms 2 Choosing a data management tool… Pick the tool that is appropriate for the data needs of the project • What will be the challenges you face with each tool? – Complexity and scale of the data being collected – Mixture of collection modes: mobile, kiosk, and computer entry. -

Planning Checklist
CHAPTER 2 Planning Checklist Reproductive Health Assessment Toolkit for Conflict- Affected Women well-devised plan is needed to ensure suc data collection, data cleaning, analysis, report Acessful implementation of the Toolkit. The writing, and dissemination of findings. planning process should be initiated prior to Secure funding. securing funding. The amount of time required for the planning process will vary based on your D. Prepare locator form and questionnaire. organization’s existing infrastructure and resources. Consider this checklist a model that can be Modify country-specific responses on ques adapted as necessary to meet your specific needs tionnaire. This may require technical assis and situation. You can also change the sequence tance from DRH. of activities as needed. For example, you could Modify country-specific fields on the locator conduct field-level planning before initiating form. national-level planning. Translate locator form and questionnaire into the local language, using translators who are Part I. National-level planning able to read and write both English and the local language. A. Select a site to conduct survey. Criteria for selection include: Back-translate forms into English to ensure they were translated correctly. Availability of a reasonable estimate of popu lation size Revise translated forms as needed. (This normally occurs during training and the pilot A stable, post-emergency population with no test, with input from the survey team.) major influx or outflow of people Finalize standard local-language version of Availability of basic reproductive health the locator form and questionnaire. services B. Engage national-level stakeholders. Part II. Field-level planning Engage potential stakeholders, such as: National government agencies responsible A. -

Reconciling Food, Energy, and Environmental Outcomes: Three Essays on the Economics of Biomass Management in Western Kenya
RECONCILING FOOD, ENERGY, AND ENVIRONMENTAL OUTCOMES: THREE ESSAYS ON THE ECONOMICS OF BIOMASS MANAGEMENT IN WESTERN KENYA A Dissertation Presented to the Faculty of the Graduate School of Cornell University in Partial Fulfillment of the Requirements for the Degree of Doctor of Philosophy by Julia Berazneva August 2015 c 2015 Julia Berazneva ALL RIGHTS RESERVED RECONCILING FOOD, ENERGY, AND ENVIRONMENTAL OUTCOMES: THREE ESSAYS ON THE ECONOMICS OF BIOMASS MANAGEMENT IN WESTERN KENYA Julia Berazneva, Ph.D. Cornell University 2015 This dissertation explores human-environment interactions, focusing on on-farm biological resources (biomass) and crop residues, in particular, and how they can meet the competing demands of food production, energy generation, and environmental conservation in Sub- Saharan Africa. The empirical setting is rural western Kenya, where maize residues, one of the largest sources of on-farm biomass, constitute a large portion of livestock diets, con- tribute to household energy needs, and are fundamental in maintaining and improving soil fertility. The three dissertation essays analyze the uses and value of crop residues in tropical smallholder agriculture from several di↵erent perspectives and using di↵erent methodological approaches, all based on data from the western Kenyan highlands. The first essay (Chapter 2) treats non-marketed crop residues as factors of household production, accounting for their long-term benefits when used for soil fertility management. Empirically, the essay estimates a household-level maize production function and calculates the shadow value of maize residues as suggested by the theoretical framework and empirical estimates. This estimated value is substantial—$0.06-08 per kilogram and $208 per average farm—and is higher for poorer households. -

Coal Wholesale Lines World Report
Coal Wholesale Lines World Report established in 1974, and a brand since 1981. www.datagroup.org Coal Wholesale Lines World Report Database Ref: 4235201_L This database is updated monthly. Coal Wholesale Lines World Report COAL WHOLESALE LINES WORLD REPORT The Coal merchant wholesalers Lines Report has the following information. The base report has 59 chapters, plus the Excel spreadsheets & Access databases specified. This research provides World Data on Coal merchant wholesalers Product Lines. The report is available in several Editions and Parts and the contents and cost of each part is shown below. The Client can choose the Edition required; and subsequently any Parts that are required from the After- Sales Service. Contents Description ....................................................................................................................................... 5 REPORT EDITIONS ........................................................................................................................... 6 World Report ....................................................................................................................................... 6 Regional Report ................................................................................................................................... 6 Country Report .................................................................................................................................... 6 Town & Country Report ...................................................................................................................... -

Dissemination of Microdata Files Principles, Procedures and Practices
IHSN International Household Survey Network About the IHSN Dissemination of Microdata Files In February 2004, representatives from developing countries and development agencies participated in the Second Roundtable on Development Results held in Marrakech, Morocco. They reflected on how donors can better coordinate support to strengthen the statistical systems and monitoring and Principles, Procedures and Practices evaluation capacity that countries need to manage their development process. One of the outcomes of the Roundtable was the adoption of a global plan for statistics, the Marrakech Action Plan for Statistics (MAPS). Among the MAPS key recommendations was the creation of an International Household Survey Network. In doing so, the international community acknowledged the critical role played by sample surveys in supporting the planning, implementation and monitoring of development policies and programs. Furthermore, it provided national and international agencies with a platform to better coordinate and manage socioeconomic data collection and analysis, and to mobilize support for more efficient and effective approaches to conducting surveys in developing countries. The IHSN Working Paper series is intended to encourage the exchange of ideas and discussion Olivier Dupriez and Ernie Boyko on topics related to the design and implementation of household surveys, and to the analysis, dissemination and use of survey data. People who whish to submit material for publication in the IHSN Working Paper series are encouraged to contact the IHSN secretariat via [email protected]. IHSN Working Paper No 005 August 2010 www.ihsn.org E-mail: [email protected] www.ihsn.org WP-Cover-005.indd 1 11/1/10 2:44 PM Dissemination of Microdata Files Principles, Procedures and Practices Olivier Dupriez and Ernie Boyko IHSN Working Paper No 005 August 2010 Abstract In all countries, data producers are faced by expanding demand for microdata. -

Evaluation Specialist – Research Transparency, Reproducibility and Ethics 3Ie, New Delhi
Evaluation Specialist – Research Transparency, Reproducibility and Ethics 3ie, New Delhi 1. Background The International Initiative for Impact Evaluation (3ie) promotes evidence-informed equitable, inclusive and sustainable development. We support the generation and effective use of high- quality evidence to inform decision-making and improve the lives of people living in poverty in low- and middle-income countries. We provide guidance and support to produce, synthesise and quality assure evidence of what works, for whom, how, why and at what cost. 3ie is registered as a non-governmental organisation in the United States. It has offices in New Delhi, London and Washington, DC. Our work encompasses a wide range of topics, sectors, and themes, including but not limited to: health, nutrition, education, agriculture, governance, microfinance, climate change, humanitarian interventions, and social protection. 3ie is inviting applications for the post of evaluation specialist (ES) focusing on the areas of research transparency, reproducibility and ethics (TRE), preferably based at the 3ie offices located in Washington, DC, London or in New Delhi. Applicants should have the right to work in one of 3ie’s office locations; in exceptional cases, we may consider a remote working arrangement. The opportunity to work from another country as a consultant may be considered for exceptional candidates. 2. Summary The ES will provide technical and management leadership for all aspects of 3ie’s TRE related work, including for products and services, and will support their application within 3ie’s range of evaluation activities including impact evaluations, formative research, qualitative evaluations and synthesis reviews. The ES will support the design, implementation, review, oversight, and quality assurance of TRE activities. -

Cspro Para Encuestas De Salud Reproductiva
CSPRO PARA ENCUESTAS DE SALUD REPRODUCTIVA Esta ayuda técnica va a ser desarrollada tomando como base el cuestionario Modelo de las Encuestas de Salud Reproductiva “Reproductive Health Survey“ RHS, vamos a crear un programa de ingreso de datos utilizando el software CSPRO, desarrollado por el Buro de Censos de los Estados Unidos. (Census and Survey Processing System - Sistema para el Procesamiento de Censos y Encuestas). CSPRO es un paquete orientado a censos y encuestas, que facilita la creación de pantallas de captura y verificación de digitación, aplicaciones de validación, detección de errores, tabulaciones rápidas para el análisis y la divulgación de los datos. CSPRO es un paquete de distribución libre y se lo puede conseguir en la siguiente dirección electrónica: http://www.census.gov/ipc/www/cspro/, en este mismo lugar se puede obtener acceso a la documentación necesaria para el uso y aplicación del mismo como son los manuales para: Getting Started (Cómo empezar), User's Guide (Guía del Usuario) y Data Entry User's Guide (Guía para el usuario de entrada de datos). Durante el desarrollo de esta ayuda técnica, se intentará de hacerla de la manera más explícita posible, sin embargo cualquier inquietud que pueda generarse en el desarrollo de este programa se puede acudir a los manuales indicados en el párrafo anterior. Una de las tareas más importantes para la persona que va a desarrollar el programa de ingreso de datos en que esté familiarizado con el cuestionario, es decir que al menos estuvo involucrado en parte del diseño del cuestionario